







(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
接下来是重要的一步。由于打包时没有绑定任何的资源文件,所以此时运行时会报错,提示找不到image.gif。此时,应该把程序文件夹下的assets文件夹(参见上方的文件夹层级)复制到dist文件夹中的程序文件夹,和exe文件位于同一位置。
接下来,再试一下单文件模式的打包,只需添加-F参数:
pyinstaller -w -F my_app_name.py

打包后,生成了一个单个的my_app_name.exe,而没有其他文件。同样也需要将assets文件夹复制到与该exe文件的同一位置。
4.4 资源嵌入exe
经常需要复制文件夹不仅麻烦,而且还无法防止里面的内容被用户修改。此时,我们可以使用pyinstaller的–add-data参数,将assets文件夹里面的资源嵌入到exe文件中。
资源嵌入exe只在单文件模式下使用。文件夹模式下,资源文件夹不会嵌入到exe中,但是会被复制到exe所在的文件夹。
使用资源嵌入后,资源文件夹的路径发生了变化,我们不能使用一般的相对路径来调用assets这样的内嵌资源文件夹。
前面已经讲过,pyinstaller单文件模式下的exe启动后,会将嵌入的资源文件放到一个临时的文件夹中,这个文件夹的名字不是固定的,叫做_MEIxxxxx,其中xxxxx是随机数。这个文件夹的路径在打包后会被放到sys._MEIPASS这个变量里面,只需要调用sys._MEIPASS就可以获得这个路径文件夹。
于是,我们通过以下函数返回正确的路径:
def get_path(relative_path):
try:
base_path = sys._MEIPASS # pyinstaller打包后的路径
except AttributeError:
base_path = os.path.abspath(".") # 当前工作目录的路径
return os.path.normpath(os.path.join(base_path, relative_path)) # 返回实际路径
这个函数通过一个相对的路径返回实际的绝对路径。
需要注意:sys._MEIPASS这个属性只有在打包成exe后才被创建,以py代码执行的时候这个属性是不存在的,所以要通过try…except…代码块捕获异常。如果不是pyinstaller模式,那么就使用py文件所在的文件夹的路径作为基本路径。我们不必担心这个函数的工作原理(虽然者不难理解),这个函数可以直接拿来用(是一位叫做davidpendergast的大佬写的)。
于是,我们将代码改成这样(省略了部分内容):
...
import sys
import os
def get_path(relative_path):
try:
base_path = sys._MEIPASS
except AttributeError:
base_path = os.path.abspath(".")
return os.path.normpath(os.path.join(base_path, relative_path))
...
image = tk.PhotoImage(file=get_path("assets/image.gif"))
...
接下来进行打包:
pyinstaller -w -F --add-data assets;assets my_app_name.py
打包完成后会生成一个包含嵌入资源的单独的exe,无需将资源文件放到同一文件夹下也能正常运行。
–add-data的参数由源文件名src和目标文件名dest组成。路径的源文件名和目标文件名用文件分隔符进行分隔,源文件名是该文件或文件夹的原本的路径,目标文件名是该文件夹嵌入到exe后的放入的文件夹名。
文件分隔符:在Windows系统上是分号,大部分unix系统上是冒号,可以通过os.pathsep来查看当前系统上的文件分隔符。例如:
>>> import os >>> os.pathsep ';'
比如–add-data "assets;assets"就表示将原本assets里面的所有文件,放入打包后的assets文件夹。再比如–add-data "assets/*.mp3;music"表示将原本assets里面的所有mp3文件,放入打包后的music文件夹。
4.5 更改图标
打包完成后,默认的程序图标是一个“蛇”形,但我们也可以进行更改。(根据官方文档,该功能只能在Windows和macOS上使用)
–icon或-i参数用于设置图标,该参数的值默认为"NONE",表示使用默认的图标;也可以指定为一个*.ico格式的Windows图标文件路径;*.icns的Mac图标文件路径;或者一个其他图片文件(需安装pillow模块,会通过pillow模块将其转换成标准的ico/icns格式)。
首先添加一个图标文件。图标文件在Windows上格式为*.ico,Mac上是*.icns。
- my_app
- assets
- image.gif
- my_app_name.py
- icon.ico
这个图标文件其实放在哪里都可以,因为打包完成后其实它也相当于嵌入了exe。但为了方便,还是把它放到同一文件夹下比较好。
pyinstaller -i icon.ico my_app_name.py
为了方便看,之前设置的-w, -F这些选项都省略了。最后生成了一个图标与icon.ico相一致的exe。

4.6 启动画面(闪屏)
