本次更新内容:2.14图论例题补充
目录
1 技巧
1.1 取消同步(节约时间,甚至能多骗点分,最好每个程序都写上)
1.2 万能库(可能会耽误编译时间,记不住头文件就用这个)
1.3 return 0
1.4 编译设置(Dev C++)
1.5 memset、fill填充函数
1.5.1 memset
1.5.2 fill
1.6 时间复杂度
1.6.1 常数阶 O(1)
1.6.2 对数阶 O(logn)
1.6.3 线性阶 O(n)
1.6.4 线性对数阶 O(nlogn)
1.6.5 多重循环 O(n^k)
1.7 剪枝
1.8 find函数
1.9 PI问题
1.10 C/C++帮助文档
1.11 最大空间
1.11.1 占用字节大小
1.11.2 常用数据范围
1.12 指针存字符串(了解)
1.13 日期填空题巧用电脑自带Office软件
1.13.1 求日期差(excel)
1.13.2 求日期差(计算器)
1.13.3 求星期几(excel)
1.13.4 例题(excel+word)
1.13.5 日期常用函数
1.14 字符串的精读
1.15 约瑟夫环
1.16 文件读取
1.17 输入流/输出流进制控制
1.18 setbase+setw+setfill
2 算法+数据结构
2.1 BFS(宽度优先搜索)
2.2 DFS(深度优先搜索)
2.3 最大公约数(greatest common divisor,gcd)和最小公倍数(least common multiple,lcm)
2.3.1 手写
2.3.2 套用库函数
2.4 进制转换+超大数据处理
2.4.1 十进制为媒介(常用型)
2.4.2 二进制为媒介(技巧型)(含超大数据处理)
2.5 二进制表示法
2.6 背包问题
2.7 动态规划(DP)
2.8 贪心
2.9 分治(以后更新)
2.10 数字分拆到数组中
2.11 数字和字符串的互化
2.12 排序
2.13 冒泡排序法和二分查找法(最常用)
2.14 图论
2.15 常用树的模板
2.16 快速幂算法
2.17 质因数算法
2.18 递归
2.19 STL
2.20 尺取法
2.21 倍增法(ST算法)(以后更新)
2.22 KMP算法
2.23 LIS算法和LCS算法
2.24 树状数组
2.25 二分法
3 C语言容易出错的问题
1 技巧
1.1 取消同步(节约时间,甚至能多骗点分,最好每个程序都写上)
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
1.2 万能库(可能会耽误编译时间,记不住头文件就用这个)
#include <bits/stdc++.h>
1.3 return 0
1.4 编译设置(Dev C++)
(1)工具->编译选项->编译器->编译时加入以下命令->调成C99
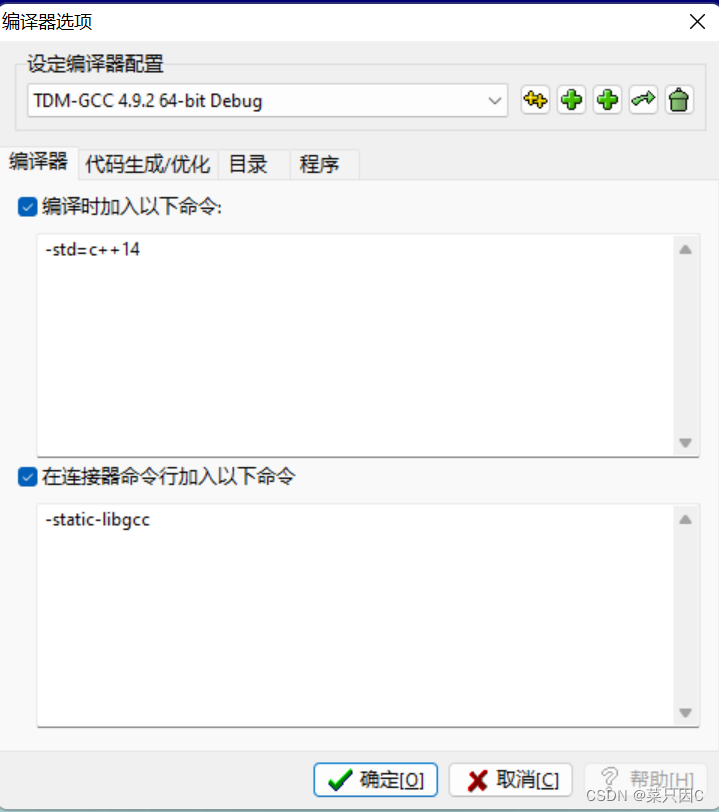
(2)工具->编译选项->代码生成/优化->代码生成->语言标准

1.5 memset、fill填充函数
1.5.1 memset
按照字节对内存块进行初始化,注意只能填充0或-1
#include <bits/stdc++.h>
using namespace std;
int a[10];
int main()
{
memset(a,-1,sizeof(a));
for(int i=0;i<10;i++)
{
cout<<a[i]<<endl;
}
return 0;
}
1.5.2 fill
可以填充任意数字
#include <cstdio>
#include <algorithm>
using namespace std;
int main() {
int arr[10];
fill(arr, arr + 10, 2);
return 0;
}
1.6 时间复杂度
蓝桥杯每一道题编译时间都限制在1s以内,遇到数据比较大的题目,往往需要降低时间复杂度。
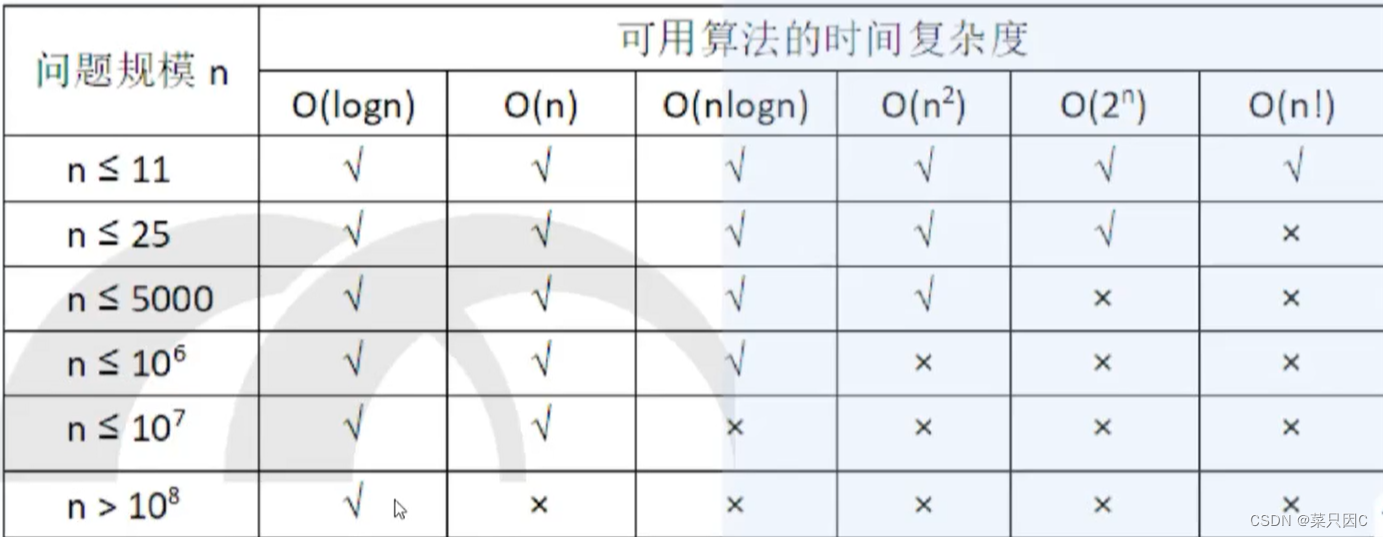
