







3、打开badboy工具,点击工具栏上的红色圆形按钮,在地址栏目中输入被试项目地址
4、录制完成后,点击工具旁边的黑色按钮,结束录制。选择“文件”–Export to Jmeter
5、打开Jmeter工具,选择“文件”–>“打开”选择刚才保存的(.jmx类型)文件,将文件导入进来。
6、演示录制
录制-代理
不推荐使用带理:
1、配置比较复杂
2、因代理的问题造成无法正常上网,甚至会重装系统。
3、仅做了解即刻。
设置代理:
1、创建一个线程组(右键点击“测试计划”—>“添加”—>“线程组”)
2、在“工作台”-非测试原件-添加“HTTP带理服务器”
3、代理服务器的端口,默认8080,可自行修改,但不要与其他应用端口冲突。
4、目标控制器:录制的脚本存放的位置,可选择项为测试计划中的线程组(根据实际情况来选择即可)。
5、分组:对请求进行分组。“分组”的概念是将一批请求汇总分组,可以把URL请求理解为组。
· “不对样本分组”:所有请求全部罗列
· “在组间添加分隔”:加入一个虚拟的以分割线命名的动作,运行通“不对样本分组”,无实际意义。
· “每个组放入一个新的控制器”:执行时按控制器给输出结果
6、“只存储每个组的第一个样本”:对于一次URL请求,实际很多次http请求的情况
7、点击“启动”
==================================================================================
1、被测试网站: xqtesting.blog.51cto.com
2、指标:响应时间及错误率
3、场景
1、测试计划
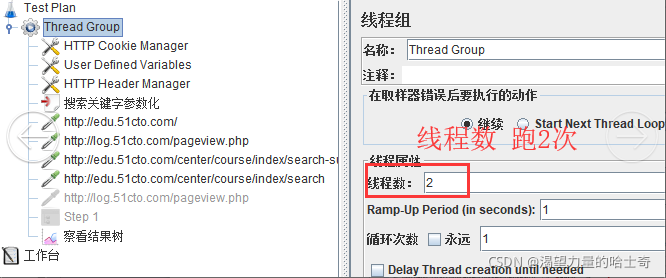
2、线程组
3、HTTP请求
4、监听器
5、运行脚本
6、查看报告

HTTP请求设置-保持默认即可
-
名称:本属性用于标识一个取样器,建议使用一个有意义的名称。
-
注释:对于测试没有任何作用,仅用户记录用户可读的注释信息
-
服务器名称或IP:HTTP请求发送的目标服务器名称或IP地址
-
端口号:目标服务器的端口号,默认值为“80”,后面的超时定义可以不用填写
-
协议:向目标服务器发送HTTP请求时的协议,可以是http亦或https,默认值是http
