







数据结构_LinkedList链表
前言:
- 此类笔记仅用于个人复习,内容主要在于记录和体现个人理解,详细还请结合bite课件、录播、板书和代码。
- 宁愿多花精力在做提前进行分析,也不想做错了再进行调试
- 形参是实参的拷贝,形参的改变不影响实参。若在函数重要影响实参,就要传实参的地址作为形参,再通过解引用地址来影响实参 <要改变谁,就传谁的地址><比如函数中想改变实参int类型的变量,就要传它的地址int*;要改变int *,就要传二级指针int **>
- 第三条👆非常非常重要,理解了的话在链表这里就能绕明白了,在指针方面的理解也算是比较到位了
为什么要使用链表(顺序表的局限性)
顺序表的优点:
连续物理空间,方便通过下标随机访问
缺点:
- 插入数据,空间不足时需要扩容,扩容有性能消耗
- 头部或中间位置插入或删除数据,需要挪动其他数据,效率较低
- 可能存在一定的空间占用,浪费空间;不能按需申请和释放空间
基于顺序表的局限性,就设计出了链表
链表
链表的概念
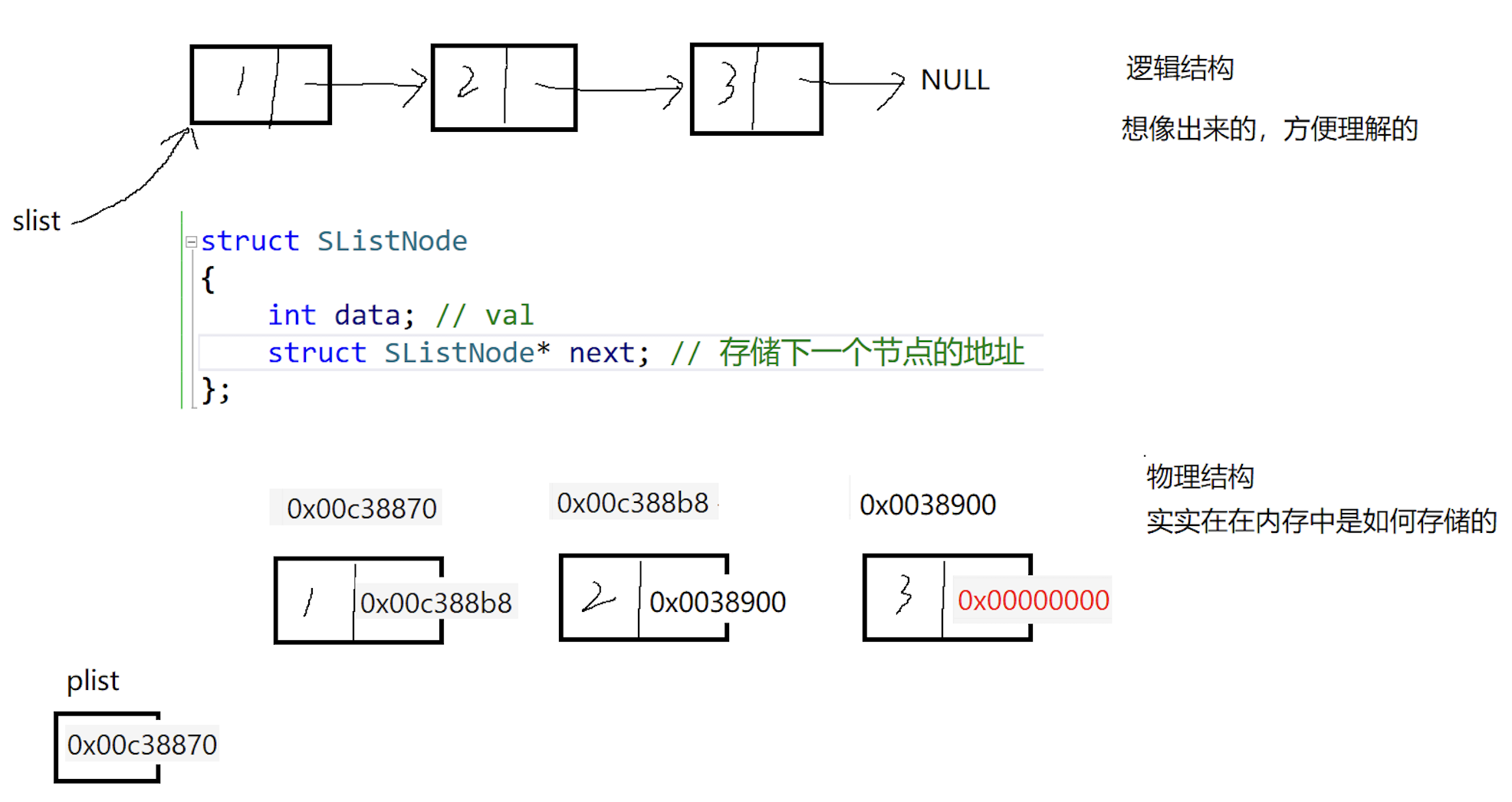