由于蓝桥杯评测系统是根据通过样例数来评分,所以我们做题时一定要注意约定样例取值范围。
例题:K倍区间(暴力法只能通过部分样例,所以要用更好的算法)
(1条消息) K倍区间(蓝桥杯2017年第八届省赛B组第十题)(C/C++)_菜只因C的博客-CSDN博客 https://blog.csdn.net/m0_71934846/article/details/128434135?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_71934846/article/details/128434135?spm=1001.2014.3001.5501
1.6.1 常数阶 O(1)
int i=1;
int j=2;
int m=i+j;
1.6.2 对数阶 O(logn)
int i=1;
while(i<n)
{
i=i*2;
}
1.6.3 线性阶 O(n)
for(int i=0;i<n;i++)
{
cout<<i<<endl;
)
1.6.4 线性对数阶 O(nlogn)
for(int m=1;m<n;m++)
{
int i=1;
while(i<n)
{
i=i*2;
}
}
1.6.5 多重循环 O(n^k)
k为循环层数
1.7 剪枝
做题时已经发现的不可能取到的数值,就不要再让计算机算了,尽量节省时间,蓝桥杯中目前遇到的还没有用到过过于繁琐的剪枝,大多也是在BFS和DFS中出现(bool vis)
例题:货物摆放
(4条消息) 货物摆放(蓝桥杯C/C++省赛)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/129349475?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22129349475%22%2C%22source%22%3A%22m0_71934846%22%7D
1.8 find函数
函数作用:查找该元素在数组中第一次出现的位置的地址(类似于0x的地址)
模型:find(查找起点,查找终点,查找目标元素)
同样,查找区间为[查找起点,查找终点)
#include <bits/stdc++.h>
using namespace std;
int main()
{
int a[10]={2,6,8,1,3,7,5,1,0,11};
cout<<find(a+0,a+5,8)<<endl;//打印类似0x地址
cout<<find(a+0,a+5,8)-a<<endl;//打印数组【】内的序号
return 0;
}
1.9 PI问题
PI=atan(1.0)*4
PI=3.14159265
1.10 C/C++帮助文档

1.11 最大空间
1.11.1 占用字节大小
| 类型 | 32位计算机 | 64位计算机 |
| char | 1 | 1 |
| short int | 2 | 2 |
| int | 4 | 4 |
| long int | 4 | 8 |
| long long int | 8 | 8 |
| char* | 4 | 8 |
| float | 4 | 4 |
| double | 8 | 8 |
1.11.2 常用数据范围
| 类型 | 范围 | 估计值 |
| char | -128~+127 | |
| short | -32767~+32768 | 3*10^4 |
| unsigned short | 0~+65536 | 6*10^4 |
| int=long | -2147483648~+2147483647 | 2*10^9 |
| unsigned int | 0~+4294967295 | 4*10^9 |
| long long | -9223372036854775808~+9223372036854775807 | 9*10^18 |
1.12 指针存字符串(了解)
这个比赛很少用指针,如果想要存储字符串,用指针也是一个不错的选择(直接可以用string类避免用指针)
//指针数组存储字符串列表
#include <stdio.h>
