







目录
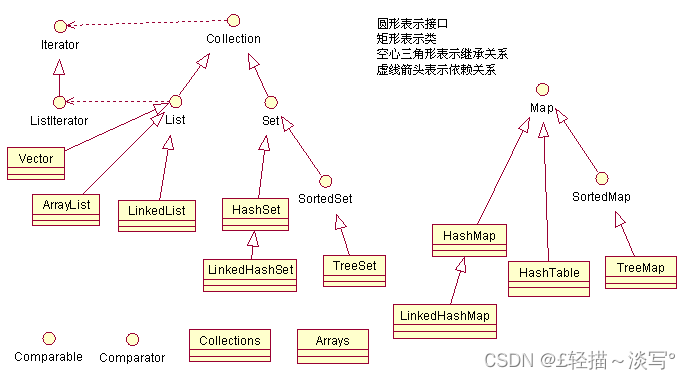
一、UML(统一建模语言)集合框架类图
二、Java集合框架概述
集合可以看作是一种容器,用来存储对象信息。所有集合类都位于java.util包下,但支持多线程的集合类位于java.util.concurrent包下。
数组与集合的区别如下:
1)数组长度不可变化而且无法保存具有映射关系的数据;集合类用于保存数量不确定的数据,以及保存具有映射关系的数据。
2)数组元素既可以是基本类型的值,也可以是对象;集合只能保存对象。
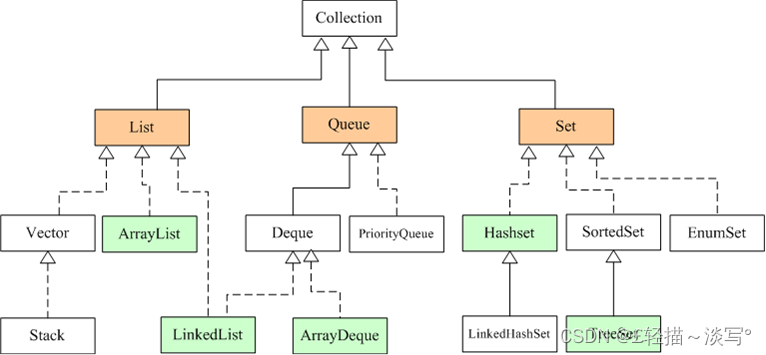
Java集合类主要由两个根接口Collection和Map派生出来的,Collection派生出了三个子接口:List、Set、Queue(Java5新增的队列),因此Java集合大致也可分成List、Set、Queue、Map四种接口体系,(注意:Map不是Collection的子接口)。
其中List代表了有序可重复集合,可直接根据元素的索引来访问;Set代表无序不可重复集合,只能根据元素本身来访问;Queue是队列集合;Map代表的是存储key-value对的集合,可根据元素的key来访问value。
上图中淡绿色背景覆盖的是集合体系中常用的实现类,分别是ArrayList、LinkedList、ArrayQueue、HashSet、TreeSet、HashMap、TreeMap等实现类。
二、Java集合常见接口及实现类
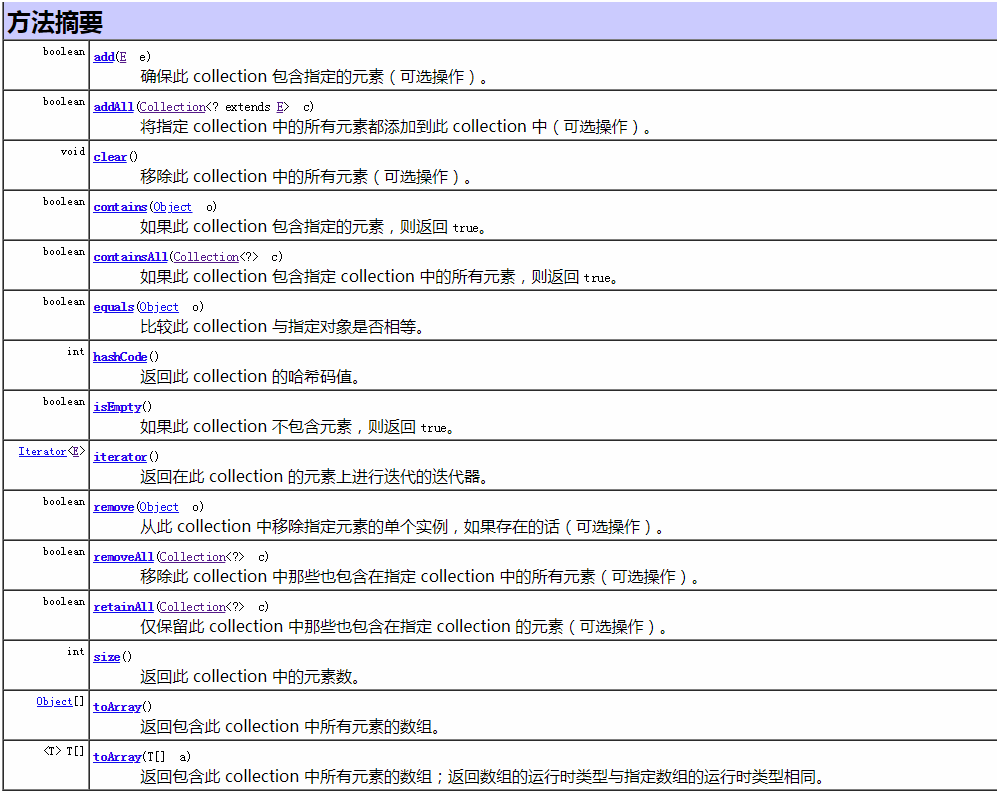
1. Collection接口常见方法(来源于Java API)
2. Set集合
Set集合与Collection的方法相同,由于Set集合不允许存储相同的元素,所以如果把两个相同元素添加到同一个Set集合,则添加操作失败,新元素不会被加入,add()方法返回false。为了帮助理解,请看下面代码示例:
public class Test {
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("hello world");
set.add("hello 美好的世界");
set.add("hello 美好的世界");//添加不进去
System.out.println("集合中元素个数:"+set.size());
System.out.println("集合中元素为:"+set.toString());
}
}运行结果如下:
集合中元素个数:2
集合中元素为:[hello world, hello 美好的世界]
分析:由于String类中重写了hashCode()和equals()方法,用来比较指向的字符串对象所存储的字符串是否相等。所以这里的第二个"hello 美好的世界"是加不进去的。
下面着重介绍Set集合几个常用实现类:
1)HashSet类
HashSet是Set集合最常用实现类,是其经典实现。HashSet是按照hash算法来存储元素的,因此具有很好的存取和查找性能。
HashSet具有如下特点:
♦ 不能保证元素的顺序。
♦ HashSet不是线程同步的,如果多线程操作HashSet集合,则应通过代码来保证其同步。
♦ 集合元素值可以是null。
HashSet存储原理如下:
当向HashSet集合存储一个元素时,HashSet会调用该对象的hashCode()方法得到其hashCode值,然后根据hashCode值决定该对象的存储位置。HashSet集合判断两个元素相等的标准是(1)两个对象通过equals()方法比较返回true;(2)两个对象的hashCode()方法返回值相等。因此,如果(1)和(2)有一个不满足条件,则认为这两个对象不相等,可以添加成功。如果两个对象的hashCode()方法返回值相等,但是两个对象通过equals()方法比较返回false,HashSet会以链式结构将两个对象保存在同一位置,这将导致性能下降,因此在编码时应避免出现这种情况。
HashSet查找原理如下:
基于HashSet以上的存储原理,在查找元素时,HashSet先计算元素的HashCode值(也就是调用对象的hashCode方法的返回值),然后直接到hashCode值对应的位置去取出元素即可,这就是HashSet速度很快的原因。
重写hashCode()方法的基本原则如下:
♦ 在程序运行过程中,同一个对象的hashCode()方法返回值应相同。
♦ 当两个对象通过equals()方法比较返回true时,这两个对象的hashCode()方法返回值应该相等。
♦ 对象中用作equals()方法比较标准的实例变量,都应该用于计算hashCode值。
2)LinkedHashSet类
LinkedHashSet是HashSet的一个子类,具有HashSet的特性,也是根据元素的hashCode值来决定元素的存储位置。但它使用链表维护元素的次序,元素的顺序与添加顺序一致。由于LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet,但在迭代访问Set里的全部元素时由很好的性能。
