







字符串
字符串我们已经并不陌生了,上次我们学习的:
print('你好,python研发部!')在这行代码里,'你好,python研发部!'就是一个字符串
字符串的本质是:字符序列。将字符(字母,汉字,数字,符号等)像羊肉串一样串在一起,就是字符串。
字符串的创建方式
我们一般通过引号创建字符串,使用print可以将字符串引号里的内容输出,引号是不输出的
那如果我们想输出带有引号的字符串怎么办呢?
当字符串本身带有双引号时,我们可以使用单引号创建
当字符串本身带有单引号时,我们可以使用双引号创建
实操:输出带有引号的字符串
a = "I love 'Python'!"
print(a) #I love 'Python'!
b = 'I love "Python"!'
print(b) #I love "Python"!
len()函数和空字符串
len()用于计算字符串含有多少字符。例如:
a = 'len()函数'
print(len(d)) #结果:7python允许空字符串存在,即长度为0的字符串
实操:输出空字符串的长度:
a = ''
print(len(a)) #输出:0转义字符
我们可以使用\+特殊字符,实现某些难以用字符表示的效果。比如:换行等。
常见的转义字符有这些:
| 转义字符 | 描述 |
|---|---|
| \ (在行尾时) | 续行符 |
| \ | 反斜杠符号 |
| \' | 单引号 |
| \" | 双引号 |
| \b | 退格(Backspace) |
| \n | 换行 |
| \t | 横向制表符 |
| \r | 回车 |
| \\ | \ |
实操:使用换行符\n
a = 'I\nlove\nU'
print(a)
输出:
I
love
U字符串拼接
可以使用+将多个字符串拼接起来。例如:'aa'+ 'bb' 结果是'aabb'
a = 'aa'+'bb'
print(a) #输出:aabb如果+两边都是字符串,则拼接。
如果+两边都是数字,则加法运算
如果+两边类型不同,则抛出异常,即出错
可以将多个字符串直接放到一起实现拼接。例如:'aa' 'bb'结果是'aabb'
"aa""bb"结果是"aabb"
print('aa''bb') #输出 'aabb'
print("aa""bb") #输出 "aabb"字符串复制
使用 * 可以实现字符串复制
实操:输出3次'python研发部'
a = 'python研发部'*3
print(a) #输出'python研发部python研发部python研发部'不换行打印
首先,我们允许下列代码:
print('你好,月木天上!')
print('你好,python研发部!')允许后,我们会发现当输出'你好,python研发部!'时,它为什么会在第二行,
而不是在第一行屁股后面呢?
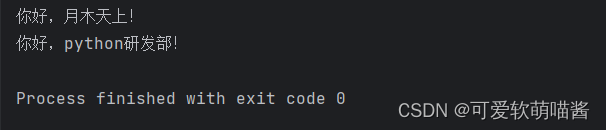
原因是当我们第一次调用print时,会自动打印一个换行符,导致第二次打印被迫换行了
可以通过参数end = “任意字符串”。将换行符删掉。
实操1:不换行打印:
print("你好,python",end="")
print("研发部") #输出:你好,python研发部实操2:不换行替换字符打印:
print("你好,月木天上!",end='————')
print("python研发部!") #输出:你好,月木天上!————python研发部!从控制台读取字符串 input()
我们可以使用input()从控制台读取键盘输入的内容。
我们创建一个a,然后令a=input(),每次运行input时,我们都可以从控制台重新给他一个变量
实操:输出名字:
a = input('请输入名字:')
print('您的名字是:' + a)
#输出结果:
请输入名字: 张三
您的名字是: 张三实现字符串替换 replace()
字符串是不可改变的。但是,我们确实有时候需要替换某些字符。
这时,我们可以通过replace()来实现。
它会先创建一个新的字符串,然后再把你想替换的内容替换掉,并不会修改原有字符串。
a = '你好,月木天上!'
b = a.replace('月木天上','python研究部')
print(a) #输出:你好,月木天上!
#此时输出的字符串不是最初的字符串,而是一个全新的字符串
print(b) #输出:你好,python研究部!在b = a.replace('月木天上','python研究部')中 ,a代表你要替换的字符串
第一个引号里是原来字符串内的内容,第二个引号里是你想要替换的内容
实现数字转字符串 str()
使用 str() 将非字符串的对象可以转成字符串。
比如 a = 5,那么这个时候a的值为5,但如果 a = str(5),那么a就会变成 '5'
a = str(5.20) #结果是:a = '5.20'
b = str(3.14e2) #结果是:b = '314.0'
c = str(True) #结果是:c = 'True'提取字符 []
我们可以通过在字符串后面添加[],在[]里面指定偏移量,可以提取该位置的单个字符。
我们可以为字符串编一个序号,比如 a = 'abcd'
从前往后为正向搜索:a的序号为0,或者说是偏移量为0,b的偏移量为1,c为2,依次类推
从后往前为反向搜索,d为-1,c为-2,以此类推
注意:最前面的第一个字符,偏移量为 0 而不是 1
最后面的第一个字符,偏移量为-1
我们可以通过他们的偏移量,将其提取出来
实操:正向搜索与反向搜索
a="abcd"
print(a[ 0]) #输出:a
print(a[-1]) #输出:d切片slice操作 [start:end:step]
我们可以通过切片操作,提取字符串的一部分,而不是单个字符
那么start,end,step又分别代表什么呢?
