






一、常用库函数
1、sort:包含在头文件<algorithm>中,使用类似于快速排序的改进算法
用法 sort(起始地址,结束地址的下一位,*比较函数) 平均时间复杂度nlogn
2.max(x,y) max({1,2,3,4}) min(x,y) min({1,2,3,4}) 时间复杂度1
3.min_element(st,ed)返回地址[st,ed)中最小的那个值的下标 (选代器),传入参数为两个地址或迭代器
max_element(st,ed)返回地址[st,ed)中最大的那个值的下标 (选代器),传入参数为两个地址或迭代器
时间复杂度均为O(n),n为数组大小(由传入的参数决定)
4.nth_element(st,k,ed)
进行部分排序,返回值为void()传入参数为三个地址或迭代器。其中第二个参数位置的元素将处于正确位置,其他位置元素的顺序可能是任意的,但前面的都比它小,后面的都比它大。时间复杂度O(n)
5.binary_search:(起始地址,结束地址的下一个地址,要找的值)二分查找,返回bool
6.lower_bound和upper_bound
使用前提:数组为非降序
lower_bound(st,ed,x)返回地址[st,ed)第一个大于等于x的元素的地址
upper_bound 大于x
7.islower(char ch)/isupper(char ch):检查字符大小写。需要包含头文件<cctype> 返回bool
8.tolower(char ch)和toupper(char ch):如果不是大/小写字母则不进行操作
9.ASCII码
字符‘0’~‘9’对应十进制:48~57
A~Z:65~90
a-z:97~122
10.全排列
10.1.next_permutation()
next_permutation 函数用于生成当前序列的下一个排列。它按照字典序对序列进行重新列,如果存在下一个排列,则将当前序列更改位下一个排列,并返回 true;如果当前序列已经是最后一个排列,则将序列更改为第一个排列并返回 false。
10.2.prev_permutation()
prev-permutation 函数与 next_permutation 函数相反,它用于生成当前序列的上一个排列。它按照字典序对序列进行重新排列,如果存在上一个排列,则将当前序列更改为上一个排列,并返回true;如果当前序列已经是第一个排列,则将序列更改为最后一个排列,并返回 false。
11.其他库函数
11.1memset()
用于设置内存块值的函数,原型定义在<cstring>头文件中,返回一个指向ptr的指针(返回值没啥用)
需要注意的是,memset0函数对于非字符类型的数组可能会产生未定义行为
函数声明:void* memset(void* ptr,int value,size_t num)
ptr:指向要设置值的内存块的指针
value:要设置的值,通常为整数(8位二进制数)
num:要设置的字节数
memset(arr,0,sizeof(arr))将数组arr的所有元素设置为0
11.2.swap(可用于交换任意类型的变量)
swap(T &a,T &b)
a:第一个值的引用
b:第二个值的引用
11.3reverse:用于反转容器中元素顺序的函数,原型定义在<algorithm>;只能支持双向迭代器的 容器
函数声明:template<class Bidirit>
void reverse(Bidirit first,Bidirit last);
Bidirit:地址/迭代器
first:指向容器中要反转的第一个元素的迭代器
last:指向容器中要反转的最后元素的下一个元素的迭代器
11.4unique:用于去除相邻重复元素的函数,原型在<algorithm>头文件
unique(first,last)函数接受两个参数:
first:指向容器中要去重的第一个元素的迭代器
last: 指向容器中要去重的最后一个元素的下一个位置的迭代器
unique()函数将[first, last)范围内的相邻重复元素去除,并返回一个指向去重后范围的尾后迭代器
时间复杂度n
二、STL
1.pair:是一个模板类,表示一对值的集合,位于<utility>头文件
pair的定义
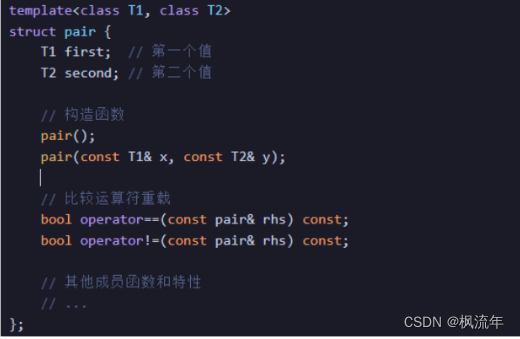
T1、T2分别是第一个值和第二个值的类型
first,second=分别为第一个值和第二个值
pair自带排序规则是按照first成员升序排序,若相等,则按照second成员排序,可自定义排序
2.vector:是一个动态数组容器,可以存储一系列相同类型元素,标准库<vector>中定义的模板类
2.1特性
- 容器大小:vector是一个动态数组,可以根据需要自动调整大小。它会根据元素的数量动态分配内存空间。
- Gint元素访问:可以通过索引来访问vector中的元素。索引从0开始,最后一个元素的索引是size-1,可以使用[]运算符或at()函数来访问元素
- 元素添加和删除:可以使用push_back()函数在vector的末尾添加元素,使用pop-back()函数删除未尾的元素。还可以使用insert()函数在指定位置插入元素,使用erase()函数删除指定位置的元素
- 容器大小管理: 可以使用size()函数获取vector中元素的数量,使用empty()函数检查vector是否为空函数调救,还可以使用resize()函数调整vector的大小。
- 迭代器: vector提供了迭代器,可以用于遍历容器中的元素。可以使用begin()函数获取指向第一个元素的迭代器,使用end0函数获取指向最后一个元素之后位置的迭代器
2.2vector常用函数
push_back():将元素添加到容器末尾
pop_back():删除容器末尾的元素
begin()和end():返回指向vector第一个元素和最后一个元素之后位置的迭代器
2.3vector排序
可用sort函数,两个参数分别为v.begin()和v.end()
2.4vector去重
先对vector排序
再用unique将重复元素移动到容器末尾,并返回指向末尾第一个重复元素的迭代器
最后使用erase将重复元素删除
3.list
list的使用频率不高,在做题时极少遇到需要使用list的情景list是一种双向链表容器,它是标准模板库(STL) 提供的一种序列容器list容器以节点 (node) 的形式存储元素并使用指针将这些节点链接在一起,形成一个链表结构。


