







前提
顺序表的优缺点:
优点:
😔 连续的物理空间,支持根据下标随机访问
缺点:
😔插入数据,空间不足时要扩容,会造成一定的资源浪费
😔头插或中间位置插入元素时需要挪动元素,效率比较低
基于顺序表的缺点,就出现了链表.
1.单链表概念
链表是物理存储结构上非连续,非顺序的存储结构,整个链表通过对各个结点地址的链式存储来实现.链表由结点组成.
链表类似于火车,由一节节的车厢通过钩子连接起来.
那么问题来了,这些结点之间是怎么联系起来的呢?
其实是通过引用所指向的地址连接起来的.
也就是每一个结点都分为两部分,分别是数值域和next域(地址域)
结点是一个引用类型
那么存储的地址是谁的地址?
其实是下一个结点的地址
我们用有四个结点的链表来说明:这四个结点之间的关系是这样的
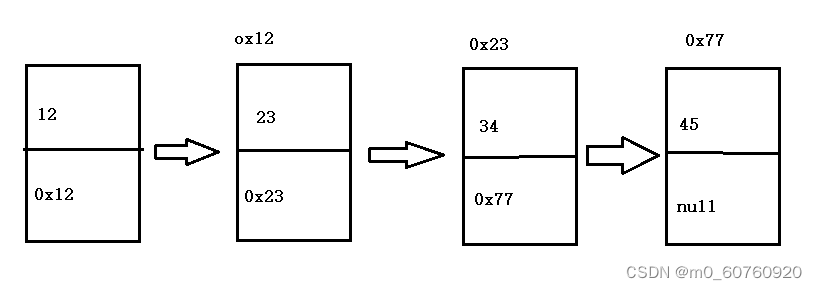
我们发现:
😔next域里面存储的就是下一个结点的引用变量(地址)
😔第四个结点的next域为null,说明没有下一个结点了
我们知道链表是由结点组成的,那么结点是怎么组成的呢?
从上面那张图片我们知道:
每一个结点都是一个独立的个体,那我们可以把它抽象成一个内部类,并放到单链表这个类里面,这样的话我们就可以在单链表这个类里面使用结点这个类.
2.单链表的创建
public class MyLinkedList {
listNode head=null;//声明链表中的头结点
//创建单链表结构,将链表中的每一个结点定义成一个内部类
public class listNode{
public int val;//结点的数值域
public listNode next;//结点的next域,存储下一个结点的地址,两个结点之间通过next关联
public listNode(int val){//构造方法,给新的结点赋值,同时next默认为null
this.val=val;
}
}
}
补充:static修饰结点类也可以,表示结点类脱离MyLinkedList也可以单独存在.
链表创建好之后,就有一些对链表的基本操作方法:
2.1 链表的初始化
那怎么初始化呢?
也就是创建一些结点,并在每一个结点中都把下一个结点的地址存储起来,让结点之间关联起来.
public listNode listInit(){
Scanner sc=new Scanner(System.in);
System.out.println("输入链表长度");
int n=sc.nextInt();
System.out.println("输入链表第1个元素的值");
int firstVal=sc.nextInt();
this.head=new listNode(firstVal);//创建链表的第一个结点,将链表的头结点引用head指向第一个结点
listNode cur=this.head;//创建cur结点去完成对链表的初始化,因为头结点head很重要,不能直接使用,否则会丢失链表
for(int i=1;i<n;i++){
System.out.println("请输入链表第"+(i+1)+"个元素的值");
int val=sc.nextInt();
listNode node=new listNode(val);
cur.next=node;//当前结点的next存放的就是下一个结点的引用变量node,node存储的就是下一个结点的地址
cur=node;//将当前结点移动到下一结点位置
}
return this.head;//返回链表头结点
}
😀
对于结点之间的连接,用到的就是cur这个结点引用变量:
当cur引用也指向第一个结点之后,cur.next就代表第一个结点的next域,只要next域存储了下一个结点的地址,这两个结点就连接起来了.