3)TreeSet类
TreeSet时SortedSet接口的实现类,TreeSet可以保证元素处于排序状态,它采用红黑树的数据结构来存储集合元素。TreeSet支持两种排序方法:自然排序和定制排序,默认采用自然排序。
♦ 自然排序
TreeSet会调用集合元素的compareTo(Object obj)方法来比较元素的大小关系,然后将元素按照升序排列,这就是自然排序。如果试图将一个对象添加到TreeSet集合中,则该对象必须实现Comparable接口,否则会抛出异常。当一个对象调用方法与另一个对象比较时,例如obj1.compareTo(obj2),如果该方法返回0,则两个对象相等;如果返回一个正数,则obj1大于obj2;如果返回一个负数,则obj1小于obj2。
Java常用类中已经实现了Comparable接口的类有以下几个:
♦ BigDecimal、BigDecimal以及所有数值型对应的包装类:按照它们对应的数值大小进行比较。
♦ Charchter:按照字符的unicode值进行比较。
♦ Boolean:true对应的包装类实例大于false对应的包装类实例。
♦ String:按照字符串中的字符的unicode值进行比较。
♦ Date、Time:后面的时间、日期比前面的时间、日期大。
对于TreeSet集合而言,它判断两个对象是否相等的标准是:两个对象通过compareTo(Object obj)方法比较是否返回0,如果返回0则相等。
♦ 定制排序
想要实现定制排序,需要在创建TreeSet集合对象时,提供一个Comparator对象与该TreeSet集合关联,由Comparator对象负责集合元素的排序逻辑。
综上:自然排序实现的是Comparable接口,定制排序实现的是Comparator接口。(具体代码实现会在后续章节中讲解)
4)EnumSet类
EnumSet是一个专为枚举类设计的集合类,不允许添加null值。EnumSet的集合元素也是有序的,它以枚举值在Enum类内的定义顺序来决定集合元素的顺序。
5)各Set实现类的性能分析
HashSet的性能比TreeSet的性能好(特别是添加,查询元素时),因为TreeSet需要额外的红黑树算法维护元素的次序,如果需要一个保持排序的Set时才用TreeSet,否则应该使用HashSet。
LinkedHashSet是HashSet的子类,由于需要链表维护元素的顺序,所以插入和删除操作比HashSet要慢,但遍历比HashSet快。
EnumSet是所有Set实现类中性能最好的,但它只能 保存同一个枚举类的枚举值作为集合元素。
以上几个Set实现类都是线程不安全的,如果多线程访问,必须手动保证集合的同步性,这在后面的章节中会讲到。
3. List集合
List集合代表一个有序、可重复集合,集合中每个元素都有其对应的顺序索引。List集合默认按照元素的添加顺序设置元素的索引,可以通过索引(类似数组的下标)来访问指定位置的集合元素。
实现List接口的集合主要有:ArrayList、LinkedList、Vector、Stack。
1)ArrayList
ArrayList是一个动态数组,也是我们最常用的集合,是List类的典型实现。它允许任何符合规则的元素插入甚至包括null。每一个ArrayList都有一个初始容量(10),该容量代表了数组的大小。随着容器中的元素不断增加,容器的大小也会随着增加。在每次向容器中增加元素的同时都会进行容量检查,当快溢出时,就会进行扩容操作。所以如果我们明确所插入元素的多少,最好指定一个初始容量值,避免过多的进行扩容操作而浪费时间、效率。
ArrayList擅长于随机访问。同时ArrayList是非同步的。
2)LinkedList
LinkedList是List接口的另一个实现,除了可以根据索引访问集合元素外,LinkedList还实现了Deque接口,可以当作双端队列来使用,也就是说,既可以当作“栈”使用,又可以当作队列使用。
LinkedList的实现机制与ArrayList的实现机制完全不同,ArrayLiat内部以数组的形式保存集合的元素,所以随机访问集合元素有较好的性能;LinkedList内部以链表的形式保存集合中的元素,所以随机访问集合中的元素性能较差,但在插入删除元素时有较好的性能。
3)Vector
与ArrayList相似,但是Vector是同步的。所以说Vector是线程安全的动态数组。它的操作与ArrayList几乎一样。
4)Stack
Stack继承自Vector,实现一个后进先出的堆栈。Stack提供5个额外的方法使得Vector得以被当作堆栈使用。基本的push和pop 方法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置。Stack刚创建后是空栈。
5)Iterator接口和ListIterator接口