-
方法:发送HTTP请求的方法,可用方法包括GET、POST、HEAD、PUT、OPTIONS、TRACE、DELETE等。
-
Content encoding:内容的编码方式。
-
路径:目标URL路径(不包括服务器和端口)
-
自动重定向:如果选中该选项,当发送HTTP请求后得到的响应是302/301时,Jmeter 自动重定向到新的页面。
-
Use keep Alive:当该选项被选中时,jmeter和目标服务器之间使用 Keep-Alive方式
进行HTTP通信,默认选中。
Keep-Alive:持久长连接
-
Use multipart/form-data for HTTP POST:当发送HTTP POST请求时,使用Use multipart/form-data方法发送,默认不选中。
-
同请求一起发送参数:在请求中发送URL参数,对于带参数的URL,jmeter提供了 一个简单的对参数化的方法。用户可以将URL中所有参数设置在本表中,表中的 每一行是一个参数值对(对应RUL中的名称1=值1)
-
同请求一起发送文件:在请求中发送文件,通常,HTTP文件上传行为可以通过这 种方式模拟。
-
从HTML文件获取所有有内含的资源:当该选项被选中时,jmeter在发出HTTP请 求并获得响应的HTML文件内容后,还对该HTML进行Parse并获取HTML中包含
的所有资源(图片、flash等),默认不选中,如果用户只希望获取页面中的特定资源,可以在下方的Embedded URLs must match 文本框中填入需要下载的特定资源表达式,这样,只有能匹配制定正则表达式的URL指向资源才会被下载。
-
用作监视器:此取样器被当成监视器,在Monitor Results Listener中可以直接看到 基于该取样器的图形化统计信息。默认为不选中。
-
Save response as MD5 hash : 选中该项,在执行时仅记录服务端响应数据的MD5值,
而不记录完整的响应数据。在需要进行数据量非常大的测试时,建议选中该项以减 少取样器记录相应数据的开销。
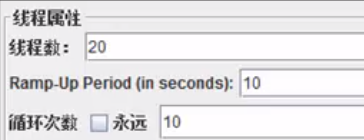
线程组属性/设置
-
线程数:虚拟用户数
-