😀
从上面的代码我们也可以知道:
node引用是指向新建的结点的,也就是node里面存储的是第二个结点的地址,所以当cur.next=node,这两个结点就被连接起来了.
😔
那如果再来一个结点呢?该怎么连接?
我们只需要让cur=cur.next,cur.next=node即可
当cur=cur.next之后,那么引用变量cur所引用的就变为了第二个结点,那么cur.next=node,也就是把第三个结点的地址存储到了第二个结点的next域中.
😔
有人会问,为什么需要再定义一个结点的引用变量cur呢?用head结点引用指向的不断改变来连接各个结点不可以吗?
是可以的,但是如果用head结点来连接其他结点的话,我们还能找到head吗?还能找到这个链表吗?
我们来看个例子:为什么不能直接使用头结点head!
💗我们先手动创建一个链表:
public class MyLinkedList {
class listNode{
public int val;
public listNode next;
public listNode(int val){
this.val=val;
}
}
public listNode head;
//手动创建链表
public void createLinkedList(){
listNode node1=new listNode(12);
listNode node2=new listNode(23);
listNode node3=new listNode(34);
listNode node4=new listNode(45);
node1.next=node2;
node2.next=node3;
node3.next=node4;
head=node1;
}
//遍历链表
public void display(){
while(head!=null){
System.out.print(head.val+" ");
head=head.next;
}
}
}
💗然后我们在测试类Test中对这个链表进行打印:
public class Test {
public static void main(String[] args) {
MyLinkedList myLinkedList=new MyLinkedList();
myLinkedList.createLinkedList();
myLinkedList.display();
System.out.println();
System.out.println("=====================");
myLinkedList.display();
}
}
💗最后,我们得到的结果是:
12 23 34 45
=====================
通过这个例子,我们发现,利用head结点进行遍历打印,第一次遍历可以成功地把所有结点打印出来,但是,第二次打印这个链表的时候却没有结果.这是因为第一次打印结束之后,我们丢失了head这个结点,head结点为null了.而每一次的打印都必须先找到head结点才可以.
2.2 链表的打印
public void linkedListPrint(){
listNode cur=this.head;//创建cur引用变量去完成遍历(因为头节点不能直接使用,会丢失从而导致链表的丢失)
while(cur!=null){
System.out.println(cur.val+" ");
cur=cur.next;//打印完当前结点,就指向下一结点,完成下一结点的打印
}
System.out.println();
}
2.3 获取链表的长度
//时间复杂度为O(N)
public int getSize(){
listNode cur=this.head;
int l=0;
while (cur!=null){
l++;
cur=cur.next;
}
return l;
}
2.4 判断链表是否为空
// 为空就抛出异常,终止程序
private void isEmpty() { // 判断链表是否为空,只是该类中使用,所有
if (head == null) {
System.out.println("该链表为空!!!");
throw new NullPointerException();
// 如果抛出的是 RunTimeException 或者 RunTimeException 的子类,则可以不用处理,直接交给JVM来处理
//异常一旦抛出,其后的代码就不会执行,相当于就直接return了
}
}
以上操作就可以得到一个基本的链表了,接下来来看对链表的一些操作
3.链表的基本操作
😀在链表头部插入元素
//时间复杂度O(1)
public void addHead(int data) {
listNode node=new listNode(data);//新插入的结点node
node.next=this.head;//🧐
this.head=node;//🧐
}
注意:🧐这两行代码的顺序很重要,不要弄反!
