







ALTER TABLE Persons
ADD UNIQUE (P_Id)
3)已创建的表中删除unique约束
ALTER TABLE Persons
DROP INDEX uc_PersonID
3)primary key 约束
作用:
- PRIMARY KEY 约束唯一标识数据库表中的每条记录。
- 主键必须包含唯一的值。
- 主键列不能包含 NULL 值。
- 每个表都应该有一个主键,并且每个表只能有一个主键。
实例:
1)创建表时添加primary key 约束:
--mysql
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (P_Id)
)
--SQL Server / Oracle / MS Access:
CREATE TABLE Persons
(
P_Id int NOT NULL PRIMARY KEY,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
2)已创建的表添加primary key 约束
ALTER TABLE Persons
ADD PRIMARY KEY (P_Id)
3)已创建的表中删除primary key 约束
ALTER TABLE Persons
DROP PRIMARY KEY
4)foreign key 约束
作用:
- 一个表中的 FOREIGN KEY 指向另一个表中的 UNIQUE KEY(唯一约束的键)。
- FOREIGN KEY 约束用于预防破坏表之间连接的行为。
- FOREIGN KEY 约束也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一。
实例:
“Persons” 表:
| P_Id | LastName | FirstName | Address | City |
|---|---|---|---|---|
| 1 | Hansen | Ola | Timoteivn 10 | Sandnes |
| 2 | Svendson | Tove | Borgvn 23 | Sandnes |
| 3 | Pettersen | Kari | Storgt 20 | Stavanger |
“Orders” 表:
| O_Id | OrderNo | P_Id |
|---|---|---|
| 1 | 77895 | 3 |
| 2 | 44678 | 3 |
| 3 | 22456 | 2 |
| 4 | 24562 | 1 |
- “Orders” 表中的 “P_Id” 列指向 “Persons” 表中的 “P_Id” 列。
- “Persons” 表中的 “P_Id” 列是 “Persons” 表中的 PRIMARY KEY。
- “Orders” 表中的 “P_Id” 列是 “Orders” 表中的 FOREIGN KEY。
1)创建表时添加foreign key 约束:
--mysql
CREATE TABLE Orders
(
O_Id int NOT NULL,
OrderNo int NOT NULL,
P_Id int,
PRIMARY KEY (O_Id),
FOREIGN KEY (P_Id) REFERENCES Persons(P_Id)
)
--SQL Server / Oracle / MS Access:
CREATE TABLE Orders
(
O_Id int NOT NULL PRIMARY KEY,
OrderNo int NOT NULL,
P_Id int FOREIGN KEY REFERENCES Persons(P_Id)
)
2)已创建的表添加foreign key 约束
ALTER TABLE Orders
ADD FOREIGN KEY (P_Id)
REFERENCES Persons(P_Id)