pyinstaller单文件模式启动速度较慢,所以可能需要一个启动画面(闪屏)进行过渡,提示用户正在进行加载。这个启动画面可以是单张图片,也可以是文本(默认情况下文本禁用,使用方式参见第5章)。
这个启动画面的实现基于Tcl/Tk(和python tkinter模块一样),打包时会附带约1.5MB的额外文件来支持这个功能。
支持闪屏,需要先准备一张图片,必须是PNG格式(如果你安装了pillow模块,可以用pillow模块支持的其他格式)。然后,在打包时加上–splash参数,并传入图片路径。
pyinstaller --splash splash.png my_app_name.py
控制闪屏可以通过pyi_splash模块,这个模块和上一节的sys._MEIPASS属性一样,在没有通过pyinstaller打包成exe后是不起作用的,所以必须带上try…except…代码。
pyi_splash.close()方法用于关闭闪屏。一般放在程序开头即可,因为只要运行到程序开头,说明pyinstaller的加载就基本完成了。
于是,在程序开头部分添加以下代码:
try:
import pyi_splash
pyi_splash.close()
except ImportError:
pass
如果不用这段代码进行关闭,那么闪屏将一直显示。
打包后,闪屏效果如下。

至于pyi_splash还有一个update_text方法,用于在闪屏画面上显示加载文本,将在5.7节介绍。
4.7 禁用异常提示
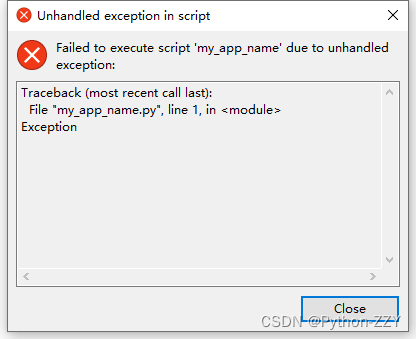
–disable-windowed-traceback参数用于禁用异常提示。如果不添加这个参数,将会在非控制台程序出错(似乎仅限非致命的错误)时弹出一个窗口报告异常信息(注意:仅在隐藏控制台模式下弹出异常报告窗口)。为了测试,我在代码第一行添加了raise Exception,运行打包后的exe后效果如图所示。
5 使用Spec文件
当你调用以上的打包方式时,会在脚本的文件夹下生成一个*.spec文件。
*.spec文件包含了打包需要使用的所有配置信息。直接在命令行中将*.spec文件路径传给pyinstaller,也可以进行打包。比如:
pyinstaller my_app_name.spec
(其中my_app_name.spec是根据my_app_name.py生成的Spec文件)
这样,当你多次打包同一个项目时,就无需每次都传入那么多参数,只需要传入*.spec文件的路径即可。
*.spec文件也比较好处理,直接使用python编辑器或记事本就能编辑。
5.1 生成Spec文件
使用pyi-makespec工具可以根据pyinstaller的命令行参数生成Spec文件。用法很简单,在原先使用pyinstaller的打包命令中,把"pyinstaller"换成"pyi-makespec"就可以生成一个Spec文件。例如:
pyi-makespec -w -F --add-data assets;assets my_app_name.py
要更改Spec文件的生成路径,可以指定参数–specpath。
如果报错提示找不到pyi-makespec,转到最后一章:常见问题。
当你使用*.spec文件进行pyinstaller打包时,大部分的打包参数都不可用,需要预先在*.spec文件中预先设定。
pyinstaller会将*.spec里面的内容当做代码执行。单文件模式和文件夹模式的*.spec文件略有不同。
下面是一个*.spec文件(单文件模式打包)的例子。
# -*- mode: python ; coding: utf-8 -*-
block_cipher = None
a = Analysis(
['my_app_name.py'],
pathex=[],
binaries=[],
datas=[('assets', 'assets')],
hiddenimports=[],
hookspath=[],
hooksconfig={},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False,
)
pyz = PYZ(a.pure, a.zipped_data, cipher=block_cipher)
exe = EXE(
pyz,
a.scripts,
a.binaries,
a.zipfiles,
a.datas,
[],
name='my_app_name',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
upx_exclude=[],
runtime_tmpdir=None,
console=False,
disable_windowed_traceback=False,
argv_emulation=False,
target_arch=None,
codesign_identity=None,
entitlements_file=None,
)
下面是一个文件夹模式的*.spec文件的例子:
# -*- mode: python ; coding: utf-8 -*-
block_cipher = None
a = Analysis(
['my_app_name.py'],
pathex=[],
binaries=[],
datas=[('assets', 'assets')],
hiddenimports=[],
hookspath=[],
hooksconfig={},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False,
