







目录
2.2 Use of abstraction in design
3. Huffman coding & Priority queues
3.1 Huffman coding - Abstraction example
3.2 Huffman coding - Key ideas
3.3 More on haffman coding - en-/de-coding
3.4 Use of abstraction in the design of Huffman coding - Data structures & algorithms
3.5 Implementation of Huffman coding using priority queues & binary trees
4.1 Use cases of information hiding
5.1 Encapsulation in an O-O world
5.2 Encapsulation in communication
5.4 Data structures & abstraction, info hiding, encapsulation
7. Static vs dynamic data structures
1. Data Structures
Data Structures covers:
数据结构设计中的一般问题:
- 一维和多维数组
- 链表,双链表及其操作
- 栈(stacks)和栈上的操作
- 队列(queues)和队列上的操作
- 映射(maps)和映射上的操作
- 树和图(Trees&Graphs)
为了更高效地访问数据,数据结构是把数据系统地组织起来的一种方式。每个数据结构都需要其中的算法来处理其中的数据。插入(insertion),删除(delete),检索(retrieval)等算法。因此,学习数据结构要从以下三个方面进行:
- properties
- organisation
- operations
2. Abstraction
We can talk about abstraction either as a process or as an entity.
- As a process: 抽象是指提取一个项目或一组项目的基本细节,而忽略非必要的细节。
- As an entity: 抽象指的是一个模型、一个视图或一些实际项目的表示,它忽略了项目的一些细节。
- Abstraction 规定了某些信息比其他信息更重要,但并没有提供一个具体的机制来处理不重要的信息。
在软件开发中,有以下几种不同的抽象类型:
- Data abstraction: The aim of data abstraction is to identify which details of how data is stored and can be manipulated are important and which are not
- Procedural abstraction: The aim of procedural abstraction is to identify which details of how a task is accomplished are important and which are not
Application of abstraction
- Data Mining, the process of extracting patterns from data, has been applied in many fields to obtain good economical results.
- Big Data Analytics
- Knowledge Discovery in Databases (KDD) is an emerging field under data mining.
- Just as many other forms of knowledge discovery, KDD creates abstractions of the input data.
2.1 Key of abstraction
- Extracting the commonality of components and hiding their details. (提取组建的共性并且隐藏细节)
- Abstraction typically focuses on the outside view of an object or concept. (抽象通常侧重于对象或概念的外部观点)
Examples:
- Looking at a map, we draw roads and highways, forests, not individual trees
- Looking at various bank accounts, what commonality can we extract? Using an O-O approach(面向对象):
- States: AccountNo, CustomerName, Amount
- Behaviour: Credit, Debit, and getAmount
2.2 Use of abstraction in design
Abstraction in design: break things into groups and figure out the details for each separately.
Abstraction leads to a top-down approach.
Most projects can be improved with abstraction:
- Think of the high-level. What do you want to accomplish? There should be one goal. (得到目标)
- Refine this goal into parts (components) (将目标细化成几部分,也就是所说的组件)
- Think of multiple ways to implement each component (考虑实现每个组件的多种方法)
3. Huffman coding & Priority queues
3.1 Huffman coding - Abstraction example
Huffman coding is an effective way of encoding (and decoding) textual (or non-textual) data. It has been used in communication, e.g. source coding. (编码文本数据,解码非文本数据)
A large information system may need a piece of software that carries out the Huffman encoding of the data stored on a disk or generated from some data source. (一个大型信息系统可能需要一个软件,对存储在磁盘上的数据或从某些数据源产生的数据进行哈夫曼编码)
The Huffman encoding software uses priority queue to accomplish its tasks.