链表是一种在物理存储结构上非顺序非连续的存储结构,数据元素的逻辑结构是通过链表中的指针链接实现的


链表的基本结构:
- 存储的数据元素
- 链表结构体指针(指向下一个链表的节点<或称结点>或NULL)
节点/结点:在数据结构中,每一个数据节点/结点对应一个存储单元,节点/结点就是存储单元的地址(比如在链表里,结点就是链表结构体的地址)
注意:
- 从上图中可以看出,链式结构在逻辑上一定是连续的,但在物理(存储)上不一定是连续的
- 现实中的结点一般都是从堆上申请出来的
- 从堆上申请的空间,都是按照一定的策略进行分配的,两次申请的空间可能连续,可能不连续

链表的分类
- 单向或双向
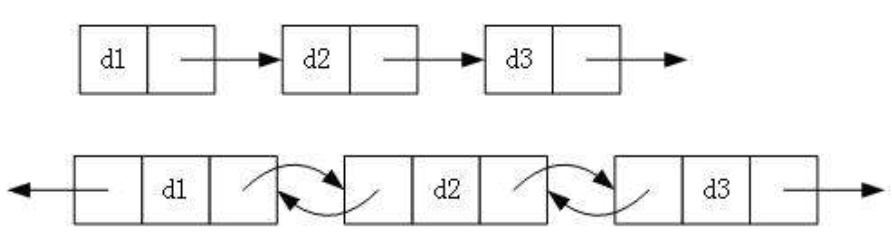
- 带头或不带头
- 循环或非循环
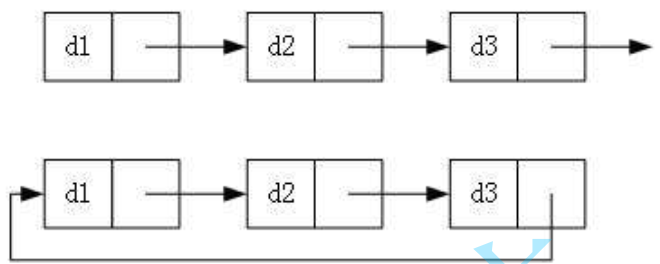
最常见的两种结构:
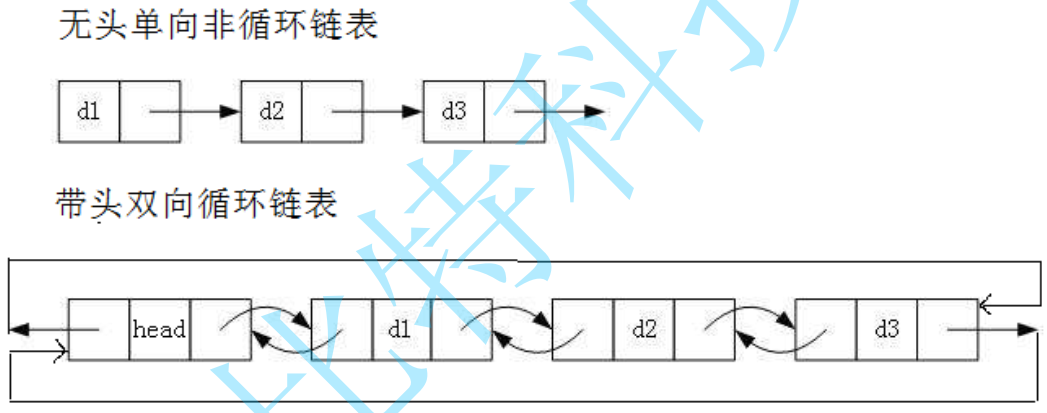
- 无头单向非循环链表:结构比较简单,一般不会单独用来存储数据用。更多情况下是作为其他数据结构的子结构,比如哈希桶、图的邻接表等。另外这种结构在面试题中出现的概率比较高。