3)已创建的表中删除foreign key 约束
ALTER TABLE Orders
DROP FOREIGN KEY fk_PerOrders
5)check 约束
作用:
- CHECK 约束用于限制列中的值的范围。
- 如果对单个列定义 CHECK 约束,那么该列只允许特定的值。
- 如果对一个表定义 CHECK 约束,那么此约束会基于行中其他列的值在特定的列中对值进行限制。
实例:
1)创建表时添加check 约束:
--mysql
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
CHECK (P_Id>0)
)
--SQL Server / Oracle / MS Access:
CREATE TABLE Persons
(
P_Id int NOT NULL CHECK (P_Id>0),
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
2)已创建的表添加check 约束
ALTER TABLE Persons
ADD CHECK (P_Id>0)
3)已创建的表中删除check 约束
ALTER TABLE Persons
DROP CHECK chk_Person
6)default 约束
作用:
- DEFAULT 约束用于向列中插入默认值。
- 如果没有规定其他的值,那么会将默认值添加到所有的新记录。
实例:
1)创建表时添加default 约束:
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255) DEFAULT 'Sandnes'
)
2)已创建的表添加default 约束
ALTER TABLE Persons
ALTER City SET DEFAULT 'SANDNES'
3)已创建的表中删除default 约束
ALTER TABLE Persons
ALTER City DROP DEFAULT
14.create index 语句
作用:
- CREATE INDEX 语句用于在表中创建索引。
- 在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据。
- 可以在表中创建索引,以便更加快速高效地查询数据。
- 用户无法看到索引,它们只能被用来加速搜索/查询。
语法:
--在表上创建一个简单的索引。允许使用重复的值:
CREATE INDEX index_name
ON table_name (column_name)
--在表上创建一个唯一的索引。不允许使用重复的值
CREATE UNIQUE INDEX index_name
ON table_name (column_name)
实例:
1)在 “Persons” 表的 “LastName” 列上创建一个名为 “PIndex” 的索引:
CREATE INDEX PIndex
ON Persons (LastName)
2)如果您希望索引不止一个列,您可以在括号中列出这些列的名称,用逗号隔开:
CREATE INDEX PIndex
ON Persons (LastName, FirstName)
15.SQL drop
作用:
- 通过使用 DROP 语句,可以轻松地删除索引、表和数据库。
语法:
-----DROP INDEX 语句用于删除表中的索引。
--MS Access
DROP INDEX index_name ON table_name
--DB2/Oracle
DROP INDEX index_name
-- MS SQL Server
DROP INDEX table_name.index_name
--MySQL
ALTER TABLE table_name DROP INDEX index_name
----DROP TABLE 语句用于删除表。
DROP TABLE table_name