😃尾插法
//时间复杂度O(N),找尾巴的过程
public void addLast(int val){
listNode node=new listNode(val);
if(this.head==null){
this.head=node;//当head为空,直接让head指向node即可
return;
}else {
listNode cur=this.head;
while(cur.next!=null){
cur=cur.next;
}
cur.next=node;
}
}
链表的头插,尾插都不需要挪动元素.而且链表的插入只是修改指向
😀指定下标插入元素
public void addIndex(int pos,int data){
if(pos<0||pos>this.getSize()){//pos==getSize也是可以的,这样相当于在尾部插入结点
System.out.println();
}
listNode node=new listNode(data);//要插入到新的结点
//如果是头插
if(pos==0){//当插入的是头结点时
addHead(data);
return;
}
//如果是其他位置插入
else {
listNode cur=this.head;
for(int i=0;i<pos-1;i++){//这种情况包含了尾插结点
cur=cur.next;//通过循环,让cur指向要新增下标的前一个结点
}
node.next=cur.next;//先将node结点指向下一个结点,再让cur指向node结点
cur.next=node;
}
}
😍第二种写法:
public void addPos(int pos,int val){
if(pos<0||pos>this.getSize()){//pos==getSize也是可以的,这样相当于在尾部插入结点
System.out.println();
}
listNode node=new listNode(val);
if(pos==0){
this.head=node;
} else if (pos==getSize()) {
addLast(val);
}else {
listNode cur=this.head;
for(int i=0;i<pos-1;i++){
cur=cur.next;
}
node.next=cur.next;
cur.next=node;
}
}
有一个需要注意的点:
node.next=cur.next;
cur.next=node;
这两步的顺序很重要!为什么呢?我们来看!
比如我们想在下标为2的地方插入新的结点node,那么首先我们就要通过循环找到要插入的的结点(也就是下标为2的结点)的前一个结点.
然后呢❓
容易错的地方就在于,很多人会认为,让下标为1的结点的next指向node,让node指向下标为2的结点不就可以了吗.
但这样是不对的!这种错误思路的代码是
cur.next=node;
node.next=❓
我们发现❓处不知道应该填写什么.是因为结点2原本是通过结点1来找到的,但是当执行cur.next=node之后,我们丢失了结点2,所以到了node.next=结点2时,我们无法知道结点2在哪里.
所以说,我们要特别注意!
😀删除头结点
public void deleteHead(){
if(ifEmpty()){//检查是否为空
System.out.println("链表为空,无法删除");
return;
}
if(head.next!=null){//如果head结点不是链表唯一的结点,就直接将head结点的下一节点变为新的head结点,原来的head结点自动被系统回收
this.head=this.head.next;
}
else {
this.head=null;//当链表只有一个元素的时候
}
}
😀删除指定下标的结点
public void deleteIndex(int pos){
if (pos<0||pos>=this.getSize()){//注意此时pos不能等于getSize,因为getSize位置没有结点,结点下标最大到getSize-1的地方
System.out.println("下标不合理,删除失败");
return;
}
if (pos==0){//pos==0,相当于删除的是头结点
deleteHead();
return;
}
listNode cur=this.head;//创建一个cur引用去完成循环
for (int i=1;i<pos-1;i++){//要让cur指向要删除的结点的前一个结点
cur=cur.next;
}
cur.next=cur.next.next;
}
思路就是:我们要删除一个结点,本质上就是要让其他结点不指向它,也就是其他结点的next域不存储被删除结点的引用.
