







最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
目录
元素定位
导包
element系列
1、find_element_by_id()
2、find_element_by_name()
3、find_element_by_class_name()
4、find_element_by_xpath()
5、find_element_by_tag_name()
6、find_element_link_text()
7、find_element_by_partial_link_text()
8、find_element_by_css_selector()
elements系列
JS元素定位
window.location 对象
元素定位
更改元素属性值
页面滚动条
等待时间
强制等待
隐式等待
显示等待
EC模块
搭配显示等待扩展
无头模式
窗口切换
设置窗口大小
多窗口切换
iframe
弹窗处理
鼠标键盘操作
键盘操作
鼠标操作
结语
元素定位
====
小北在这里用的是PyCharm写的selenium,至于怎么下载怎么用,我推荐https://www.runoob.com/w3cnote/pycharm-windows-install.html,至于selenium包怎么下载使用,如果你用的是PyCharm,那就直接导入吧,下面我会讲明白的。
元素定位有很多种,需要根据不同的情况使用不同的方法,主要还是看个人兴趣,以及需求啦。我们一个个来看
导包
–
这一切的一切,还是从头开始。先说说下载selenium包,并导入这一些列的基础写法:
from selenium import webdriver
这一代码是从selenium中导入webdriver的包,第一次使用输入进去之后pycharm会提示你,也就是在selenium下面会有一条红线,这时候我们只需要点击它,把鼠标放上去就可以看到
然后我们点击Install package selenium即可,等带一分钟左右,红线就会消失。
element系列
| id | find_element_by_id() |
| name | find_element_by_name() |
| class_name | find_element_by_class_name() |
| xpath | find_element_by_xpath() |
| tag_name | find_element_by_tag_name() |
| link_text | find_element_link_text() |
| partial_link_text | find_element_by_partial_link_text() |
css_selector | find_element_by_css_selector() |
这就是八种基本定位方式,有一些也不是常用的,不是因为别的,只是因为在较多的时候元素不止一种,且同一种元素一个页面有可能不止一个,所以不能很好的快速定位,也就不是常用的了。
接下来就拿各种实际例子解释吧。
1、find_element_by_id()
按下F12,在百度界面的数据框内点击右键,点击检查,就可以看到一些列的元素属性。

如果你想看到百度一下按钮的元素属性可以通过检查来看到。

通过这张图可以看到这,输入款的元素属性有id,有name,还有很多七七八八的,我们先看id,通过find_element_by_id()来定位它。