Important points:
- The description abstracts from all details on how the priority queue and its operations are implemented. 该描述对优先队列及其操作如何实现的所有细节进行了抽象。
- Nonetheless the description enables a programmer to focus on the design of the particular module using the priority queue functions given. 尽管如此,该描述使程序员能够专注于使用所给的优先级队列功能的特定模块的设计。
3.2 Huffman coding - Key ideas
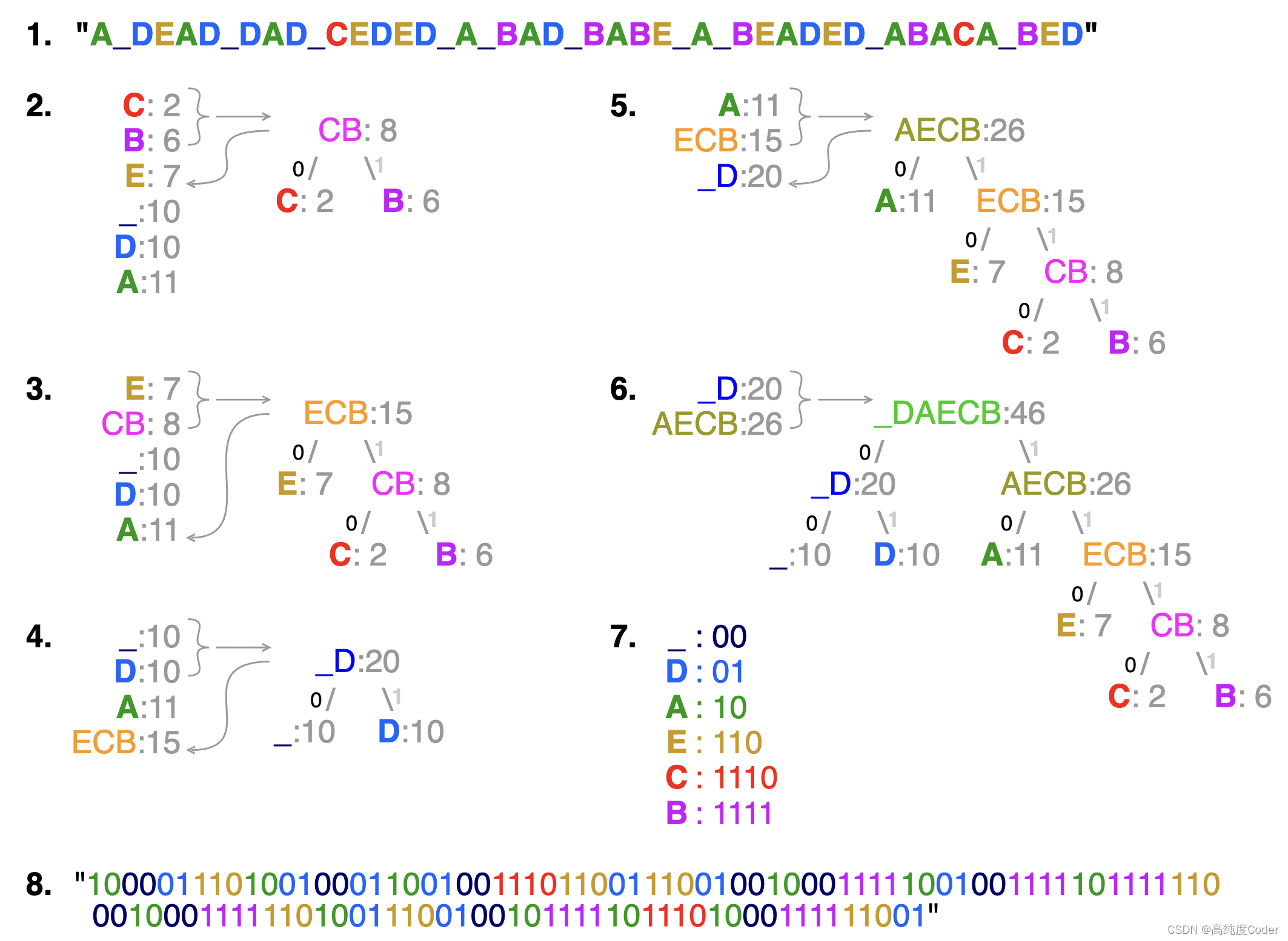
Based on the frequency of occurrence of a data item (pixel in images, alphabet in texts).
Huffman coding 的原理是使用更少的位对频繁出现的数据进行编码
Codes are stored in a Code Book which may be constructed for each image (alphabet) or a set of images.