😀删除所有数值为key的元素
public void deleteAllKey(int key){
if (ifEmpty()){
System.out.println("链表为空,删除失败");//检查是否为空
}
while(this.head!=null&&this.head.val==key){//删除头结点
deleteHead();
if(this.head==null){//当头结点为空,直接返回,否则会有空指针异常
return;
}
}
listNode cur=this.head;
while(cur.next!=null){
if(cur.next.val==key){
cur.next=cur.next.next;//包含删除尾结点的情况
}else {
cur=cur.next;
}
}
}
😀查找元素key是否在链表中
public boolean searchKey(int key){
listNode cur=this.head;
while (cur!=null){
if (cur.val==key){
return true;
}
else {
cur=cur.next;
}
}
return false;
}
😀清空链表
public void clear(){
this.head=null;//直接让head结点为null
}
注意:如果链表中的结点的val为引用类型的话,则用equals比较,而不是
😀总的来说:插入结点,就是让cur走到要插入位置的前一步.删除结点,也是让cur走到要删除位置的前一步
总代码
public class MyLinkedList {
listNode head=null;//声明链表中的头结点
//创建单链表结构,将链表中的每一个结点定义成一个内部类
public class listNode{
public int val;//结点的数值域
public listNode next;//结点的next域,存储下一个结点的地址,两个结点之间通过next关联
public listNode(int val){//构造方法,给新的结点赋值,同时next默认为null
this.val=val;
}
}
//链表的初始化
public listNode listInit(){
Scanner sc=new Scanner(System.in);
System.out.println("输入链表长度");
int n=sc.nextInt();
System.out.println("输入链表第1个元素的值");
int firstVal=sc.nextInt();
this.head=new listNode(firstVal);//创建链表的第一个结点,将链表的头结点引用head指向第一个结点
listNode cur=this.head;//创建cur结点去完成对链表的初始化,因为头结点head很重要,不能直接使用,否则会丢失链表
for(int i=1;i<n;i++){
System.out.println("请输入链表第"+(i+1)+"个元素的值");
int val=sc.nextInt();
listNode node=new listNode(val);
cur.next=node;//当前结点的next存放的就是下一个结点的引用变量node,node存储的就是下一个结点的地址
cur=node;//将当前结点移动到下一结点位置
}
return this.head;//返回链表头结点
}
//链表的打印
public void linkedListPrint(){
listNode cur=this.head;//创建cur引用变量去完成遍历(因为头节点不能直接使用,会丢失从而导致链表的丢失)
while(cur!=null){
System.out.print(cur.val+" ");
cur=cur.next;//打印完当前结点,就指向下一结点,完成下一结点的打印
}
System.out.println();
}
//获取链表长度
public int getSize(){
listNode cur=this.head;
int l=0;
while (cur!=null){
l++;
cur=cur.next;
}
return l;
}
//判断链表是否为空
private boolean ifEmpty() { // 判断链表是否为空,只是该类中使用,所有
if (head == null) {
System.out.println("该链表为空!!!");
return true;
}
return false;
}
//在链表头部插入元素
public void addHead(int data) {
listNode node=new listNode(data);//新插入的结点node
node.next=this.head;
this.head=node;
}
//指定下标插入元素
public void addIndex(int pos,int data){
if(pos<0||pos>this.getSize()){//pos==getSize也是可以的,这样相当于在尾部插入结点
System.out.println("pos位置不合法,插入失败");
return;
}
listNode node=new listNode(data);//要插入到新的结点
//如果是头插
if(pos==0){//当插入的是头结点时
addHead(data);
return;
}
//如果是其他位置插入
else {
listNode cur=this.head;
for(int i=0;i<pos-1;i++){//这种情况包含了尾插结点
cur=cur.next;//通过循环,让cur指向要新增下标的前一个结点
}
node.next=cur.next;//先将node结点指向下一个结点,再让cur指向node结点
cur.next=node;
}
}
//删除头结点
public void deleteHead(){
if(ifEmpty()){//检查是否为空
System.out.println("链表为空,无法删除");
return;
}
if(head.next!=null){//如果head结点不是链表唯一的结点,就直接将head结点的下一节点变为新的head结点,原来的head结点自动被系统回收
this.head=this.head.next;
}
else {
this.head=null;//当链表只有一个元素的时候
}
}
//删除指定下标的结点
public void deleteIndex(int pos){
if (pos<0||pos>=this.getSize()){//注意此时pos不能等于getSize,因为getSize位置没有结点,结点下标最大到getSize-1的地方
System.out.println("下标不合理,删除失败");
return;
}
if (pos==0){//pos==0,相当于删除的是头结点
deleteHead();