const int max = 5;
int main()
{
const char *names[] =
{ //定义指针数组,存储字符串列表
"Zhang San", //每个元素都是双引号括起来的
"Li Si",
"Wang Wu",
"Su Wukong",
"Tang Er",
};
int i=0;
for(i=0;i<max;i++)
{
printf("Value of names[%d] = %s\n",i,names[i]); // 注意 %s
}
return 0;
}
1.13 日期填空题巧用电脑自带Office软件
1.13.1 求日期差(excel)
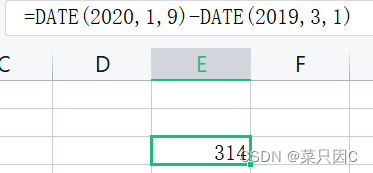
格中输入:
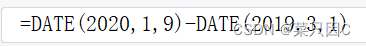
回车:
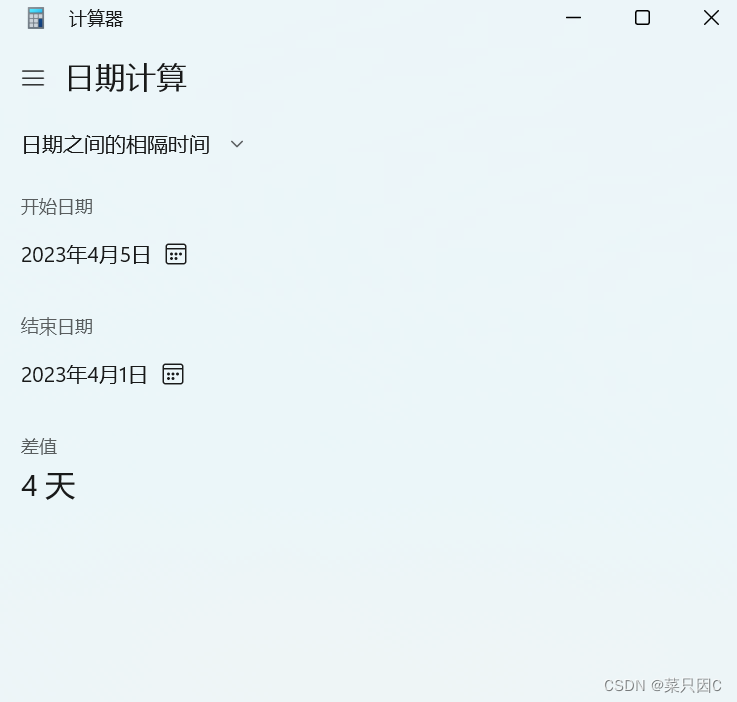
1.13.2 求日期差(计算器)
日期计算
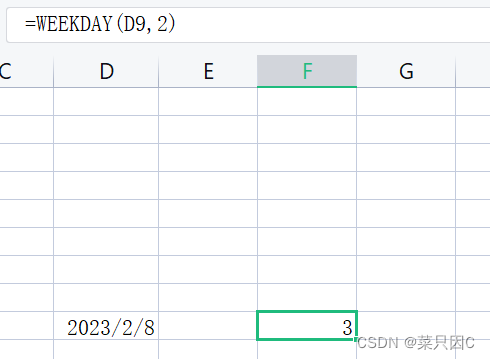
1.13.3 求星期几(excel)
在一个格中输入日期:

在另一个格中输入:
(第一个参数表示日期所在位置,第二个参数表示输出样式(会有提示))
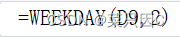
回车:
1.13.4 例题(excel+word)
题目描述
小蓝每天都锻炼身体。
正常情况下,小蓝每天跑 1 千米。如果某天是周一或者月初(1 日),为了激励自己,小蓝要跑 2 千米。如果同时是周一或月初,小蓝也是跑 2 千米。
小蓝跑步已经坚持了很长时间,从 2000 年 1 月 1 日周六(含)到 2020 年 10 月 1 日周四(含)。请问这段时间小蓝总共跑步多少千米?
这题明显用代码写就过于复杂,还容易出错
首先用excel填充2000年1月1日到2020年10月1日(发现共有7580行)
然后设置单元格格式排成

这样的格式
这个时候我发现的问题是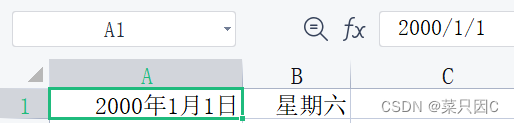
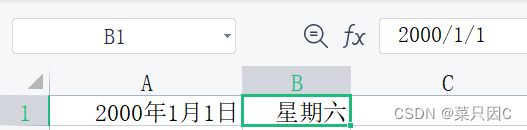
感觉好像只是把外衣改了一下,但本质还是2000/1/1这个格式,导致替换出现问题(查找似乎还没有问题,这块不太懂,懂的佬麻烦给我指点一下)
这样的话我索性把AB列复制到word里(仅保留文字)
根据word复制过去的文字的格式查找
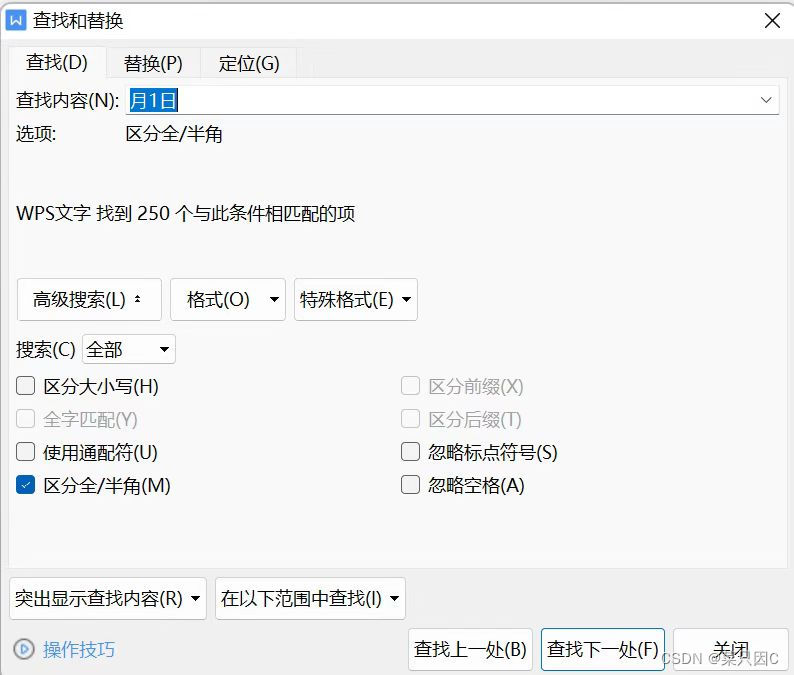
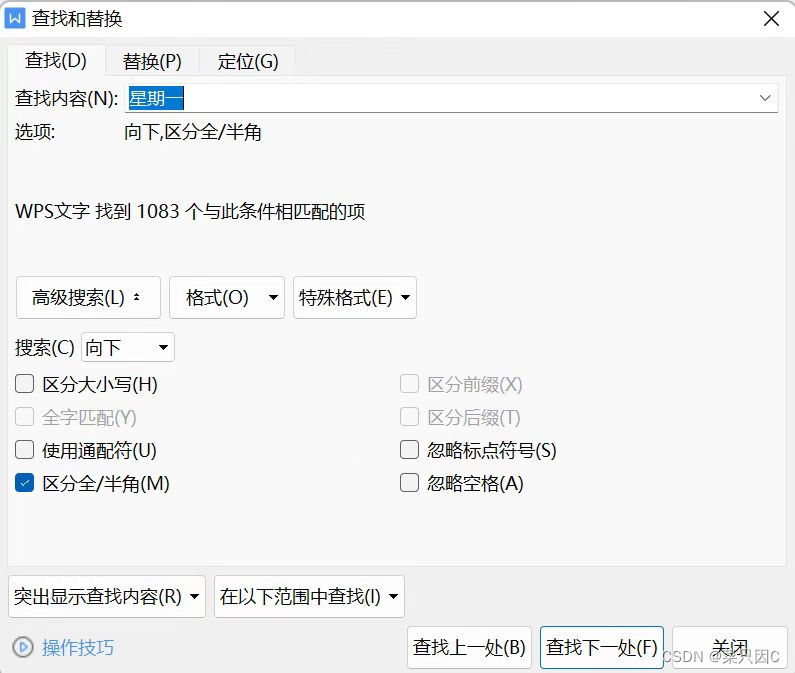
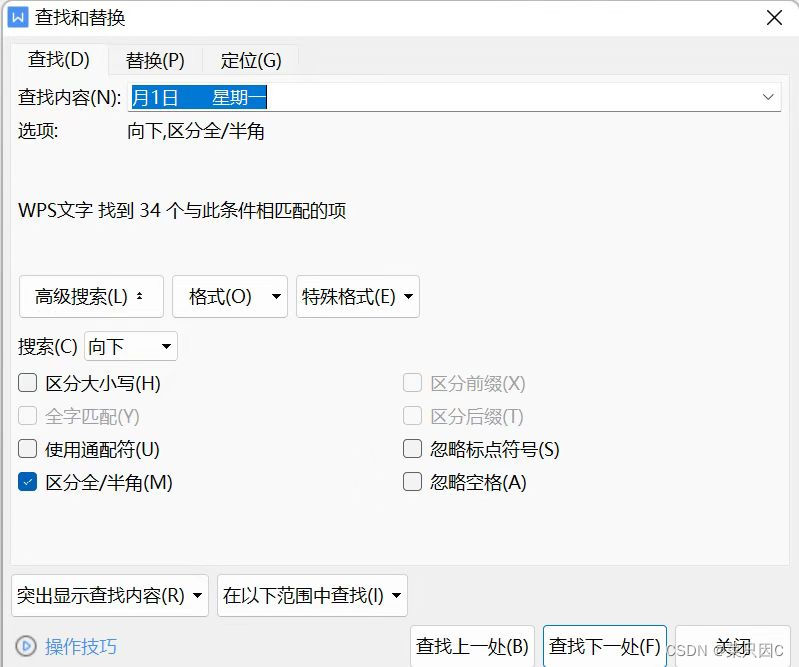
总共有1083个星期一
总共有250个1日
总共有34个星期一&&1日
所以有250+1083-34=1299天需要跑两公里
总共有7580天
所以有7580-1299=6281天需要跑一公里
所以共跑1299*2+6281*1=8879公里
1.13.5 日期常用函数
日期部分处理(C/C++)_菜只因C的博客-CSDN博客日期部分处理(C/C++) https://blog.csdn.net/m0_71934846/article/details/129697869?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22129697869%22%2C%22source%22%3A%22m0_71934846%22%7D
https://blog.csdn.net/m0_71934846/article/details/129697869?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22129697869%22%2C%22source%22%3A%22m0_71934846%22%7D
1.14 字符串的精读