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://baidu.com’)
fox.find_element_by_id(‘kw’).send_keys(‘python’)
fox.find_element_by_id(‘su’).click()
我们需要实例化驱动,也就是webdriver,selenium只是一个库,我们需要通过实例化来调用这个库中的属性,也就是一系列的元素定位方式,所以fox = webdriver.Firefox()必不可少,你也可以通过谷歌,IE什么的浏览器都可以,首先要保证的是驱动跟浏览器版本一致。
fox.get(),是你想要打开的网址,有了这两步,接下来就可以元素定位了,我定位了百度输入框。
怎么样才知道定位了?所以我加上了.send_keys(),输入内容的意思,在里面你可以写入你想要输入的内容,字符串形式的。然后我又定位了百度一下按钮,用了.click()方法,点击的意思,就是在输入内容后,点击百度一下开始搜索。效果如下:
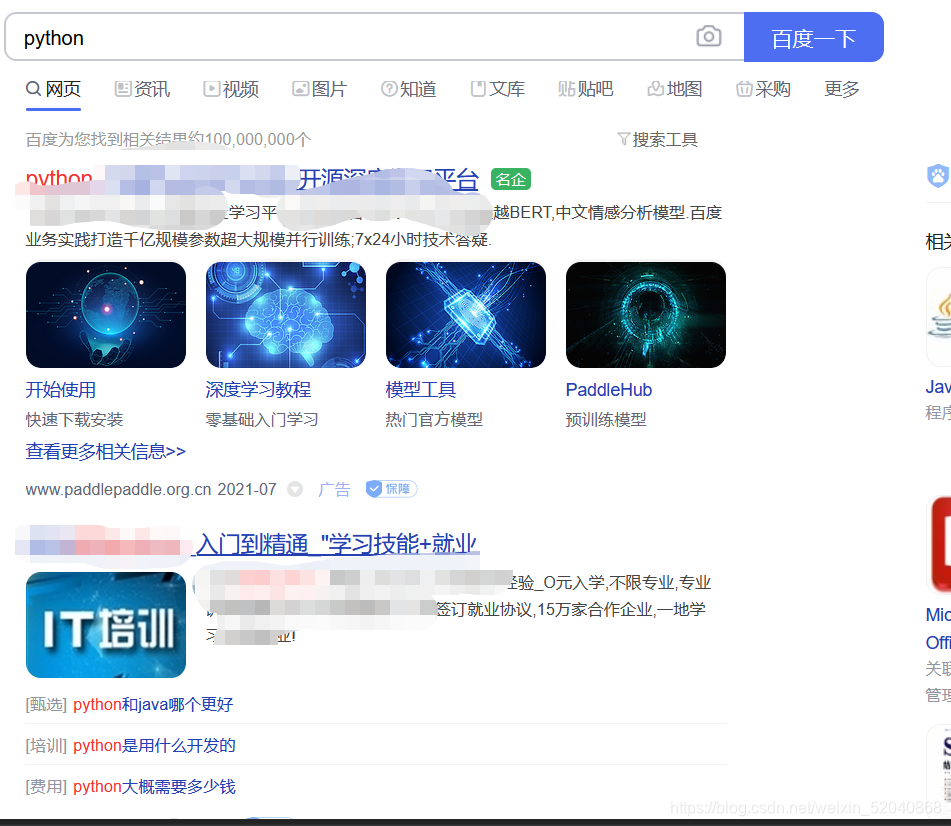
2、find_element_by_name()
在id定位方式中解释了比较清楚了,接下来就直接看吧,跟着来写。

from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://baidu.com’)
fox.find_element_by_name(‘wd’).send_keys(‘python’)
fox.find_element_by_id(‘su’).click()
3、find_element_by_class_name()

from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://www.taobao.com/’)
fox.find_element_by_class_name(‘search-combobox-input’).send_keys(‘python’)
4、find_element_by_xpath()
xpath是一种万能的定位方式,当时也有不好的地方,比如下述的例子,一个xpath定位代码很短,一个却很长,所以 ,有其他定位方式的时候优先选择。
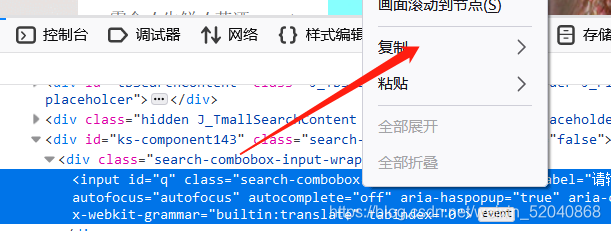
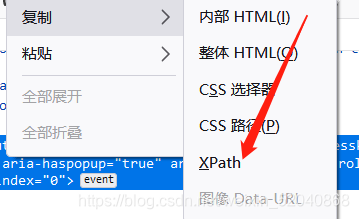
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://www.taobao.com/’)
fox.find_element_by_xpath(‘//*[@id=“q”]’).send_keys(‘python’)
fox.find_element_by_xpath(‘/html/body/div[2]/div/div/div[2]/div/div[1]/div[2]/form/div[1]/button’).click()
5、find_element_by_tag_name()
这个定位方式很少用到,用来定位元素标签的,而元素标签定位起来范围较广,定位效率低,什么样的是元素标签,如input,div,li,ul等,这些在一个页面中出现概率极为频繁。这里就不为大家解释图了,直接上代码,写法类似。下属代码只是示例代码不是实例!!!