- 带头双向循环链表:结构最复杂,一般用来单独存储数据用。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而比较简单了,后面我们代码实现了就知道了。
单链表的实现
因为本人太懒了所以不想再写一遍了,此处放上我写的用C++实现的带头单向不循环链表
链表OJ
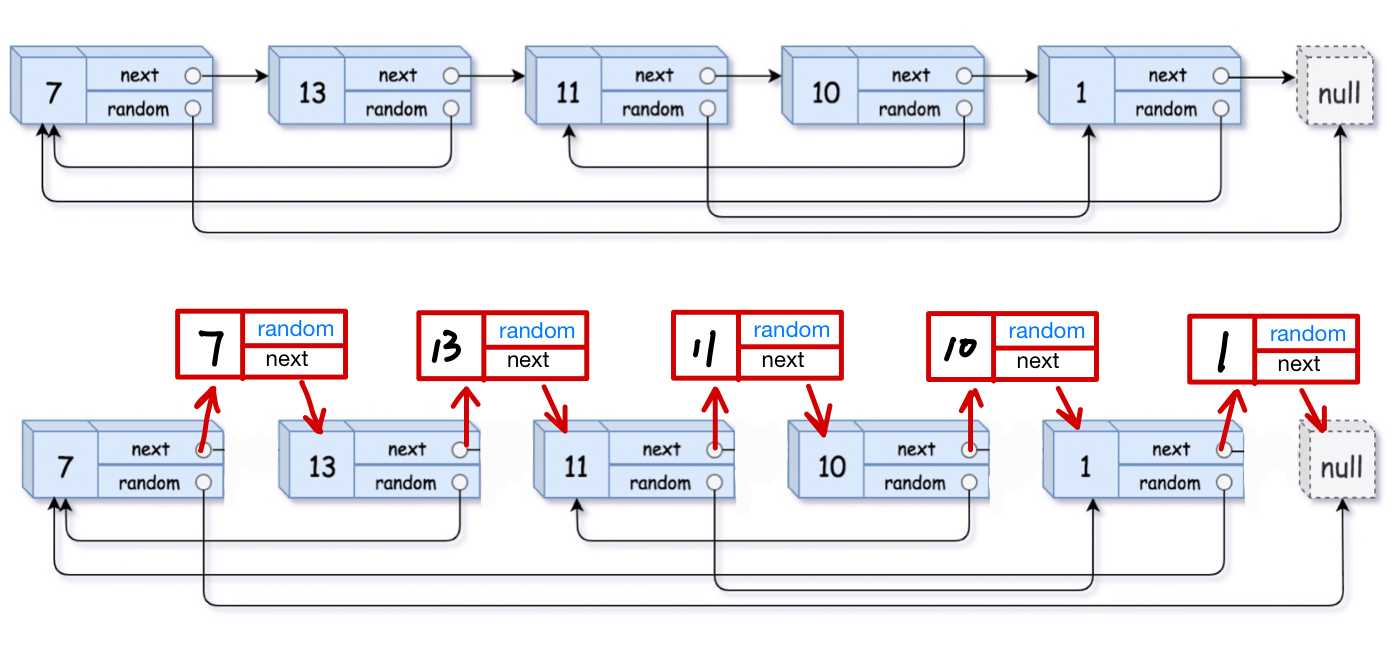
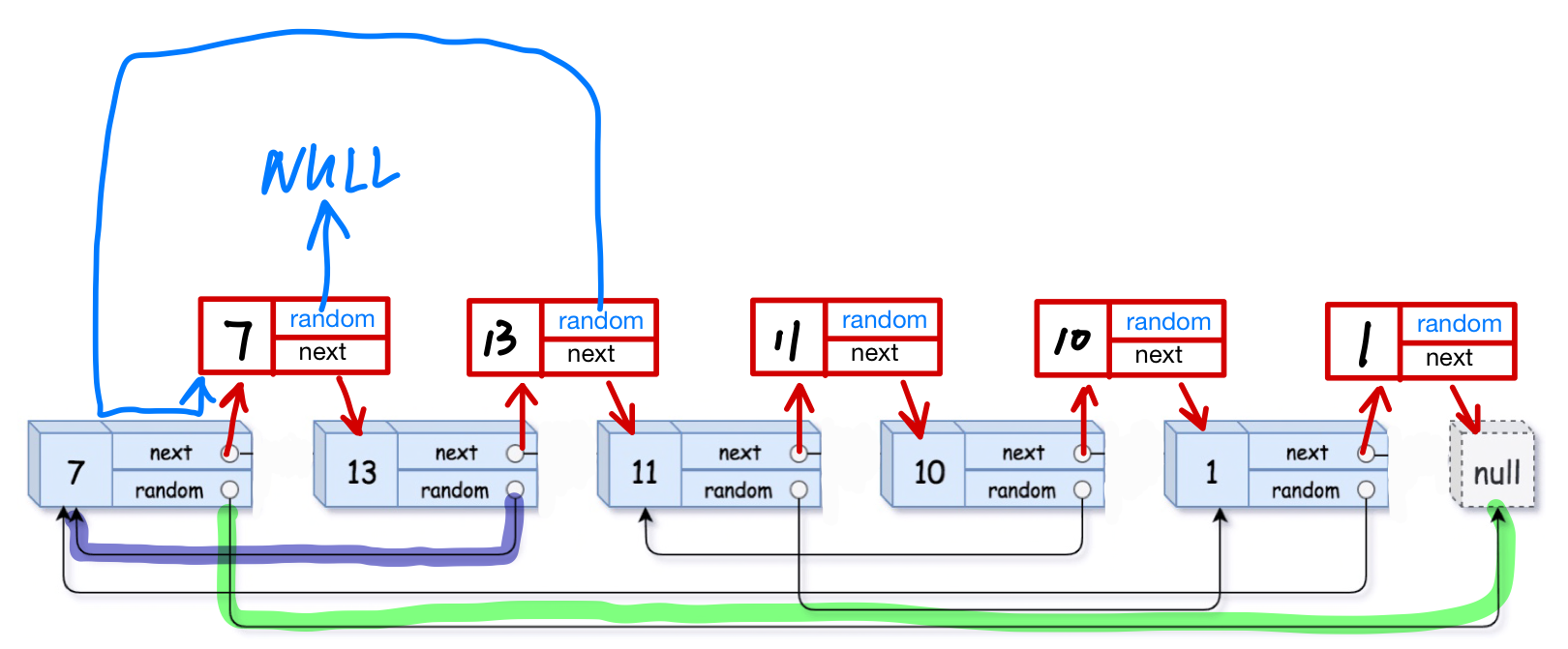
复制一个新的链表,除了要求存储的数据data与原链表一致,还要求链表内每个结点的random指向的相对位置不变
由于链表的结点都是malloc出来的,因此每个结点的地址都是随机的,只能通过相对关系来找到random指向的结点
思路一:
遍历原链表第一遍,创建一个新链表,把data数据复制过去
再用一个指针遍历一遍原链表,每到达一个结点A记录下它在链表中的位置,并跳转到random指向的结点B,再由另一个结点从链表头开始,直到走到random跳转之后的结点,记录下来结点B在链表位置,这样就可以得到结点A和它的random指向的结点B的相对位置关系。