(8条消息) 字符串的特殊读取——基于蓝桥杯两道题目(C/C++)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/129051871?spm=1001.2014.3001.5502
1.15 约瑟夫环
(11条消息) 约瑟夫环(蓝桥杯决赛C/C++)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/129048522?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22129048522%22%2C%22source%22%3A%22m0_71934846%22%7D
1.16 文件读取
购物清单(蓝桥杯C/C++省赛)_菜只因C的博客-CSDN博客购物清单(蓝桥杯C/C++省赛)https://blog.csdn.net/m0_71934846/article/details/129333108?spm=1001.2014.3001.5501
1.17 输入流/输出流进制控制
#include <bits/stdc++.h>
using namespace std;
int main()
{
int a=10;
cout<<oct<<10<<endl<<hex<<10<<endl<<dec<<10<<endl;
printf("%#o %#x %#d",a,a,a);//012 0xa 10
return 0;
}
1.18 setbase+setw+setfill
#include <bits/stdc++.h>
using namespace std;
int main()
{
int x,n,a[100];
cin>>n;
for(int i=0;i<n;i++)
{
cin>>hex>>x;
a[i]=x;
}
for(int i=0;i<n;i++)
{
cout<<setbase(8)<<a[i]<<endl;
}
return 0;
}
#include <bits/stdc++.h>
using namespace std;
int main()
{
cout<<setw(25)<<256<<endl;//前面有25-3=22个空格
cout<<setfill('9')<<setw(10)<<256;//前面有7个9
}
2 算法+数据结构
2.1 BFS(宽度优先搜索)
用到队列(有时会用到优先队列)
主要思想:把所有符合条件的点都压入队列,然后挨个元素弹出上下左右前后搜索,直到队列清空时代表搜索完毕,搜索的时候注意判断是否已经搜索过,用bool vis【】判断。
例题1:全球变暖
(1条消息) 全球变暖(蓝桥杯2018年省赛B组试题I)(C/C++)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/128434254?spm=1001.2014.3001.5502
例题2:跳马
(2条消息) 跳马(蓝桥杯算法训练C/C++)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/128807974?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128807974%22%2C%22source%22%3A%22m0_71934846%22%7D
2.2 DFS(深度优先搜索)
用到递归(不好理解)
主要模板:可参见如下全排列例题
(2条消息) 全排列(C/C++)(DFS)_菜只因C的博客-CSDN博客_全排列c++dfshttps://blog.csdn.net/m0_71934846/article/details/128721334?spm=1001.2014.3001.5501总结起来有如下几步:
(1)确定 边界 if()return;
(2)进入for循环
(3)判断是否搜索过 if(vis[])vis[]=true; dfs(); vis[]=false;
DFS例题合集(不定时更新):
