







2、小哥一直在你楼下等(小哥还有其他的快递要送)。
3、周末再送(显然等不及)。
4、这个女朋友我不要了(绝对不可能)!
小芳便利店出现后,交互图就应如下:
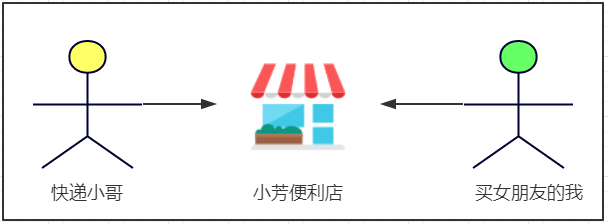
在上面例子中,“快递小哥”和“买女朋友的我”就是需要交互的两个系统,小芳便利店就是我们本文要讲的-“消息中间件”。总结下来小芳便利店(消息中间件)出现后有如下好处:
1、 解耦
快递小哥手上有很多快递需要送,他每次都需要先电话一一确认收货人是否有空、哪个时间段有空,然后再确定好送货的方案。这样完全依赖收货人了!如果快递一多,快递小哥估计的忙疯了……如果有了便利店,快递小哥只需要将同一个小区的快递放在同一个便利店,然后通知收货人来取货就可以了,这时候快递小哥和收货人就实现了解耦!
2、 异步
快递小哥打电话给我后需要一直在你楼下等着,直到我拿走你的快递他才能去送其他人的。快递小哥将快递放在小芳便利店后,又可以干其他的活儿去了,不需要等待你到来而一直处于等待状态。提高了工作的效率。
3、 削峰
假设双十一我买了不同店里的各种商品,而恰巧这些店发货的快递都不一样,有中通、圆通、申通、各种通等……更巧的是他们都同时到货了!中通的小哥打来电话叫我去北门取快递、圆通小哥叫我去南门、申通小哥叫我去东门。我一时手忙脚乱……
我们能看到在系统需要交互的场景中,使用消息队列中间件真的是好处多多,基于这种思路,就有了丰巢、菜鸟驿站等比小芳便利店更专业的“中间件”了。
最后,上面的故事纯属虚构……
消息队列通信的模式
=============
通过上面的例子我们引出了消息中间件,并且介绍了消息队列出现后的好处,这里就需要介绍消息队列通信的两种模式了:
一、 点对点模式