4.stack:stack是一种后进先出 (LIFO) 的数据结构,使用前需要包含头文件<stack>
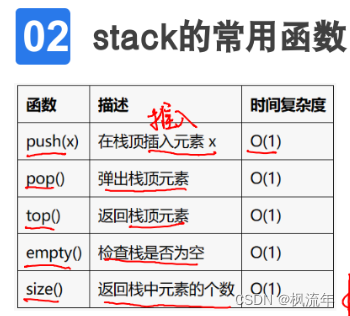
tips:将一个数组元素依次放入栈,再依次取出,可以实现数组翻转
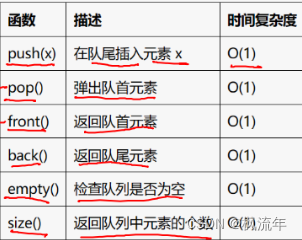
5.queue
5.1queue常用函数
5.2.priority-queue优先队列(考察频率高)
priority定义和结构

| 函数 | 描述 | 时间复杂度 |
| push(x) | 将元素插入到优先队列中 | O(logN) |
| pop() | 弹出优先队列中的顶部元素 | O(logN) |
| top() | 返回优先队列中的顶部元素 | O(1) |
| empty() | 检查优先队列是否为空 | O(1) |
| size() | 返回优先队列中元素的个数 | O(1) |
如果优先队列中元素类型比较简单,可以直接使用greater<T>来修改比较方法
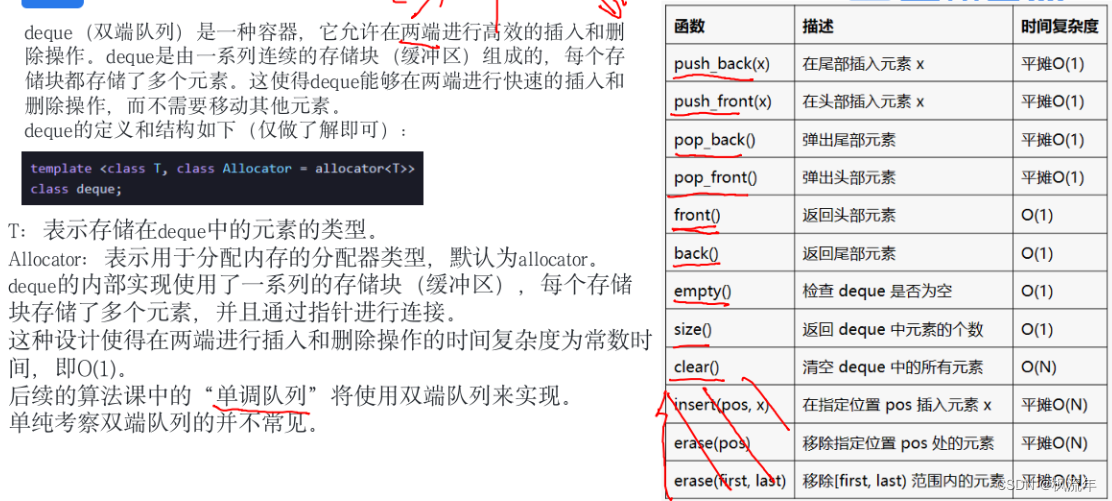
5.3deque双端队列
6.set
用于存储一组唯一的元素,并按照一定的排序规则进行排序,set中的元素是按照升序排序的,默认情况使用<进行排序
定义和结构:

Key:存储在set中元素的类型
Compare:表示元素之间的比较函数对象的类型
Allocator:用于分配内存的分配器类型
内部使用红黑树存储元素,并保持元素的有序性,使得 set在插入删除查找的时间复杂度都是对数时间,即O(logN)
常用函数
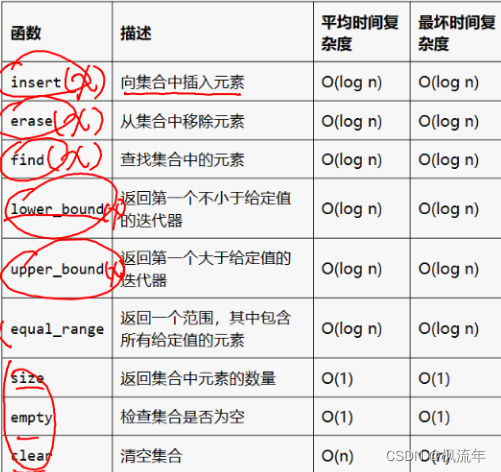
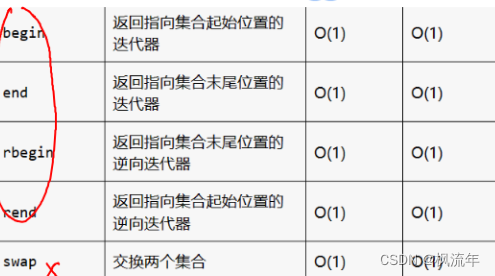
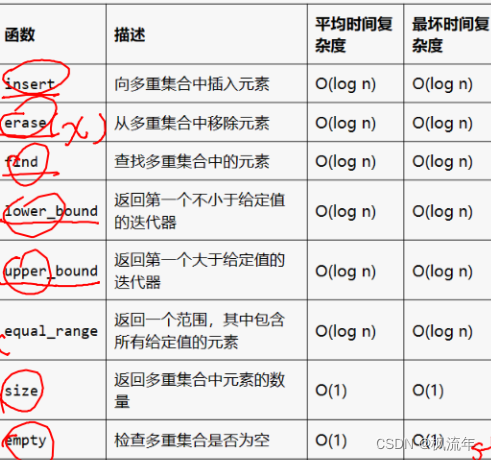
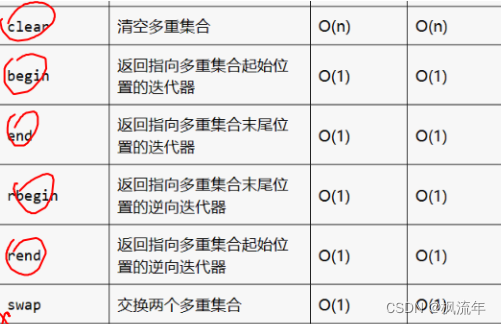
6.1.multiset多重集合:允许存储重复的元素
常用函数
6.2 unordered_set:存储唯一的元素,没有顺序,使用哈希表存储和访问,因此插入删除查找时间复杂度为O(1) (很少用)
7.map
一种关联容器,存储一组键值对,每个键都是唯一的。根据健自动进行排序,并且可以通过健快速查找对应的值。map使用红黑树实现,插入删除查找O(logn)
定义和结构

Key:键的类型
T:值的类型
Compare:比较函数。默认less
Allocator:分配内存的分配器类型,默认allocator
| 函数 | 功能 | 时间复杂度 |
| insert | 插入元素 | O(log n) |
| erase | 删除元素 | O(log n) |
| find | 查找元素 | O(log n) |
| count(key) (判断元素是否存在) | 统计元素个数 | O(log n) |
| size | 返回元素个数 | O(1) |
| begin | 返回指向容器起始位置的迭代器 | O(1) |
| end | 返回指向容器末尾位置的迭代器 | O(1) |
| clear | 清空容器 | O(n) |
| empty | 判断容器是否为空 | O(1) |
| lower_bound | 返回指向第一个不小于指定键的元素位置 | O(log n) |
| upper_bound | 返回指向第一个大于指定键的元素位置 | O(log n) |
7.1multimap:允许存储多个具有相同键的键值对,蓝桥杯几乎用不到
7.2unordered_map:键唯一,不排序(不稳定,少用)















 503
503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