ramp up period:设置的虚拟用户数需要多长时间全部启动。如果线程数为20,时 间为10,也就是每秒钟启动2个线程。
参考:https://blog.csdn.net/sunwangdian/article/details/50738870
-
循环次数:每个线程发送请求的次数。如果线程数为20,循环次数为100,那么每 个线程发送100次请求。总请求数为20*100=2000.如果勾选了“永远”,那么所有 线程会一致发送请求,一到选择停止运行脚本。
-
调度器:可以更灵活的设置运行时间等。
监听器-聚合报告
附:保存文件的后缀 jtl 单位:毫秒
-
Lable:定义HTTP请求名称
-
Samples:表示这次测试中一共发出了多少个请求
-
Average:平均响应时长—默认情况下是单个Request的平均响应时长,当使用了Transaction Controller时,也可以以Transaction为单位显示平均响应时长。
-
Median:中位数,也就是50%用户的响应时长。
-
90%Line:90%用户的响应时长。
-
Min:访问页面的最小响应时长。
-
Max:访问页面的最大响应时长。
-
Error%:错误请求的数量/请求的总数
-
Throughput:默认情况下表示每秒完成的请求数(Request per Second),当使用了
Transaction Controller 时,也可以表示类似 LoadRunner 的Tranaction per Second数。
- KB/Sec:每秒从服务器端接收到的数据量。
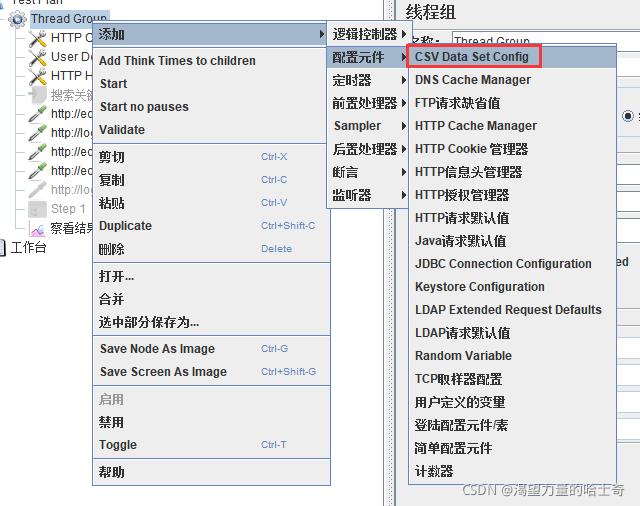
参数化的两种实现方式 用户参数 与 CSV Data Set Config
用户参数


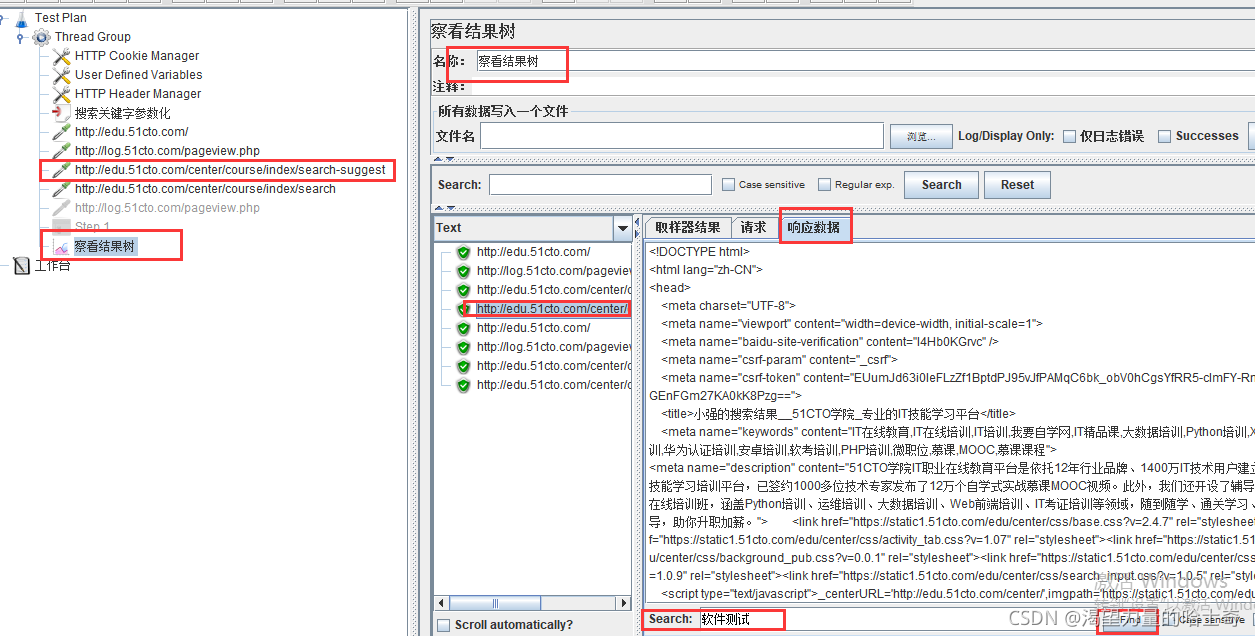
察看结果树
CSV Data Set Config

多个变量参数化与单个变量参数化的区别
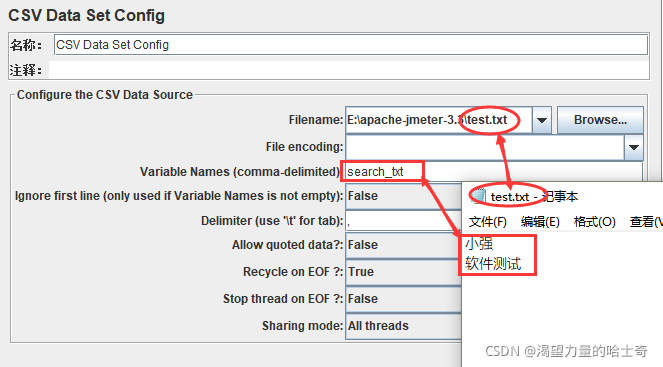
单个变量
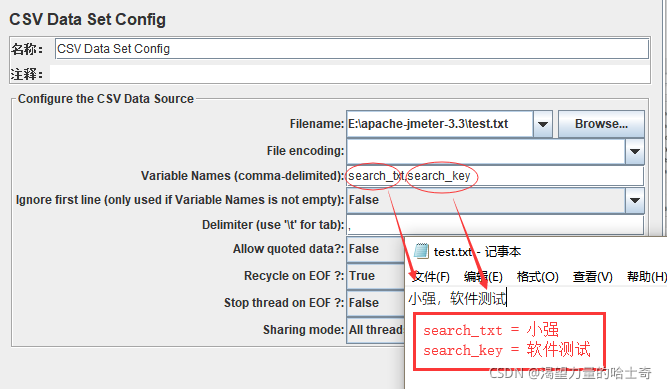
多个变量
- 多个变量的情况下,使用“,”【英文格式】逗号作为分隔符,将关键字进行分隔.