)
pyz = PYZ(a.pure, a.zipped_data, cipher=block_cipher)
exe = EXE(
pyz,
a.scripts,
[],
exclude_binaries=True,
name='my_app_name',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
console=False,
disable_windowed_traceback=False,
argv_emulation=False,
target_arch=None,
codesign_identity=None,
entitlements_file=None,
)
coll = COLLECT(
exe,
a.binaries,
a.zipfiles,
a.datas,
strip=False,
upx=True,
upx_exclude=[],
name='my_app_name',
)
这里面包含一些特殊的类,比如Analysis, PYZ, EXE等,文件夹模式下还多了一个COLLECT类。只有当pyinstaller运行时才会被定义,很显然你不能在python解释器中直接调用它们。 这些类的参数与pyinstaller的命令行参数并不一样。
接下来将针对Spec文件中的这些对象进行介绍
5.2 Analysis对象
Analysis类包含一些分析信息,它分析模块的导入以及一些依赖文件。
这个类的常用参数介绍如下。
| 参数名 | 默认值 | 描述 | (常用参数)示例 |
| scripts | 必选参数,无默认值 | 需要分析的文件路径列表(一般就是需要打包的文件) | [“myscript.py”] |
| pathex | None | 需要额外进行分析模块导入的文件(夹)路径,包含命令行–path参数指定内容 | [“C:/Python310/Lib/site-packages”, "C:/my_module] |
| binaries | None | 需要嵌入的二进制文件列表,包含命令行–add-binary参数指定内容 | |
| datas | None | 需要嵌入的非二进制文件(夹),包含命令行–add-data参数指定内容 | [(“assets”, “assets”), (“music/*.mp3”, “music”)] |
| hiddenimport | None | 需要额外导入的模块列表 | [“module1”, “module2”] |
| hookspath | None | 钩子文件路径列表(钩子文件用于配置一些模块特殊的导入,后文详解) | |
| hooksconfig | None | 一个字典,包含钩子的配置信息 | |
| excludes | None | 需要被忽略,不进行导入的模块列表 | |
| runtime_hooks | None | 运行时的钩子列表,指定为一系列文件名 | |
| noarchive | False | 如果设为True,则不会将源代码放到一个存档中进行存储,而是作为多个单独的文件 |
在完成分析后,需要将一些属性传递给PYZ类。Analysis对象包含了以下属性,你可以不必了解它们:
| 属性名 | 描述 |
| scripts | 同参数中的scripts |
| pure | 需要一起打包的纯python模块 |
| pathex | 同参数中的pathex |
| binaries | 同参数中的binaries |
| datas | 同参数中的datas |
5.3 PYZ对象
完成分析后,将Analysis对象的一些属性传递给PYZ类。PYZ相当于一个压缩包,里面储存了所有的依赖文件。
pyz = PYZ(a.pure, a.zipped_data, cipher=block_cipher)
5.4 EXE对象
定义PYZ对象后,接下来需要定义EXE对象,也就是可执行文件对象。
不同打包模式(单文件或文件夹)的EXE对象参数略有不同。其中常用参数如下:
| 参数 | 默认值 | 描述 | (常用参数)示例 |
| console | True | 是否显示控制台,相当于命令行-w参数 | |
| disable_windowed_traceback | False | 是否禁用异常提示,相当于命令行–disable-windowed-traceback参数 | |
| name | None | 可执行文件的名称。在Windows上会自动添加".exe"后缀 | “my_app_name” |
| icon | None | 可执行文件的图标路径 | “icon.ico” |
5.5 COLLECT对象(仅-D文件夹模式)
使用文件夹模式打包时还会有一个COLLECT对象,该对象用于创建文件夹。它有一个常用的关键字参数name,表示文件夹的名称。
5.6 Bundle对象(仅macOS系统)
如果你要在macOS上创建应用程序,且你的应用程序是无控制台的,那么在exe构建完成之后还需要添加一些代码。
app = BUNDLE(exe,
name='my_app_name.app',
icon="icon.ico",
bundle_identifier=None)
5.7 Splash对象
如果你想要在应用中添加启动画面(图片和文本都可以),需要在Spec文件中额外添加一个Splash对象进行控制。
在分析完代码后,创建Splash对象:
a = Analysis(...)