Iterator是一个接口,它是集合的迭代器。集合可以通过Iterator去遍历集合中的元素。Iterator提供的API接口如下:
♦ boolean hasNext():判断集合里是否存在下一个元素。如果有,hasNext()方法返回 true。
♦ Object next():返回集合里下一个元素。
♦ void remove():删除集合里上一次next方法返回的元素。
ListIterator接口继承Iterator接口,提供了专门操作List的方法。ListIterator接口在Iterator接口的基础上增加了以下几个方法:
♦ boolean hasPrevious():判断集合里是否存在上一个元素。如果有,该方法返回 true。
♦ Object previous():返回集合里上一个元素。
♦ void add(Object o):在指定位置插入一个元素。
以上两个接口相比较,不难发现,ListIterator增加了向前迭代的功能(Iterator只能向后迭代),ListIterator还可以通过add()方法向List集合中添加元素(Iterator只能删除元素)。
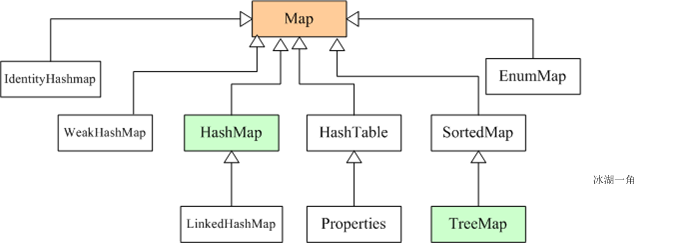
4. Map集合
Map接口采用键值对Map<K,V>的存储方式,保存具有映射关系的数据,因此,Map集合里保存两组值,一组值用于保存Map里的key,另外一组值用于保存Map里的value,key和value可以是任意引用类型的数据。key值不允许重复,可以为null。如果添加key-value对时Map中已经有重复的key,则新添加的value会覆盖该key原来对应的value。常用实现类有HashMap、LinkedHashMap、TreeMap等。
Map常见方法(来源于API)如下:
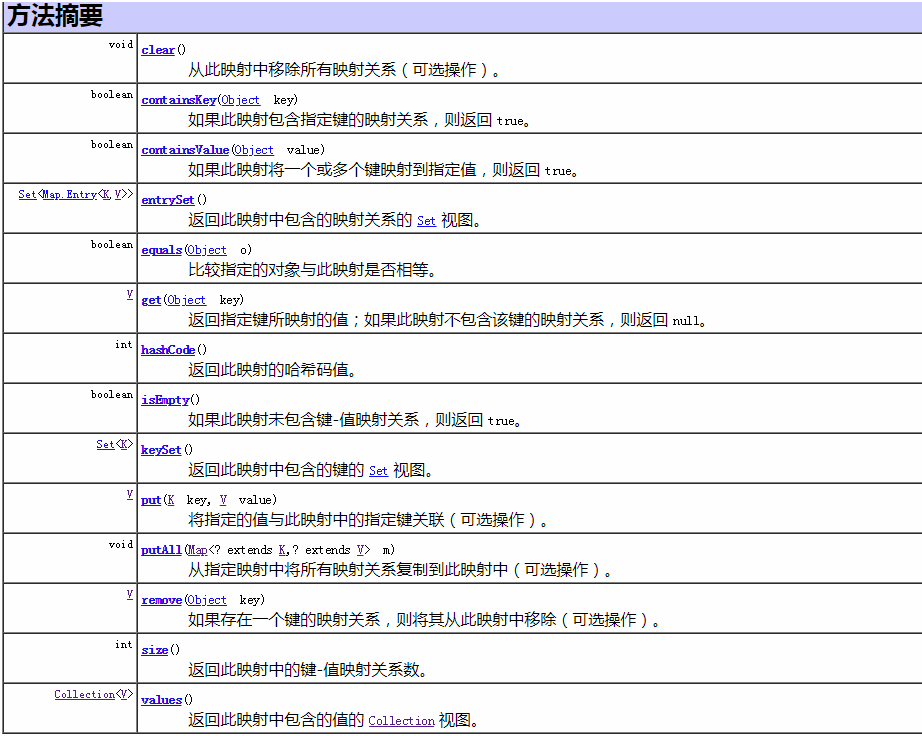
1)HashMap与Hashtable
HashMap与Hashtable是Map接口的两个典型实现,它们之间的关系完全类似于ArrayList与Vertor。HashTable是一个古老的Map实现类,它提供的方法比较繁琐,目前基本不用了,HashMap与Hashtable主要存在以下两个典型区别:
♦ HashMap是线程不安全,HashTable是线程安全的。
♦ HashMap可以使用null值最为key或value;Hashtable不允许使用null值作为key和value,如果把null放进HashTable中,将会发生空指针异常。
为了成功的在HashMap和Hashtable中存储和获取对象,用作key的对象必须实现hashCode()方法和equals()方法。
HashMap工作原理如下:
HashMap基于hashing原理,通过put()和get()方法存储和获取对象。当我们将键值对传递给put()方法时,它调用建对象的hashCode()方法来计算hashCode值,然后找到bucket位置来储存值对象。当获取对象时,通过建对象的equals()方法找到正确的键值对,然后返回对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会存储在链表的下一个节点中。
2)LinkedHashMap实现类
LinkedHashMap使用双向链表来维护key-value对的次序(其实只需要考虑key的次序即可),该链表负责维护Map的迭代顺序,与插入顺序一致,因此性能比HashMap低,但在迭代访问Map里的全部元素时有较好的性能。
3)Properties
Properties类时Hashtable类的子类,它相当于一个key、value都是String类型的Map,主要用于读取配置文件。
4)TreeMap实现类
TreeMap是SortedMap的实现类,是一个红黑树的数据结构,每个key-value对作为红黑树的一个节点。TreeMap存储key-value对时,需要根据key对节点进行排序。TreeMap也有两种排序方式:
♦ 自然排序:TreeMap的所有key必须实现Comparable接口,而且所有的key应该是同一个类的对象,否则会抛出ClassCastException。
♦ 定制排序:创建TreeMap时,传入一个Comparator对象,该对象负责对TreeMap中的所有key进行排序。
5)各Map实现类的性能分析
♦ HashMap通常比Hashtable(古老的线程安全的集合)要快
♦ TreeMap通常比HashMap、Hashtable要慢,因为TreeMap底层采用红黑树来管理key-value。
♦ LinkedHashMap比HashMap慢一点,因为它需要维护链表来爆出key-value的插入顺序。
三、List集合使用
1.循环遍历;2.循环删除;3.迭代器;4.list集合特性
package com.j2ee.text;
import java.util.ArrayList;
import java.util.List;
/**
* 测试