用户参数与CSV Data Set Config
关于"用户参数"与"CSV Data Set Config"哪个元件用来做参数化更有优势,没有标 准答案,"两者都可以用",主要看使用者更倾向于哪一个。
一般情况下,参数化数据量不是很大的情况下,使用用户参数更为简便些。
如果参数化数据量比较大的情况下,比如开发导出来的CSV文件,CSV Data Set Config
要比用户参数来说更有优势些。
可以理解为“增加并发、模拟并发”
定义:
简单的说,虽然我们的“性能测试”理解为“多用户并发测试”,但真正的并发是不存在的, 为了更真实的实现并发这概念,我们可以在需要压力的地方设置集合点,每到输入用户 名和密码登录时,所有的虚拟用户都相互之间等一等,然后,一起访问。
如淘宝的秒杀,多个用户同时进行一个操作。
注意:
1、jmeter集合点通过添加定时器来完成。
2、JMeter里面的集合点通过添加定时器来完成。
3、Synchronizing timer仅作用于同一个JVM中的线程。
查看下文“注意点”处的补充。
操作步骤
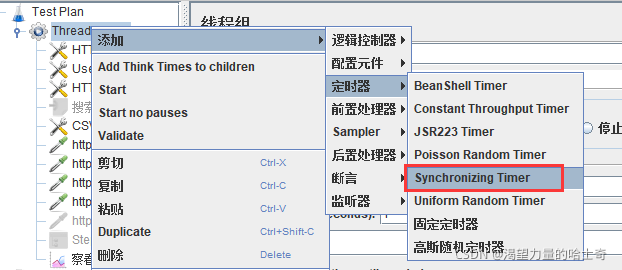
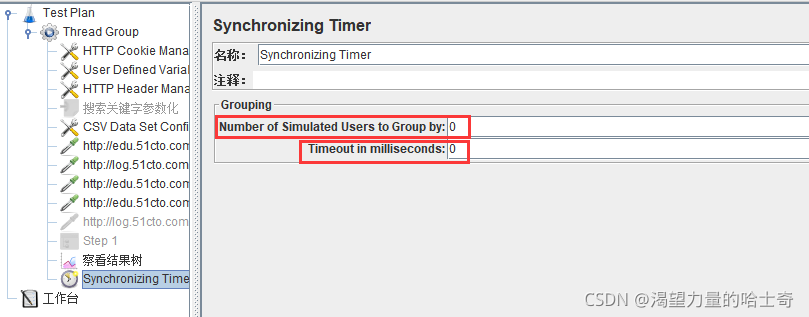
注意:
- Number of Simulated Users to Group by:
每次释放的线程数量。如果设置为0,等同于设置为线程租中的线程数量。
可理解为集合多少人后再执行请求
- Timeout in milliseconds:
如果设置为0,Timer将会等待线程数达到了"Number of Simultaneous Users to Group"中设置的值才释放。如果大于0,那么如果超过Timeout in milliseconds中设置的最大等待时间(毫秒为单位)后还没达到"Number of Simultaneous Users to Group"中设置的值,Timer将不再等待,释放已到达的线程。默认为0。
- 如果设置Timeout in milliseconds为0,且线程数量无法达到"Number of Simultaneous
Users to Group by” 中设置的值,那么Test将无限等待,除非手动终止。
作用域
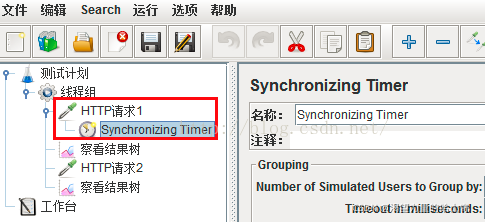
如果希望定时器仅应用于其中一个sampler,则把该定时器作为子节点加入,如下图
定时器仅仅对HTTP请求1起作用,即仅在HTTP请求1执行前执行定时器,和HTTP请 求2无关。
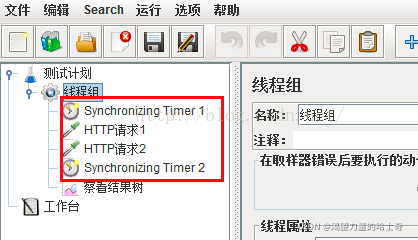
如果希望synchronizing timer应用于多个sampler.