----DROP DATABASE 语句用于删除数据库。
--DROP DATABASE database_name
----只删除表中的数据,不删除表本身
TRUNCATE TABLE table_name
16.SQL alter table 语句
作用:
- ALTER TABLE 语句用于在已有的表中添加、删除或修改列
语法:
--在表中添加列
ALTER TABLE table_name
ADD column_name datatype
--删除表中的列
ALTER TABLE table_name
DROP COLUMN column_name
--改变表中列的数据类型
ALTER TABLE table_name
MODIFY COLUMN column_name datatype
17.SQL auto increment 字段
作用:
- Auto-increment 会在新记录插入表中时生成一个唯一的数字。
- 通常希望在每次插入新记录时,自动地创建主键字段的值
语法:
--MySQL
CREATE TABLE Persons
(
ID int NOT NULL AUTO_INCREMENT,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (ID)
)
--SQL Server
CREATE TABLE Persons
(
ID int IDENTITY(1,1) PRIMARY KEY,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
--Access
CREATE TABLE Persons
(
ID Integer PRIMARY KEY AUTOINCREMENT,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
--Oracle
CREATE SEQUENCE seq_person
MINVALUE 1
START WITH 1
INCREMENT BY 1
CACHE 10
18.SQL 视图
作用:
- 视图是基于 SQL 语句的结果集的可视化的表。
- 视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。
- 以向视图添加 SQL 函数、WHERE 以及 JOIN 语句,也可以呈现数据,就像这些数据来自于某个单一的表一样。
语法:
CREATE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
---注释:视图总是显示最新的数据!每当用户查询视图时,数据库引擎通过使用视图的 SQL 语句重建数据。
实例:
1)视图 “Current Product List” 会从 “Products” 表列出所有正在使用的产品(未停产的产品)。
--创建视图
CREATE VIEW [Current Product List] AS
SELECT ProductsID,ProductName
FROM Products
WHERE Discontinued=No
---查询视图
SELECT * FROM [Current Product List]
2)更新视图:
CREATE OR REPLACE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
3)删除视图
DROP VIEW view_name
19.SQL null值
作用:
- NULL 值代表遗漏的未知数据。
- 默认地,表的列可以存放 NULL 值。
- 如果表中的某个列是可选的,那么我们可以在不向该列添加值的情况下插入新记录或更新已有的记录。这意味着该字段将以 NULL 值保存。
- NULL 值的处理方式与其他值不同。
- NULL 用作未知的或不适用的值的占位符。
- 无法比较 NULL 和 0;它们是不等价的。