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://www.taobao.com/’)
fox.find_elements_by_tag_name(‘input’).send_keys(‘python’)
6、find_element_link_text()
这个方法可以更具文本来定位,但是需要一个较为完整的一段文字

在这里定位一个新闻:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get(‘http://news.baidu.com/’)
driver.find_element_by_link_text(‘广州地铁十三号线二期西洲站封顶’).click()
7、find_element_by_partial_link_text()
这个方法可以更具文本来定位,并且只需要较为关键的文字即可,同上述有所区别,但是也有些相似。

在这里定位一个热点要闻。热点要闻图片会被禁掉所以这里就不那么…你们懂的。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get(‘http://news.baidu.com/’)
driver.find_element_by_partial_link_text(‘共同和谱写’).click()
8、find_element_by_css_selector()
css定位也是也不错的东西,我个人认为可以适当的使用。
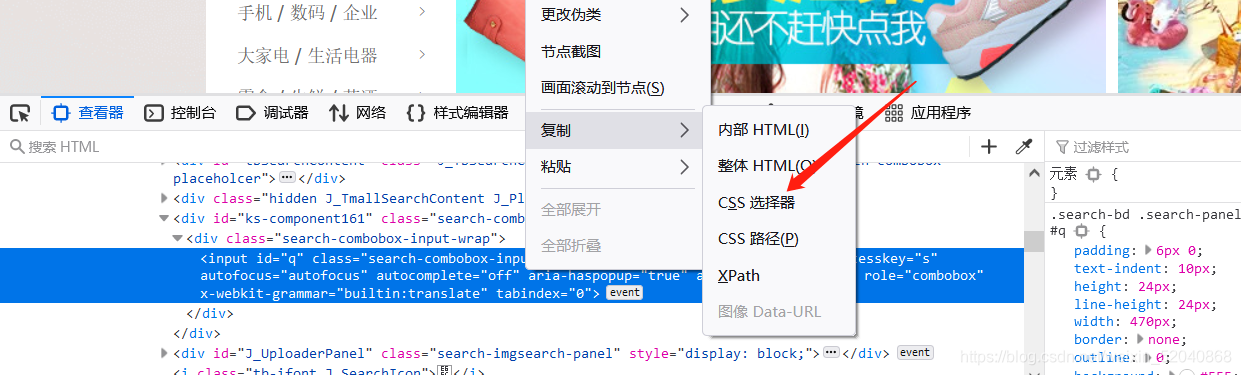
from selenium import webdriver
driver = webdriver.Firefox()
driver.get(‘https://www.taobao.com/’)
driver.find_element_by_css_selector(‘#q’).send_keys(‘python’)
elements系列
| id | find_elements_by_id() |
| name | find_elements_by_name() |
| class_name | find_elements_by_class_name() |
| xpath | find_elements_by_xpath() |
| tag_name | find_elements_by_tag_name() |
| link_text | find_elements_link_text() |
| partial_link_text | find_elements_by_partial_link_text() |
css_selector | find_elements_by_css_selector() |
显而易见elements定位与element的定位方式有一些细微的区别,举一个例子,其用法相差不大。这里需要用到列表取值,也就是索引值。我定位hao123:
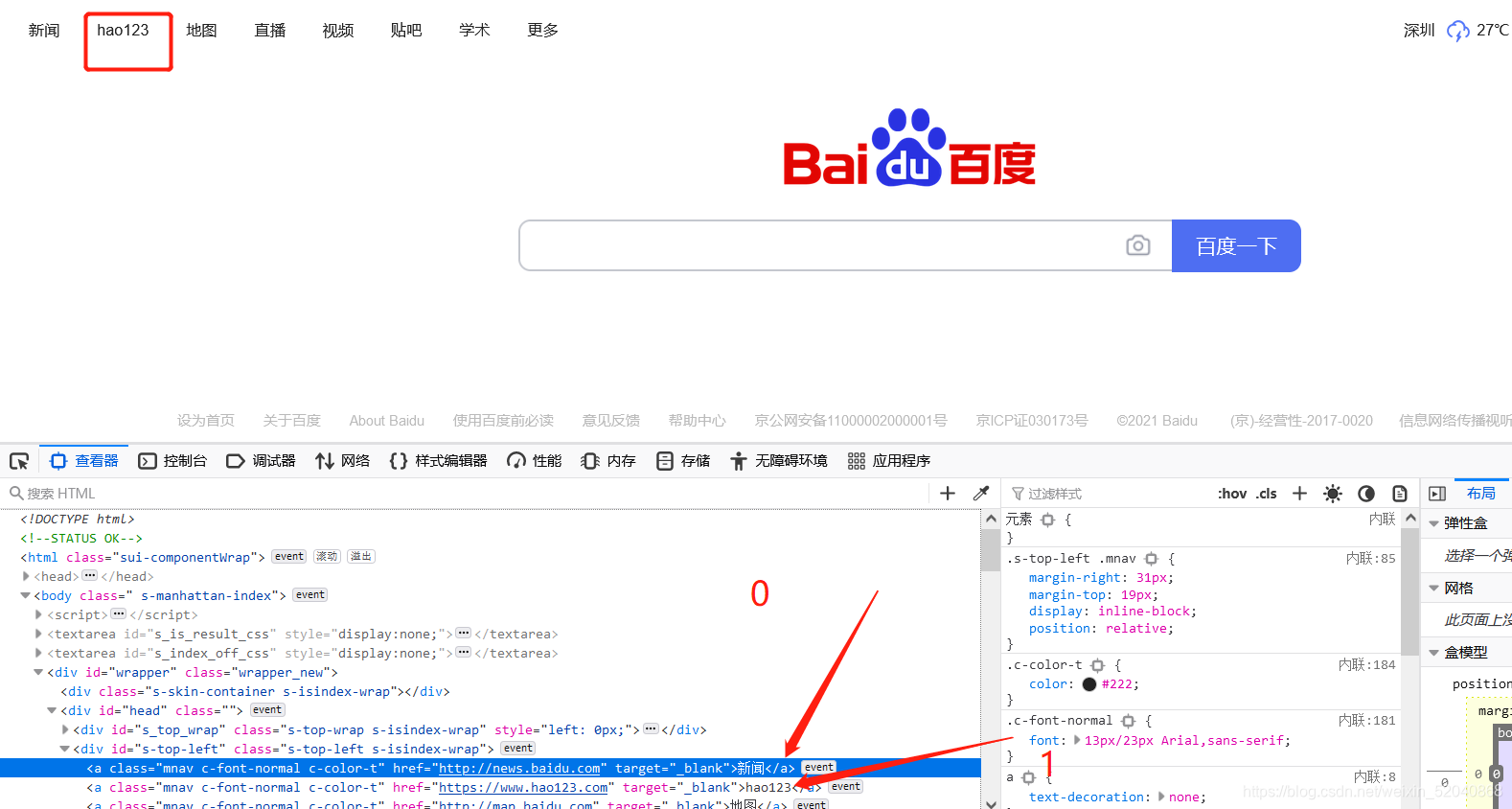
from selenium import webdriver
driver = webdriver.Firefox()
driver.get(‘https://www.baidu.com/’)
driver.find_elements_by_class_name(‘mnav’)[1].click()
对于元素组定位我不建议使用xpath等指定定位方法,更建议去定位一个标签的元素名,然后通过列表取值,不过没关系,后面学习的内容经过结合使用,你可以想用什么定位就用什么定位,对于上述例子而已你可以使用鼠标定位的方式去进行点击,使用JS或者jQuery的方式进行点击。
JS元素定位
JS定位也是一个不错的方法,就是麻烦了点,不过也是比较实用的。
先看基础的:
1. 获取内部宽高属性:innerHeight,innerWidth 单位:px(像素) 内部宽高:是指除去菜单栏、工具栏、边框等占位元素后,用于显示网页的净宽高 • window.innerHeight - 浏览器窗口的内高度(以像素计) • window.innerWidth - 浏览器窗口的内宽度(以像素计)
2. 获取外部宽高属性:outerHeight,outerWidth 单位:px(像素) • window.outerHeight 浏览器窗口的外部高度(以像素计) • window.outerWidth 浏览器窗口的外部宽度(以像素计)
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://baidu.com’)
打印内宽,内高
js_ih = ‘return window.innerHeight’
js_iw = ‘return window.innerWidth’
i = fox.execute_script(js_ih)
o = fox.execute_script(js_iw)
print(i,o)
上述代码使用看JS代码打印出了内宽、高,也可以打印外框高,但是需要使用专门的JS写法。需要给定一个返回值,并使用execute_script()进行处理。
另外还有一些其他的操作,如:
新窗口打开链接,此操作与fox.get类似,但是是在原来的基础上打开一个新的窗口
js = “window.open(‘http://baidu.com’)”
关闭一个新的窗口
js_c = ‘window.close()’
fox.execute_script(js_c)
window.location 对象
window.location 对象可不带 window 前缀书写
1. window.location.href 返回当前页面的 href (URL)
2. window.location.hostname 返回 web 主机的域名
3. window.location.pathname 返回当前页面的路径或文件名
4. window.location.protocol 返回使用的 web 协议(http: 或 https:)
5. selenium执行js语句
• driver.execute_script(js) js:就是值js的语句
• 要想获得js的返回值,必须在js语句前加上return
• js_url= “return location.href” • baidu_url=driver.execute_script(js_url)
上述这些,主要用于判断或验证某些标题,地址等可以用到:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get(‘https://baidu.com/’)
#存储所有的js语句
js1=[‘return location.href’,‘return location.hostname’,‘return location.port’,‘return location.title’]
#获取url
url=driver.execute_script(js1[0])
#获取域名
hostname=driver.execute_script(js1[1])
#获取port,返回URL服务器使用的端口号
port=driver.execute_script(js1[2])
#获取title
title1=driver.execute_script(js1[3])
print(“url:{}\nhostname:{}\nport:{}\ntitle:{}”
.format(url,hostname,port,title1))
我将想要获取的值存入了一个列表,通过列表取值的方法拿到对应想要的值。
location的对象方法
indow.location 对象可不带 window 前缀书写
1. location.assign(url) 加载新页面