(6条消息) DFS合集(蓝桥杯C/C++)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/128876358?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128876358%22%2C%22source%22%3A%22m0_71934846%22%7D
2.3 最大公约数(greatest common divisor,gcd)和最小公倍数(least common multiple,lcm)
2.3.1 手写
最大公约数
#include <bits/stdc++.h>
using namespace std;
int a,b;
int main()
{
scanf("%d%d",&a,&b);
for(int i=min(a,b);i>=1;i--)
{
if(a%i==0&&b%i==0)
{
printf("%d",i);
break;
}
}
return 0;
}
最小公倍数
#include <bits/stdc++.h>
using namespace std;
int a,b;
int main()
{
scanf("%d%d",&a,&b);
for(int i=1;i<=a*b;i++)
{
if(i%a==0&&i%b==0)
{
printf("%d",i);
break;
}
}
return 0;
}
2.3.2 套用库函数
最大公约数
#include <bits/stdc++.h>
using namespace std;
int main()
{
cout<<__gcd(25,5);
return 0;
}
最小公倍数
多写一个lcm函数
#include <bits/stdc++.h>
using namespace std;
int lcm(int a,int b)
{
return a*b/__gcd(a,b);
}
int main()
{
cout<<lcm(25,5);
return 0;
}
2.4 进制转换+超大数据处理
2.4.1 十进制为媒介(常用型)
(8条消息) 任意进制转换成十进制/十进制转换成任意进制(ASCII码法)(C/C++)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/128297645?spm=1001.2014.3001.5502
2.4.2 二进制为媒介(技巧型)(含超大数据处理)
十六进制转八进制+超大数据处理(蓝桥杯基础练习C/C++)_菜只因C的博客-CSDN博客十六进制转八进制+超大数据处理(蓝桥杯基础练习C/C++)https://blog.csdn.net/m0_71934846/article/details/128745875?spm=1001.2014.3001.5502
2.5 二进制表示法
例题:无聊的逗
(8条消息) 蓝桥杯试题 算法训练 无聊的逗(C/C++)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/128717938?spm=1001.2014.3001.5502
2.6 背包问题
(3条消息) 背包问题代码合集(C/C++)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/128989505?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128989505%22%2C%22source%22%3A%22m0_71934846%22%7D
2.7 动态规划(DP)
例题1:拿金币
(1条消息) 拿金币(蓝桥杯算法训练)(C/C++)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/128456365?spm=1001.2014.3001.5502
例题2:包子凑数