如何测试 NULL 值
- 无法使用比较运算符来测试 NULL 值,比如 =、< 或 <>。
- 必须使用 IS NULL 和 IS NOT NULL 操作符来测试null
实例:
1)选取在 “Address” 列中带有 NULL 值的记录:
SELECT LastName,FirstName,Address FROM Persons
WHERE Address IS NULL
2)选取在 “Address” 列中不带有 NULL 值的记录
SELECT LastName,FirstName,Address FROM Persons
WHERE Address IS NOT NULL
第三章 SQL函数
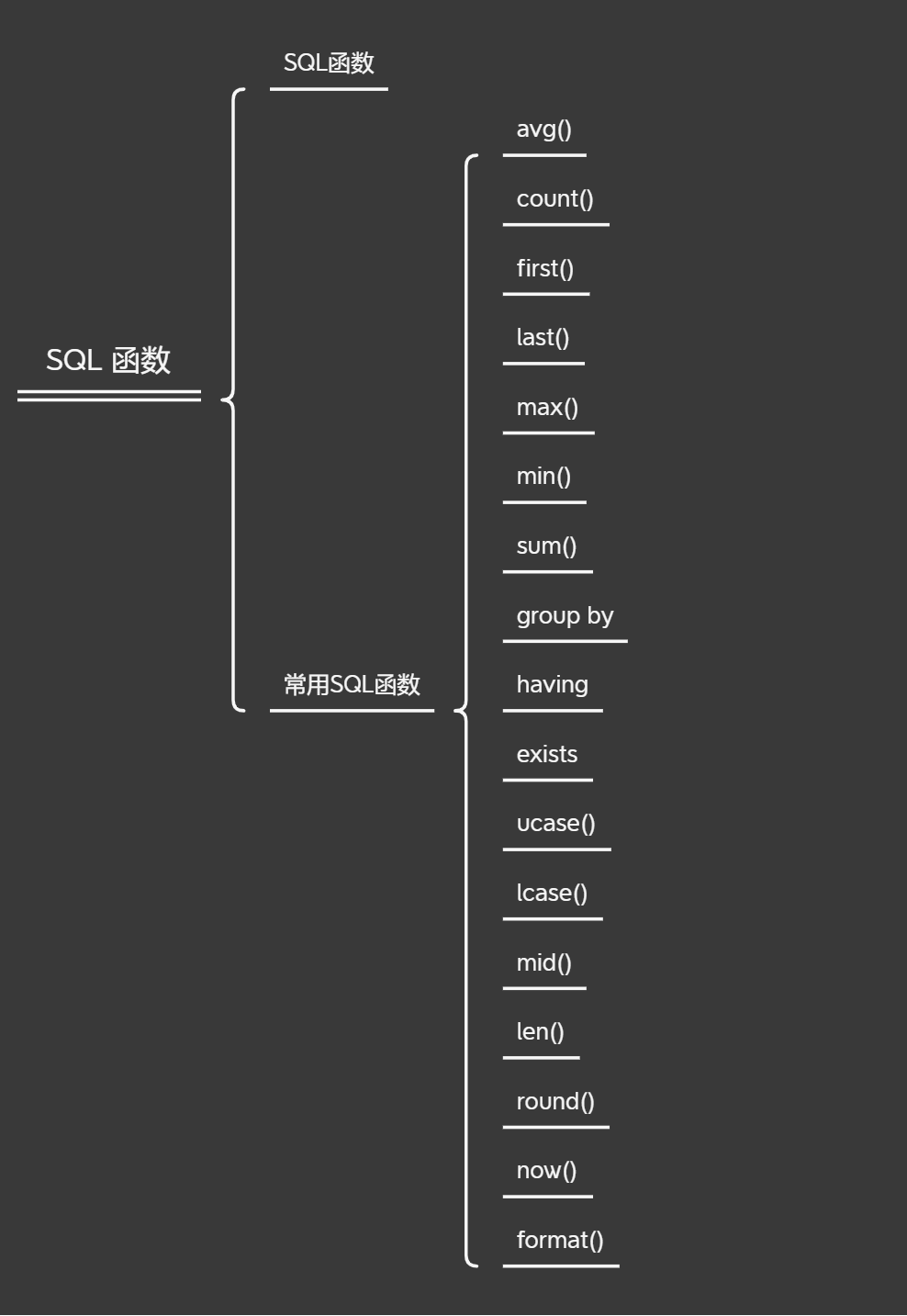
第一节 SQL date 函数
SQL Date 数据类型
MySQL 使用下列数据类型在数据库中存储日期或日期/时间值:
- DATE - 格式:YYYY-MM-DD
- DATETIME - 格式:YYYY-MM-DD HH:MM:SS
- TIMESTAMP - 格式:YYYY-MM-DD HH:MM:SS
- YEAR - 格式:YYYY 或 YY
SQL Server 使用下列数据类型在数据库中存储日期或日期/时间值:
- DATE - 格式:YYYY-MM-DD
- DATETIME - 格式:YYYY-MM-DD HH:MM:SS
- SMALLDATETIME - 格式:YYYY-MM-DD HH:MM:SS
- TIMESTAMP - 格式:唯一的数字
MySQL Date 函数
下面的表格列出了 MySQL 中最重要的内建日期函数:
| 函数 | 描述 |
|---|---|
| NOW() | 返回当前的日期和时间 |
| CURDATE() | 返回当前的日期 |
| CURTIME() | 返回当前的时间 |
| DATE() | 提取日期或日期/时间表达式的日期部分 |
| EXTRACT() | 返回日期/时间的单独部分 |
| DATE_ADD() | 向日期添加指定的时间间隔 |
| DATE_SUB() | 从日期减去指定的时间间隔 |
| DATEDIFF() | 返回两个日期之间的天数 |
| DATE_FORMAT() | 用不同的格式显示日期/时间 |
SQL Server Date 函数
下面的表格列出了 SQL Server 中最重要的内建日期函数:
| 函数 | 描述 |
|---|---|
| GETDATE() | 返回当前的日期和时间 |
| DATEPART() | 返回日期/时间的单独部分 |
| DATEADD() | 在日期中添加或减去指定的时间间隔 |
| DATEDIFF() | 返回两个日期之间的时间 |
| CONVERT() | 用不同的格式显示日期/时间 |
第二节 SQL null 函数
--SQL Server / MS Access
SELECT ProductName,UnitPrice*(UnitsInStock+ISNULL(UnitsOnOrder,0))
FROM Products
--Oracle 没有 ISNULL() 函数。不过,我们可以使用 NVL() 函数达到相同的结果:
SELECT ProductName,UnitPrice*(UnitsInStock+NVL(UnitsOnOrder,0))
FROM Products
--Mysql
SELECT ProductName,UnitPrice*(UnitsInStock+IFNULL(UnitsOnOrder,0))
FROM Products
-或
SELECT ProductName,UnitPrice*(UnitsInStock+COALESCE(UnitsOnOrder,0))
FROM Products
第三节 aggregate 函数
1.AVG() - 返回平均值
作用:
