







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
分析r返回的文本信息
发现验证码的标签的资源地址为 src=“CheckCode.aspx” ,我们可以直接requests然后下载验证码图片,下载图片的一种优雅的方式如下
def \_\_get\_code(self):request = requests.get(self.\_\_real\_base\_url + 'CheckCode.aspx', headers=self.\_\_headers)with open('code.jpg', 'wb')as f:f.write(request.content)im = Image.open('code.jpg')im.show()print('Please input the code:')code = input()return code
上面的代码把图片保存为code.jpg,Python有一个Image模块,可以实现自动打开图片
这样验证码就展示出来了,我们人工输入或者转入打码平台皆可
登录数据的构造
这是上面抓的登录post的数据包,
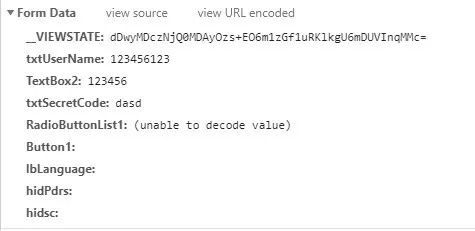
发现有信息无法被解码,应该是gb2312编码,查看解码前的编码
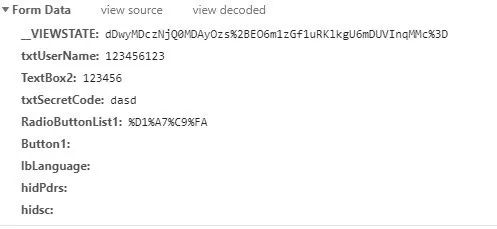
然后将不能解码的代码复制能够解码的地方
发现%D1%A7%C9%FA编码解码后为学生
这也就对应了学生选项的登录
学号和密码和验证码能够显而易见地知道是哪些信息,但是我们发现有__VIEWSTATE这一项
查找一下,这是一个表单隐藏信息,我们可以用BeautifulSoup库解析可以得出该一项数据的值

这是完整的登录数据包,
def \_\_get\_login\_data(self, uid, password):self.\_\_uid = uidrequest = self.\_\_set\_real\_url()soup = BeautifulSoup(request.text, 'lxml')form\_tag = soup.find('input')\_\_VIEWSTATE = form\_tag['value']code = self.\_\_get\_code()data = {'\_\_VIEWSTATE': \_\_VIEWSTATE,'txtUserName': self.\_\_uid,'TextBox2': password,'txtSecretCode': code,'RadioButtonList1': '学生'.encode('gb2312'),'Button1': '','lbLanguage': '','hidPdrs': '','hidsc': '',}return data
登录
如果登录完成了,如何判断是否登录成功呢?我们从登录成功返回的界面发现有姓名这一标签,而我们等一下也是需要学生姓名,所以我们用这个根据来判断是否登录成功。
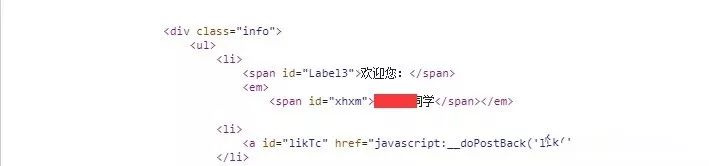
代码如下,进行了验证码用户名和密码的提示信息判别
def login(self,uid,password):while True:data = self.\_\_get\_login\_data(uid, password)request = requests.post(self.\_\_real\_base\_url + 'default2.aspx', headers=self.\_\_headers, data=data)soup = BeautifulSoup(request.text, 'lxml')try:name\_tag = soup.find(id='xhxm')self.\_\_name = name\_tag.string[:len(name\_tag.string) - 2]print('欢迎'+self.\_\_name)except:print('Unknown Error,try to login again.')time.sleep(0.5)continuefinally:return True
获取选课信息
接下来就是获取选课信息了,这里我们以校公选课为例子,点击进去,进行抓包,headers没有什么好注意的,我们只用关注get发送的包即可
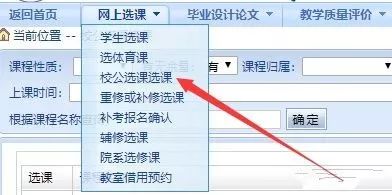

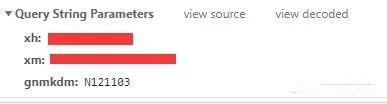
发现有学号与姓名与gnmkdm这一项,姓名我们需要编码为gb2312的形式才能进行传送
这里我们注意headers需要新增Referer项也就是当前访问的网址,才能进行请求
def \_\_enter\_lessons\_first(self):data = {'xh': self.\_\_uid,'xm': self.\_\_name.encode('gb2312'),'gnmkdm': 'N121103',}self.\_\_headers['Referer'] = self.\_\_real\_base\_url + 'xs\_main.aspx?xh=' + self.\_\_uidrequest = requests.get(self.\_\_real\_base\_url + 'xf\_xsqxxxk.aspx', params=data, headers=self.\_\_headers)self.\_\_headers['Referer'] = request.urlsoup = BeautifulSoup(request.text, 'lxml')self.\_\_set\_\_VIEWSTATE(soup)
注意到上面有一个设置VIEWSTATE值的函数,这里等下在选课构造数据包的时候会讲
模拟选课
随便选一门课,然后提交,抓包,看一下有什么数据发送