包子凑数(蓝桥杯2017年省赛B组试题H)(C/C++)_菜只因C的博客-CSDN博客包子凑数(蓝桥杯2017年省赛B组试题H)(C/C++)https://blog.csdn.net/m0_71934846/article/details/128434225?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128434225%22%2C%22source%22%3A%22m0_71934846%22%7D
2.8 贪心
思路:选取局部最优解,但是最大的缺陷就是在某些情况下不适用
举例:纸币问题
比如面额有1元,2元,5元,10元,20元,50元,100元,那么对于110元来说,可以用贪心从最大面额100元开始找。
但是如果改纸币面额,比如1元,2元,5元,20元,55元,100元,那么如果用到贪心算法,会发现并不能找出最优解(贪心:100+5+5=110 动态规划:55+55=110)
动态规划代码如下:
#include <bits/stdc++.h>
using namespace std;
int dp[10000];
int n;
int b[6]={1,5,20,50,55,100};
int temp;
int main()
{
dp[0]=0;
dp[1]=1;
dp[5]=1;
dp[20]=1;
dp[50]=1;
dp[55]=1;
dp[100]=1;
for(int i=1;i<=10000;i++)
{
temp=10000;
for(int k=0;k<6;k++)
{
if(i>=b[k])
{
temp=min(dp[i-b[k]]+1,temp);
}
}
dp[i]=temp;
}
for(int i=1;i<10000;i++)
{
cout<<i<<"元用"<<dp[i]<<"张"<<endl;
}
return 0;
}
2.9 分治(以后更新)
大部分是二分法
2.10 数字分拆到数组中
(2条消息) 把一个数字分拆存到数组内(C/C++)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/128698111?spm=1001.2014.3001.5501
2.11 数字和字符串的互化
求不了子数字,但能求子字符串
例题:超级质数
(2条消息) 超级质数(蓝桥杯C/C++算法赛)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/128723978?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128723978%22%2C%22source%22%3A%22m0_71934846%22%7D
2.12 排序
(4条消息) 找字符串中最大字符(三种快速方法)_求字符串中最大的字符_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/128457227?spm=1001.2014.3001.5501
2.13 冒泡排序法和二分查找法(最常用)
冒泡排序法和二分查找法(C/C++)_菜只因C的博客-CSDN博客冒泡排序法和二分查找法(C/C++)https://blog.csdn.net/m0_71934846/article/details/128757285?spm=1001.2014.3001.5502
2.14 图论
图论(入门版)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/128757672?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_71934846/article/details/128979920?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128979920%22%2C%22source%22%3A%22m0_71934846%22%7Dhttps://blog.csdn.net/m0_71934846/article/details/128979920?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128979920%22%2C%22source%22%3A%22m0_71934846%22%7D
