







此时 methods 在运行时可以被成功解析和调用,因为已经从内核二进制文件加载了足够的信息,例如它可以解析和调用 main 库中的函数。
package:kernel/ast.dart定义了描述内核 AST 的类;package:front_end处理解析 Dart 源代码并从中构建内核 AST。dart::kernel::KernelLoader::LoadEntireProgram是将内核 AST 反序列化为相应 VM 对象的入口点;pkg/vm/bin/kernel_service.dart实现了内核服务隔离,runtime/vm/kernel_isolate.cc将 Dart 实现粘合到 VM 的其余部分;package:vm承载大多数基于内核的 VM 特定功能,例如各种内核到内核的转换;由于历史原因一些特定于 VM 的转换仍然存在于package:kernel中。
最初所有的函数都会有一个占位符,而不是它们的主体的实际可执行代码:它们指向 LazyCompileStub,它只是要求运行时系统为当前函数生成可执行代码,然后 tail-calls 这个新生成的代码。

第一次编译函数时,是通过未优化编译器完成的。
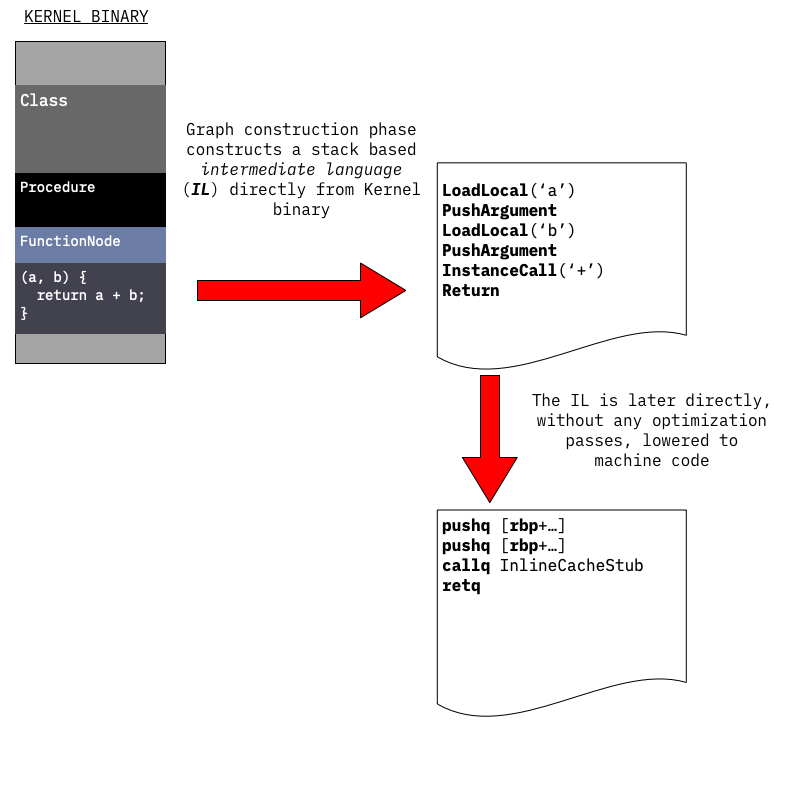
未优化编译器分两遍生成机器代码:
- 1、遍历函数体的序列化 AST 以生成函数体的控制流图( CFG ),CFG 由填充有中间语言( IL ) 指令的基本块组成。在此阶段使用的 IL 指令类似于基于堆栈的虚拟机的指令:它们从堆栈中获取操作数,执行操作,然后将结果推送到同一堆栈。
实际上并非所有函数都具有实际的 Dart / Kernel AST 主体,例如在 C++ 中定义的本地函数或由 Dart VM 生成的人工
tear-off函数,在这些情况下,IL 只是凭空创建,而不是从内核 AST 生成。
- 2、生成的 CFG 使用一对多的底层 IL 指令直接编译为机器代码:每个 IL 指令扩展为多个机器语言指令。
在此阶段没有执行任何优化,未优化编译器的主要目标是快速生成可执行代码。
这也意味着:未优化的编译器不会尝试静态解析内核二进制文件中未解析的任何调用,VM 当前不使用基于虚拟表或接口表的调度,而是使用内联缓存实现动态调用。
内联缓存的原始实现,实际上是修补函数的 native 代码,因此得名内联缓存,内联缓存的想法可以追溯到 Smalltalk-80,请参阅 Smalltalk-80 系统的高效实现。
内联缓存背后的核心思想,是在特定的调用点中缓存方法解析的结果,VM 使用的内联缓存机制包括:
-
一个调用特定的缓存(
dart::UntaggedICData),它将接收者的类映射到一个方法,如果接收者是匹配的类,则应该调用该方法,缓存还存储一些辅助信息,例如调用频率计数器,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