splash = Splash('splash.png',
binaries=a.binaries,
datas=a.datas,
text_pos=(10, 50),
text_size=12,
text_color='black')
然后在EXE中绑定splash对象。注意:单文件模式和文件夹模式方式略有不同。
以下是单文件模式绑定splash对象的方法。
splash = Splash(...)
exe = EXE(pyz,
a.scripts,
splash, # <-- both, splash target
splash.binaries, # <-- and splash binaries
...)
以下是文件夹模式的方法。
splash = Splash(...)
exe = EXE(pyz,
splash, # <-- splash target
a.scripts,
...)
coll = COLLECT(exe,
splash.binaries, # <-- splash binaries
...)
下面介绍Splash对象的一些参数。注意:由于Splash窗口基于Tcl/Tk(和python tkinter一样),所以里面有一些用法与Tcl/Tk(tkinter)的用法很像,但不重要。
| 参数 | 默认值 | 描述 | (常用参数)示例 |
| image_file | 必选参数,无默认值 | 图片文件路径,必须是PNG格式(如果你安装了pillow模块,可以用pillow模块支持的其他格式) | “splash.png” |
| binaries | 必选参数,无默认值 | Analysis对象的binaries属性 | |
| datas | 必选参数,无默认值 | Analysis对象的datas属性 | |
| text_pos | None | 闪屏文本相对于闪屏图片的显示位置(是一个(x, y)元组,锚点为文本左下角)。如果不指定,则禁用文本显示 | (500, 400) |
| text_size | 12 | 文本大小 | |
| text_font | “TkDefaultFont” | 文本使用的字体(必须是系统上安装了的字体),如果不指定则设为系统默认字体 | “宋体” |
| text_color | “black” | 文本颜色,颜色格式可以是颜色名称字符串或者十六进制颜色字符串,如"#ff00ff"(注意:不支持(r, g, b)元组形式) | |
| text_default | “Initializing” | 默认显示的文本(后面可以用pyi_splash.update_text来更新显示的文本) | “加载中……” |
| max_img_size | (760, 480) | 最大闪屏图片尺寸。如果超出尺寸,那么闪屏图片将会被按纵横比缩放,容纳到该尺寸中。可以设为None不缩放 | |
| always_on_top | True | 闪屏窗口是否置顶,如果置顶,其位于其他窗口之上 | |
| rundir | “__splash” | 设置运行闪屏时,用于存放一些相关文件的文件夹名称。使用这个参数主要是为了避免命名冲突,一般不会使用 |
下面就以一个示例来演示Splash的文本显示。使用的代码还是上一章节使用的。
在开头添加以下代码:
try:
import pyi_splash
import time
for i in range(100):
text = f"加载中……进度{i}%"
time.sleep(0.1) # 模拟一个速度比较慢的加载过程
pyi_splash.update_text(text) # 更新显示的文本
pyi_splash.close() # 关闭闪屏
except ImportError:
pass
然后通过pyi-makespec生成对应的Spec文件:
pyi-makespec -w -F --add-data assets;assets --splash splash.png my_app_name.py
由于Splash的文本显示只能在Spec文件中进行配置,所以我们先打开my_app_name.spec,将Splash对象的代码进行修改,如下所示:
splash = Splash(
'splash.png',
binaries=a.binaries,
datas=a.datas,
text_pos=(30, 270),
text_size=12,
minify_script=True,
always_on_top=True,
)
然后进行打包:
pyinstaller my_app_name.spec
运行效果如下:

可以看到,首先显示文本被设定为加载的各个依赖文件,然后变成update_text中自己设定的加载内容。
5.8 多包捆绑(打包多个exe)
