







 这篇博客介绍了如何使用Python进行网络爬虫,爬取新闻网站的文章标题、URL和图片链接。通过解析HTML,提取出class为'hot-article-img'的a节点,获取每篇文章的元信息。接着,博主展示了如何下载图片并保存到本地的pic文件夹,以及如何将数据保存到数据库。涉及到的库包括requests、BeautifulSoup和chardet。
这篇博客介绍了如何使用Python进行网络爬虫,爬取新闻网站的文章标题、URL和图片链接。通过解析HTML,提取出class为'hot-article-img'的a节点,获取每篇文章的元信息。接着,博主展示了如何下载图片并保存到本地的pic文件夹,以及如何将数据保存到数据库。涉及到的库包括requests、BeautifulSoup和chardet。
import chardet
response = request.urlopen(“http://www.jianshu.com/”)
html = response.read()
charset = chardet.detect(html)# {‘language’: ‘’, ‘encoding’: ‘utf-8’, ‘confidence’: 0.99}
html = html.decode(str(charset[“encoding”])) # 解码
print(html)
由于抓取的html文档比较长,这里简单贴出来一部分给大家看下
<meta name="description" content="简书是一个优质的创作社区,在这里,你可以任性地创作,一篇短文、一张照片、一首诗、一幅画……我们相信,每个人都是生活中的艺术家,有着无穷的创造力。">
<meta name="keywords" content="简书,简书官网,图文编辑软件,简书下载,图文创作,创作软件,原创社区,小说,散文,写作,阅读">
…后面省略一大堆
这就是Python3的爬虫简单入门,是不是很简单,建议大家多敲几遍
[](https://xiaoshitou.blog.csdn.net/article/details/78041347)三,Python3爬取网页里的图片并把图片保存到本地文件夹
------------------------------------------------------------------------------------------
目标
* 爬取百度贴吧里的图片
* 把图片保存到本地,都是妹子图片奥
不多说,直接上代码,代码里的注释很详细。大家仔细阅读注释就可以理解了
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml(“http://tieba.baidu.com/p/3205263090”)
html = html.decode(‘UTF-8’)
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print(“全部抓取完成”)
迫不及待的看下都爬取到了些什么美图
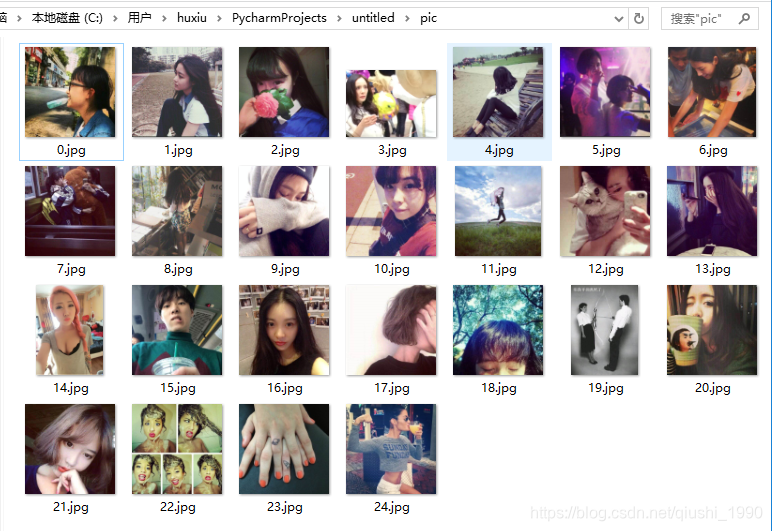
就这么轻易的爬取到了24个妹子的图片。是不是很简单。
[](https://xiaoshitou.blog.csdn.net/article/details/78041347)四,Python3爬取新闻网站新闻列表
--------------------------------------------------------------------------------
* 这里我们只爬取新闻标题,新闻url,新闻图片链接。
* 爬取到的数据目前只做展示,等我学完Python操作数据库以后会把爬取到的数据保存到数据库。
到这里稍微复杂点,就分布给大家讲解
* 1 这里我们需要先爬取到html网页上面第一步有讲怎么抓取网页
* 2分析我们要抓取的html标签

分析上图我们要抓取的信息再div中的a标签和img标签里,所以我们要想的就是怎么获取到这些信息
这里就要用到我们导入的BeautifulSoup4库了,这里的关键代码
使用剖析器为html.parser
soup = BeautifulSoup(html, ‘html.parser’)
获取到每一个class=hot-article-img的a节点
allList = soup.select(‘.hot-article-img’)
上面代码获取到的allList就是我们要获取的新闻列表,抓取到的如下
[

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1568
1568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