2. location.reload() 重新加载当前页面,刷新
3. location.replace(url) 用输入的url替换当前的url
assign与replace的区别:
1. location.assign(url) : 加载 URL 指定的新的 HTML 文档。就相当于一个链接,跳转到指定的url,当前页 面会转为新页面内容,可以点击后退返回上一个页面。
2. location.replace(url) : 通过加载 URL 指定的文档来替换当前文档,这个方法是替换当前窗口页面,前 后两个页面共用一个窗口,所以是没有后退返回上一页的
用法介绍
js_left_r = ‘window.location.reload()’
fox.execute_script(js_left_r)
元素定位
id定位:document.getElementById()
name定位:document.getElementsByName()
tag定位:document.getElementsByTagName()
class定位:document.getElementsByClassName()
css定位:document.querySelectorAll()
对于定位,JS与CSS这两者不做推荐,在合适的时候使用合适的方法就好,能精准的定位,完成项目所需才是重点:这里也是拿百度搜索界面举的例子,用的是JS语法,我个人觉得元素定位用JS属实有些麻烦,但是JS在特定的时候还是挺方便的。
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘http://baidu.com’)
js_input = “document.getElementById(‘kw’).value=‘python’”
fox.execute_script(js_input)
jx_click = “document.getElementById(‘su’).click()”
fox.execute_script(jx_click)
于其他的doucument.getElementsByName()等元素等位方法,唯一特殊的就是doucument.querySelectorAll(),这个于selenium的css元素定位相似,都是通过css选择器定位。这里定位后获取该元素的文本值。
doucument.querySelectorAll()
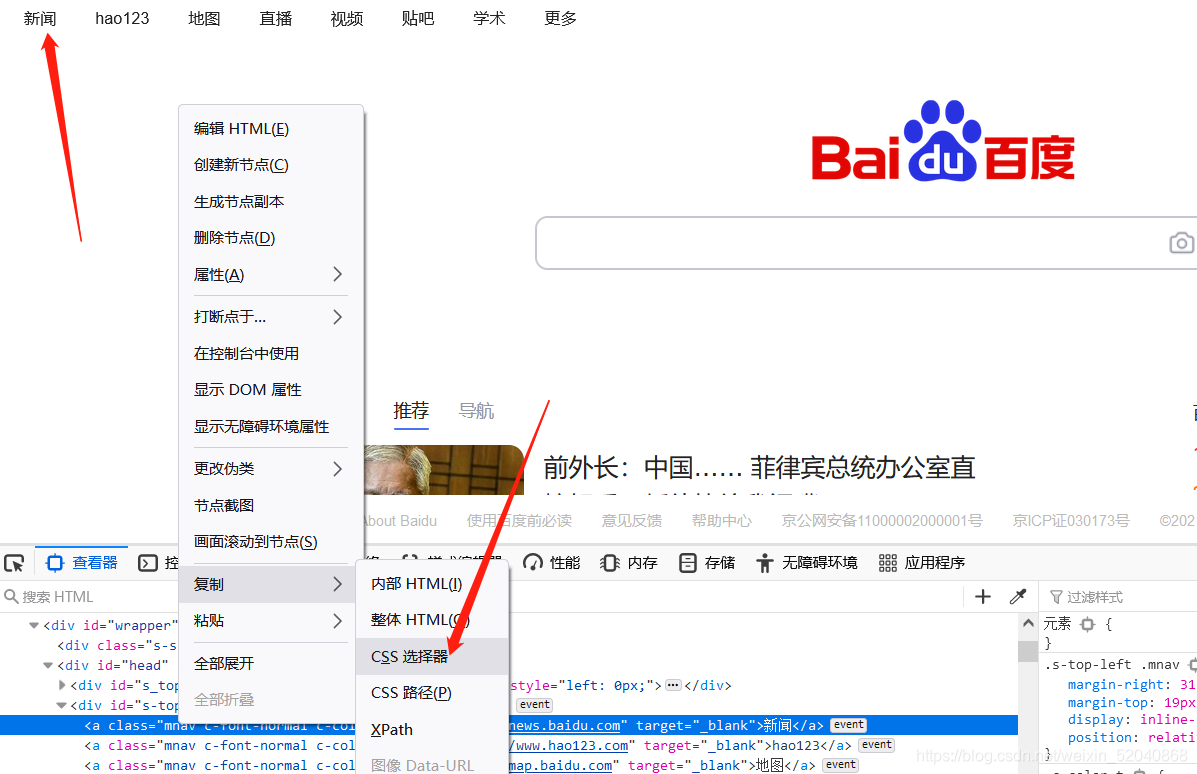
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://baidu.com’)
获取当前页面的标题
i = fox.execute_script(‘return document.title’)
print(i)
获取该元素的文本值
js_input = ‘return document.querySelector(“a.mnav:nth-child(1)”).textContent’
i = fox.execute_script(js_text)
print(i)
document.getElementsByClassName

这里可以看到它的class属性,也可以定位标签span,看个人爱好,两者不论用JS哪种方法都需要索引取值,如果说你觉的太麻烦就用doucument.querySelectorAll(),右击选择CSS选择器吧,这是万能的然而也不是万能的,后续慢慢体会,不过推荐对于没有id/name/classname属性使用。
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://baidu.com’)
js_text = “return document.getElementsByClassName(‘title-content-title’)[0].click()”