start(起始偏移量):代表开始,比如设置start为0,那么就是从偏移量为0的字符开始提取
end(终止偏移量) :代表结束,比如设置end为2,那么提取到偏移量为2的前一个字符停止提取,
不会提取偏移量为2的字符
step(步长) :代表步长:
设置为1,则提取第一个字符,第二个字符,第三个字符,依次类推
设置为2,则提取第一个字符,第三个字符,第五个字符,依次类推
设置为3,则提取第一个字符,第四个字符,第七个字符,依此类推
我们可以发现,步长就是下一个字符的偏移量减去上一个字符的偏移量的值
如果设置为-1,那么会逆向提取,比如字符串为'1234',那么提取的结果为'4321'
我们还可以不设置终止偏移量与步长,甚至起始偏移量。可以通过以下实例来理解:
[0] 提取偏移量为0的字符
[0:5] 提取偏移量从0到4的所有字符
[0:5:2] 提取偏移量为从0到4的第一个字符,第三个字符,第五个字符
[::-1] 逆向提取所有字符
重点:如果想逆向提取偏移量从2到4的所有字符该怎么办呢
有些聪明的同学肯定会觉得那不是很简单吗,照猫画虎,[2:5:-1]不就可以了吗
但实际这种语法是错误的
我们应该先使用[2:5]提取字符,再使用[::-1]进行逆向提取,也就是说,正确答案是[2:5][::-1]
实操1:感受步长
同学们可以把字符串设置长一些,步长调大一些,感受步长
a = "abcdefg"
print(a[0:5:2]) #输出:ace实操2:逆向提取偏移量从2到4的所有字符
a = "abcdefg"
print(a[2:5][::-1]) #输出:edc分割 split() 和 合并join()
split() 可以基于指定分隔符将字符串分隔成多个子字符串存储到列表(列表以后再学)中。
如果不指定分隔符,则默认使用空白字符(换行符/空格/制表符)为分隔符。
实操:分割字符串
a="I Love Python"
b=a.split()
print(b) #输出:['I', 'Love', 'Python']join() 的作用和 split() 作用刚好相反,用于将列表里的一系列子字符串连接起来。
我们还可以在引号里设置连接字符,它就好像胶水一样,将子字符串粘到一起
实操:合并字符串
a=['I', 'Love', 'Python']
b='*'.join(a)
print(b) #输出:I*Love*Python推荐使用join函数,效率较快
因为join函数在拼接字符串之前会计算所有字符串的长度,然后逐一拷贝,仅新建一次对象。
不推荐使用+,因为使用+,会生成新的字符串对象,效率较慢
字符串驻留机制和字符串比较
字符串驻留:常量字符串只保留一份。什么意思呢?
如果 苹果 = '橘子' ,香蕉 = '橘子' ,那么苹果与香蕉相等吗?
这个时候同学们的意见可能不一了,苹果与香蕉是两个东西,苹果怎么可能是香蕉呢?
但在python中,我们需要换一个方式去思考,如图:

也就是说,在电脑的内存中,只有一个橘子,苹果与香蕉只是橘子的外号
无论它叫苹果还是香蕉或者叫西瓜,它们的指针都共同指向了橘子
也可以说他们的本质都是橘子,而且还是同一个橘子也就是说,苹果与香蕉相等
字符串的比较和同一性
我们可以直接使用 == , != 对字符串进行比较,是否含有相同的字符。
我们使用 is ,is not,判断两个对象是否同一个对象。比较的是对象的地址,即id是否相等。
学会了 is 与 is not,我们就可以判断刚才的苹果是不是等于香蕉了
实操:苹果等于香蕉
苹果 = '橘子'
香蕉 = '橘子'
print(苹果 is 香蕉) #True
print(苹果 is not 香蕉) #False成员操作符 判断子字符串
in ,not in 关键字,判断某个字符(子字符串)是否存在于母字符串中。
c = "Python#"
d = "Py"
print(d in c) #True
print(d not in c) #False字符串常用方法汇总
1.常用查找方法
我们以一段文本作为测试:
a='''我是张三,我在月木天上上班。我是一个编程的爱好者,现在我正在python研发部进行学习,
部长告诉我,认真学习全套课程可以月入30000,我信了,所有我正在全力学习!'''
