







5. 查询语句执行流程
执行 SQL 语句 select * from user where id = 1 时发生了什么
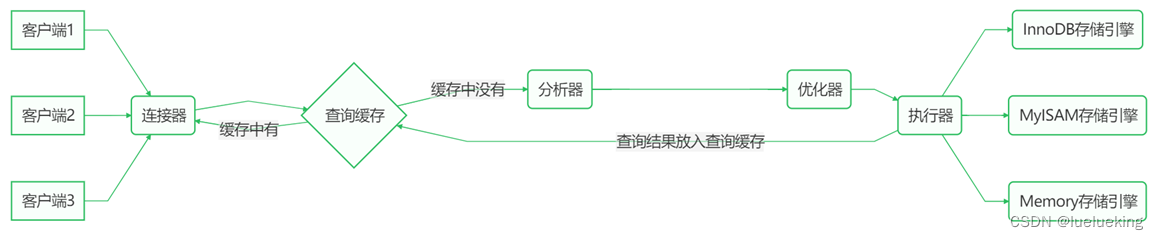
连接器:负责建立连接、检查权限、连接超时时间由 wait_timeout 控制,默认 8 小时
查询缓存:会将 SQL 和查询结果以键值对方式进行缓存,修改操作会以表单位导致缓存失效
分析器:词法、语法分析
优化器:决定用哪个索引,决定表的连接顺序等
执行器:根据存储引擎类型,调用存储引擎接口
存储引擎:数据的读写接口,索引、表都在此层实现
6. undo log 与 redo log
undo log
-
回滚数据,以行为单位,记录数据每次的变更,一行记录有多个版本并存
-
多版本并发控制,即快照读(也称为一致性读),让查询操作可以去访问历史版本
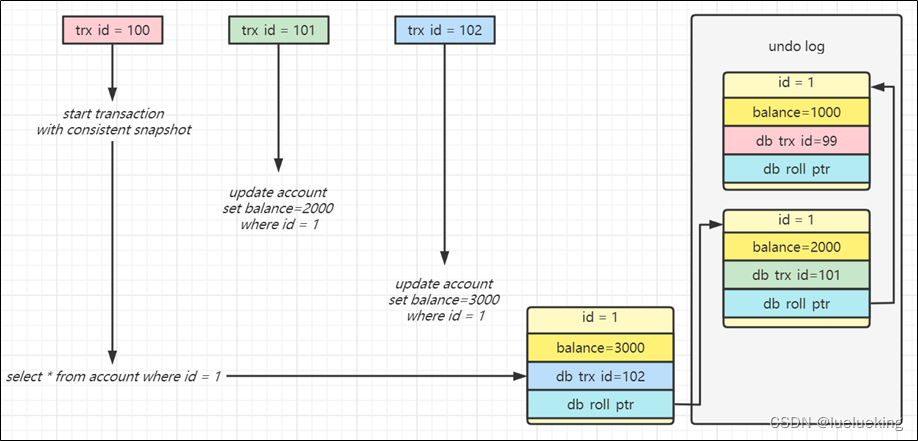
◽️每个事务会按照开始时间,分配一个单调递增的事务编号 trx id
◽️每次事务的改动都会以行为单位记入回滚日志,包括当时的事务编号,改动的值等
◽️查询操作,事务编号大于自己的数据是不可见的,事务编号小于等于自己的数据才是可见的
▫️例如图中红色事务看不到 trx id=102 以及 trx id=101 的数据,只有 trx id=99 的数据对它可见
redo log
redo log 的作用主要是实现 ACID 中的持久性,保证提交的数据不丢失
◽️它记录了事务提交的变更操作,服务器意外宕机重启时,利用 redo log 进行回放,重新执行已提交的变更操作
◽️事务提交时,首先将变更写入 redo log,事务就视为成功。至于数据页(表、索引)上的变更,可以放在后面慢慢做
- 数据页上的变更宕机丢失也没事,因为 redo log 里已经记录了
- 数据页在磁盘上位置随机,写入速度慢,redo log 的写入是顺序的速度快
它由两部分组成,内存中的 redo log buffer,磁盘上的 redo log file
◽️redo log file 由一组文件组成,当写满了会循环覆盖较旧的日志,这意味着不能无限依赖 redo log,更早的数据恢复需要 binlog
◽️buffer 和 file 两部分组成意味着,写入了文件才真正安全,同步策略由参数 innodb_flush_log_at_trx_commit 控制
-
-
0 - 每隔 1s 将日志 write and flush 到磁盘
-
1 - 每次事务提交将日志 write and flush(默认值)
-
2 - 每次事务提交将日志 write,每隔 1s flush 到磁盘,意味着 write 意味着写入操作系统缓存,如果 MySQL 挂了,而操作系统没挂,那么数据不会丢失
-
















 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