如下,执行HTTP请求1和HTTP请求2前都会执行同步定时器1、2。当执行一个sampler 之前时,和sampler处于相同作用域的定时器都会被执行;
注意点
问:集合点的位置一定要在Sample(采样器)之前才能生效吗?
答:在Jmeter中,timer是在sampler之前执行的。不管这个定时器的位置放在sampler之 后,还是之前。当然,如果有多个timer的时候,在相同作用域下,会按上下顺序执行 timer,这个就需要慎重放置timer的顺序;不过,为了更好的可读性,还是建议将timer放在对应的sampler前面 或 子节点中;
关于Synchronizing timer补充: Synchronizing timer 仅作用于同一个JVM中的线程。
- a.如果分布式测试时
synchronizing timer作用于所有jvm,那么jvm之间或者说监控jvm 工作的部件就需要频繁通讯,确定线程的数量及状态等,然后集结了足够的线程后,又要发送信号让Jmeter来发送测试请求,中间存在延时,这样就无法模拟更真实的高并发了,而且这个东西还会消耗测试机器的一部分性能,会给测试结果带来负面影响;所以暂时是只支持控制单个jvm,如果后面有办法解决上面那些问题后,就可以实现控制多个jvm,控制总并发量;
- b.如果分布式测试
并使用了Synchronizing timer,且设置的值是小于单个jvm的线程数量;但是,较难确保所有jvm都在同一时间点集结了同样数量的线程数,这样就很难下测试结论了,因为都不知道是多少并发下的性能表现;当然了,可以将线程的启用时间拉长,并将超时时间延长,这样就很可能会与同一时刻集结到足够的线程,达到超高并发的测试;所以,分布式测试与Synchronizing timer一般不是同时使用的;如果非要用,则需要慎重设置相关参数
