







题目描述
观察下面的数字金字塔。
写一个程序来查找从最高点到底部任意处结束的路径,使路径经过数字的和最大。每一步可以走到左下方的点也可以到达右下方的点。
7
3 8
8 1 0
2 7 4 4
4 5 2 6 5
在上面的样例中,从7→3→8→7→5 的路径产生了最大
输入格式
第一个行一个正整数 r ,表示行的数目。
后面每行为这个数字金字塔特定行包含的整数。
输出格式
单独的一行,包含那个可能得到的最大的和。
输入输出样例
输入 #1
5 7 3 8 8 1 0 2 7 4 4 4 5 2 6 5
输出 #1
30
说明/提示
【数据范围】
对于 100% 的数据,1≤r≤1000,所有输入在[0,100] 范围内。
题目翻译来自NOCOW。
USACO Training Section 1.5
IOI1994 Day1T1
分析:应该算是非常经典的一道题了。
本次尝试多种方法并进行算法和时间复杂度上分析加深理解。
先来一发dfs:
#include <iostream>
#include<math.h>
#include<string>
#include<vector>
#include<algorithm>
using namespace std;
int n;
int arr[1001][1001] = { 0 };
int mx = 0;
void dfs(int x, int y,int sum) {//简单dfs
if (x > n) {
mx = max(mx, sum);//取大
return;
}
dfs(x + 1, y,sum+arr[x][y]);//向下搜的同时,加上本格的和
dfs(x + 1, y + 1, sum + arr[x][y]);
}
int main() {
cin >> n;
for (int j = 1; j <= n; j++)
for (int i = 1; i <= j; i++)
cin >> arr[j][i];
dfs(1, 1,0);
cout << mx;
return 0;
}直接tle。结果自然是没错,但是深搜把每条路径都搜了一遍,这题也没法用简单的用贪心剪枝,时间超的有些离谱也是正常的。

目前没想到怎么优化,换个方法。
先看样例,
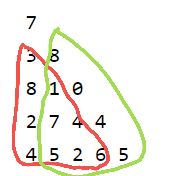
比如从第一个点的时候要算最大路径,有两条路,向左向右。可以看成,这一点的值加上以下一点为起点的最大值路径。写成递推式:
说人话也就是要计算以这一点为起点向下走可以产生的最大值,可以看作这一点的值加上以为起点下一点可以产生的最大值(红色和绿色中的最大值)而以下一点为起点可以产生的最大值又可以看作下一点的值加上下下点的......
这样就把一个大问题逐渐化为更小的问题,直到到最后一行,没办法选择选左边还是右边了,就返回该点的值。也就是递推和递归的思想。
根据递推式,我们可以写出代码:
#include <iostream>
#include<math.h>
#include<string>
#include<vector>
#include<algorithm>
using namespace std;
int n;
int arr[1001][1001] = { 0 };
int maxx = 0;
int dfs(int x, int y) {
if (y == n) {//到最底下一层开始返回,因为没得选了
return arr[y][x];
}
return arr[y][x] + max(dfs(x, y + 1), dfs(x + 1, y + 1));//见图,选择最大的那一部分
/*每次函数分成左右两个部分求解
此层一直加上最大的下一层,即可得到最大值路径
*/
}
int main() {
cin >> n;
for (int j = 1; j <= n; j++) {
for (int i = 1; i <= j; i++) {
cin >> arr[j][i];
}
}
int t = dfs(1, 1);
cout << t;
}问题解决了吗?来看看评测结果
(递归)

