






语音笔记未做整理
并发容器和框架

-
内置线程安全机制
Java 并发容器框架(如java.util.concurrent包)内置了线程安全控制逻辑(如锁机制、CAS 无锁算法等),无需开发者手动添加同步代码(如synchronized、ReentrantLock),即可保证多线程环境下的数据操作安全。 -
预定义线程安全数据结构
框架提供了多种线程安全的数据结构,例如:ConcurrentHashMap(线程安全的哈希表,支持高并发读写)CopyOnWriteArrayList(写时复制的列表,适用于读多写少场景)BlockingQueue(阻塞队列,支持多线程间安全通信)
通过调用这些容器的方法(如put、take、add等),可直接实现线程安全的操作。
-
简化开发流程
开发者无需关注底层锁的实现细节,直接使用框架提供的接口和类,降低了多线程编程的复杂度和出错概率。
ConcurrentHashMap *

ConcurrentHashMap 是 Java 中的一个线程安全的哈希表实现,它位于 java.util.concurrent 包下。与 HashTable 和同步包装后的 HashMap 相比,ConcurrentHashMap 在多线程环境下具有更高的性能和更好的并发访问特性。
1. HashMap 的底层结构
-
数据结构:
- 数组 + 链表(JDK 1.7 及以前):哈希冲突时,新节点采用头插法插入链表。
- 数组 + 链表 + 红黑树(JDK 1.8+):当链表长度超过 8 且数组长度≥64 时,链表转换为红黑树(提高查询效率至 O (logN)),新节点采用尾插法。
-
哈希冲突处理:
通过链地址法(Chaining)解决冲突,即多个元素映射到同一数组位置时,以链表 / 红黑树形式存储。
2. 线程不安全的表现
在并发场景下,HashMap可能出现:
- 数据覆盖:多线程同时执行
put操作时,若哈希冲突导致链表节点被覆盖,可能丢失数据。 - 死循环(环形链表)(JDK 1.7 及以前):
当多线程同时触发resize()扩容时,头插法可能导致链表节点的引用形成环形结构,导致get()操作陷入死循环。注意:JDK 1.8 改用尾插法,但
HashMap仍非线程安全,并发时可能丢失数据。
3. 版本差异对比
| 特性 | JDK 1.7 | JDK 1.8+ |
|---|---|---|
| 数据结构 | 数组 + 链表 | 数组 + 链表 + 红黑树 |
| 插入方式 | 头插法(扩容时可能逆序) | 尾插法(避免环形链表,但仍非线程安全) |
| 扩容条件 | 元素数量超过阈值(容量 × 负载因子) | 同上,但链表转红黑树需满足长度≥8 且数组长度≥64 |
4. 线程安全替代方案
若需在并发环境使用哈希表,建议选择:
- ConcurrentHashMap:
- JDK 1.7:分段锁(Segment),不同段可并发读写。
- JDK 1.8:CAS+ synchronized,锁粒度细化到数组节点,并发性能更高。
- Hashtable:
早期实现,通过synchronized修饰所有方法,效率较低,不推荐。
5. 常见面试问题
- HashMap 的底层原理:哈希表结构、哈希冲突处理、链表转红黑树条件。
- 为什么 HashMap 线程不安全:数据覆盖、环形链表(JDK 1.7)。
- ConcurrentHashMap 如何保证线程安全:分段锁(旧版)→ CAS+ synchronized(新版)。
- HashMap 与 Hashtable 的区别:线程安全性、空键支持、性能。
1. final 关键字与引用类型
- final 修饰引用类型:
引用变量的指向不可变,但对象内容可修改。
示例:final HashMap map = new HashMap(); map.put("key", "value"); // 合法:修改对象内容 map = new HashMap(); // 非法:不能改变引用指向
2. HashMap 在并发场景的死循环问题
- 问题根源:
多线程同时触发resize()扩容时,可能导致链表节点的引用形成环形结构(JDK 1.7 头插法下尤为严重),造成get()操作死循环。 - 触发条件:
多线程并发写入,且 HashMap 需扩容(默认负载因子 0.75,数组长度超过阈值时触发)。 - JDK 1.8 改进:
改用尾插法,但仍未解决数据覆盖问题,HashMap 在并发场景仍不安全。
3. 分段锁(Segment)技术(ConcurrentHashMap 旧版实现)
- 结构:
将整个哈希表分成多个独立的段(Segment),每个段相当于一个小 HashMap,段之间可并发读写。 - 锁粒度:
锁的范围从整个哈希表缩小到单个 Segment,并发性能显著提升。 - 缺点:
不支持跨段操作(如 size () 需锁定所有段),且结构复杂,JDK 1.8 后被弃用。
4. 哈希(散列)的概念
- 定义:
将任意长度的输入通过哈希函数转换为固定长度的输出(哈希值),用于数据分组或快速查找。 - 示例:
- 简单散列:对连续编号取模(如
id % 4),分组均匀但缺乏随机性。 - 理想散列:对随机唯一 ID 取模(如
UUID.randomUUID().hashCode() % 4),分组概率上接近均匀。
- 简单散列:对连续编号取模(如
- 应用:
HashMap 通过哈希值确定元素在数组中的位置,冲突时用链表 / 红黑树存储。
5. 面试高频问题
-
HashMap 为什么线程不安全?
- 多线程写入可能导致数据覆盖;
- 扩容时可能形成环形链表(JDK 1.7)。
-
ConcurrentHashMap 如何优化锁机制?
- JDK 1.7:分段锁(Segment);
- JDK 1.8:CAS+ synchronized(锁粒度细化到数组节点)。
-
哈希散列的原理与应用
- 原理:通过哈希函数将数据均匀分布;
- 应用:负载均衡、数据分片、HashMap 寻址。
- 多线程扩容的时候会发生死循环
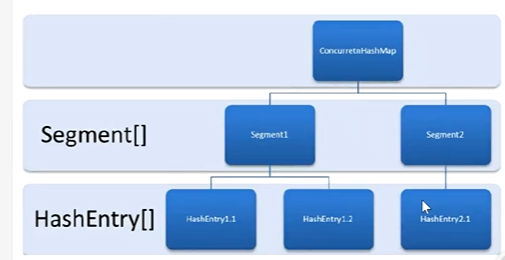
JDK 1.7 ConcurrentHashMap 分段锁结构总结
1. 核心结构(结合类图)
ConcurrentHashMap 在 JDK 1.7 中采用 “二维数组 + 分段锁” 设计:
- 顶层:
ConcurrentHashMap容器。 - 中层:
Segment[]数组(分段),每个Segment是一个独立的 “小 HashMap”,内部自带锁(继承ReentrantLock)。 - 底层:每个
Segment内部包含HashEntry[]数组,HashEntry通过 链表 处理哈希冲突(类似 JDK 1.7HashMap的结构)。
2. 分段锁的工作原理
- 锁的粒度:每个
Segment独立加锁。当线程操作某个Segment时,仅锁定该Segment,其他Segment可被并发访问。- 例如:线程 A 写
Segment1,线程 B 读Segment2,二者互不阻塞。
- 例如:线程 A 写
- 哈希定位:键的哈希值先决定归属哪个
Segment(通过hash % Segment数量),再在该Segment内定位HashEntry数组的位置。
3. 设计的核心意义
- 解决并发性能瓶颈:
对比Hashtable的 全局锁(全表互斥,并发度低),ConcurrentHashMap通过 分段锁 将锁竞争范围缩小到单个Segment,大幅提升多线程读写效率。 - 空间换时间:
用Segment数组的额外空间,换取更高的并发能力(本质是 “分而治之” 的思想)。
4. 局限性与进化(对比 JDK 1.8)
- 局限性:
Segment数量固定(默认 16),若数据哈希不均(如大量键落到同一Segment),会导致该Segment成为锁竞争热点。- 跨段操作(如
size()需遍历所有Segment并加锁)效率较低。
- JDK 1.8 的改进:
取消Segment,直接用Node[]数组存储数据,锁粒度细化到 数组节点(通过CAS + synchronized实现),进一步提升并发性能,同时支持链表转红黑树优化查询。
5. 面试高频考点
-
问:JDK 1.7 和 JDK 1.8 的
ConcurrentHashMap有何区别?