* @author Administrator
*
*/
public class Test {
public static void main(String[] args) {
//实例化list集合(net包中)
List<Object> list = new ArrayList<Object>();
//添加数据
list.add(new String("张三"));
list.add("李四");
list.add(5);
list.add("张小帅");
list.add("李四");
//遍历list集合,3种方式
//1.for循环遍历 //特点:1.有序 2.可重复
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
//代码结果:
//张三
//李四
//5
//张小帅李四
//有序:插入数据的顺序是什么,那么我们在遍历list集合的时候数据显示就是什么样的顺序。
//2.foreach遍历
for (Object object : list) {
System.out.println(object);
}
//2.1.jdk1.8版本新特性遍历:list.forEach(System.out::println);
//3.迭代器遍历
Iterator<Object> it = list.iterator();
while(it.hasNext()) {
Object val = it.next();
System.out.println(val);
}
//list集合删除方式
//1.for循环删除
//list集合特性:当删除了一个前面的元素后,后面的元素会自动往前靠。
for (int i = list.size()-1; i>=0; i--) {
list.remove(i);
}
Integer lenght = list.size();
for (int i = 0; i < list.size(); i++) {
list.remove(0);
}
System.out.println(list.size());
System.out.println(list);
//2.迭代器遍历删除
System.out.println("-----------------");
Iterator<Object> it = list.iterator();
while(it.hasNext()) {
it.next();
it.remove();
}
System.out.println(list.size());
System.out.println(list);
//3.调用list集合中全部清空的方法
System.out.println("----------------");
list.clear();
System.out.println(list.size());
System.out.println(list);
System.out.println("----------------");
System.out.println(list.size());
System.out.println(list);
System.out.println("-----------------------------------------");
//list优化:核心概念:①初始化变量(开始为10个Object数组);②负载因子(扩容比例1.5);③计算公式;
//当数据大于10个Object数组所能容纳的个数时,会自动扩容,扩容比例为:当前容器大小*负载因子
List list1 = new ArrayList();
//添加数据,用于观察list集合的Object[]数组个数的扩容情况
for (int i = 1; i <= 50; i++) {
System.out.println(i);
list.add(i);
getLen(list);
}
//优化代码:
//当我们知道自己要添加多少个数据的时候,我们利用集合的构造方法进行定义即可,
//避免Object[]个数大于数据的情况
//例如:以上我们已经生成了50个数据,我们把上面的List list1 = new ArrayList();替换成下面:
List list1 = new ArrayList(50);
System.out.println("-----------------------------------------");
//泛型:以类型作为参数的类叫做泛型
//作用:提供程序健壮性,简化代码
List<Integer> arraylist = new ArrayList<Integer>();
//添加数据
arraylist.add(56);
arraylist.add(53);
arraylist.add(52);
arraylist.add(55);
arraylist.add(57);
arraylist.add(23);
//什么是泛型,就是集合规定了数据类型<数据类型>
//获取偶数的数据