与之前的dfs比较一下
(深搜)
好像没有什么区别,因为尽管这样写看起来有所改进,但跟直接深搜一样时间复杂度都是O(2^n)。
深搜的时间复杂度不难理解,把每条路都遍历了,有两个选择,时间复杂度为O(2^n)。
而这个递归,虽然看起来每次都是计算一遍之前的结果最后取最优的结果,但是每次计算一遍之前的结果,不是计算一次,而是要调用一次递归,递归的每层又要调用之前的函数,导致时间复杂度非常高。但这样写不深搜好的一个方面,就是容易优化,用记忆化搜索。就是开一个数组记入到每个点时该调用的值。
记忆化搜索
#include <iostream>
#include<math.h>
#include<string>
#include<vector>
#include<algorithm>
#include<string.h>
using namespace std;
int n;
int arr[1001][1001] = { 0 };
int maxx = 0;
int rec[10001][1001] = { 0 };//记忆数组,记录每个点对应能走的最大值
int dfs(int x, int y) {
if (y == n) {
return arr[y][x];
}
if (rec[y][x] == -1)//这里-1表示记忆数组还没有记录该点,如果输入数据含-1,自己改成输入取不到的数即可
rec[y][x] = max(dfs(x, y + 1), dfs(x + 1, y + 1));//递推式
return (arr[y][x] + rec[y][x]);
/*每次函数分成左右两个部分求解
此层一直加上最大的下一层,即可得到最大值路径
*/
}
int main() {
memset(rec, -1, sizeof(rec));//初始化记忆数组
cin >> n;
for (int j = 1; j <= n; j++) {
for (int i = 1; i <= j; i++) {
scanf("%d",&arr[j][i]);
}
}
int t = dfs(1, 1);
cout << t;
}记忆化之后每次计算该点能走的最大值只需要调用一次函数。

可以跟之前的结果对比。(这里前几个测试点的时间比原来的长。已经测试了是memset初始数组的效率太低,跟算法本身关系不大,从后面几个数据较大的测试点更可以看出记忆化搜索的高效率)
(后来才知道这个方法就是dp。。。orz)
尝试分析一下时间复杂度:
以这张样例为例:


因为还没学数据结构,感觉有些困难,不过还是试试吧。
首先递推式的时间复杂度为O(F(n)),这里应该是线性递推。而且由于记忆化,只计算一次也就是O(n),但在三角形上每走一点都要计算一次递推,时间复杂度应该是O(n^2)
但具体常数怎么考虑的还不是很懂,继续学吧。应该开始学dp了,这段时间多在写递归和搜索,虽然感觉自己还是挺菜的搜索也写不了什么难题,但还是得继续,希望寒假可以开绿题orz。
就这题来说虽然简单,不过还是学到了好多,希望以后可以这样多去总结和思考,不要一味追求题目数量。
小彩蛋
前面写了深搜本来想顺便把广搜的也写一遍,虽然知道同一图里广搜和深搜平均效率其实是一样的,但是想练一下。本来应该挺常规的,但评测的时候发生了点意外。
先上源码:
#include <iostream>
#include<math.h>
#include<string>
#include<vector>
#include<algorithm>
#include<queue>
using namespace std;
int n;
int arr[1001][1001] = { 0 };
int mx = 0;
struct node {//队列元素
int x;
int y;
int sum;
};
int used[10001][1001] = { 0 };
void bfs(int x, int y) {
//总思路就是广搜纯暴力把全图遍历一遍,然后最后在星号**处进行“结算”,计算最值;
queue<node>q;
q.push({ 1,1,0 });
while (!q.empty()) {
node now = q.front();
int* p =q.end();
q.pop();
//↓此处父节点已到了最后一层,开始对最后一批父节点的所有子节点结算
/***/ if (now.x > n) {
mx = max(now.sum, mx);
}
else {//注意加else,到了最后一层不继续往下添加节点了
int nextx = now.x + 1, nexty = now.y + 1;
if (used[nextx][nexty] == 0)
{
q.push({ nextx,nexty,now.sum + arr[now.x][now.y] });
used[now.x][now.y] = 1;
}
nextx = now.x + 1, nexty = now.y;
if (used[nextx][nexty] == 0)
{
q.push({ nextx,nexty,now.sum + arr[now.x][now.y] });
used[now.x][now.y] = 1;
}
}
}
}
int main() {
cin >> n;
for (int j = 1; j <= n; j++)
for (int i = 1; i <= j; i++)
cin >> arr[j][i];
bfs(1, 1);
cout << mx;
return 0;
}然后结果

跟纯深搜的对比一下(注意广搜的未通过点是mle内存炸了)
很少见这种爆内存的,不过大概可以猜到是数据量太大时队列的子节点过多然后爆了。去上网搜了一下,发现这还不是主要的,主要的是STL的queue的pop操作只弹出元素不释放内存,也就是整个过程的节点全部存下来了没有释放。而深搜中每次函数递归完return会释放此时的栈也就是内存。stl的queue不释放内存这个就有点离谱了。我尝试去问了问学长,

然后我现在不想评价这个屑(
















 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