2.15 常用树的模板
蓝桥杯常用树模板(C/C++)_菜只因C的博客-CSDN博客蓝桥杯常用树模板(C/C++)https://blog.csdn.net/m0_71934846/article/details/128764616?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128764616%22%2C%22source%22%3A%22m0_71934846%22%7D
2.16 快速幂算法
快速幂算法(C/C++)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/128772642?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128772642%22%2C%22source%22%3A%22m0_71934846%22%7D
2.17 质因数算法
质因数算法(C/C++)_菜只因C的博客-CSDN博客质因数算法(C/C++)https://blog.csdn.net/m0_71934846/article/details/129732458?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22129732458%22%2C%22source%22%3A%22m0_71934846%22%7D
2.18 递归
是指函数/过程/子程序在运行过程序中直接或间接调用自身而产生的重入现象。
在计算机编程里,递归指的是一个过程:函数不断引用自身,直到引用的对象已知。
使用递归解决问题,思路清晰,代码少。但是在主流高级语言中(如C语言、Pascal语言等)使用递归算法要耗用更多的栈空间,所以在堆栈尺寸受限制时(如嵌入式系统或者内核态编程),应避免采用。所有的递归算法都可以改写成与之等价的非递归算法。
递归的重点是找到递归表达式
例1:阶乘
#include <bits/stdc++.h>
using namespace std;
int f(int n)
{
if(n==1)
{
return 1;
}
return n*f(n-1);
}
int main()
{
cout<<f(10);
return 0;
}
例2:汉诺塔
汉诺塔+汉诺四塔(C/C++)_菜只因C的博客-CSDN博客汉诺塔(C/C++)https://blog.csdn.net/m0_71934846/article/details/128796546?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128796546%22%2C%22source%22%3A%22m0_71934846%22%7D
例3:斐波那契数列
(3条消息) 斐波那契数列(C/C++)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/129676902?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22129676902%22%2C%22source%22%3A%22m0_71934846%22%7D
2.19 STL
(2条消息) STL使用方法(C++)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/128843820?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128843820%22%2C%22source%22%3A%22m0_71934846%22%7D