再在新链表中根据关系令random指向相应的结点。
最后返回新链表
缺点:过程太繁琐
于是就有了,思路二:
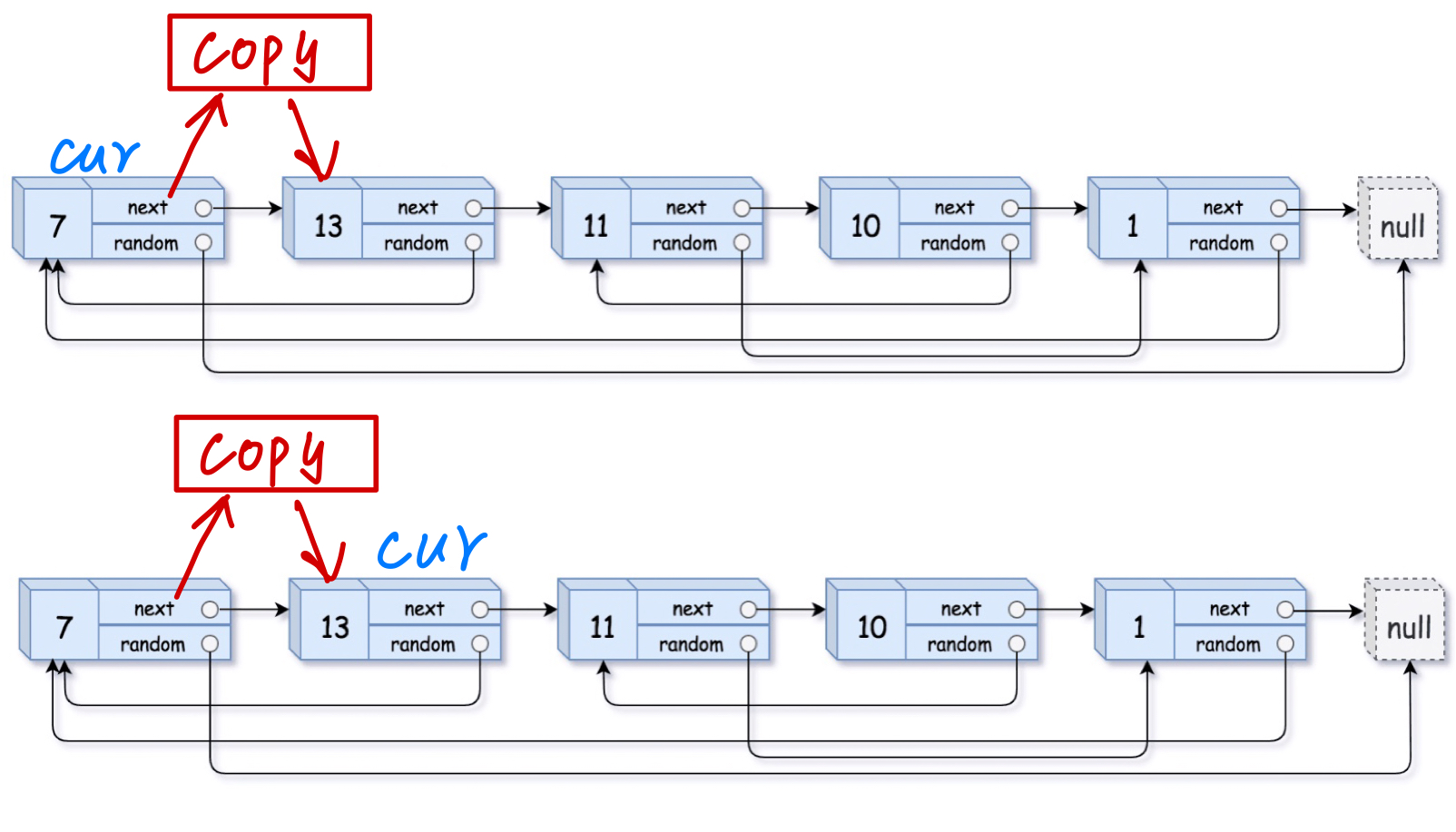
直接在原来链表的基础上创建复制结点,每个复制结点就在原结点后面,然后把下一个原结点连接在复制结点后面
创造拷贝结点,链接到原链表原结点的后面,并复制val的值
方法一:定义一个cur用来遍历原链表,定义一个copy指针用作拷贝
让copy=cur->next , cur->next=copy, cur= copy->next
struct Node *cur = head; while(cur) { struct Node *copy = (struct Node *)malloc(sizeof(struct Node)); copy->val = cur->val; copy->next = cur->next; cur->next = copy; cur = copy->next; }注意这里是对于链表进行的拷贝,而不是简单的进行链表的链接,因此需要构造新的结点再进行拷贝
