






文章目录
全链接神经网络是各层之间的神经元每个都链接在一些,这样一来就会出现一个问题,那就是当我们的输出层神经元很多的时候,链接就会很多,参数的维度就会很高。比如说,假设我们有一个足够充分的照片数据集,数据集中是拥有标注的照片,每张照片具有百万级像素,这意味着网络的每次输入都有一百万个维度。 即使将隐藏层维度降低到1000,这个全连接层也将有 1 0 6 × 1 0 3 10^6 \times 10^3 106×103个参数。 想要训练这个模型将不可实现,因为需要有大量的GPU、分布式优化训练的经验和超乎常人的耐心。
一、空间不变性和局部性
- 平移不变性(translation invariance):不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”。想象一下,假设你想从一张图片中找到某个物体。 合理的假设是:无论哪种方法找到这个物体,都应该和物体的位置无关。 卷积神经网络正是将空间不变性(spatial invariance)的这一概念系统化,从而基于这个模型使用较少的参数来学习有用的表示。
- 局部性(locality):神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则。最终,可以聚合这些局部特征,以在整个图像级别进行预测。
二、边界检测——一个小例子感受卷积
假设现在我们有如下一张单通道的图片:

我们想要检测出这张图片的边界(也就是1和0的分界线)。我们应该怎么做呢?
我们可以设计一个滤波器(filter,也叫kernel),大小为
2
×
2
2 \times 2
2×2:

然后我们用这个kernel覆盖在图片上,从左上角开始,和图片进行运算,得到一个数值。然后挪动这个“小方块”,直到图片上所有的位置都进行了计算。这个过程就叫“卷积”。我们在挪动这个小方块的时候可以选择不同的移动距离,这里我们叫步长。比如说我们的步长是1,那么我们每次计算完就移动一格。这样我们可以得到如下的一个新的数据阵:

可以看到,这个新的数据阵在除了分界线处全都是0,也就是说我们找到了这个图片里的边界。
从上面这个例子中,我们发现,我们可以通过设计特定的kernel,让它去跟图片做卷积,就可以识别出图片中的某些特征,比如边界。 上面的例子是检测竖直边界,我们也可以设计出检测水平边界的,只用把刚刚的kernel旋转90°即可。对于其他的特征,理论上只要我们经过精细的设计,总是可以设计出合适的filter的。
那么问题来了,对于图像问题要提取的特征肯定有各种各样的kernel,我们怎么可能全都一个一个的人为给定呢?首先,我们都不一定清楚对于一大推图片,我们需要识别哪些特征,其次,就算知道了有哪些特征,想真的去设计出对应的kernel,恐怕也并非易事,要知道,特征的数量可能是成千上万的。
其实这些kernel,根本就不用我们去设计,每个kernelr中的各个数字,不就是参数吗,我们可以通过大量的数据,来让机器自己去“学习”这些参数,这就是CNN的原理。
三、CNN里的一些概念
1. padding
从上面的例子可以看出来,做过卷积之后原本 6 × 6 6 \times 6 6×6 的图片变成了 5 × 5 5 \times 5 5×5,丢失了边缘的像素。那么如果我们做的卷积次数较多的话,边缘信息就是丢失的比较多。如果我们想要卷积后的图片大小和之前一样的话我们就需要在卷积前做padding,也就是把需要做卷积的图片先补充上会丢失的行列数。
2. stride 步长
有时候我们的图片很大,如果一步一步的做卷积速度可能会没那么快,并且信息也有部分重叠。这时候我们可以调整步长,每次卷积之后可以选择移动3个单位,这样卷积之后的图片 大小也会变小。
3. pooling 池化
池化的作用也可以减小参数的个数。就是我们在每次做卷积之后,将得到的图片分割,只提取每一块中最重要的信息(现在最常用的应该是Max Pooling,就是取区域里最大的那个值)。如下图(图片来源已带有水印)所示:

除了Max Pooling,还有Average Pooling,顾名思义就是取那个区域的平均值。
4. 多通道卷积
彩色的图片在计算机里有RGB三个通道,可以理解为一个立方体,对多通道问题进行卷积,也需要具有相同通道数的卷积核。比如说我们现在有一张 8 ∗ 8 ∗ 3 8*8*3 8∗8∗3 的图片,我们就需要用一个 3 ∗ 3 ∗ 3 3*3*3 3∗3∗3 的卷积核去做卷积,得到的就是一个 6 ∗ 6 ∗ 1 6*6*1 6∗6∗1 的输出。如果我们用4个这样的卷积核的话,得到的输出就会有4个通道。如下图所示:

(这张图是从知乎一个大佬那里借来的,我感觉这张图片已经展示的很清晰了。)
5. 1x1卷积层
1x1的卷积层就是卷积核是一个1x1的,这个卷积核失去了卷积层的特有能力——在高度和宽度维度上,识别相邻元素间相互作用的能力,其实卷积的唯一计算发生在通道上。