- AVG() 函数返回数值列的平均值。
语法:
SELECT AVG(column_name) FROM table_name
演示:
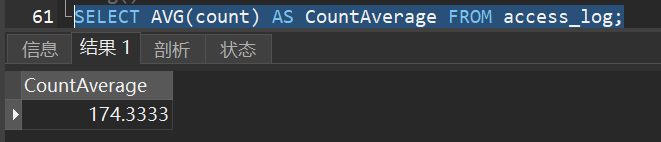
1)从 “access_log” 表的 “count” 列获取平均值:
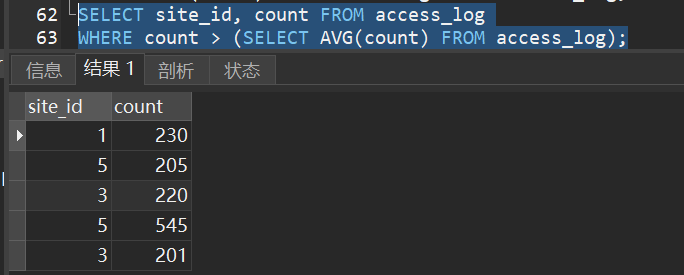
2)选择访问量高于平均访问量的 “site_id” 和 “count”:
2.COUNT() - 返回行数
作用:
- COUNT() 函数返回匹配指定条件的行数。
语法:
--返回指定列的值的数目(NULL 不计入)
SELECT COUNT(column_name) FROM table_name;
--返回表中的记录数
SELECT COUNT(*) FROM table_name;
--返回指定列的不同值的数目:
SELECT COUNT(DISTINCT column_name) FROM table_name;
演示:
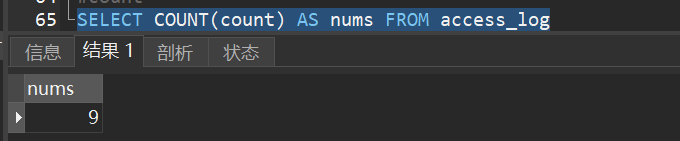
1)计算 “access_log” 表中 “site_id”=3 的总访问量:
2)计算 “access_log” 表中总记录数:
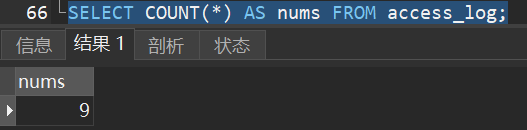
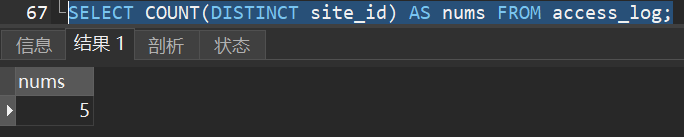
3)计算 “access_log” 表中不同 site_id 的记录数:
3.FIRST() - 返回第一个记录的值
作用:
- FIRST() 函数返回指定的列中第一个记录的值。
语法:
--只有 MS Access 支持 FIRST() 函数。
SELECT FIRST(column_name) FROM table_name;
--SQL Server
SELECT TOP 1 column_name FROM table_name
ORDER BY column_name ASC;
--MySQL
SELECT column_name FROM table_name
ORDER BY column_name ASC
LIMIT 1;
--Oracle
SELECT column_name FROM table_name
ORDER BY column_name ASC
WHERE ROWNUM <=1;
演示:
1)选取 “Websites” 表的 “name” 列中第一个记录的值:
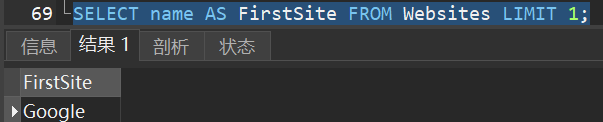
4.LAST() - 返回最后一个记录的值
作用:
- LAST() 函数返回指定的列中最后一个记录的值。
语法:
--MS Access 支持 LAST() 函数。
SELECT LAST(column_name) FROM table_name;
--SQL Server
SELECT TOP 1 column_name FROM table_name
ORDER BY column_name DESC;
--MySQL
SELECT column_name FROM table_name
ORDER BY column_name DESC
LIMIT 1;
--Oracle
SELECT column_name FROM table_name
ORDER BY column_name DESC
WHERE ROWNUM <=1;
演示:
1)选取 “Websites” 表的 “name” 列中最后一个记录的值:
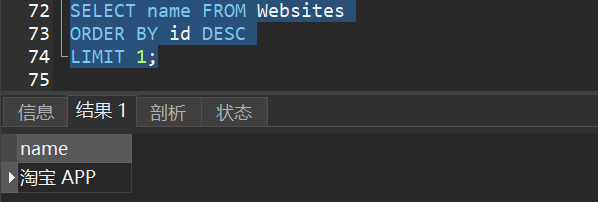
5.MAX() - 返回最大值
作用:
- MAX() 函数返回指定列的最大值。
语法:
SELECT MAX(column_name) FROM table_name;
演示:
1)从 “Websites” 表的 “alexa” 列获取最大值:
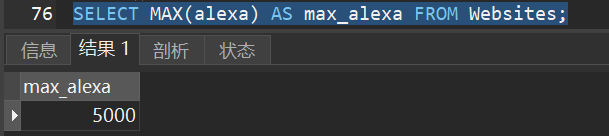
6.MIN() - 返回最小值
作用:
- MIN() 函数返回指定列的最小值。
语法:
SELECT MIN(column_name) FROM table_name;
演示:
1)从 “Websites” 表的 “alexa” 列获取最小值:
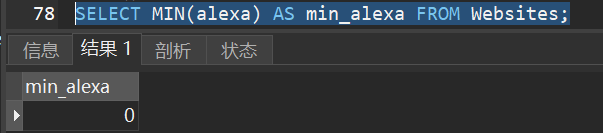
7.SUM() - 返回总和
作用:
- SUM() 函数返回数值列的总数。
语法:
SELECT SUM(column_name) FROM table_name;
演示:
1)查找 “access_log” 表的 “count” 字段的总数:
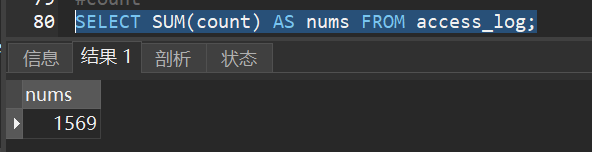
第四节 scalar 函数
1.UCASE() - 将某个字段转换为大写
作用:
- UCASE() 函数把字段的值转换为大写。
语法:
SELECT UCASE(column_name) FROM table_name;
演示:
1)从 “Websites” 表中选取 “name” 和 “url” 列,并把 “name” 列的值转换为大写:
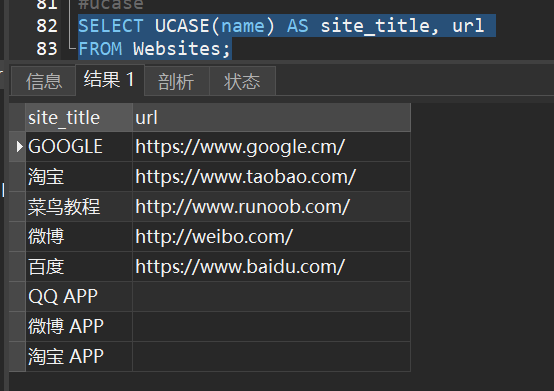
2.LCASE() - 将某个字段转换为小写
作用:
- LCASE() 函数把字段的值转换为小写。
语法:
SELECT LCASE(column_name) FROM table_name;
演示:
1)从 “Websites” 表中选取 “name” 和 “url” 列,并把 “name” 列的值转换为小写:
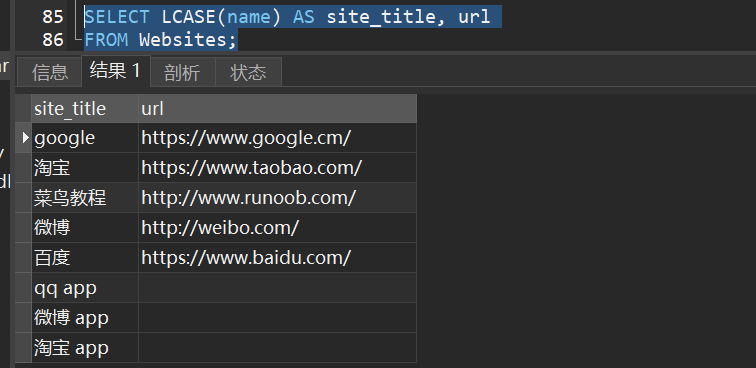
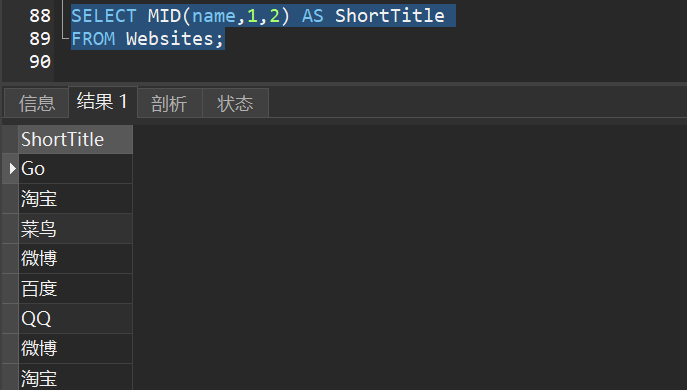
3.MID() - 从某个文本字段提取字符,MySql 中使用
作用:
- MID() 函数用于从文本字段中提取字符。
语法:
SELECT MID(column_name,start[,length]) FROM table_name;
--column_name 必需。要提取字符的字段。
--start 必需。规定开始位置(起始值是 1)。
--length 可选。要返回的字符数。如果省略,则 MID() 函数返回剩余文本。
演示:
1)从 “Websites” 表的 “name” 列中提取前 2个字符:
4.LEN() - 返回某个文本字段的长度
作用:
- LEN() 函数返回文本字段中值的长度。
语法:
SELECT LEN(column_name) FROM table_name;
--MYSQL
SELECT LENGTH(column_name) FROM table_name;
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Linux运维工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)


最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
x教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow
第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。
本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-P6k6Xij3-1712549491510)]















 1219
1219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