fox.execute_script(js_text)
更改元素属性值
1. document.getElementById(‘kw’).autocomplete= ‘off’ --常用元素属性修改
2. document.getElementById(‘vip’).style.visibility= ‘visible’ --设置元素的隐藏属性,是否显示visibility:hidden(隐藏),visible(显示) display : none(隐藏),block(显示)
4. document.querySelector(‘#train_date’).readOnly=false --修改元素的只读属性
修改元素属性值及其文本值

from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://baidu.com’)
s_input = “return document.querySelector(‘a.mnav:nth-child(1)’).text = ‘NEWS’”
fox.execute_script(s_input)
js_input = “document.getElementById(‘kw’).autocomplete=‘on’”
fox.execute_script(js_input)

隐藏天猫的图标:
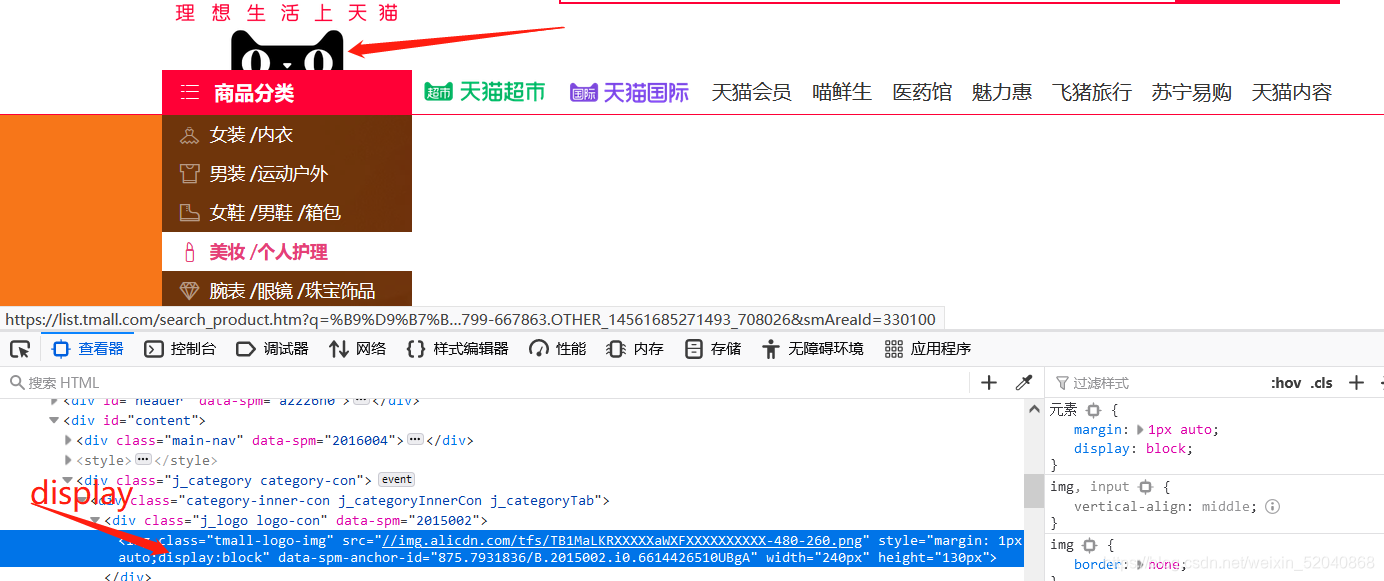
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://www.tmall.com/’)
tm = “document.querySelector(‘.tmall-logo-img’).style.display=‘none’”
fox.execute_script™
12306出发日期只读可选,修改成可写,

注意大小写,readOnly
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://www.12306.cn/’)
tm = “document.getElementById(‘train_date’).readOnly=false”
fox.execute_script™

页面滚动条
因为如果页面没有完全显示,element如果是在下拉之后才能显示出来,只能先滚动到该元素才能进 行click,否则是不能click
1. document.body.scrollHeight 获取对象的滚动高度
2. document.body.scrollWidth 获取对象的滚动宽度
3、window.scrollTo(x,y) 方法可把内容滚动到指定的坐标。
动到页面底部
1. 左下角:window.scrollTo(0,document.body.scrollHeight)
2. 右下角:window.scrollTo(document.body.scrollWidth,document.body.scrollHeight)
3. 指定位置:window.scrollTo(0,数值)
4. 滑动到指定元素:ele.srollIntoView() true:与元素顶部对其,false:与元素底部对齐
document.querySelector(‘’).scrollIntoView(false)
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://www.taobao.com/’)
fox.maximize_window()
打印页面高度
js_height = “return document.body.scrollHeight”
height = fox.execute_script(js_height)
print(height)
打印页面宽度
js_width = “return document.body.scrollWidth”