In all cases the code book plus encoded data must be transmitted to enable decoding. (在所有情况下,都必须传输code book和编码数据,以实现解码)
3.3 More on haffman coding - en-/de-coding
哈夫曼树,也叫最优二叉树。
In computer science and information theory, a Huffman code is a particular type of optimal prefix code that is commonly used for lossless data compression. The process of finding or using such a code proceeds by means of Huffman coding.
The output from Huffman's algorithm can be viewed as a variable-length code table for encoding a source symbol (such as a character in a file). The algorithm derives this table from the estimated probability or frequency of occurrence (weight) for each possible value of the source symbol.
The simplest construction algorithm uses a priority queue where the node with lowest probability is given highest priority:
- Create a leaf node for each symbol and add it to the priority queue.
- While there is more than one node in the queue:
- Remove the two nodes of highest priority (lowest probability) from the queue
- Create a new internal node with these two nodes as children and with probability equal to the sum of the two nodes' probabilities.
- Add the new node to the queue.
- The remaining node is the root node and the tree is complete.
3.4 Use of abstraction in the design of Huffman coding - Data structures & algorithms
Components
- Encoding
- Decoding
- Codebook management
1) A priority queue is a data structure for maintaining a set Q of elements each with an associated value (and key).
A priority queue supports the following operations:
- INSERT(Q,x) inserts the element x into Q.
- MIN(Q) returns the element of Q with minimal key.
- EXTRACT-MIN(Q) removes and returns the element of Q with minimal key.
2) A binary tree is a data structure for maintaining a set Q of nodes each with an associated value and options of left and right child nodes.
A binary tree supports the following operations:
- ALLOCATE-NODE creates a new node(节点), returning a reference to the node z created.
- right(z) refers to the right child node of z.
- left(z) refers to the left child node of z.
3.5 Implementation of Huffman coding using priority queues & binary trees
S is a data structure containing pairs (a, f [a]) where a is a character in the alphabet and f [a] its frequency in the text. Q is a priority queue, initially empty
n <-- |S|; Q <-- S;
for i <--1 to n−1{
z <-- ALLOCATE-NODE()
right[z] <-- EXTRACT-MIN(Q)
x <-- right[z]
left[z] <-- EXTRACT-MIN(Q)
y <-- left[z]
f [z] <-- f [x]+ f [y]
INSERT(Q, z)
}
return EXTRACT-MIN(Q)Not only priority queue is used in the encoding algorithm shown above, but also binary tree.
4. Information hiding
在计算机科学中,信息隐藏是将计算机程序中最有可能发生变化的设计决策进行隔离的原则,从而保护程序的其他部分在设计决策发生变化时不被大量修改。这种保护包括提供一个稳定的接口,保护程序的其余部分不受实现(其细节可能会改变)的影响。以另一种方式书写,信息隐藏是指利用编程语言的特性(如私有变量)或明确的输出策略,防止客户对类或软件组件的某些方面进行访问的能力。
Information hiding is the principle that users of a module need to know only the essential details of this module (as identified by abstraction). So, abstraction leads us to identify details of a module which are important for a user and which are unimportant. Information hiding tells us that we should actively keep all unimportant details secret from the user and try to prevent him from making use any unimportant details.
The important details of a module that a user needs to know form the specification of a module. So information hiding means that modules are used via their specifications, not their implementations.
4.1 Use cases of information hiding
Hide the physical storage layout for data so that if it is changed, the change is restricted to a small subset of the total program. 隐藏数据的物理存储布局,这样,如果它被改变,这个改变会被限制在总程序的一个小子集上。
A module designed with information hiding in mind would protect the remainder of the program from such a change. 一个考虑到信息隐藏的模块可以保护程序的其余部分不受这种变化的影响。
In a well-designed object-oriented application, an object publicizes what it can do—that is, the services it is capable of providing, or its method headers—but hides the internal details both of how it performs these services and of the data (attributes & structures) that it maintains in order to support these services. 在一个精心设计的面向对象的应用程序中,一个对象公开了它能做什么,也就是它能够提供的服务,或者它的方法头,但隐藏了它如何执行这些服务的内部细节,以及它为了支持这些服务而维护的数据(属性和结构)。
4.2 Java method signature
The signature of a method is the combination of
- method's name along with
- number and types of the parameters (and their order).