| 方法和使用示例 | 说明 | 结果 |
|---|---|---|
| len(a) | 字符串长度 | 80 |
| a.startswith('我是张三') | 是否以字符串‘我是张三’开头 | True |
| a.endswith('学习!') | 是否以字符串'学习!'结尾 | True |
| a.find('学习') | 第一次出现'学习'的位置 | 41 |
| a.rfind('学习') | 最后一次出现‘学习’的位置 | 80 |
| a.count('学习') | 字符串'学习'出现了几次 | 3 |
| a.isalnum() | 所有字符是否全是字母或数字 | False |
实操:将上述所有方法使用一次
a='''我是张三,我在月木天上上班。我是一个编程的爱好者,现在我正在python研发部进行学习,
部长告诉我,认真学习全套课程可以月入30000,我信了,所有我正在全力学习!'''
print(len(a)) #输出:80
2.去除首尾信息strip()
我们可以通过strip()去除字符串首尾指定信息。
lstrip()去除字符串左边指定信息。
rstrip()去除字符串右边指定信息。
实操:分别去除首尾,左边,右边指定信息
a="abbbba"
print(a.strip("a")) #输出bbbb
#相当于print("abbbbbba".strip("a"))
print(a.lstrip("a")) #输出bbbba
print(a.rstrip("a")) #输出abbbb3.大小写转换
a = "i love Python"| 示例 | 说明 | 结果 |
|---|---|---|
| a.capitalize() | 产生新的字符串,首字母大写 | I love Python |
| a.title() | 产生新的字符串,每个单词的首字母都大写 | I Love Python |
| a.upper() | 产生新的字符串,所有字符全转成大写 | I LOVE PYTHON |
| a.lower() | 产生新的字符串,所有字符全转成小写 | i love python |
| a.swapcase() | 产生新的字符串,所有字母大小写转换 | I LOVE pYTHON |
实操:将上述所有方法使用一次
我就不演示了,哎嘿
4.格式排版
格式排版就相当于是word文档里的 居中对齐center(n),左侧对齐ljust(n),右侧对齐rjust(n)
n代表总字数,n为8代表总字数为8,比如:
'月木天上'.center(8)代表将月木天上居中对齐,总共占用8个字符,即 月木天上 。
注意:左侧与右侧共有四个空白字符
'月木天上'.center(8,'*')代表将月木天上居中对齐,并且使用'*'替换空白字符,即**月木天上**
实操:分别使用居中对齐,左侧对齐,右侧对齐
a = '月木天上'
print(a.center(8)) #输出: 月木天上
print(a.center(8,"*")) #输出:**月木天上**
print(a.ljust(8,"*")) #输出:月木天上****
print(a.rjust(8,"*")) #输出:****月木天上5.特征判断方法
| isalnum() | 是否为字母(包含汉字)或数字组成 |
| isalpha() | 是否由字母(包含汉字)组成 |
| isdigit() | 是否只由数字组成 |
| isspace() | 是否为空白符 |
| isupper() | 是否为大写字母 |
| islower() | 是否为小写字母 |
实操:检查字符串是否只由字母(包含汉字)或数字组成
a="我爱python666"
print(a.isalnum()) #True字符串的格式化format()
我们可以往字符串里使用{} 和:,从而达到格式化的目的,为什么要格式化呢?
比如我们想输出一句话: a = '我叫张三,我18岁,我张三变成了帅哥。'
那么如果李四想变成帅哥, 就需要 b ='我叫李四,我20岁,我李四变成了帅哥。'
那么如果王五也想变成帅哥, 就需要 c = '我叫王五,我21岁,我王五变成了帅哥。'
如果再来几个人怎么办,每个人都需要打一句话这也太麻烦了吧!!
