







做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
量子状态又可表示为:
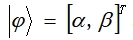
量子遗传算法将染色体上的基因用量子比特表示,从而增加种群多样性。随机生成m个染色体,每个染色体上的基因用量子比特表示 ,且初始化为
,且初始化为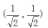 。
。
2.2 在量子遗传算法中,染色体采用量子位的概率幅进行编码,编码方案如下:
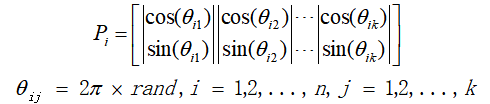
Pi为第i个基因,为量子比特的相位,n为染色体数目,k为量子位的位数即解空间的维数,rand是[0,1]范围内的随机数。每个量子位为分上下两行,分别对应两个量子基本态的概率幅,满足归一化条件,因此每个个体包含上下两条文化基因链,每条基因链是优化问题的一个候选解。由此可知,量子遗传算法在种群规模不变的情况下,候选解个数比遗传算法多一倍,增加了解空间的多样性,提高了寻优成功的概率。
2.3 对初始化种群中的每一个个体进行测量。
随机生成一个数x∈[0,1],若
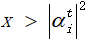
则测量值取1,否则取0。
2.4 对每个测量值进行适应度的评估,以适应度来选择最优个体,进行遗传变异。
2.5 使用量子旋转门进行下一代个体的更新,量子旋转门为逻辑门中一种较为常用的方法,具体表示为:
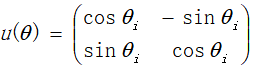
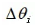 为量子旋转的角度,则量子比特的更新表示为:
为量子旋转的角度,则量子比特的更新表示为:
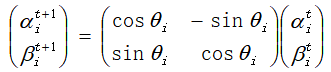
2.6 进行迭代,y=y+1
2.7 达到终止设定条件,输出最佳个体,得到最优解。
3 流程图

4 量子遗传算法——Python实现
4.1 数据

4.2 代码
-- coding: utf-8 --
#导入包==
import numpy as np
from sklearn import svm #SVM是二分类器
from sklearn import cross_validation #交叉验证(Cross Validation)用来验证分类器的性能一种统计分析方法
import random
import math
import matplotlib.pyplot as plt
#=1.导入训练数据==
def load_data(data_file):
‘’’
input: data_file(string):训练数据所在文件
output: data(mat):训练样本的特征
label(mat):训练样本的标签
‘’’
data = []
label = []
f = open(data_file)
for line in f.readlines():
lines = line.strip().split(’ ')
#=提取得出label=
label.append(float(lines[0]))
#提取出特征,并将其放入到矩阵中=
index = 0
tmp = []
for i in range(1, len(lines)):
li = lines[i].strip().split(“:”)
if int(li[0]) - 1 == index:
tmp.append(float(li[1]))
else:
while(int(li[0]) - 1 > index):
tmp.append(0)
index += 1
tmp.append(float(li[1]))
index += 1
while len(tmp) < 13:
tmp.append(0)
data.append(tmp)
f.close()
return np.array(data), np.array(label).T
#=2. QGA算法===================
class QGA(object):
#2.1 类初始化==
‘’'定义QGA类
‘’’
def init(self,population_size,chromosome_num,chromosome_length,max_value,min_value,iter_num,deta):
‘’'初始化类参数
population_size(int):种群数
chromosome_num(int):染色体数,对应需要寻优的参数个数
chromosome_length(int):染色体长度
max_value(float):染色体十进制数值最大值
min_value(float):染色体十进制数值最小值
iter_num(int):迭代次数
deta(float):量子旋转角度
‘’’
self.population_size = population_size
self.chromosome_num = chromosome_num
self.chromosome_length = chromosome_length
self.max_value = max_value
self.min_value = min_value
self.iter_num = iter_num
self.deta = deta
#2.2 种群的量子形式初始化===========
def species_origin_angle(self):
‘’'种群初始化
input:self(object):QGA类
output:population_Angle(list):种群的量子角度列表
population_Angle2(list):空的种群的量子角度列表,用于存储交叉后的量子角度列表
‘’’
population_Angle = []
for i in range(self.chromosome_num):
tmp1 = [] #存储每个染色体所有取值的量子角度
for j in range(self.population_size):
tmp2 = [] #存储量子角度
for m in range(self.chromosome_length):
a = np.pi * 2 * np.random.random()
tmp2.append(a)
tmp1.append(tmp2)
population_Angle.append(tmp1)
return population_Angle
#将初始化的量子角度序列转换为种群的量子系数列表
def population_Q(self,population_Angle):
‘’’
input:self(object):QGA类
population_Angle(list):种群的量子角度列表
output:population_Q(list):种群的量子系数列表