signature: 方法名和形参
5. Encapsulation
Like abstraction, we can consider encapsulation either as a process or as an entity:
- As a process, encapsulation means the act of enclosing one or more items (data/functions) within a (physical or logical) container. 作为一个过程,封装是指将一个或多个项目(数据/功能)封闭在一个(物理或逻辑)容器中的行为。
- As an entity, encapsulation, refers to a package or an enclosure that holds (contains, encloses) one or more items (data/functions). 作为一个实体,封装是指容纳(包含,包围)一个或多个项目(数据/功能)的包或外壳。
The separator between the inside and the outside of this enclosure is sometimes called wall or barrier.
5.1 Encapsulation in an O-O world
In object-oriented programming, encapsulation is the inclusion within an object of all the resources needed for the object to function – i.e., the methods and the data. 在面向对象的编程中,封装是将对象运行所需的所有资源(即方法和数据) 包含在一个对象中。
The object is said to publish its interfaces. Other objects adhere to these interfaces to use the object without having to worry how the object accomplishes it. 这个对象发布一个接口,其他对象遵守这些接口来使用该对象,而不必担心该对象是如何完成的。
An object can be thought of as a self-contained atom. The object interface consists of public methods and instantiated data. 一个对象可以被认为是一个独立的原子。对象的接口由公共方法和实例化的数据组成。
5.2 Encapsulation in communication
In communication, encapsulation is the inclusion of one data structure within another structure so that the first data structure is hidden. For example, a TCP/IP-formatted packet can be encapsulated within an ATM frame. Within the context of sending and receiving the ATM frame, the encapsulated packet is simply a bit stream that describes the transfer. 在通信中,封装是将一个数据结构包含在另一个结构中,从而使第一个数据结构被隐藏。 例如,一个TCP/IP格式的数据包可以被封装在一个ATM帧中。 在发送和接收ATM帧的情况下,封装的数据包只是一个用来描述传输的比特流。
5.3 Comparisons
- Abstraction is a technique that helps us identify which specific information is important for the user of a module, and which information is unimportant. 确定哪些重要哪些不重要
- Information hiding is the principle that all unimportant information should be hidden from a user. 把不重要的隐藏起来
- Encapsulation is then the technique for packaging the information in such a way as to hide what should be hidden, and make visible what is intended to be visible. 打包,将应该隐藏的东西隐藏起来,并将打算显示的东西显示出来。
Using the processes of abstraction and encapsulation under the guidinglines of information hiding, we enjoy the following advantages:
- Simpler, modular programs that are easier to design & understand.
- Side-effects from direct manipulation of data are eliminated or minimised.
- Localisation of errors (only methods defined on a class can operate on the class data), which allows localised testing.
- Program modules are easier to read, change, and maintain.
5.4 Data structures & abstraction, info hiding, encapsulation
Data structures represent one big common factor across programs. Specification of data structures requires the use of abstraction, info hiding, encapsulation. Practice of abstraction, info hiding, encapsulation on modular programming leads to further development of data structures. Further development of data structures leads to better modular programming. 数据结构的规范需要使用抽象、信息隐藏和封装的方法。 模块化编程中的抽象、信息隐藏、封装的实践导致了数据结构的进一步发展。 数据结构的进一步发展导致了更好的模块化编程。
6. Efficiency in space & time
6.1 Efficiency in space
A well-chosen data structure should try to minimise memory usage (avoid the allocation of unnecessary space).
6.2 Efficiency in time
A well-chosen data structure will include operations that are efficient in terms of speed of execution (based on some wellchosen algorithm). For our purposes the most important measure for the speed of execution will be the number of accesses to data items stored in the data structure. 对于我们的目的来说,衡量执行速度的最重要标准是对存储在数据结构中的数据项的访问次数。
7. Static vs dynamic data structures
Besides time and space efficiency another important criterion for choosing a data structure is whether the number of data items it is able to store can adjust to our needs or is bounded. This distinction leads to the notions of dynamic data structures vs. static data structures. 除了时间和空间效率之外,选择数据结构的另一个重要标准是它能够存储的数据项的数量是否能够根据我们的需要进行调整或者是有限制的。 这种区别导致了动态数据结构与静态数据结构的概念。
- Dynamic data structures grow or shrink during run-time to fit current requirements e.g. a structure used in modelling traffic flow.