有没有办法只用一个 a 就能完成所有人都变为帅哥的办法呢? 有,那就是format()。
首先我们先用{}替换掉人名与年龄,因为每个人的名字与年龄都不一样,
帅哥就不用变了,因为他们都想变成帅哥,我们把名字变为为{0},年龄变为{1}
那么就变成了 a = '我叫{0},我{1}岁,我{0}变成了帅哥。'
然后在它的后面加上 .format('张三',18),也就是a.format('张三',18)
我们可以把张三与18换成任何想变成帅哥的人与年龄
format() 函数可以接受不限个数的参数,位置可以不按顺序。
实操:让所有人变成帅哥
a = '我叫{0},我{1}岁,我{0}变成了帅哥。'
print(a.format("张三", 18))
#输出:我叫张三,我18岁,我张三变成了帅哥。
print('我叫{0},我{1}岁,我{0}变成了帅哥。'.format("张三", 18))
#这么写更常用,输出结果与上面相同有些同学说,既然替换的是名字与年龄
那么不想用没有代表性的{0},{1},那么我想用更直观的方式比如{name},{age},这样完全是可以的
我们可以使用以0为开头的数字,也可以使用字符串 ,但由于变成了字符串,语法也会发生变化
需要在format()里面加上 = 号
实操:让所有人变成帅哥
b = '我叫{name},我{age}岁,我{name}变成了帅哥。'
print(b.format(name='张三',age=18))
#输出:我叫张三,我18岁,我张三变成了帅哥。
print('我叫{name},我{age}岁,我{name}变成了帅哥。'.format(name='张三',age=18))
#这么写更常用,输出结果与上面相同,1.在format中使用填充与对齐
填充常跟对齐一起使用,^、<、>分别是居中、左对齐、右对齐,后面要带上宽度与前面讲的格式排版类似
刚才我们学到,a = '我叫{0},我{1}岁,我{0}变成了帅哥。'
那么如何使用填充与对齐呢,我们只需要在{0}或者{1},加上:号并在后面带上填充的字符,
只能是一个字符,不指定的话默认用空格填充
例如{0:*^4},意思是居中对齐,宽度为4,并使用*代替空白符填充
实操:让名字也变帅气
a = '我叫{0:*^4},我{1}岁,我{0:*^4}变成了帅哥。'
print(a.format("张三","18"))
#输出:我叫*张三*,我18岁,我*张三*变成了帅哥。
print('我叫{0:*^4},我{1}岁,我{0:*^4}变成了帅哥。'.format("张三","18"))
#输出:我叫*张三*,我18岁,我*张三*变成了帅哥。2.在format中使用数字格式化
浮点数通过 f,整数通过 d进行需要的格式化。
我们通过数字格式化可以做到,保留几位小数,或者将小数变为整数,百分数等很多功能。
注意:记得不要忘记位置参数,比如保留{0}的2位小数,那么应该写{0:.2f},而不是{:.2f}
| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 3.1415926 | {:.2f} | 3.14 | 保留小数点后两位 |
| 3.1415926 | {:+.2f} | +3.14 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} | 3 | 四舍五入 |
| 5 | {:0>2d} | 05 | 数字补零 (填充左边, 宽度为2) |
| 5 | {:x<4d} | 5xxx | 数字补x (填充右边, 宽度为4) |
| 10 | {:x<4d} | 10xx | 数字补x (填充右边, 宽度为4) |
| 1000000 | {:,} | 1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} | 25.00% | 百分比格式 |
| 1000000000 | {:.2e} | 1.00E+09 | 指数记法 |
| 13 | {:10d} | 13 | 右对齐 (默认, 宽度为10) |
| 13 | {:<10d} | 13 | 左对齐 (宽度为10) |
| 13 | {:^10d} | 13 | 中间对齐 (宽度为10) |
实操: 测试表格内标红方法
a = "我是{0},我的存款有{1:.2f}"
b=a.format("张三",3000.6666)
print(b) #我是张三,我的存款有3000.67可变字符串 io
Python中,字符串属于不可变对象,不支持原地修改,
如果需要修改其中的值,只能创建新的字符串l
这个时候我们就可以使用io.StringIO对象,创建新的字符串对象,然后进行修改。
下面是建立io对象的演示:
import io #导入io模块
a = "hello, 张三"
b = io.StringIO(a) #建立一个可变字符串b
print(b) #输出<_io.StringIO object at 0x00000254EB2905E0>这个时候我们发现,新的字符串对象无法被直接打印,
我们需要新的语法才可以打印:
print(b.getvalue()) #输出:hello, 张三同时我们可以进行修改:
b.seek(7) #指针知道索引7这个位置
b.write("李四") #从索引7开始修改字符串
print(b.getvalue()) #输出hello, 李四实操:把张三变成李四
import io #导入io模块
a = "hello, 张三"
b = io.StringIO(a) #建立一个可变字符串b,他的内容也是"hello, 张三"
b.seek(7) #将指针指到索引7这个位置
b.write("李四") #从索引7开始修改字符串
print(b.getvalue()) #输出:hello, 李四类型转换总结
这是对本章类型转换内容的总结,大家只需要看一眼,
要求以后用到的时候能回来找就就可以,不用操作,继续下一章的学习吧!
| 类型转换 | |
|---|---|
| int(x [,base]) | 将x转换为一个整数 |
| long(x [,base] ) | 将x转换为一个长整数 |
| float(x) | 将x转换到一个浮点数 |
| complex(real[,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| Complex(A) | 将参数转换为复数型 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个序列 (key,value)元组 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| unichr(x) | 将一个整数转换为Unicode字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