关于集合点,在实际应用中基本上是不用的,或者说非常少非常少用。
其实,仅仅就集合点来说,影响性能么?答案:影响。那么影响大么?答案:其实也不是太大。
因为一个系统能够承受的并发数和压力取决于两点。
- 取决于业务脚本里的思考时间
同样的并发、同样压力情况下,若思考时间不同,能够承受的压力也是不同的。
- 取决于系统真正的处理能力,或者说 TPS【系统吞吐量,亦说QPS】,TPS每秒处理的能力越高,那么处理压力的能力相对来说就会多一些。
按照Jmeter官方的翻译过来叫“断言”,其实功能与LoadRunner的“检查点”是一样 的,叫法不一样罢了(文字游戏)
断言/检查点
对响应的结果做一个判断。
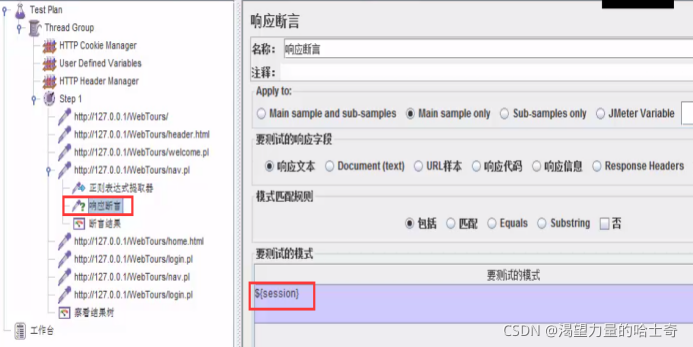
响应断言
注意点
1、模式匹配规则
2、要测试的模式
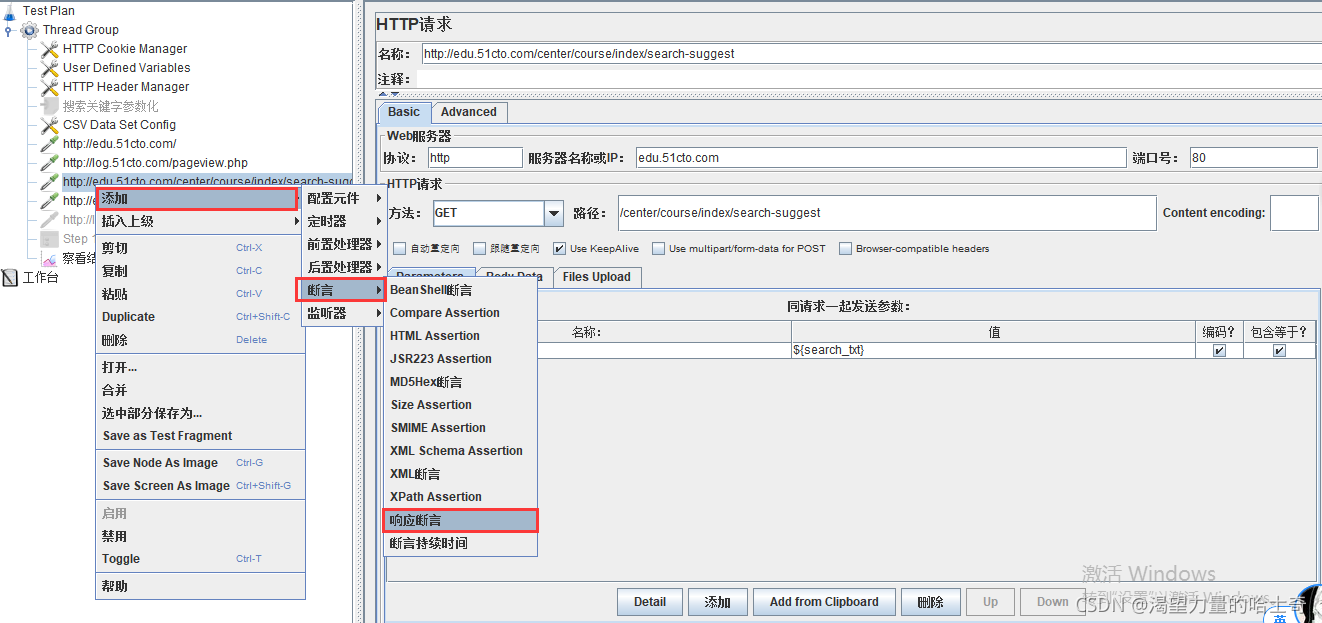
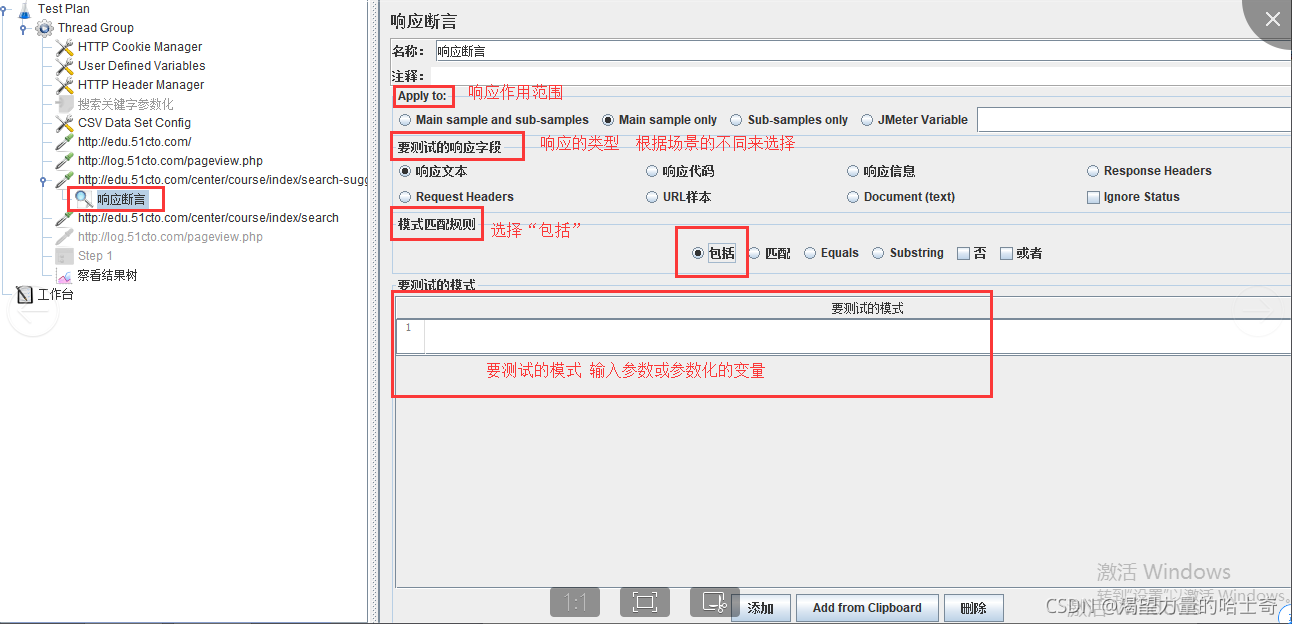
响应断言的参数
Apply to:响应作用范围
1、Main sample and sub-samples:断言应用于主采样器和子采样器。
2、Main sample only:断言仅应用于主采样器。
3、Sub-samples only:断言仅应用于子采样器。
4、Jmeter Variable:断言将被施加到命名变量的内容,变量值进行匹配
要测试的响应字段
1、响应文本:指页面返回的http文本内容 。
2、响应代码:指请求返回的状态,如200 。
3、响应信息:指请求返回的响应信息,如OK、not found 。
4、Response Headers : 响应头信息 。