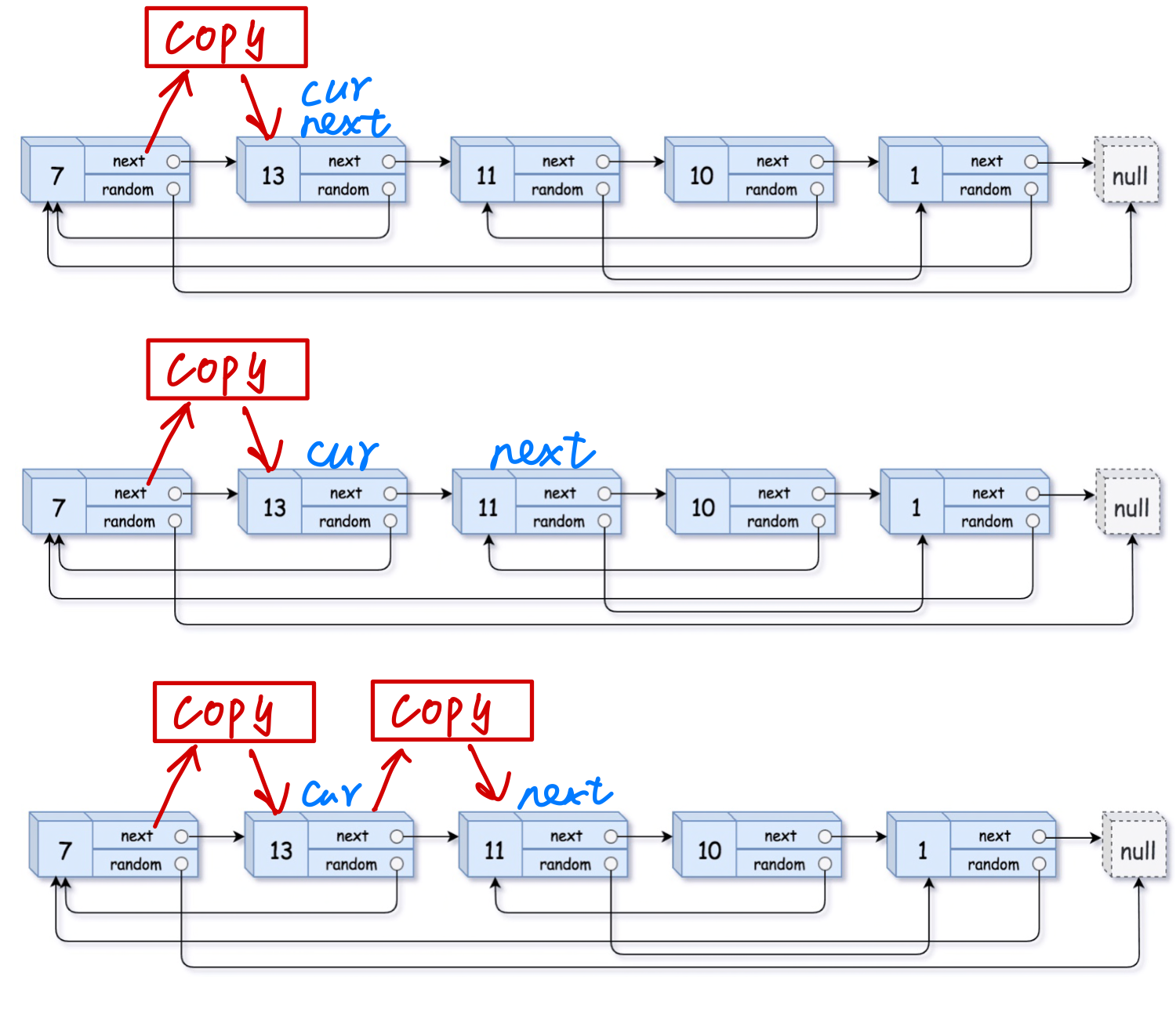
方法二:定义一个cur用来遍历原链表,一个next来找cur的next,一个copy用作拷贝
有了next就不用在乎拷贝顺序了
next=cur->next, cur-> next=copy, copy->next= next
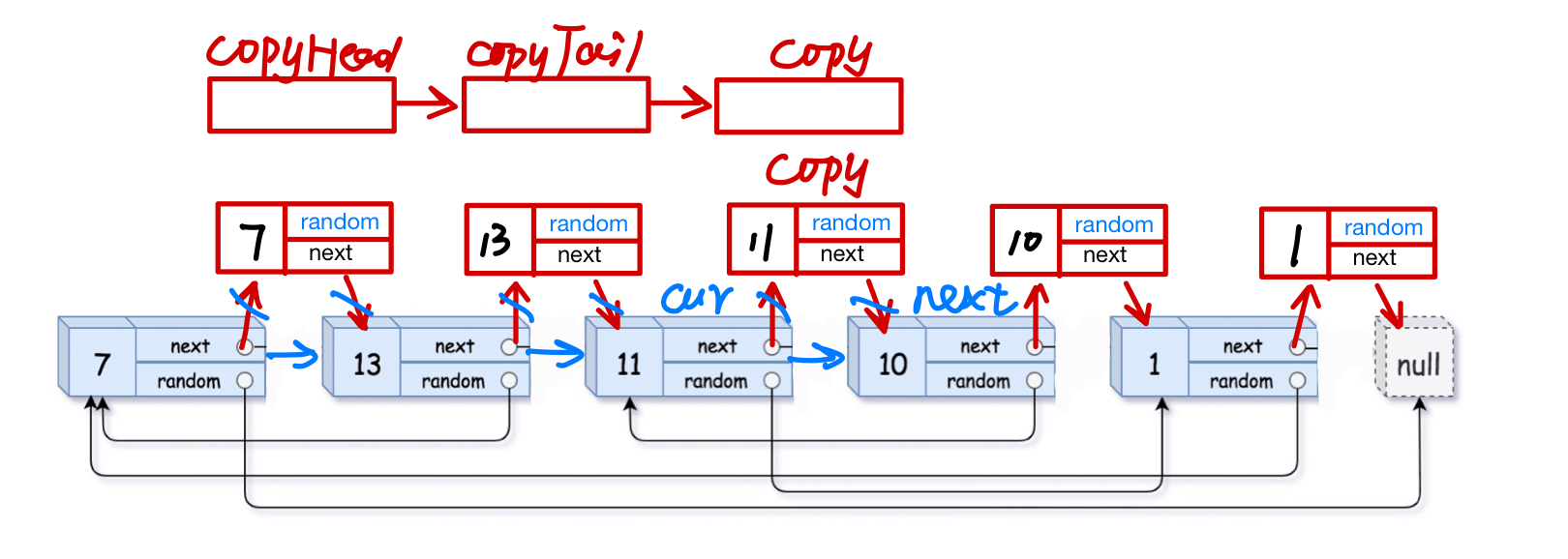
链接拷贝结点的random
copy->random指向前面cur->random->next
以为cur->random的后一个就是它的copy,这样直接就找到了相对位置的copy
如果cur->random指向NULL,copy->random直接指向NULL
struct Node *copy = NULL; cur = head; while(cur) { copy = cur->next; if(cur->random == NULL) { copy->random = NULL; } else { copy->random = cur->random->next; } cur = copy->next; }把copy从原链表中解下来,形成复制链表,把原链表连回去
创建拷贝链表的头指针copyHead还有尾指针copyTail
尾指针是为了尾插结点,头指针是为了定位
创建一个next指针便于再原链表上辅助copy和cur移动
copy将值赋给拷贝链表,cur负责连接原链表
cur = head; struct Node *copyHead = NULL; struct Node *copyTail = NULL; while(cur) { struct Node *copy = cur->next; struct Node *next = copy->next; cur->next = next; if(copyTail == NULL) { copyHead = copyTail = copy; } else { copyTail->next = copy; copyTail = copyTail->next; } cur = next; } return copyHead;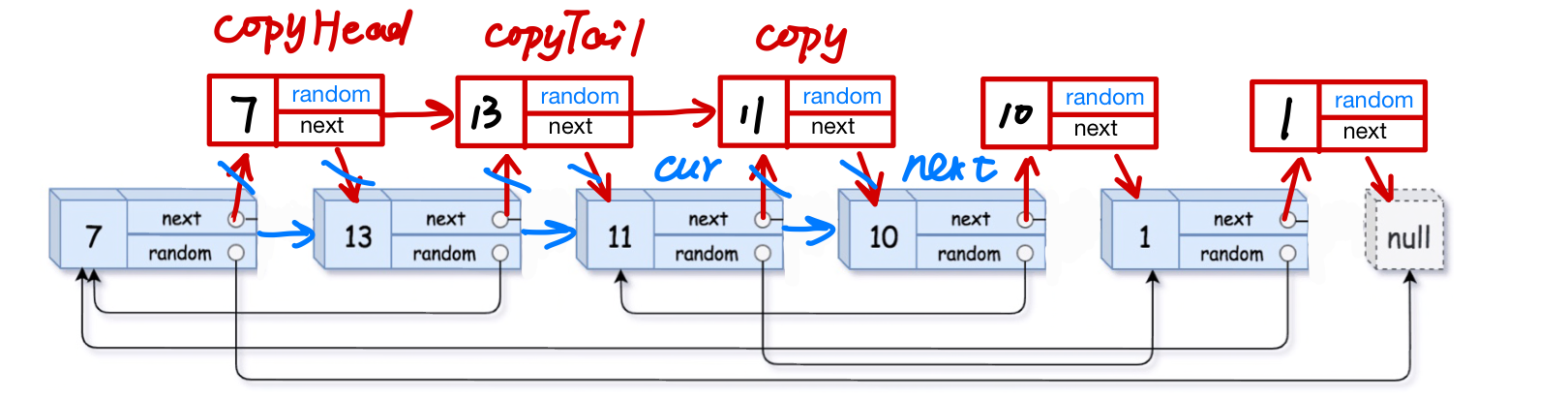
可以看成构建新的链表
//源代码 struct Node* copyRandomList(struct Node* head) { struct Node *cur = head; //创造拷贝结点,链接到原链表的结点后面,并复制val的值 while(cur) { struct Node *copy = (struct Node *)malloc(sizeof(struct Node)); copy->val = cur->val; copy->next = cur->next; cur->next = copy; cur = copy->next; } //连接拷贝结点的random struct Node *copy = NULL; cur = head; while(cur) { copy = cur->next; if(cur->random == NULL) { copy->random = NULL; } else { copy->random = cur->random->next; } cur = cur->next->next; } //把copy从原链表中解下来,形成复制链表,把原链表连回去 cur = head; struct Node *copyHead = NULL; struct Node *copyTail = NULL; while(cur) { struct Node *copy = cur->next; struct Node *next = copy->next; cur->next = next; if(copyTail == NULL) { copyHead = copyTail = copy; } else { copyTail->next = copy; copyTail = copyTail->next; } cur = next; } return copyHead; }
结束
That’s all, thanks for reading!💐















 3339
3339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