for (int i = 0; i < arraylist.size(); i++) {
if(arraylist.get(i)%2==0) {
System.out.println("------偶数-------");
System.out.println(arraylist.get(i));
}
}
System.out.println("-----------------------------------------");
//装箱:把值类型(基本数据类型)转换成引用类型
Integer n = new Integer(1);
//拆箱:把引用类型转换成基本类型
int aa = n.intValue();
//jdk1.5版本之后引入了自动装箱和自动拆箱功能,因此我们在写代码时
//如果我们已经安装jdk1.5版本之后,则不需要将八大基本数据类型转成引用类型,添加至集合中。
}
//定义一个方法
/**
* 该方法用户查看list集合中数据不同Object数组的个数
* @param list 集合
*/
public static void getLen(List list) {
try {
//获取Object集合
Field field = list.getClass().getDeclaredField("elementData");
//打开权限
field.setAccessible(true);
//转换成Object数组类型
Object[] obj= (Object[])field.get(list);
//打印数组长度
System.out.println("集合大小为:"+obj.length);
} catch (Exception e) {
//e.printStackTrace();
}
}
}
四、Set集合的使用
①HashSet:1.无序;2.唯一;3.底层结构:HashMap
package com.set.test;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
/**
* Set集合测试类
*
* @author Administrator
*
*/
public class SetText {
private Integer sage;// 年龄
private String sname;// 姓名
public SetText(Integer sage, String sname) {
super();
this.sage = sage;
this.sname = sname;
}
public SetText(String sname) {
super();
this.sname = sname;
}
public Integer getSage() {
return sage;
}
public void setSage(Integer sage) {
this.sage = sage;
}
public String getSname() {
return sname;
}
public void setSname(String sname) {
this.sname = sname;
}
// 打印所有属性值(比较方式)
@Override
public String toString() {
return "SetText [sage=" + sage + ", sname=" + sname + "]";
}
// 判断对象是否相同
@Override
public int hashCode() {
// 判断当前属性是否存在,存在那么比较下一个属性(0),如果两个属性都不存在(),调用equals方法继续判断
final int prime = 31;
int result = 1;
// result = prime * result + ((sage == null) ? 0 : sage.hashCode());
result = prime * result + ((sname == null) ? 0 : sname.hashCode());
return result;
}
// 判断对象是否相同(比较方式)
@Override
public boolean equals(Object obj) {
// this代表当前对象,obj代表传入的对象
// true:已存在 false:未存在,直接添加
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
SetText other = (SetText) obj;
// 重写
if (other.getSname() == this.getSname())
return true;
return false;
}
public static void main(String[] args) {
// set集合特点:1.无序;2.唯一;
// 1.无序
Set<SetText> set = new HashSet<SetText>();