return;
}
listNode cur=this.head;//创建一个cur引用去完成循环
for (int i=1;i<pos-1;i++){//要让cur指向要删除的结点的前一个结点
cur=cur.next;
}
cur.next=cur.next.next;
}
//找到关键字key的前驱结点
public listNode searchPrev(int key){
if(this.head==null){//一个结点都没有
return null;
}
listNode cur=this.head;
while(cur.next!=null){//当cur.next==null时说明没有要删除的结点
if(cur.next.val==key){
return cur;//cur是要删除的key的前驱结点
}
cur=cur.next;
}
return null;//没有要删除的结点
}
//删除链表中第一个数值为key的元素
public void deleteKey(int key){
if(head.val==key){
head=head.next;
return;
}
listNode node=searchPrev(key);
if(node==null){
return;
}
listNode del=node.next;//要删除的结点
node.next=del.next;
}
//删除链表所有数值为key的结点
public void deleteAllKey(int key){
if (ifEmpty()){
System.out.println("链表为空,删除失败");//检查是否为空
}
while(this.head!=null&&this.head.val==key){//删除头结点
deleteHead();
if(this.head==null){//当头结点为空,直接返回,否则会有空指针异常
return;
}
}
listNode cur=this.head;
while(cur.next!=null){
if(cur.next.val==key){
cur.next=cur.next.next;//包含删除尾结点的情况
}else {
cur=cur.next;
}
}
}
//查找元素key是否在链表中
public boolean searchKey(int key){
listNode cur=this.head;
while (cur!=null){
if (cur.val==key){
return true;
}
else {
cur=cur.next;
}
}
return false;
}
}
测试代码
public class Test {
public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.listInit();
System.out.println("链表初始化后.第一次打印");
myLinkedList.linkedListPrint();
System.out.println("==========================");
myLinkedList.addHead(5);
System.out.println("头插元素5之后,第二次打印");
myLinkedList.linkedListPrint();
System.out.println("==========================");
myLinkedList.addIndex(2, 9);
System.out.println("在下标1处插入元素9之后,第三次打印");
myLinkedList.linkedListPrint();
System.out.println("==========================");
myLinkedList.deleteIndex(3);
System.out.println("删除下标为3的元素后,第四次打印");
myLinkedList.linkedListPrint();
System.out.println("==========================");
myLinkedList.deleteHead();
System.out.println("删除头结点后,第五次打印");
myLinkedList.linkedListPrint();
System.out.println("===========================");
myLinkedList.deleteAllKey(2);
System.out.println("删除所有值为2的元素后,第六次打印");
myLinkedList.linkedListPrint();
System.out.println("===========================");
System.out.println("输出链表的长度");
System.out.println(myLinkedList.getSize());
}
}
结果
输入链表长度
4
输入链表第1个元素的值
1
请输入链表第2个元素的值
2
请输入链表第3个元素的值
3
请输入链表第4个元素的值
4
链表初始化后.第一次打印
1 2 3 4
==========================
头插元素5之后,第二次打印
5 1 2 3 4
==========================
在下标1处插入元素9之后,第三次打印
5 1 9 2 3 4
==========================
删除下标为3的元素后,第四次打印
5 1 2 3 4
==========================
删除头结点后,第五次打印
1 2 3 4
===========================
删除所有值为2的元素后,第六次打印
1 3 4
===========================
输出链表的长度
3
4. 链表面试题
😎反转一个单链表 OJ链接
大体思路:将第一个结点之后的元素都用头插法,插入到链表头部
代码:
//空间复杂度要求O(1)
//时间复杂度要求O(N)
//利用遍历,头插法
public listNode reverse(){
if(this.head==null){
return null;
}
if(this.head.next==null){
return this.head;
}
listNode cur=head.next;
head.next=null;
while (cur!=null){
listNode curNext=cur.next;
cur.next=head;
head=cur;
cur=curNext;
}
return head;
}
😎链表的中间结点 OJ链接
大体思路:快慢指针,也就是创建一个fast引用,一个slow引用,先指向head结点,fast每次走两步,slow每次走一步,fast的速度是slow的两倍,同样的路程,当fast走到最后,slow的位置刚好就是中间位置.