- Static data structures are fixed at the time of creation. example: a structure used to store a postcode or credit card number (which has a fixed format).
Note that it is the structure that is static (or dynamic), not the data. So, in a static data structure the stored data can change over time, only the structure is fixed. Of course, the stored data could also stay constant in both static and dynamic data structures.
Note that in the definition of a static data structure we have placed no constraints on when it is created, only that once it is created it will be fixed. This will be important when we determine whether arrays in Java are static data structures or not! 在静态数据结构的定义中,我们没有对它的创建时间进行限制,只是说一旦创建,它就会被固定下来。 当我们确定Java中的数组是否是静态数据结构时,这将是非常重要的。
7.1 Static data structures
Advantages
- Ease of specification. Programming languages usually provide an easy way to create static data structures of almost arbitrary size.
- No memory allocation overhead. Since static data structures are fixed in size, 1) There are no operations that can be used to extend static structures; 2) Such operations would need to allocate additional memory for the structure (which takes time). 没有内存分配的开销。 由于静态数据结构的大小是固定的,1)没有可以用来扩展静态结构的操作;2)这种操作需要为结构分配额外的内存(这需要时间)。
Disadvantages
- Must make sure there is enough capacity. Since the number of data items we can store in a static data structure is fixed, once it is created, we have to make sure that this number is large enough for all our needs. 必须确保有足够的容量。 由于我们可以在静态数据结构中存储的数据项的数量是固定的,一旦它被创建,我们必须确保这个数字足以满足我们所有的需求。
- More elements? (errors), fewer elements? (waste) 1) However, when our program tries to store more data items in a static data structure than it allows, this will result in an error (e.g. ArrayIndexOutOfBoundsException) 2) On the other hand, if fewer data items are stored, then parts of the static data structure remain empty, but the memory has been allocated and cannot be used to store other data. 1)当我们的程序试图在静态数据结构中存储超过它所允许的数据项时,这将导致一个错误(例如ArrayIndexOutOfBoundsException)2)另一方面,如果存储较少的数据项,那么静态数据结构的部分仍然是空的,但内存已被分配,不能用来存储其他数据。
7.2 Dynamic data structures
Advantages
- There is no requirement to know the exact number of data items since dynamic data structures can shrink and grow to fit exactly the right number of data items, there is no need to know how many data items we will need to store. 没有要求知道数据项的确切数量,因为动态数据结构可以收缩和增长,以适应确切的数据项数量,所以没有必要知道我们需要存储多少数据项。
- Efficient use of memory space. Extend a dynamic data structure in size whenever we need to add data items which could otherwise not be stored in the structure and shrink a dynamic data structure whenever there is unused space in it, then the structure will always have exactly the right size and no memory space is wasted. 有效地利用内存空间。每当我们需要增加数据项时,就扩大动态数据结构的大小,否则就不能存储在结构中,每当动态数据结构中出现未使用的空间时,就缩小动态数据结构的大小,那么该结构将永远有准确的大小,没有内存空间被浪费。
Disadvantages
- Memory allocation/de-allocation overhead. 内存分配/释放的开销
- Whenever a dynamic data structure grows or shrinks, then memory space allocated to the data structure has to be added or removed (which requires time). 每当动态数据结构增长或收缩时,就必须增加或删除分配给该数据结构的内存空间(这需要时间)。
8. Q&A(著名有Q无A环节doge)
- Both space efficiency & time efficiency are metrics used to evaluate the performance of an algorithm (and a data structure).
- Dynamic data structures are more space efficient in general.
- Static data structures are more time efficient in general.
- Information hiding is the principle that users of a software component need to know only the essential details of how to initialize and access the component, and do not need to know the details of the implementation.
Answer: all True;
课堂笔记,整理不易,有失偏颇的地方还请大佬们及时指正😭
















 3254
3254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











