






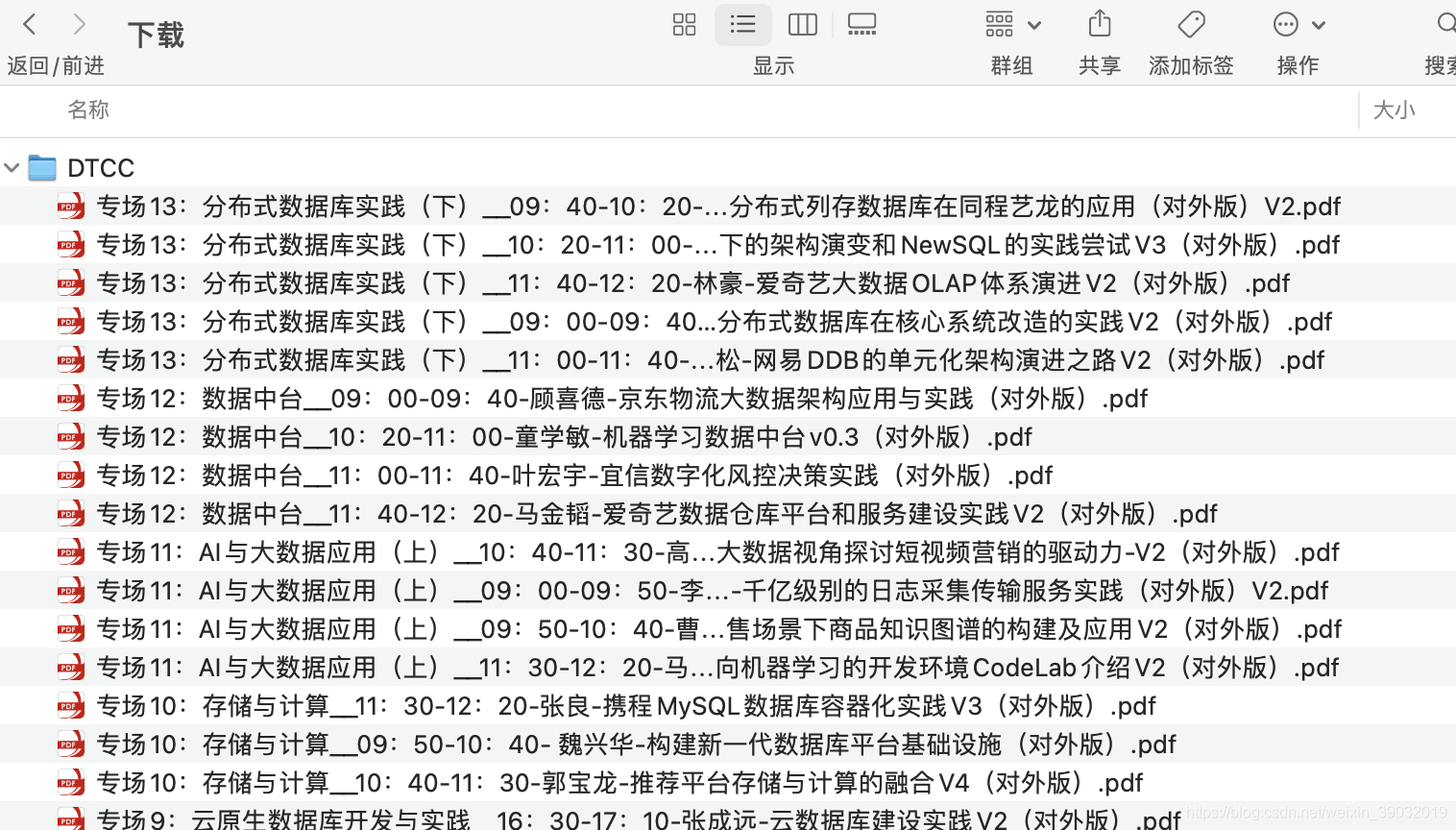
话不多说,上代码
encoding: utf-8
from bs4 import BeautifulSoup
import requests
from urllib.request import urlopen
import re
import json
def visit(url):
headers = {
“User-Agent”: “Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)”,
“accept”: “application/json, text/javascript, /; q=0.01”,
“accept-encoding”: “gzip, deflate, br”,
“accept-language”: “zh-CN,zh;q=0.9”,
“content-type”: “application/x-www-form-urlencoded; charset=UTF-8”,
“cookie”: “”, – 填自己的
“referer”: “”,
“sec-fetch-dest”: “document”,
“sec-fetch-mode”: “navigate”,
“sec-fetch-site”: “same-origin”,
}
res = requests.get(url,headers=headers)
bsObj = BeautifulSoup(res.text, “html.parser”)
return bsObj
def visit_homepage(url):
bsObj = visit(url)
content = bsObj.find(‘div’, class_=“content”)
content_list = content.select(“p”)
category = []
for i in range(4,len(content_list)):
try:
urls = content_list[i].a[‘href’]
name = content_list[i].get_text(“|”).split(“|”)[0].replace(’ ‘,’‘).replace(’\xa0’,‘’)
category.append([name,urls])
except:
pass
print(category)
return category
def download_pdf(conf,path):
category_name = conf[0]
category_url = conf[1]
bsObj = visit(category_url)
res = re.search(r’(.)token:(.?),',str(bsObj) ,re.M|re.I)
token = res.group(2).replace(‘"’,‘’).replace(’ ‘,’')
arts = re.findall(r’(.)li data-docinfo=(.?)}',str(bsObj) ,re.M|re.I)
for art in arts:
art_str = “{”+str(art).split(‘{’)[1].replace(“')”,“}”)
art_dic = json.loads(art_str)
id = art_dic[‘id’]
name = art_dic[‘name’]
download_url = “https://api.z.itpub.net/download/file?st-usertoken=%s&id=%s”%(token,str(id))
print(download_url)
data = urlopen(download_url).read()
with open(path+category_name+‘__’+name, ‘wb’) as f:
f.write(data)
print("finish download ")
if name == ‘main’:
homepage = “https://z.itpub.net/article/detail/5260C494873379BAA63BAB7C5CBD7A95”
path = “/Users/xxx/Downloads/DTCC/”
download
category = visit_homepage(homepage)
for i in category:
download_pdf(i,path)
程序下载
========
1、cookie换成自己的
最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划
















 572
572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









