







列表
列表:用于存储任意数目、任意类型的数据集合。
列表是内置可变序列,是包含多个元素的有序连续的内存空间。
列表的标准语法格式:a = [10,20,30,40],其中,10,20,30,40这些称为:列表a的元素。
列表中的元素可以各不相同,可以是任意类型。比如:a = [10,20,'python研发部',True]
Python的列表大小可变,根据需要随时增加或缩小。
列表的创建
1.基本语法[]创建
实例1:基本语法[]创建
a = [10,20,'python研发部',True]
b = [] #创建一个空的列表对象
2.list() 创建
实例2.:list() 创建
a = list() #创建一个空的列表对象
b = list("python") #结果:['p', 'y', 't', 'h', 'o', 'n']3. range() 创建整数列表
range() 可以帮助我们非常方便的创建整数列表
格式:range([start,] end [,step]) (符号[]代表可有可没有,以后文档会经常用到)
range()里的数字代表的是位置参数,而计算机中位置参数一般从数字0开始,
举个例子,range(3)代表[0,1,2],并没有3
start,end, step之前已经详细讲过,这里不再赘述
实操:输出数字0-9,1-9
a = list(range(10)) #输出:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
b = list(range(1,10,1)) #输出:[1, 2, 3, 4, 5, 6, 7, 8, 9]4.推导式生成列表(稍微了解一下,重点在for循环后讲)
使用列表推导式可以非常方便的创建列表,在开发中经常使用,也是python具有代表性的方法
观察这个推导式: a = [x*2 for x in range(5)],首先我们观察for后面的式子
[for x in range(5)] 代表 x的值为在五次循环内分别拥有以下列表里的值:[0,1,2,3,4]
最后我们再观看for前面的x*2,意思是每个值都乘以2,也就是 [0,2,4,6,8]
实操:使用推导式
a = [x*2 for x in range(5)]
print(a) #输出 [0, 2, 4, 6, 8]列表元素的增加
1.append()方法
原地修改列表对象,是真正的列表尾部添加新的元素,速度最快,推荐使用。
实操:使用 append() 添加元素
a = [20,40]
a.append(60)
print(a) #结果:[20, 40, 60]2.+ 运算符操作
并不是真正的尾部添加元素,而是创建新的列表对象;
将原列表的元素和新列表的元素依次复制到新的列表对象中。
这样,会涉及大量的复制操作,对于操作大量元素不建议使用。
实操:使用+运算符添加元素
a = [20,40]
a = a+[60]
print(a) #两次地址不一样,输出[20, 40, 60]3.extend() 方法
将目标列表的所有元素添加到本列表的尾部,也就是合并两个列表为一个列表,属于原地操作,
不创建新的列表对象。
a = [20,40]
b = [60,80]
a.extend(b) #将b加入a
print(a) #输出列表a:[20, 40, 60, 80]4.insert()插入元素
使用insert()方法可以将指定的元素插入到列表对象的任意指定位置。
a = [1,2,4]
a.insert(2,3)
a.insert(2,3)中,2代表插入指针(位置参数)为2这个位置,3是我们要插入的元素
这样会让插入位置后面所有的元素进行移动,会影响处理速度。涉及大量元素时,尽量避免使用。
实操:让3回家
a = [1,2,4]
a.insert(2,3)
print(a) #结果:[1, 2, 3, 4]5.乘法扩展
使用乘法扩展列表,生成一个新列表,新列表元素是原列表元素的多次重复。
实操:爱你一百次
a = ['我爱你']
b = a*100
print(b)
#输出:['我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你', '我爱你']列表元素的删除
1.del 删除
删除列表指定位置的元素。
实操:x请拱出去
a = [1,2,"x",3,4]
del a[2]
print(a) #结果:[1, 2, 3, 4]2.pop()方法
pop()删除并返回指定位置元素,如果未指定位置则默认操作列表最后一个元素。
实操:分别使用默认删除与指定删除
a = [1,2,3,4,5]
b1 = a.pop() #默认删除尾部
print(a) #输出:[1, 2, 3, 4]
print(b1) #输出:5a = [1,2,3,4,5]
b2 = a.pop(1) #删除索引1的元素
print(a) #输出:[1, 3, 4, 5]
print(b2) #输出:53.remove()方法
删除首次出现的指定元素,若不存在该元素则抛出异常。
实操:删除第一个2
a = [1,2,1,2]
a.remove(2)
print(a) # 输出[1, 1, 2]
a.remove(3) # 报错:ValueError:list.remove(x): x not in listdel(),pop(),remove()三种方法在删除非尾部元素时也会像插入insert()一样使操作位置后面的元素发生移动 ,使处理速度变慢
索引访问
列表元素访问和计数
假如有一个列表a = [1,2,3,4,5,6,7,8]
我们使用a[2],即可访问指针为2的元素,使用print()就可以输出,指针超出列表长度就会报错
实操:访问指针为2的元素
a = [1,2,3,4,5,6,7,8]
print(a[2]) # 输出3
print(a[10]) # 报错:IndexError: list index out of rangeindex() 获得指定元素在列表中首次出现的索引
index()可以获取指定元素首次出现的指针(索引,位置参数)位置。
语法是:index(value,start,end)。其中,start和end指定了搜索的范围。
实操:谁第一次出现?