// HashSet底层结构:(HashMap)
// 默认的hashcode是当前对象的内存地址经过运算的值。
// 使用 new 对象地址都不同(地址:是对变量或对象存储的路径的描述)
// 2.去重原理:先调用hashcode方法比较,再调用equals方法比较
// ①如果hashcode不同,则直接放入
// ②如果hashcode相同,则通过equals方法判断
// 3.遍历方式
// 添加数据:
set.add(new SetText(11, "张三"));
set.add(new SetText(7, "李四"));
set.add(new SetText(71, "王老五"));
set.add(new SetText(8, "唯一"));
set.add(new SetText(44, "老王"));
set.add(new SetText(24, "老王"));
set.add(new SetText(44, "老王"));
// ①迭代器遍历:
// 实例化迭代器
Iterator<SetText> it = set.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
// (没重写)遍历结果:
// SetText [sage=8, sname=唯一]
// SetText [sage=44, sname=老王]
// SetText [sage=11, sname=张三]
// SetText [sage=71, sname=王老五]
// SetText [sage=7, sname=李四]
// SetText [sage=24, sname=老王]
// 我们可以清楚看到44岁的老王被去掉了一个,因为它在hashcode方法中就已经被识别出是相同的,因此直接就去掉了
// 那么假设我们要比较名字呢?我们可以修改hashcode方法和equals方法(例如:上面)重写后:
// SetText [sage=7, sname=李四]
// SetText [sage=11, sname=张三]
// SetText [sage=44, sname=老王]
// SetText [sage=8, sname=唯一]
// SetText [sage=71, sname=王老五]
// 如果还要按照其它条件可以自主修改:hashcode方法和equals方法
// ②迭代器遍历:
Iterator<SetText> ita = set.iterator();
while (ita.hasNext()) {
System.out.println(ita.next());
}
// ③foreach遍历
set.forEach(System.out::println);
}
}
②ThreeSet:1.有序;2.底层结构(二叉树)
package com.set.test;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
/**
* TreeSet集合测试类
*
* @author Administrator
*
*/
public class TreeSetText implements Comparable<TreeSetText> {
private int tid;// 编号
private String tname;// 名字
public TreeSetText() {
}
public TreeSetText(int tid, String tname) {
super();
this.tid = tid;
this.tname = tname;
}
@Override
public String toString() {
return "TreeSetText [tid=" + tid + ", tname=" + tname + "]";
}
public int getTid() {
return tid;
}
public void setTid(int tid) {
this.tid = tid;
}
public String getTname() {
return tname;
}
public void setTname(String tname) {
this.tname = tname;
}
public static void main(String[] args) {
// TreeSet特点:1.有序(插入数据顺序无序);2.底层结构:二叉树。
// 按照:升序、降序来排序。
Set<String> set = new TreeSet<String>();
// 添加数据
set.add("zs");
set.add("ls");
set.add("ww");
// 遍历
set.forEach(System.out::println);
// 结果:
// ls
// ww
// zs
// 这里我们看到就会疑惑,为什么我们在添加数据最后打印的时候,顺序不一样,不是特点是有序的吗?