前三个值可以在原网页中input标签中找到,由于前两项为空,就不获取了,而第三项我们使用soup解析获取即可,由于这个操作是每请求一次就变化的,我们写成一个函数,每次请求完成就设置一次。
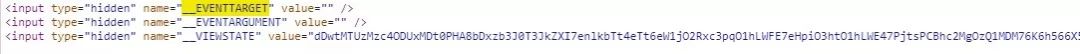
def \_\_set\_\_VIEWSTATE(self, soup):\_\_VIEWSTATE\_tag = soup.find('input', attrs={'name': '\_\_VIEWSTATE'})self.\_\_base\_data['\_\_VIEWSTATE'] = \_\_VIEWSTATE\_tag['value']
而其他数据,我们通过搜索响应网页就可以知道他们是干什么用的,这里我只说明我们要用的数据。
TextBox1为搜索框数据,我们可以用这个来搜索课程,dpkcmcGrid:txtPageSize为一页显示多少数据,经过测试,服务器最多响应200条。
值得注意的是ddl_xqbs这个校区数据信息,我所在的校区的数字代号为2,也许不同学校设置有所不同,需要自己设置一下,也可以从网页中获取
下面是基础数据包,由于我们搜索课程与选择课程都要使用这个基础数据包,所以我们直接在init函数里面新增
self.\_\_base\_data = {'\_\_EVENTTARGET': '','\_\_EVENTARGUMENT': '','\_\_VIEWSTATE': '','ddl\_kcxz': '','ddl\_ywyl': '','ddl\_kcgs': '','ddl\_xqbs': '2','ddl\_sksj': '','TextBox1': '','dpkcmcGrid:txtChoosePage': '1','dpkcmcGrid:txtPageSize': '200',}
然后我们关注一下这条数据,我们搜索一下,发现这是课程的提交选课的代码,所以我们也可以直接从网页中获取,而on表示选项被选上

kcmcGrid:\_ctl2:xk:'on'
搜索课程
课程有很多信息,比如名字,上课时间,地点,这些东西确定好了才知道选的是哪门课,所以我们先新建一个类来存储信息
class Lesson:def \_\_init\_\_(self, name, code, teacher\_name, Time, number):self.name = nameself.code = codeself.teacher\_name = teacher\_nameself.time = Timeself.number = numberdef show(self):print('name:' + self.name + 'code:' + self.code + 'teacher\_name:' + self.teacher\_name + 'time:' + self.time)
有了这个类,我们就可以进行搜索课程了,具体代码看下面代码,解析网页内容就不细讲了。
def \_\_search\_lessons(self, lesson\_name=''):self.\_\_base\_data['TextBox1'] = lesson\_name.encode('gb2312')request = requests.post(self.\_\_headers['Referer'], data=self.\_\_base\_data, headers=self.\_\_headers)soup = BeautifulSoup(request.text, 'lxml')self.\_\_set\_\_VIEWSTATE(soup)return self.\_\_get\_lessons(soup)def \_\_get\_lessons(self, soup):lesson\_list = []lessons\_tag = soup.find('table', id='kcmcGrid')lesson\_tag\_list = lessons\_tag.find\_all('tr')[1:]for lesson\_tag in lesson\_tag\_list:td\_list = lesson\_tag.find\_all('td')code = td\_list[0].input['name']name = td\_list[1].stringteacher\_name = td\_list[3].stringTime = td\_list[4]['title']number = td\_list[10].stringlesson = self.Lesson(name, code, teacher\_name, Time, number)lesson\_list.append(lesson)return lesson\_list
进行选课
选课我们只要将lesson_list传入即可,这就是我们之前创建的Lesson类的实例的列表,‘Button’的内容为’ 提交 ',这两边各有一个空格,完事后我们可以进行发送请求进行选课。
这里我们用正则提取了错误信息,比如选课时间未到、上课时间冲突这些错误信息来提示用户,我们还解析了网页的已选课程,这里也不细讲了,都是基础的网页解析。
def \_\_select\_lesson(self, lesson\_list):data = copy.deepcopy(self.\_\_base\_data)data['Button1'] = ' 提交 '.encode('gb2312')for lesson in lesson\_list:code = lesson.codedata[code] = 'on'request = requests.post(self.\_\_headers['Referer'], data=data, headers=self.\_\_headers)soup = BeautifulSoup(request.text, 'lxml')self.\_\_set\_\_VIEWSTATE(soup)error\_tag = soup.html.head.scriptif not error\_tag is None:error\_tag\_text = error\_tag.stringr = "alert\('(.+?)'\);"
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