a = [10,20,30,40,50,20,30,20,30]
b = a.index(20) #结果:1
c = a.index(20,3) #结果:5 从指针3开始往后搜索的第一个20
d = a.index(30,5,7) #结果:6 从指针5到7这个区间,第一次出现30元素的位置
count() 获得指定元素在列表中出现的次数
实操:出现了几次6?
a = [1,6,6,1,6,6,1]
print(a.count(6)) #输出:4切片操作
切片slice操作可以让我们快速提取子列表或修改。
标准格式为:[start:end:step]
假如设 a = [10,20,30,40,50,60,70]
| 操作和说明 | 说明 | 示例 | 结果 |
|---|---|---|---|
[:] | 提取整个列表 | [:] | [10, 20, 30, 40, 50, 60, 70] |
[start:] | 从start索引开始到结尾 | [1:] | [20, 30, 40, 50, 60, 70] |
[:end] | 从头开始直到end-1 | [:2] | [10,20] |
[start:end] | 从start到end-1 | [1:3] | [20,30] |
[start:end:step] | 从start提取到end-1,步长是step | [1:6:2] | [20, 40, 60] |
负数情况
| 示例 | 说明 | 结果 |
|---|---|---|
[-3:] | 倒数三个 | [50,60,70] |
[-5:-3] | 倒数第五个到倒数第三个(包头不包尾) | [30,40] |
[::-1] | 步长为负,从右到左反向提取 | [70, 60, 50, 40, 30, 20, 10] |
实操:将以上正负数情况挑选进行测试
a = [10,20,30,40,50,60,70]
print(a[:]) #输出:[10, 20, 30, 40, 50, 60, 70]
print(a[1:]) #输出:[20, 30, 40, 50, 60, 70]
print(a[:2]) #输出:[10, 20]
print(a[1:3]) #输出:[20, 30]
print(a[1:6:2]) #输出:[20, 40, 60]成员关系操作 in
成员资格判断
判断列表中是否存在指定的元素,我们可以使用count()方法,我们刚才学过,
它可以返还出现的次数,返回0则表示不存在,返回大于0则表示存在。
a = [10,20,30]
b = a.count(10)
print(b) #输出1 表示存在但是,一般我们会使用更加简洁的in关键字来判断,直接返回True或False
a = [10,20,30]
print(20 in a) #True列表的遍历
此处涉及到循环,不理解的话可以等学到循环再看
首先设列表 a = [10,20,30,40]
然后设循环 for b in a:,意思是每次循环都会依次获取列表a里的一个值作为b,
最后我们使用print语句就可以通过输出观察到我们遍历的数据。
a = [10,20,30,40]
for b in a:
print(b)
'''输出10
20
30
40'''列表的复制
list1 = [30,40,50]
list2 = list1这种方式只是将list2也指向了列表对象,
也就是说list2和list2持有地址值是相同的,列表对象本身的元素并没有复制。
下面这种方式可以生成新的列表对象:
实操:复制列表
list1 = [30,40,50]
list2 = [] + list1 #生成了新列表对象列表排序
sort() 原列表排序
实操:原列表排序
默认升序排序
a = [20,10,30,40]
a.sort() #默认是升序排列
print(a) #输出[10, 20, 30, 40]降序排序
a = [20,10,30,40]
a.sort(reverse=True) #降序排列
print(a) #[40, 30, 20, 10]随机排序
import random #导入模块
a = [20,10,30,40]
random.shuffle(a) #随机排序
print(a) #输出[30, 20, 10, 40]sorted() 建新列表的排序
我们也可以通过内置函数sorted()进行排序,这个方法会返回一个新列表,不对原列表做修改。
实操:生成新的升序与降序列表
a = [20,10,30,40]
b = sorted(a) #默认升序
print(b) #输出新的升序列表[10, 20, 30, 40]
c = sorted(a,reverse=True) #降序
print(c) #输出新的降序列表[40, 30, 20, 10]reversed() 返回迭代器
内置函数reversed()不对原列表做任何修改,只是返回一个逆序排列的迭代器对象。