‘’’
population_Q = []
for i in range(len(population_Angle)):
tmp1 = [] #存储每个染色体所有取值的量子系数对
for j in range(len(population_Angle[i])):
tmp2 = [] #存储每个染色体的每个取值的量子对
tmp3 = [] #存储量子对的一半
tmp4 = [] #存储量子对的另一半
for m in range(len(population_Angle[i][j])):
a = population_Angle[i][j][m]
tmp3.append(np.sin(a))
tmp4.append(np.cos(a))
tmp2.append(tmp3)
tmp2.append(tmp4)
tmp1.append(tmp2)
population_Q.append(tmp1)
return population_Q
#2.3计算适应度函数值==========
def translation(self,population_Q):
‘’'将种群的量子列表转换为二进制列表
input:self(object):QGA类
population_Q(list):种群的量子列表
output:population_Binary:种群的二进制列表
‘’’
population_Binary = []
for i in range(len(population_Q)):
tmp1 = [] # 存储每个染色体所有取值的二进制形式
for j in range(len(population_Q[i])):
tmp2 = [] ##存储每个染色体每个取值的二进制形式
for l in range(len(population_Q[i][j][0])):
if np.square(population_Q[i][j][0][l]) > np.random.random():
tmp2.append(1)
else:
tmp2.append(0)
tmp1.append(tmp2)
population_Binary.append(tmp1)
return population_Binary
#=求适应度函数数值列表,本实验采用的适应度函数为RBF_SVM的3_fold交叉验证平均值=
def fitness(self,population_Binary):
‘’’
input:self(object):QGA类
population_Binary(list):种群的二进制列表
output:fitness_value(list):适应度函数值类表
parameters(list):对应寻优参数的列表
‘’’
#=(1)染色体的二进制表现形式转换为十进制并设置在[min_value,max_value]之间=
parameters = [] #存储所有参数的可能取值
for i in range(len(population_Binary)):
tmp1 = [] #存储一个参数的可能取值
for j in range(len(population_Binary[i])):
total = 0.0
for l in range(len(population_Binary[i][j])):
total += population_Binary[i][j][l] * math.pow(2,l) #计算二进制对应的十进制数值
value = (total * (self.max_value - self.min_value)) / math.pow(2,len(population_Binary[i][j])) + self.min_value ##将十进制数值坐落在[min_value,max_value]之间
tmp1.append(value)
parameters.append(tmp1)
#(2)适应度函数为RBF_SVM的3_fold交叉校验平均值=====
fitness_value = []
for l in range(len(parameters[0])):
rbf_svm = svm.SVC(kernel = ‘rbf’, C = parameters[0][l], gamma = parameters[1][l])
cv_scores = cross_validation.cross_val_score(rbf_svm,trainX,trainY,cv =3,scoring = ‘accuracy’)
fitness_value.append(cv_scores.mean())
#=(3)找到最优的适应度函数值和对应的参数二进制表现形式==
best_fitness = 0.0
best_parameter = []
best_parameter_Binary = []
for j in range(len(population_Binary)):
tmp2 = []
best_parameter_Binary.append(tmp2)
best_parameter.append(tmp2)
for i in range(len(population_Binary[0])):
if best_fitness < fitness_value[i]:
best_fitness = fitness_value[i]
for j in range(len(population_Binary)):
best_parameter_Binary[j] = population_Binary[j][i]
best_parameter[j] = parameters[j][i]
return parameters,fitness_value,best_parameter_Binary,best_fitness,best_parameter
#2.4 全干扰交叉===
def crossover(self,population_Angle):
‘’'对种群量子角度列表进行全干扰交叉
input:self(object):QGA类
population_Angle(list):种群的量子角度列表
‘’’
#=初始化一个空列表,全干扰交叉后的量子角度列表
population_Angle_crossover = []
for i in range(self.chromosome_num):
tmp11 = []
for j in range(self.population_size):
tmp21 = []
for m in range(self.chromosome_length):
tmp21.append(0.0)
tmp11.append(tmp21)
population_Angle_crossover.append(tmp11)
for i in range(len(population_Angle)):
for j in range(len(population_Angle[i])):