5、Request Headers :请求头信息。
6、剩余几个还不了解~~
模式匹配规则:
1、包括=返回结果包括你指定的内容,支持正则匹配
2、匹配:
(1)相当于 equals 。当返回值固定时,可以返回值做断言,效果和equals相同
(2)正则匹配 。 用正则表达式匹配返回结果,但必须全部匹配。 即正则表达式 必须能匹配整个返回值,而不是返回值的一部分。
3、Equals ::返回结果与指定断言完全一致
4、SubString:与 “包括”差不多,都是指返回结果包括你指定的内容,但是SubString不支持正则字符串。
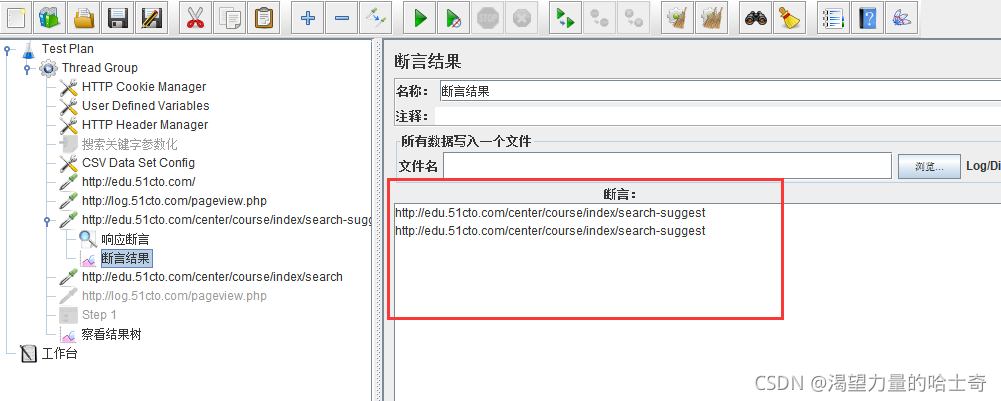
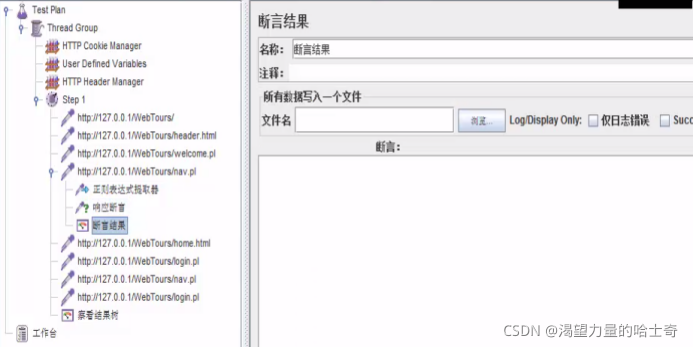
断言结果
对“响应断言”的“断言结果”进行再次的判断
增加"断言结果"
断言结果判定
- 成功
如果成功,“断言”一栏显示请求地址
- 失败
如果失败,“断言”一栏请求地址下方显示报错原因。

1、和LoadRunner中的关联差不多
2、Jmeter中关联的两种方式:正则、xpath(一般xml的时候用的多)
正则:一般用的比较多的是正则
XML:返回的数据是XML格式的情况,用XML居多
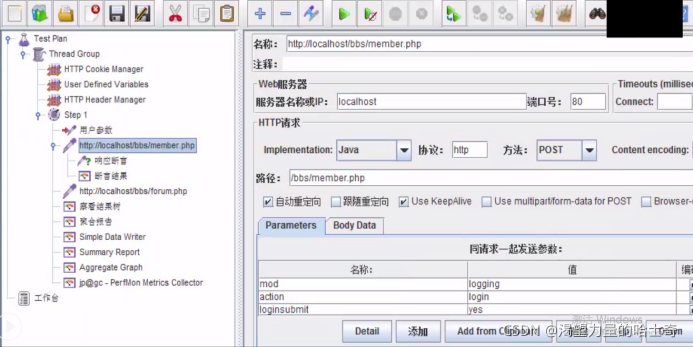
3、以webtours登录威力进行演示 webtours.jmx
webtours:LoadRunner自带的
步骤
1、webtours开启关联
2、badboy录制
3、导入Jmeter
4、找出需要关联的请求(nav.pl)
5、该请求 --> 后置处理器 --> 正则 --> 填入内容
6、增加断言
7、增加断言结果
8、运行查看