奇数个结点的时候,fast.next==null,就找到了中间结点.偶数个结点的时候,fast为空,就找到了.
代码:
public listNode middleNode(listNode head){
listNode fast=this.head;
listNode slow=this.head;
while(fast!=null&&fast.next!=null){//这一步很重要!顺序一定先是fast!=null,然后是fast.next!=null
//而不能先是fast.next!=null,然后是fast!=null,这样会发生空指针异常
fast=fast.next.next;
slow=slow.next;
}
return slow;
}
😎返回倒数第k个结点 OJ链接
方法一:
大体思路:最后一个结点与倒数第k个结点差k-1步.先让fast走k-1步,然后fast走一步,slow走一步,直到fast.next为null的时候.此时slow所指的就是倒数第k个结点.
代码:
public listNode kthToLast2(listNode head,int k){
if(k<=0||k>getSize()){
return null;
}
if(head==null){
return null;
}
listNode fast=this.head;
listNode slow=this.head;
while(k-1!=0){//让fast先走k-1步
fast=fast.next;
k--;
if(fast==null){
return null;
}
}
while (fast.next!=null){//fast走一步,slow走一步
fast=fast.next;
slow=slow.next;
}
return slow;
}
方法二:
大体思路:倒数第k个结点,就往后走getSize()-k步,此时就是要找的结点
代码:
public listNode kthToLast(listNode head,int k){
listNode cur=this.head;
if(k<1||k>this.getSize()){
System.out.println("k输出不正确,无法找到");
}else {
if(this.head==null){
return null;
} else if (this.head.next==null) {
return this.head;
}else {
for(int i=0;i<getSize()-k;i++){
cur=cur.next;
}
}
}
return cur;
}
😎合并两个有序链表 OJ链接
大体思路:双指针遍历两个链表,比较结点大小关系,两个指针交替前进,直到遍历结束.
重要的一点:引入伪头结点,因为刚开始合并链表并没有结点,所以无法将结点添加到合并链表中.
解决方案:就是引入一个结点作为合并链表的伪头结点,将其他结点添加到这个伪结点之后.
需要注意的地方:当两个链表不一样长,那么就会跳出while循环,跳出之后,直接将没有遍历完的链表添加到合并链表后面,因为这两个链表本身就是有序的.
代码:
public listNode mergeTwoLists(listNode list1, listNode list2) {
listNode newHead=new listNode(0);
listNode tmp=newHead;
while(list1!=null&&list2!=null){
if(list1.val<list2.val){
tmp.next=list1;
list1=list1.next;
tmp=tmp.next;
}else {
tmp.next=list2;
list2=list2.next;
tmp=tmp.next;
}
}
tmp.next=(list1==null?list2:list1);
return newHead.next;
}
😎回文链表 OJ链接
大体思路:找到中间结点,然后将中间结点之后的结点翻转,然后双指针进行判断.
需要注意的地方:偶数个结点和奇数个结点的不同处理
代码:
public boolean isPalindrome(listNode head){
listNode fast=head;
listNode slow=head;
if(head==null){
return false;
}
if(head.next==null){
return true;
}
//1.找中间结点
while (fast!=null&&fast.next!=null){//这两个判断缺一不可,而且顺序很重要,否则会报空指针异常
fast=fast.next.next;
slow=slow.next;
}
listNode cur=slow.next;
//2.翻转中间结点后的结点
while(cur!=null){
listNode curNext=cur.next;
cur.next=slow;
slow=cur;
cur=curNext;
}
//3.双指针判断
while(head!=slow){
if(head.val!=slow.val){
return false;
}
if(head.next==slow){//当结点个数为偶数个,需要增加这个判断
return true;
}
}
return true;
}
😎链表分割 OJ链接
大体思路:遍历完这个链表之后,我们会得到两个链表,一个是数据小于x的链表small,一个是数据大于x的链表large,最后我们只需要将small链表的尾结点指向large链表的头结点即可.