有些产品由几个不同的应用程序组成,每个应用程序可能依赖于一组通用的第三方库,或者以其他方式共享一部分代码。在打包这样的产品时,如果单独对待每个应用程序,将其与所有依赖项捆绑在一起,那就太可惜了,因为这意味着要存储代码和库的副本。
此时,我们可以使用多包特性来捆绑一组可执行应用程序,以便它们共享库的单个副本。我们可以在单文件或单文件夹应用程序中做到这一点。
比如有两个应用都使用了tkinter模块,且这两个应用相关,需要在发布时放到一起(比如一个应用专门用于图片剪裁,另外一个专门用于图片滤镜,它们可能共用了部分功能)。如果分别打包,那么每个应用都会包含一个tkinter模块的依赖文件,而且都储存相同的内容,这就很浪费存储空间。如果用多包捆绑的话,只会有一个tkinter模块的依赖文件,两个应用都可以调用相同的依赖。
文件夹模式的多包捆绑
如果采用文件夹模式,想要捆绑多个应用程序,那么只需要共享一个COLLECT对象。假如有hello1.py, hello2.py,将这两个应用进行捆绑,可以将它们的Spec文件进行一些组合。
首先通过pyi-makespec分别生成hello1.py, hello2.py的Spec文件。
然后将其中的Analysis, PYZ, EXE, Splash等对象分别以不同的变量名放入同一个Spec文件,然后将它们的COLLECT对象组合起来。
hello1_a = Analysis(['hello1.py'], ...)
hello1_pyz = PYZ(hello1_a.pure, hello1_a.zipped_data, ...)
hello1_exe = EXE(hello1_pyz,
hello1_a.scripts,
...)
hello2_a = Analysis(['hello2.py'], ...)
hello2_pyz = PYZ(hello2_a.pure, hello2_a.zipped_data, ...)
hello2_exe = EXE(hello2_pyz,
hello2_a.scripts,
...)
coll = COLLECT(hello1_exe,
hello1_a.binaries,
hello1_a.zipfiles,
hello1_a.datas,
hello2_exe,
hello2_a.binaries,
hello2_a.zipfiles,
hello2_a.datas,
...
name='hello')
这样,将会生成同一个文件夹,该文件夹下包含两个文件hello1.exe, hello2.exe。 它们共享一部分的依赖文件。
单文件模式的多包捆绑
单文件模式下,多包捆绑会生成多个单独的exe,其中一个exe包含它们共有的依赖文件。
比如打包hello1.py和hello2.py,设置hello1包含共有的依赖文件,最后生成hello1.exe, hello2.exe。生成的hello1.exe由于包含两个exe共有的依赖文件,其文件大小会大于hello2.exe。
运行hello1.exe时与单独打包效果相同。但是运行hello2.exe时,它会在hello1.exe中搜索它需要的依赖文件,速度会稍慢。
如果将hello2.exe移动到别的地方,或者将hello1.exe改名,那么hello2.exe将无法运行,因为它找不到hello1.exe,从而无法找到所需的依赖文件。
以下是hello1.py和hello2.py两个程序文件,将以它们为例进行打包。
# hello1.py
while True:
input("hello1")
# hello2.py
while True:
input("hello2")
首先通过pyi-makespec生成对应的Spec文件。完成后,将两个Spec文件的Analysis类汇总到一个文件中,并进行改名。
a1 = Analysis(
['hello1.py'],
...
)
a2 = Analysis(
['hello2.py'],
...
)
接下来在下面调用MERGE函数。这个函数会分析两个文件中重复的依赖项,将结果放到分析类的dependencies属性中。MERGE中位于第一个的程序将会包含共有的依赖项。
MERGE((a1, "hello1", "hello1"), (a2, "hello2", "hello2"))
然后将两个文件的ZIP和EXE进行汇总。汇总时需要额外向EXE类传递一个参数Analysis.dependencies。
pyz1 = PYZ(...)
exe1 = EXE(pyz1,
a1.dependencies, ####
a1.scripts,
a1.binaries,
a1.zipfiles,
a1.datas, ...)
pyz2 = PYZ(...)
exe2 = EXE(
pyz2,
a2.dependencies, ####
a2.scripts,
a2.binaries,
a2.zipfiles,
a2.datas, ...)