for m in range(len(population_Angle[i][j])):
ni = (j - m) % len(population_Angle[i])
population_Angle_crossover[i][j][m] = population_Angle[i][ni][m]
return population_Angle_crossover
#2.4 变异======
def mutation(self,population_Angle_crossover,population_Angle,best_parameter_Binary,best_fitness):
‘’'采用量子门变换矩阵进行量子变异
input:self(object):QGA类
population_Angle_crossover(list):全干扰交叉后的量子角度列表
output:population_Angle_mutation(list):变异后的量子角度列表
‘’’
#(1)求出交叉后的适应度函数值列表=====
population_Q_crossover = self.population_Q(population_Angle_crossover) ## 交叉后的种群量子系数列表
population_Binary_crossover = self.translation(population_Q_crossover) ## 交叉后的种群二进制数列表
parameters,fitness_crossover,best_parameter_Binary_crossover,best_fitness_crossover,best_parameter = self.fitness(population_Binary_crossover) ## 交叉后的适应度函数值列表
#(2)初始化每一个量子位的旋转角度==
Rotation_Angle = []
for i in range(len(population_Angle_crossover)):
tmp1 = []
for j in range(len(population_Angle_crossover[i])):
tmp2 = []
for m in range(len(population_Angle_crossover[i][j])):
tmp2.append(0.0)
tmp1.append(tmp2)
Rotation_Angle.append(tmp1)
deta = self.deta
#(3)求每个量子位的旋转角度====
for i in range(self.chromosome_num):
for j in range(self.population_size):
if fitness_crossover[j] <= best_fitness:
for m in range(self.chromosome_length):
s1 = 0
a1 = population_Q_crossover[i][j][0][m]
b1 = population_Q_crossover[i][j][1][m]
if population_Binary_crossover[i][j][m] == 0 and best_parameter_Binary[i][m] == 0 and a1 * b1 > 0:
s1 = -1
if population_Binary_crossover[i][j][m] == 0 and best_parameter_Binary[i][m] == 0 and a1 * b1 < 0:
s1 = 1
if population_Binary_crossover[i][j][m] == 0 and best_parameter_Binary[i][m] == 0 and a1 * b1 == 0:
s1 = 1
if population_Binary_crossover[i][j][m] == 0 and best_parameter_Binary[i][m] == 1 and a1 * b1 < 0:
s1 = -1
if population_Binary_crossover[i][j][m] == 0 and best_parameter_Binary[i][m] == 1 and a1 * b1 == 0:
s1 = 1
if population_Binary_crossover[i][j][m] == 1 and best_parameter_Binary[i][m] == 0 and a1 * b1 > 0:
s1 = -1
if population_Binary_crossover[i][j][m] == 1 and best_parameter_Binary[i][m] == 0 and a1 * b1 < 0:
s1 = 1
if population_Binary_crossover[i][j][m] == 1 and best_parameter_Binary[i][m] == 0 and a1 * b1 == 0:
s1 = -1
if population_Binary_crossover[i][j][m] == 1 and best_parameter_Binary[i][m] == 1 and a1 * b1 > 0:
s1 = 1
if population_Binary_crossover[i][j][m] == 1 and best_parameter_Binary[i][m] == 1 and a1 * b1 < 0:
s1 = -1
if population_Binary_crossover[i][j][m] == 1 and best_parameter_Binary[i][m] == 1 and a1 * b1 == 0:
s1 = 1
Rotation_Angle[i][j][m] = deta * s1
else:
for m in range(self.chromosome_length):
s2 = 0
a2 = population_Q_crossover[i][j][0][m]
b2 = population_Q_crossover[i][j][1][m]
if population_Binary_crossover[i][j][m] == 0 and best_parameter_Binary[i][m] == 0 and a2 * b2 > 0:
s2 = -1
if population_Binary_crossover[i][j][m] == 0 and best_parameter_Binary[i][m] == 0 and a2 * b2 < 0:
s2 = 1
if population_Binary_crossover[i][j][m] == 0 and best_parameter_Binary[i][m] == 0 and a2 * b2 == 0:
s2 = 1
if population_Binary_crossover[i][j][m] == 0 and best_parameter_Binary[i][m] == 1 and a2 * b2 > 0:
s2 = -1
if population_Binary_crossover[i][j][m] == 0 and best_parameter_Binary[i][m] == 1 and a2 * b2 < 0:
s2 = 1
if population_Binary_crossover[i][j][m] == 0 and best_parameter_Binary[i][m] == 1 and a2 * b2 == 0:
s2 = 1
if population_Binary_crossover[i][j][m] == 1 and best_parameter_Binary[i][m] == 0 and a2 * b2 > 0:
s2 = 1
if population_Binary_crossover[i][j][m] == 1 and best_parameter_Binary[i][m] == 0 and a2 * b2 < 0:
s2 = -1
if population_Binary_crossover[i][j][m] == 1 and best_parameter_Binary[i][m] == 0 and a2 * b2 == 0:
s2 = 1
if population_Binary_crossover[i][j][m] == 1 and best_parameter_Binary[i][m] == 1 and a2 * b2 > 0:
s2 = 1
if population_Binary_crossover[i][j][m] == 1 and best_parameter_Binary[i][m] == 1 and a2 * b2 < 0:
s2 = -1
if population_Binary_crossover[i][j][m] == 1 and best_parameter_Binary[i][m] == 1 and a2 * b2 == 0:
s2 = 1
Rotation_Angle[i][j][m] = deta * s2
#=(4)根据每个量子位的旋转角度,生成种群新的量子角度列表=========
for i in range(self.chromosome_num):
for j in range(self.population_size):
for m in range(self.chromosome_length):
population_Angle[i][j][m] = population_Angle[i][j][m] + Rotation_Angle[i][j][m]
return population_Angle
#2.5 画出适应度函数值变化图
def plot(self,results):
‘’’
画图
‘’’
X = []
Y = []
for i in range(self.iter_num):
X.append(i + 1)
Y.append(results[i])
plt.plot(X,Y)
plt.xlabel(‘Number of iteration’,size = 15)
plt.ylabel(‘Value of CV’,size = 15)
plt.title(‘QGA_RBF_SVM parameter optimization’)
plt.show()
#=2.6 主函数======
def main(self):
results = []
best_fitness = 0.0
best_parameter = []
#=种群初始化=
population_Angle= self.species_origin_angle()
#=迭代==
for i in range(self.iter_num):
population_Q = self.population_Q(population_Angle)
计算本次迭代的适应度函数值列表,最优适应度函数值及对应的参数
parameters,fitness_value,current_parameter_Binary,current_fitness,current_parameter = self.fitness(population_Binary)
找出到目前为止最优的适应度函数值和对应的参数
if current_fitness > best_fitness:
best_fitness = current_fitness
best_parameter = current_parameter
print(‘iteration is :’,i+1,‘;Best parameters:’,best_parameter,‘;Best fitness’,best_fitness)
results.append(best_fitness)
全干扰交叉
population_Angle_crossover = self.crossover(population_Angle)
量子旋转变异
population_Angle = self.mutation(population_Angle_crossover,population_Angle,current_parameter_Binary,current_fitness)
if name == ‘main’:
print(‘----------------1.Load Data-------------------’)
trainX,trainY = load_data(‘rbf_data’)
print(‘----------------2.Parameter Seting------------’)
population_size=200
chromosome_num=2
chromosome_length=20
如果你也是看准了Python,想自学Python,在这里为大家准备了丰厚的免费学习大礼包,带大家一起学习,给大家剖析Python兼职、就业行情前景的这些事儿。
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。


四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

成为一个Python程序员专家或许需要花费数年时间,但是打下坚实的基础只要几周就可以,如果你按照我提供的学习路线以及资料有意识地去实践,你就有很大可能成功!
最后祝你好运!!!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 3817
3817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