如上图所示,点对点模式通常是基于拉取或者轮询的消息传送模型,这个模型的特点是发送到队列的消息被一个且只有一个消费者进行处理。生产者将消息放入消息队列后,由消费者主动的去拉取消息进行消费。点对点模型的的优点是消费者拉取消息的频率可以由自己控制。但是消息队列是否有消息需要消费,在消费者端无法感知,所以在消费者端需要额外的线程去监控。
二、 发布订阅模式
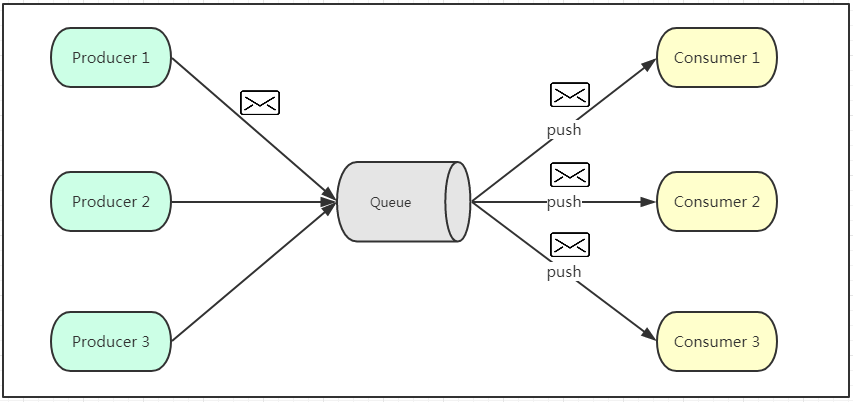
如上图所示,发布订阅模式是一个基于消息送的消息传送模型,改模型可以有多种不同的订阅者。生产者将消息放入消息队列后,队列会将消息推送给订阅过该类消息的消费者(类似微信公众号)。由于是消费者被动接收推送,所以无需感知消息队列是否有待消费的消息!但是consumer1、consumer2、consumer3由于机器性能不一样,所以处理消息的能力也会不一样,但消息队列却无法感知消费者消费的速度!所以推送的速度成了发布订阅模模式的一个问题!假设三个消费者处理速度分别是8M/s、5M/s、2M/s,如果队列推送的速度为5M/s,则consumer3无法承受!如果队列推送的速度为2M/s,则consumer1、consumer2会出现资源的极大浪费!
Kafka
=========
上面简单的介绍了为什么需要消息队列以及消息队列通信的两种模式,接下来就到了我们本文的主角——kafka闪亮登场的时候了!Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据,具有高性能、持久化、多副本备份、横向扩展能力……… 一些基本的介绍这里就不展开了,网上有太多关于这些的介绍了,读者可以自行百度一下!
基础架构及术语
话不多说,先看图,通过这张图我们来捋一捋相关的概念及之间的关系:
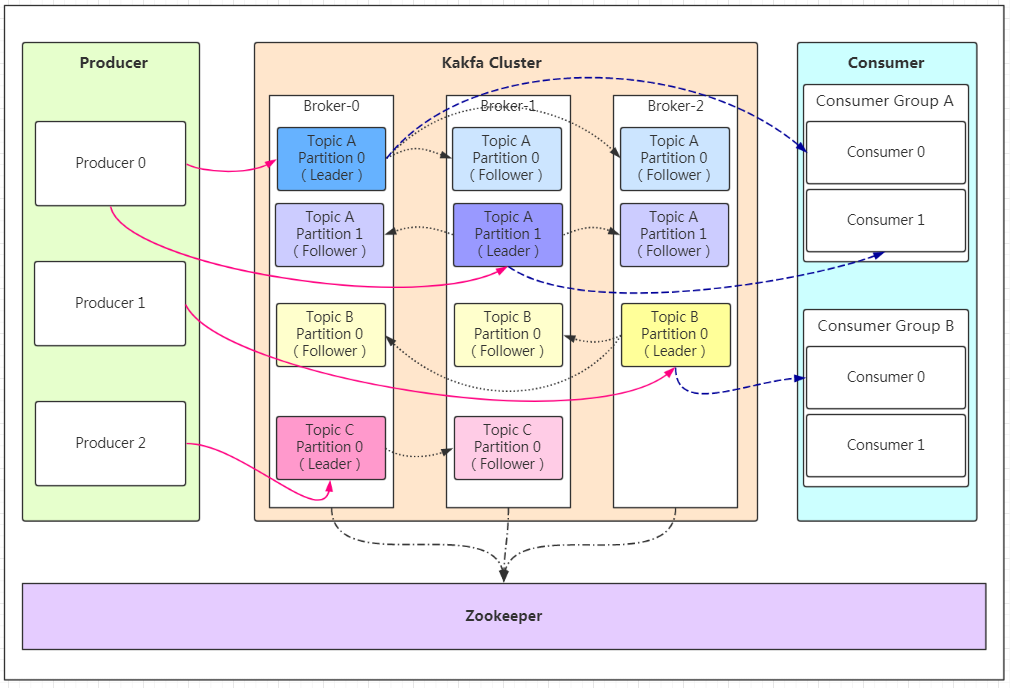
如果看到这张图你很懵逼,木有关系!我们先来分析相关概念
Producer:Producer即生产者,消息的产生者,是消息的入口。
kafka cluster:
Broker:Broker是kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等……
Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。
Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹!
Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
Message:每一条发送的消息主体。
Consumer:消费者,即消息的消费方,是消息的出口。
Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
Zookeeper:kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
工作流程分析
上面介绍了kafka的基础架构及基本概念,不知道大家看完有没有对kafka有个大致印象,如果对还比较懵也没关系!我们接下来再结合上面的结构图分析kafka的工作流程,最后再回来整个梳理一遍我相信你会更有收获!
发送数据
我们看上面的架构图中,producer就是生产者,是数据的入口。注意看图中的红色箭头,Producer在写入数据的时候永远的找leader,不会直接将数据写入follower!那leader怎么找呢?写入的流程又是什么样的呢?我们看下图:
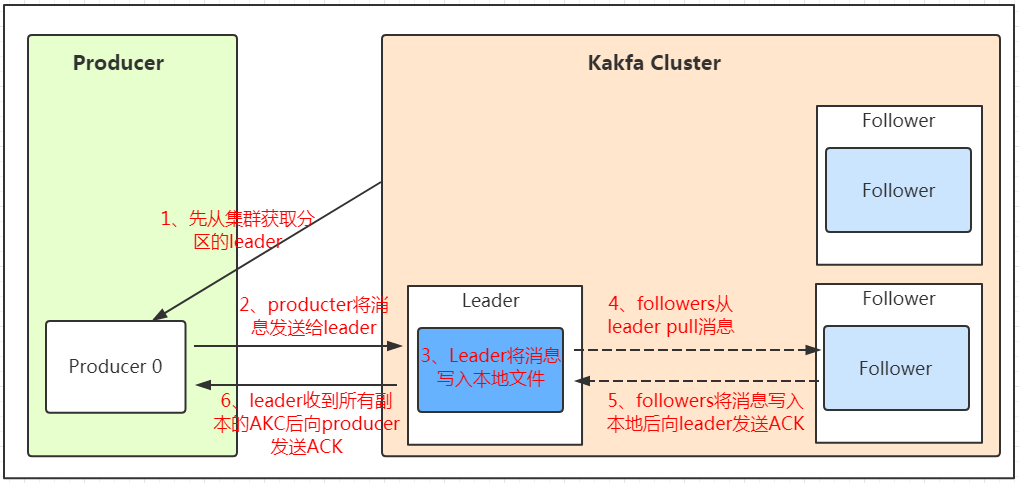
发送的流程就在图中已经说明了,就不单独在文字列出来了!需要注意的一点是,消息写入leader后,follower是主动的去leader进行同步的!producer采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘,所以保证同一分区内的数据是有序的!写入示意图如下:
最后在出来放一波福利吧!希望可以帮助到大家!
千千万万要记得:多刷题!!多刷题!!
之前算法是我的硬伤,后面硬啃了好长一段时间才补回来,算法才是程序员的灵魂!!!!
篇幅有限,以下只能截图分享部分的资源!!
(1)多线程(这里以多线程为代表,其实整理了一本JAVA核心架构笔记集)

(2)刷的算法题(还有左神的算法笔记)

(3)面经+真题解析+对应的相关笔记(很全面)
(4)视频学习(部分)
ps:当你觉得学不进或者累了的时候,视频是个不错的选择

其实以上我所分享的所有东西,有需要的话我这边可以免费分享给大家,但请一定记住获取方式:点击这里前往免费获取
4)视频学习(部分)
ps:当你觉得学不进或者累了的时候,视频是个不错的选择
[外链图片转存中…(img-Qq98RXuI-1628397854047)]
其实以上我所分享的所有东西,有需要的话我这边可以免费分享给大家,但请一定记住获取方式:点击这里前往免费获取
在这里,最后只一句话:祝大家offer拿到手软!!















 732
732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