保存文件,然后通过pyinstaller打包。

最后生成两个文件,可以看到hello1.exe的文件大小比hello2.exe大了很多,这是由于hello1.exe中包含了它们共有的依赖库。如果不使用多包捆绑,而是分别单独进行打包,那么两个文件的大小将都会超过5000KB。
6 钩子
有一些特殊的模块,它们存在一些特殊的依赖文件(比如ico, json等等)。而pyinstaller的导入分析无法检测到这些特殊的依赖文件,这就导致运行后出现问题。于是,pyinstaller引入了“钩子”。钩子文件其实就是一种python文件,后缀名为*.py即可(和Spec文件的实质是一样的)。钩子文件中指定了某个特殊模块所需要的所有依赖文件。通过传递钩子文件,pyinstaller就能找到那些“隐藏”的依赖文件。
虽然钩子文件的作用也可以被–hiddenimport, --datas这些命令行参数替代,但是使用钩子显然更加方便。
pyinstaller有一些内置的“钩子”,提供了一些常用模块的钩子文件,它们包含Django, pickle, pyqt, scipy等等。
钩子文件的常用命名格式是:hook-module.py(其中module是模块名)。(当然你也可以按自己喜好命名)
6.1 钩子文件中的全局变量
钩子文件中可以包含以下全局变量(有一些变量可以不被写在文件中):
| 属性 | 描述 | (常用属性)示例 |
| hiddenimports | 需要额外导入的模块列表,相当于命令行–hidden-import参数 | [“sys”, “pygame.mixer”] |
| excludedimports | 需要被排除,不被自动导入的模块列表(如果有一些模块在其他地方被导入,那么仍然会导入它) | [“tkinter”] |
| datas | 需要备添加的非二进制文件或文件夹,相当于命令行–add-data参数 | [(‘/usr/share/icons/education_*.png’, ‘assets’) ] |
| binaries | 需要备添加的二进制文件,相当于命令行–add-binary参数 |
以下是一个钩子文件的示例:
hiddenimports = ["re", "os"]
datas = [("assets", "assets)]
6.2 PyInstaller.utils.hooks
pyinstaller提供了一些方法用于钩子文件的制作。这些方法位于PyInstaller.utils.hooks模块。首先需要在钩子文件导入该模块。(注意pyinstaller的P和I是大写的,这是pyinstaller作为模块时的名称)
import PyInstaller.utils.hooks as hooks
下面介绍该模块中的常用函数。
is_module_satisfies(requirements, version=None, version_attr=‘__version__’)
检验模块版本是否达到requirements的要求,返回一个布尔值。关于requirements的相关格式,详见PEP 440。version_attr参数指定该模块中版本属性的名称,默认是"__version__"。
下面是一些requirements的例子:
"pygame >= 2.2.1dev1" # 大于2.1.1dev1版本的pygame模块
"PIL == 2.9.*" # 版本以2.9.开头的PIL模块
"sphinx >= 1.3.1; sqlalchemy != 0.6" # 同时满足两个要求
collect_submodules(package, filter=<function >, on_error=‘warn once’)
返回一个模块的所有子模块。filter是一个筛选函数,接收模块名作为参数,返回一个布尔值表示是否要加入这个模块到返回值中。on_error表示筛选出现异常时的处理,可以是:“raise”(抛出异常并停止pyinstaller构建),“warn”(只抛出警告,不停止pyinstaller构建),“warn once”(只警告一次,后续与之相同的警告被忽略),“ignore”(忽略,不抛出任何警告或异常)
例如:
# 收集Sphinx的所有子模块(名字中不包含test)
hiddenimports = collect_submodules(
"Sphinx", filter=lambda name: 'test' not in name)
collect_data_files(package, include_py_files=False, subdir=None, excludes=None, includes=None)
返回一个模块使用的所有非二进制文件。include_py_files表示返回的文件列表中是否应该含有*.py格式的文件。subdir是相对于要搜索的包的子目录。excludes, includes分别是需要被排除和被包含的文件列表,可以指定它们来判断是否要保留或移除某些格式的文件。
collect_dynamic_libs(package, destdir=None, search_patterns=[‘*.dll’, ‘*.dylib’, ‘lib*.so’])
返回一个模块使用的所有二进制动态库文件。