// 答:这里的有序是指a~z的排序方式,而并非添加顺序排序
// 排序:1.自然排序; 2.选择器排序
// 我们添加对象试试
// Comparable:第一种:自然比较接口
TreeSet<TreeSetText> ts = new TreeSet<TreeSetText>();
ts.add(new TreeSetText(1, "老王"));
ts.add(new TreeSetText(4, "老李"));
ts.add(new TreeSetText(3, "老五"));
ts.add(new TreeSetText(2, "老新"));
// 遍历
ts.forEach(System.out::println);
// 如果我们没有实现Comparable接口,那么就会报错
TreeSetText treeSetText = new TreeSetText();
// 第二种
TreeSet<TreeSetText> ts2 = new TreeSet<TreeSetText>(treeSetText.new NameComparator());
ts2.add(new TreeSetText(1, "lw"));
ts2.add(new TreeSetText(4, "ak"));
ts2.add(new TreeSetText(3, "yy"));
ts2.add(new TreeSetText(2, "bc"));
// 遍历
ts2.forEach(System.out::println);
}
@Override
public int compareTo(TreeSetText o) {
// 比较者大于被比较着 返回1
// 比较者等于被比较着 返回0
// 比较者小于被比较着 返回-1
// return this.getTid()-o.getTid();//升序
return -(this.getTid() - o.getTid());// 降序
}
/**
* 内部类
*
* @author Administrator
*
*/
class NameComparator implements Comparator<TreeSetText> {
@Override
public int compare(TreeSetText o1, TreeSetText o2) {
return o1.getTname().hashCode() - o2.getTname().hashCode();
}
}
}
五、Map集合详解
①HashMap集合:
package com.map.test;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
/**
* Map集合测试
*
* @author Administrator
*
*/
public class MapTest {
public static void main(String[] args) {
// Map特点:1.无序; 2.值不唯一; 3.键值对的形式存储数据;
// 一个键对应一个值,键不能重复,值可以。
// Map集合添加数据的方法:put();如下:
// 其中<>也就是泛型,可以定义任意的数据类型,称为优化集合,提高代码健壮性
Map<String, Object> map = new HashMap<String, Object>();
map.put("test", "张三");
map.put("list", new ArrayList<String>().add("无中生有"));
map.put("set", new HashSet<String>().add("老五"));
map.put("object", new Object[] { "张三", "李四" });
// Map集合遍历方式:1.遍历键keys; 2.遍历值values; 3.遍历值和键;
// 1.
Set<String> keys = map.keySet();
for (String string : keys) {
System.out.println(string);
}
// 2.
Collection<Object> values = map.values();
for (Object object : values) {
System.out.println(object);
}
// 3.
Set<Entry<String, Object>> entrySet = map.entrySet();
for (Entry<String, Object> entry : entrySet) {