如图所示,通过 1x1 的卷积层使得输出与输入具有相同的长和宽,但是通道数由 3 变成了 2。
6. 感受野
简单来说感受野就是卷积神经网络(CNN)中每层的卷积特征图(feature map)上的像素点在原始图像中映射的区域大小,也就相当于高层的特征图中的像素点受原图多大区域的影响。

Way1 对应为通常的一种理解感受野的方式。在左侧的上半张图中,是在 5x5 的图像(蓝色)上做一个 3x3 卷积核的卷积计算操作,步长为2,padding 为1,所以输出为 3x3 的特征图(绿色)。那么该特征图上的每个特征(1x1)对应的感受野,就是 3x3。在左侧的下半张图中,是在上述基础上再做了一次完全一样的卷积。对于经过第二层卷积后其上的一个特征(如红色圈)在上一层特征图上“感受”到 3x3 大小,该 3x3 大小的每个特征再映射回到图像上,就会发现由 7x7 个像素点与之关联,有所贡献。于是,就可以说第二层卷积后的特征其感受野大小是 7x7。
Way2 的理解方式其实更具有一般性,我们可以无需考虑输入图像的大小对感受野进行计算。如下图:

虽然,图上绘制了输入 9x9 的图像(蓝色),但是它的大小情况是无关紧要的,因为我们现在只关注某“无限”大小图像某一像素点为中心的一块区域进行卷积操作。首先,经过一个 3x3 的卷积层(padding=1,stride=2)后,可以得到特征输出(深绿色)部分。其中深绿色的特征分别表示卷积核扫过输入图像时,卷积核中心点所在的相对位置。此时,每个深绿色特征的感受野是 3x3 (浅绿)。这很好理解,每一个绿色特征值的贡献来源是其周围一个 3x3 面积。再叠加一个 3x3 的卷积层(padding=1,stride=2)后,输出得到 3x3 的特征输出(橙色)。此时的中心点的感受野所对应的是黄色区域 7x7,代表的是输入图像在中心点橙色特征所做的贡献。
四、一个完整的卷积神经网络
CNN的整体结构,它包含了3种层(layer):
1.Convolutional layer(卷积层–CONV)
由卷积核和激活函数构成。 一般要设置的超参数包括kernel的数量、大小、步长,以及padding是“valid”还是“same”。当然,还包括选择什么激活函数。
2.Pooling layer (池化层–POOL)
这里里面没有参数需要我们学习,因为这里里面的参数都是我们设置好了,要么是Maxpooling,要么是Averagepooling。 需要指定的超参数,包括是Max还是average,窗口大小以及步长。 通常,我们使用的比较多的是Maxpooling,而且一般取大小为(2,2)步长为2的filter,这样,经过pooling之后,输入的长宽都会缩小2倍,channels不变。
3. Fully Connected layer(全连接层–FC)
这个就是我们之前学的神经网络中的全连接层, 这里要指定的超参数,无非就是神经元的数量,以及激活函数。
所以用图示可以表示成如下的结构:
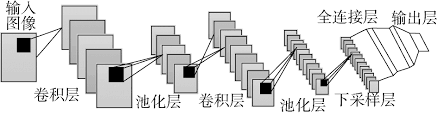
可以从图中看到,随着网络的深入,我们的“图像”(严格来说中间的那些不能叫图像了)越来越小,但是channels越来越多了。
五、一些经典的CNN模型
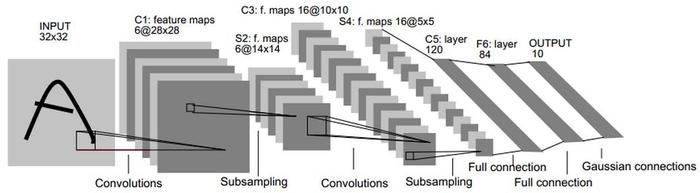
1. LeNet
2. AlexNet

3. VGG

4. ResNet
5. GoogLeNet
一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,深度指网络层次数量、宽度指神经元数量。但这种方式存在以下问题:
(1)参数太多,如果训练数据集有限,很容易产生过拟合;
(2)网络越大、参数越多,计算复杂度越大,难以应用;
(3)网络越深,容易出现梯度弥散问题(梯度越往后穿越容易消失),难以优化模型。
所以,有人调侃“深度学习”其实是“深度调参”。
解决这些问题的方法当然就是在增加网络深度和宽度的同时减少参数,为了减少参数,自然就想到将全连接变成稀疏连接。但是在实现上,全连接变成稀疏连接后实际计算量并不会有质的提升,因为大部分硬件是针对密集矩阵计算优化的,稀疏矩阵虽然数据量少,但是计算所消耗的时间却很难减少。
那么,有没有一种方法既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,就如人类的大脑是可以看做是神经元的重复堆积,因此,GoogLeNet团队提出了Inception网络结构,就是构造一种“基础神经元”结构,来搭建一个稀疏性、高计算性能的网络结构。然后给予 Inception 网络结构,构建出了GoogleNet。
















 1519
1519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