collect_all(package_name, include_py_files=True, filter_submodules=None, exclude_datas=None, include_datas=None, on_error=‘warn once’)
相当于上面的collect前缀的几个函数的综合。例如:
datas, binaries, hiddenimports = collect_all('my_module_name')
使用hooks模块可以更加方便地制作钩子。
6.3 为自己的模块提供钩子
如果自己创建的模块需要钩子,那么可以自己定义一个文件,并储存到自己的模块中。
如果你有一个名为module_name的模块文件夹,首先在自己模块的setup.cfg中(与setuptools模块相关,可自行搜索)添加如下代码(注意里面的module_name):
[options.entry_points]
pyinstaller40 =
hook-dirs = module_name.__pyinstaller:get_hook_dirs
tests = module_name.__pyinstaller:get_PyInstaller_tests
然后在module_name中添加名字为__pyinstaller的文件夹(与上面hook-dirs和tests里面的命名相一致即可)。
最后可以在__pyinstaller文件夹中添加hook文件。
7 反编译与加密
pyinstaller制作的应用,可能会被反编译(即根据生成的exe得到这个程序的源代码)。同时,也有一些方法来预防反编译,或者增加反编译的难度。
需要注意的是,反编译代码的结果大多数时候并不准确,只能得到大概的代码,可能需要后期处理。
7.1 通过pyinstxtractor进行反编译
pyinstxtractor是专门针对pyinstaller的反编译工具(也就是说,其他的打包工具,比如py2exe,cx_Freeze打包的程序无法被这个工具反编译,需要通过别的反编译工具)。
下载工具
首先通过以下链接下载pyinstxtractor:
PyInstaller Extractor download | SourceForge.net
也可以通过github下载(推荐上面的方法,毕竟github访问较慢):
GitHub - extremecoders-re/pyinstxtractor: PyInstaller Extractor
下载完成后,得到pyinstxtractor.py。
还需要下载pycdc,链接如下:
pycdc.exe · Python-ZZY - Gitee.com
想要反编译一个pyinstaller打包的应用,流程是这样的:
- 先用pyinstxtractor将*.exe文件反编译成*.pyc文件
- 用十六进制编辑器修改*.pyc文件中的magic number
- 使用pycdc工具将*.pyc转换为最终的*.py文件
下面还是以这个程序为例作为演示:
'''
一个简单的应用
'''
import tkinter as tk # 导入tkinter
root = tk.Tk() # 创建窗口
root.title("我的应用程序") # 更改标题
image = tk.PhotoImage(file="assets/image.gif")
label = tk.Label(root, text="你好,用户!", image=image, compound="top")
label.pack() # 显示图片
root.mainloop() # 保持窗口运行
为了方便演示,采用单文件模式进行打包:pyinstaller -F my_app_name.py。打包完成后,将assets文件夹放到exe所在文件夹中。
反编译exe
下面进入反编译环节。进入exe的文件夹,将下载的pyinstxtractor.py放到*.exe所在文件夹下。

在exe所在文件夹启动cmd,并输入以下命令:
python pyinstxtractor.py my_app_name.exe

运行完成后,可以看到生成了一个xxxx.exe_extracted的文件夹

进入此文件夹,可以找到一个文件名和应用名称相同,但是没有后缀的文件,这就是得到的*.pyc文件(虽然生成的时候没有后缀,不过这并不妨碍它本身的文件类型)。xxxx.exe_extracted文件夹中的其他文件则是一些依赖程序文件,等等。

添加magic number
如果你也是看准了Python,想自学Python,在这里为大家准备了丰厚的免费学习大礼包,带大家一起学习,给大家剖析Python兼职、就业行情前景的这些事儿。
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。


四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

成为一个Python程序员专家或许需要花费数年时间,但是打下坚实的基础只要几周就可以,如果你按照我提供的学习路线以及资料有意识地去实践,你就有很大可能成功!
最后祝你好运!!!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1800
1800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