System.out.println("键:" + entry.getKey() + "--值:" + entry.getValue());
}
}
}
②TreeMap集合:
package com.map.test;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import java.util.TreeMap;
/**
* ThreeMap测试类
*
* @author Administrator
*
*/
public class TreeMapTest {
public static void main(String[] args) {
// 1.ThreeMap特点:①以键排序; ②以值排序;(默认按键升序排序)
Map<String, Object> map = new TreeMap<String, Object>();// 升序
// Map<String,Object> map = new
// TreeMap<String,Object>(Comparator.reverseOrder());//降序
// ①以键排序:
map.put("zs", 100);
map.put("ls", 200);
map.put("ww", 150);
map.put("object", 50);
// 遍历
Set<Entry<String, Object>> entrySet = map.entrySet();// 升序
for (Entry<String, Object> entry : entrySet) {
System.out.println("键:" + entry.getKey() + "--值:" + entry.getValue());
}
// 结果:
// 键:list--值:true
// 键:object--值:[Ljava.lang.Object;@7852e922
// 键:set--值:true
// 键:test--值:张三
// 我们发现键是按照:a~z排序(升序)
// Hashtable:线程安全
// HashMap:线程不安全
// ②以值排序:
// 第一步:将键值对形式转换成list集合
ArrayList<Entry<String, Object>> list = new ArrayList<Entry<String, Object>>(entrySet);
// Collections
// 面试题:Collections和Collection的区别
// Collection:集合顶层接口
// Collections:集合框架中的帮助类
// 第二步:调用Collections.sort方法:按以下操作
Collections.sort(list, new Comparator<Entry<String, Object>>() {
@Override
public int compare(Entry<String, Object> a, Entry<String, Object> b) {
return -(a.getValue().hashCode() - b.getValue().hashCode());
}
});
// 重写里面的compare方法进行value值的排序
// 注意:我们遍历的是list集合
list.forEach(System.out::println);
// 2.Arrays:工具类,提供了一组静态方法操作数组
// Arrays.asList():括号里内容为:基本数据类型数组,将一个字符数组转换成集合
String trr = "1,32,5,45,64,5,6";
String[] split = trr.split(",");
List<String> asList = Arrays.asList(split);
// 遍历
asList.forEach(System.out::println);
// Arrays.toString():将数组转换成字符串
String string = Arrays.toString(split);
System.out.println(string);
}
}
六、小结部分
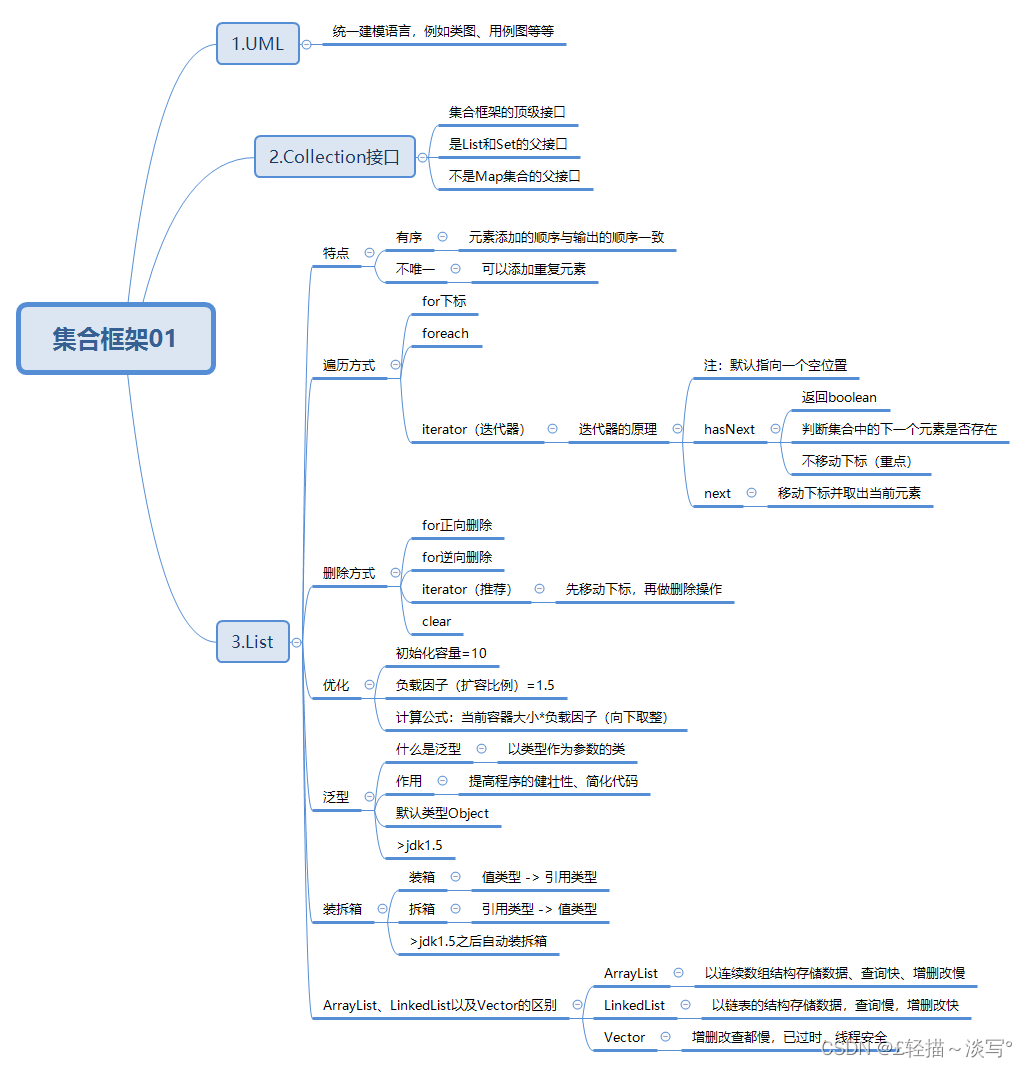
①集合框架+List集合:
②Set集合:
③Map集合:
















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