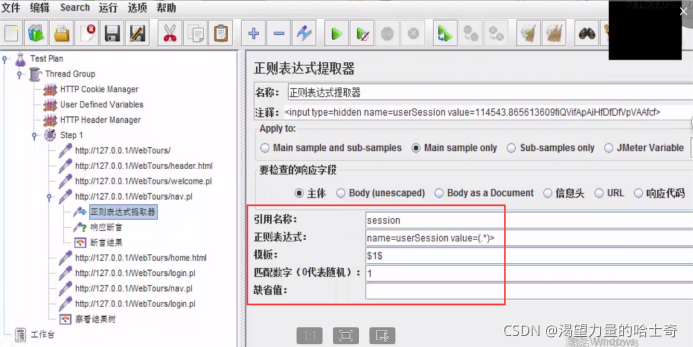
-
模板:如果前面的正则表达式取了不止一个参数,那么这里需要制定参数的组别,如果该参数为 1 1 1,则表示取得第一个值, 2 2 2表示取得第二个值
-
匹配数字:0随机; -1取所有值,以数组形式存储; 1; 2…
-
缺省值:一般默认即可(为空)
项目背景
-
XX网站
-
环境:Windows
需求
- 并发登录的性能
场景
-
1s增加2个线程;运行2000次。
-
分别查看20、40、60并发下的表现
监控
-
成功率、响应时间、标准差、CPU、MEM、IO等
-
资源监控需要在Windows / Linux下部署监控agent (server agent)
步骤
-
badboy录制
-
导入jmeter
-
参数化、检查点、集合点
-
指标监控,资源监控
-
报告(可导出到xls,然后自行生成报表)
-
演示login.jmx
注意点
关于 “聚合报告 --> 响应数据” 中文乱码解决方法
监控内存及CPU等(jconsole)
最近逛论坛的时候,发现了一个比较好的监控内存CPU等的小工具,本着开源小工具多 多益善的原则,记录一下。
打开这个小工具的步骤很简单,如果你已经配置好了Jmeter运行的环境,那么你也就 不用去做其他的配置,直接 点击:开始——》运行——》输入cmd——》然后在出现的 命令行界面输入“jconsole”即可弹出一个【java监视和管理控制台】
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1613
1613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









