






import os
import requests
安装Python并添加到环境变量,pip安装需要的相关模块即可。


百度搜索YY,点击分类选择小视频,里面的小姐姐自拍的短视频就是我们所需要的数据了。

网站是下滑网页之后加载数据,在上篇关于好看视频的爬取文章中已经有说明,YY视频也是换汤不换药。

如图所示,所框选的url地址,就是短视频的播放地址了。

数据包接口地址:
https://api-tinyvideo-web.yy.com/home/tinyvideosv2?callback=jQuery112409962628943012035_1613628479734&appId=svwebpc&sign=&data=%7B%22uid%22%3A0%2C%22page%22%3A1%2C%22pageSize%22%3A10%7D&_=1613628479736
第二页的数据请求参数:
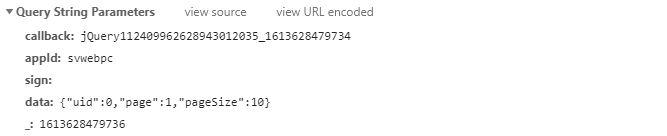
第三页的数据请求参数:
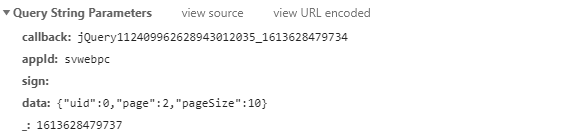
很明显这是根据data参数中的page改变翻页的。
构建翻页循环,获取视频url地址以及发布人的名字,保存到本地。
1、请求数据接口
import requests
url = ‘https://api-tinyvideo-web.yy.com/home/tinyvideosv2’
params = {
‘callback’: ‘jQuery112409962628943012035_1613628479734’,
‘appId’: ‘svwebpc’,
‘sign’: ‘’,
‘data’: ‘{“uid”:0,“page”:0,“pageSize”:10}’,
‘_’: ‘1613628479737’,
}
headers = {
‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36’
}
response = requests.get(url=url, params=params, headers=headers)
问题来了,返回的数据是json数据嘛?

如上图所示,很多人看到这样的数据肯定就觉得这不就是一个json数据嘛?

JSONDecodeError: json解码错误,它并不是有一个json数据,而是字符串。

通过response查看就知道了,返回给我们的数据是多了一段 jQuery112409962628943012035_1613628479734()
其中的json数据是包含在里面的,如果想要提取数据有三种方法。
1、返回response.text,使用正则表达式提取url地址以及发布人的名字
video_url = re.findall(‘“resurl”:“(.*?)”’, response.text)
user_name = re.findall(‘“username”:“(.*?)”’, response.text)

2、返回response.text,使用正则表达式提取 jQuery112409962628943012035_1613628479734() 中的数据,然后通过json模块把字符串转成json数据,然后遍历提取数据。
string = re.findall(‘jQuery112409962628943012035_1613628479734((.*?))’, response.text)[0]
json_data = json.loads(string)
result = json_data[‘data’][‘data’]
pprint.pprint(result)

3、把请求的url地址中的 callback 删掉,可以直接获取json数据
import pprint
import requests
url = ‘https://api-tinyvideo-web.yy.com/home/tinyvideosv2’
params = {
‘appId’: ‘svwebpc’,
‘sign’: ‘’,
‘data’: ‘{“uid”:0,“page”:1,“pageSize”:10}’,
‘_’: ‘1613628479737’,
}
headers = {
‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36’
}
response = requests.get(url=url, params=params, headers=headers)
json_data = response.json()
result = json_data[‘data’][‘data’]
pprint.pprint(result)
2、保存数据
for index in result:
video_url = index[‘resurl’]
user_name = index[‘username’]
video_content = requests.get(url=video_url, headers=headers).content
with open(‘video\’ + user_name + ‘.mp4’, mode=‘wb’) as f:
f.write(video_content)
print(user_name)
注意点: 用户名有特殊字符,保存的时候会报错


所以需要使用正则表达式替换掉特殊字符
def change_title(title):
pattern = re.compile(r"[/\😗?“<>|]”) # ‘/ \ : * ? " < > |’
new_title = re.sub(pattern, “_”, title) # 替换为下划线
return new_title
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1618
1618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