print(迭代器)无法输出我们需要的数据,需要使用print(list(迭代器))才可以输出
迭代器对象只能使用一次。
实操:使用迭代器
a = [20,10,30,40]
b = reversed(a) #创建迭代器,逆序排序
print(b) #输出迭代对象<list_reverseiterator object at 0x00000260F59AA230>
print(list(b)) #输出[40, 30, 10, 20]
print(list(b)) #输出[],因为迭代对象只能使用一次列表计数
max和min
用于返回列表中最大和最小值。
实操:输出最大值与最小值
a = [1,2,3,4,5]
print(max(a)) #输出最大值5
print(min(a)) #输出最大值1sum求和
对数值型列表的所有元素进行求和操作,对非数值型列表运算则会报错。
实操:求和
a = [3, 10, 20, 15, 9]
print(sum(a)) #输出求和 57
len() 返回列表长度
len() 返回列表长度,即列表中包含元素的个数。
实操:求列表长度
a = [10,20,30]
b = len(a)
print(b) #输出3多维列表
一维列表可以帮助我们存储一维、线性的数据。
二维列表可以帮助我们存储二维、表格的数据。
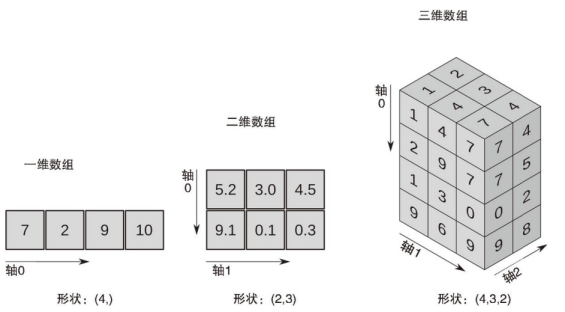
接下来我们详细讲一下二维列表,如下表:
| 姓名 | 年龄 | 薪资 | 城市 |
|---|---|---|---|
| 张三 | 18 | 30000 | 北京 |
| 李四 | 19 | 20000 | 上海 |
| 王五 | 20 | 10000 | 深圳 |
我们知道 a = [1,2,3] 中,1的索引为0,2的索引为1,3的索引为2
而在二维列表中,我们也应该把索引标出来:
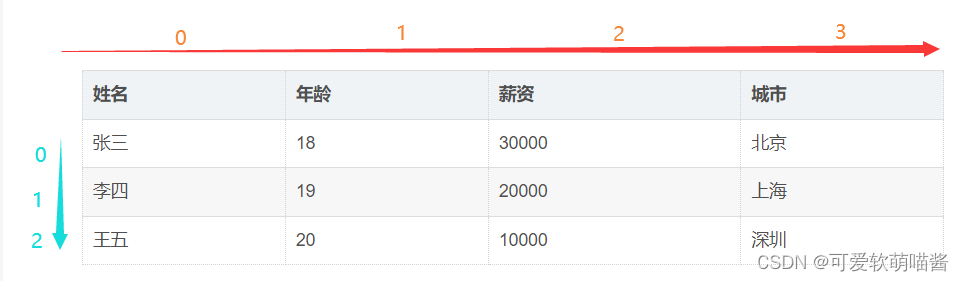
这个时候我们可以使用a[0][0]代表第一行第一列,也就是张三
a[0][1]代表第一行第二列,也就是张三的年龄
那么这份表格该如何用代码里写出来呢?
a = [
["张三",18,30000,"北京"],
["李四",19,20000,"上海"],
["王五",20,10000,"深圳"],
]这就是表格变成代码的样子
实操:输出李四的全部信息
a = [
["张三",18,30000,"北京"],
["李四",19,20000,"上海"],
["王五",20,10000,"深圳"],
]
print(a[1][0],a[1][1],a[1][2],a[1][3]) #输出:李四 19 20000 上海我们还可以通过嵌套循环打印二维列表所有的数据
实操:打印表中全部数据(由于没有学循环,照着敲一遍即可):
a = [
["张三",18,30000,"北京"],
["李四",19,20000,"上海"],
["王五",20,10000,"深圳"],
]
for m in range(3):
for n in range(4):
print(a[m][n],end="\t")
print()
'''输出 张三 18 30000 北京
李四 19 20000 上海
王五 20 10000 深圳'''列表常用方法总结
列表对象的常用方法汇总如下,方便大家学习和查阅。以后需要的时候回来查找即可。
| 方法 | 要点 | 描述 |
|---|---|---|
| list.append(x) | 增加元素 | 将元素x增加到列表list尾部 |
| list.extend(b) | 增加元素 | 将列表list2所有元素加到列表list尾部 |
| list.insert(2,x) | 增加元素 | 在列表list指定位置索引2处插入元素x |
| list.remove(x) | 删除元素 | 在列表list中删除首次出现的指定元素x |
| list.pop([index]) | 删除元素 | 删除并返回列表list指定为止index处的元素,默认是最后一个元素 |
| list.clear() | 删除所有元素 | 删除列表所有元素,并不是删除列表对象 |
| list.index(x) | 访问元素 | 返回第一个x的索引位置,若不存在x元素抛出异常 |
| list.count(x) | 计数 | 返回指定元素x在列表list中出现的次数 |
| len(list) | 列表长度 | 返回列表中包含元素的个数 |
| list.reverse() | 翻转列表 | 所有元素原地翻转 |
| list.sort() | 排序 | 所有元素原地排序 |
| list.copy() | 浅拷贝 | 返回列表对象的浅拷贝 |















 5784
5784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