2.20 尺取法
(6条消息) 尺取法(C/C++)_菜只因C的博客-CSDN博客https://blog.csdn.net/m0_71934846/article/details/128908113?spm=1001.2014.3001.5502
2.21 倍增法(ST算法)(以后更新)
快速查找某区间内的最大值
2.22 KMP算法
找子串的最快方法
KMP算法模板(C/C++)_菜只因C的博客-CSDN博客KMP算法模板(C/C++)https://blog.csdn.net/m0_71934846/article/details/128914941?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128914941%22%2C%22source%22%3A%22m0_71934846%22%7D
2.23 LIS算法和LCS算法
最长上升子序列+最长公共子序列
https://blog.csdn.net/m0_71934846/article/details/128887981?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128887981%22%2C%22source%22%3A%22m0_71934846%22%7Dhttps://blog.csdn.net/m0_71934846/article/details/128887981?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128887981%22%2C%22source%22%3A%22m0_71934846%22%7D
2.24 树状数组
https://blog.csdn.net/m0_71934846/article/details/128925432?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128925432%22%2C%22source%22%3A%22m0_71934846%22%7Dhttps://blog.csdn.net/m0_71934846/article/details/128925432?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128925432%22%2C%22source%22%3A%22m0_71934846%22%7D
2.25 二分法
https://blog.csdn.net/m0_71934846/article/details/129054635?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22129054635%22%2C%22source%22%3A%22m0_71934846%22%7Dhttps://blog.csdn.net/m0_71934846/article/details/129054635?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22129054635%22%2C%22source%22%3A%22m0_71934846%22%7D
3 C语言容易出错的问题
几个C语言容易忽略的问题_菜只因C的博客-CSDN博客几个C语言容易忽略的问题https://blog.csdn.net/m0_71934846/article/details/129242180?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22129242180%22%2C%22source%22%3A%22m0_71934846%22%7D



























 2653
2653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