注意:
关键的一点在于我们要为两个链表分别创建一个傀儡结点,分别是smallHead和largeHead,用傀儡结点的next去指向两个链表的头结点.
为什么要这样做呢?
是为了更方便的处理头结点为空的边界情况,在遍历结束后,small要指向它的链表的结尾,large要指向它的链表的结尾.
最后不要忘了,将large.next设置为null,是因为当前这个结点是复用的原来链表的结点,这个结点的next可能指向下一个不属于large链表里的结点,那么我们就要通过large.next=null来切断这个引用.
代码:
class Solution {
public ListNode partition(ListNode head, int x) {
ListNode small=new ListNode(0);
ListNode smallHead=small;
ListNode large=new ListNode(0);
ListNode largeHead=large;
ListNode cur=head;
while(cur!=null){
if(cur.val<x){
small.next=cur;
small=small.next;
}else{
large.next=cur;
large=large.next;
}
cur=cur.next;
}
large.next=null;
small.next=largeHead.next;
return smallHead.next;
}
}
😎相交链表 OJ链接
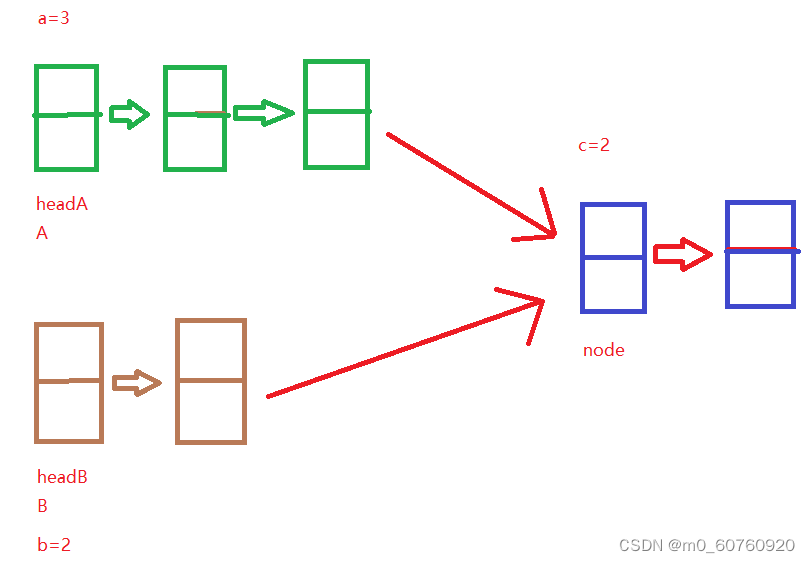
大体思路:采用双指针,设这两个链表的第一个公共结点为node,两个链表的头结点分别为headA和headB,设headA链表的结点数为a,headB链表的结点数为b,两个链表的相交部分的结点数为c.
那么就有,headA到node前,有a-c个结点.headB到node前,有b-c个结点.
创建两个结点引用变量A和B,分别指向headA和headB.
然后让A先遍历headA指向的链表,再遍历headB指向的链表,当A走到node时,总共走了a+(b-c)步.
让B先遍历headB指向的链表,再遍历headA指向的链表,当B走到node时,总共走了b+(a-c)步.
a+(b-c)=b+(a-c),此时A和B重合.
有两种情况:
😁(1)两个链表有公共尾部:也就是c>0,A和B同时指向node
😁(2)没有公共尾部:也就是c=0,那么A和B同时指向null
所以,最后返回A即可.
代码:
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode A=headA;
ListNode B=headB;
while(A!=B){
A=(A!=null?A.next:headB);
B=(B!=null?B.next:headA);
}
return A;
}
😎判断链表中是否有环 OJ链接
大体思路:利用快慢指针.让快指针走两步,慢指针走一步
那么就出现一个问题:为什么非得是快指针走两步,慢指针走一步呢?可不可以快指针走三步,四步,N步…,慢指针走一步?