width = fox.execute_script(js_width)
print(width)
下滑1000px
js_left = “window.scrollTo(0,1000)”
fox.execute_script(js_left)
下滑最底部
jx_left_down = “window.scrollTo(0,document.body.scrollHeight)”
fox.execute_script(jx_left_down)
下滑到指定元素
jx_left_zd = “document.querySelector(‘ul.list > a:nth-child(3) > div:nth-child(1) > div:nth-child(2)’).scrollIntoView(false)”
fox.execute_script(jx_left_zd)
如果是页面内部的滚动条,那就直接上元素定位,ele是元素定位赋的变量。这里实在没找到例子,了解一下。
1. ele.scrollHeight # 获取滚动条高度
2. ele.scrollWidth # 获取横向滚动条宽度
3. ele.scrollTo(x,y) #滑动到指定坐标位置
4. ele.scrollTop=1000 #控制纵向滚动条位置,距离y轴原点的距离
5. ele.scrollLeft=1000 # 控制横向滚动条位置,距离x轴原点的距离
等待时间
====
等待时间有三类,隐式等待,显示等待,强制等待,各有个的好处,且可以搭配使用,等待时间的统一好处就是帮助你更好的定位元素,有时候网络慢了,元素没有加载出来,或者想看看具体的点击操作等,等待时间都可以帮助你解决。
隐式等待不需要额外导包,强制等待与显示等待需要额外导包,看例子
强制等待
最简单的一种办法就是强制等待sleep(X),强制让浏览器等待X秒,不管当前操作是 否完成,是否可以进行下一步操作,都必须等X秒的时间。
import time
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘http://www.baidu.com’)
强制等待2S
time.sleep(2)
退出浏览器
fox.quit()
这里新介绍了一个方法,.quit(),退出的意思,这里导入了一个time,用去强制等待2S,2S后自动退出浏览器。强制等待还有一种写法,较为简便:
from time import sleep
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘http://www.baidu.com’)
强制等待2S
sleep(2)
退出网址
fox.quit()
效果是一样的,在后续就不需要每次都time.sleep()了。
缺点:
1. 不能准确把握需要等待的时间(有时操作还未完成,等待就结束了,导致报错;有时操作已经 完成了,但等待时间还没有到,浪费时间)
2. 如果在用例中大量使用,会浪费不必要的等待时间,影响测试用例的执行效率。
优点:
1. 使用简单,可以在调试时使用
隐式等待
对其设置了一个最长等待时间,如果在规定时间内网页加载完成,则执行 下一步,否则一直等到时间结束,然后执行下一步操作
from selenium import webdriver
fox = webdriver.Firefox()
隐式等待5S
fox.implicitly_wait(5)
fox.get(‘http://www.baidu.com’)
退出网址
fox.quit()
隐式等待5S,这里的例子比较简单,可能你看到的就是刚刚打开就自动退出。
缺点:
1. 使用隐式等待,程序会一直等待整个页面加载完成,才会执行下一步操作;但有时候页面想 要的元素早已经加载完成了,但是因为网页上个别元素还没有加载完成,仍要等到页面全部 完成才能执行下一步,使用也不是很灵活。