原因是快指针走三步,慢指针走一步这两个指针可能永远都不会相遇.因为有环,而且存在速度差,所以是追及相遇问题.
假设链表带环,那么两个指针最后都会进入环,快指针先进环,慢指针后进环,可能就和快指针相遇了,最差情况下两个指针之间的距离正好是环的长度,此时,两个指针每移动一次,之间的距离就缩小一步,不会出现每次刚好是套圈的情况.因此:在慢指针走到一圈之前,快指针肯定是可以追上慢指针的,也就是相遇.
我们来举个例子说明一下为什么不能是快指针走三步,慢指针走一步:
假设:我们让快指针每次走三步,慢指针每次走一步,那么肯定是**快指针先进环,慢指针后进环.**假设这两个指针的位置如图所示:
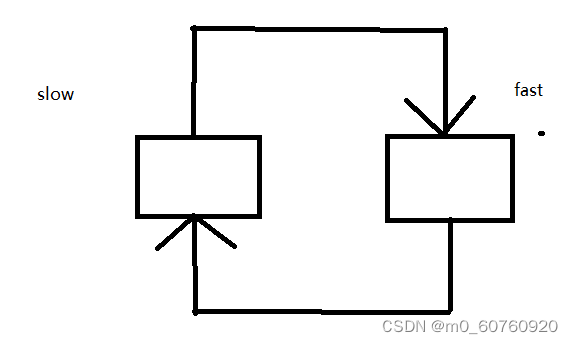
此时按照三倍的速度差来移动,那这两个指针是永远不会相遇的.
只有快指针每次走两步,慢指针每次走一步才可以,因为环的最小长度为1,即使套圈了,这两个指针也在相同的位置.
代码:
public boolean hasCycle(ListNode head) {
ListNode fast=head;
ListNode slow=head;
while(fast!=null&&fast.next!=null){
fast=fast.next.next;
slow=slow.next;
if(fast==slow){
return true;
}
}
return false;
}
😎环形链表二 OJ链接
大体思路:
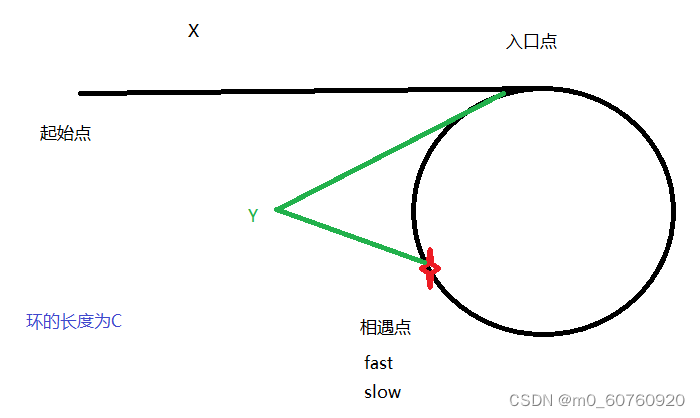
从起始结点开始,fast每次走两步,slow每次走一步,那么在环中相遇后,由于fast的速度是slow的2倍,所以fast走的路程也是slow的2倍.
fast走的路程是:X+C+(C-Y)
slow走的路程是:X+(C-Y)
所以得到表达式:X+C+(C-Y)=2*(X+(C-Y))
最后得出XY==
所以在得出相遇结点后,让fast或者slow回到起始结点,以相同的速度走(每次走一步),那么再次相遇的结点就是入口结点.
代码:
public ListNode detectCycle(ListNode head) {
ListNode fast=head;
ListNode slow=head;
while(fast!=null&&fast.next!=null){
fast=fast.next.next;
slow=slow.next;
if(fast==slow){
break;
}
}
if(fast==null||fast.next==null){
return null;
}
slow=head;
while(fast!=slow){
fast=fast.next;
slow=slow.next;
}
return fast;
}















 1933
1933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