2. 在等待时间内页面没有加载完成,时间一到也会进入下一步操作;这种情况可能出现要定位 的元素没有出现,从而报元素无法找到的错误。
优点:
1. 隐性等待对整个driver的周期都起作用,每一次操作都会调用隐式等待,所以只要设置一次 即可
显示等待
程序每隔X秒看一眼,如果条件成立了,则执行下一步,否则继续等待,直到超 过设置的最长时间,然后抛出TimeoutException异常
显示等待一般性结合until来使用,until结合匿名函数lambda来使用,有些人就会问为什么要这样呢,因为显示等待搭配起来可以做更多的工作 ,相对于其他两种等待方式,显示等待可以做的工作超乎你的想象。甚至可以直接作为断言来使用。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
fox = webdriver.Firefox()
fox.get(‘https://baidu.com’)
fox.find_element_by_id(‘kw’).send_keys(‘python’)
fox.find_element_by_id(‘su’).click()
ele = ‘/html/body/div[1]/div[4]/div[1]/div[3]/div[3]/h3/a’
驱动,最大等待时间,检测时间间隔,超时后异常信息
wait = WebDriverWait(fox,10,0.5)
判断一个元素是否在存在界面上,message表示若定位不到这个元素啧给出提示信息
l = wait.until(lambda x:x.find_element_by_xpath(ele).is_displayed(),message = ‘无此定位’)
print(l)
.is_displayed() # 元素是否显示,返回True
.is_selected() # 元素是否被选中,返回False
.is_enabled() # 元素是否可用,返回True
退出网址
fox.quit()
这里的message作用就是,当你元素无法定位的时候控制台就会提示你此消息。
缺点:
1. 使用相对比较复杂;
2. 和强制等待类似,每一行等待只执行一次,如果要进行多个元素的等待,则需要多次写入 优点:
1. 等待判断准确,不会浪费多余的等待时间,在用例中使用,可以提高执行效率。
三种等待时间就介绍完了,等待时间是可以互相通用的,隐式等待过程中,你可以加入强制等待,在写项目的过程中,你可以定义一个隐式等待,必要的时候给定强制等待,用显示等待来做一个断言。用多了就知道哪个地方该用什么样的等待时间了。
EC模块
====
EC全名expected_conditions,因为名字太长,很多人都直接将其简写,所以导入包的过程中改名为EC了 。
简介:
expected_conditions是Selenium的一个模块,主要用于对页面元素的加载进行判断,包括元素是否 存在,可点击等等。
Expected Conditions的使用场景一版有两种:
1. 直接在断言中使用
2. 与WebDriverWait配合使用,显示等待页面上元素出现或者消失
写法
1、EC.方法(参数)(driver) ,包含True,不包含False
2、EC.方法(参数).__call__(driver),包含True,不包含False
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
fox = webdriver.Firefox()
fox.get(‘https://www.baidu.com’)
判断标题是否等于百度一下
see = EC.title_is(‘百度一下,你就知道’)(fox)
print(see)
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 49万+
49万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