答:维度 JDK 1.7 JDK 1.8 结构 Segment[] + HashEntry[]Node[] + 链表/红黑树锁机制 分段锁( Segment级)节点级锁( CAS + synchronized)并发效率 受 Segment数量限制更细粒度,并发能力更强 -
问:分段锁的优缺点是什么?
答:- 优点:降低锁竞争,提升多线程并发能力;
- 缺点:
Segment数量固定,极端场景仍有锁竞争;跨段操作(如统计大小)开销高。
散列--哈希--hash
1. 哈希散列的基本定义
- 核心目标:将任意数据(如键值对、用户 ID)通过哈希函数映射到固定范围的索引或分组中,实现高效的存储与查找。
- 本质:一种数据分组技术,通过数学算法将数据 “均匀分布” 到不同区域。
2. 示例解析:全国人口分组
场景一:连续编号(理想均匀分布)
- 操作:对全国 14 亿人从 1 到 14 亿连续编号,然后对 4 取模(
id % 4)。 - 结果:余数 0、1、2、3 的人数几乎相等(最多相差 1),分组绝对均匀。
- 特点:数据本身有序,分组结果可控,但现实中很少适用(如用户 ID 通常非连续)。
场景二:随机编号(实际应用场景)
- 操作:为每个人分配唯一随机数(如 UUID),再对 4 取模。
- 结果:余数 0、1、2、3 的人数可能不同,但根据大数定律,长期来看各组数量趋近平均。
- 特点:原始数据无序,但通过哈希函数实现了概率上的均匀分布。
3. 哈希散列的核心特性
- 确定性:相同输入始终生成相同哈希值(如
hash("key")永远返回固定值)。 - 均匀性:理想情况下,哈希值应均匀分布,减少冲突(不同输入映射到同一位置的情况)。
- 高效性:哈希计算时间复杂度为 O (1),确保快速定位数据。
4. 在 HashMap/ConcurrentHashMap 中的应用
定位流程
- 计算哈希值:对键(Key)计算哈希码(如
key.hashCode())。 - 二次哈希:通过扰动函数(如 JDK 1.8 的
(h ^ (h >>> 16)))减少哈希冲突。 - 取模定位:将哈希值对数组长度取模(如
hash % table.length),确定元素在数组中的位置。
冲突处理
- 链表法:多个键映射到同一位置时,用链表 / 红黑树存储(JDK 1.8 中链表长度≥8 且数组长度≥64 时转换为红黑树)。
- 扩容机制:当元素数量超过阈值(容量 × 负载因子)时,数组扩容并重新哈希,保持负载均衡。
5. 面试高频问题
-
为什么哈希函数需要 “均匀分布”?
- 答:不均匀分布会导致大量冲突,使链表 / 红黑树过长,降低查询效率(从 O (1) 退化为 O (n) 或 O (logn))。
-
HashMap 如何解决哈希冲突?
- 答:链地址法(链表 + 红黑树)+ 扩容机制。
-
扰动函数的作用是什么?
- 答:让哈希码的高位也参与运算,减少低位冲突的概率(如 JDK 1.8 通过
h ^ (h >>> 16)将高位与低位异或)。
- 答:让哈希码的高位也参与运算,减少低位冲突的概率(如 JDK 1.8 通过
哈希(散列)在 HashMap 中的 “分组→定位” 闭环逻辑,核心总结如下:
1. 哈希的核心使命:给 “无规律数据” 建立可定位的分组
- 问题背景:现实中,数据(如字符串键、对象)本身无规律,无法直接排序或分类。
- 哈希的作用:
通过 哈希函数 对无规律数据进行 “数学转换”,生成固定范围的哈希值,将数据映射到不同 “分组”(如 HashMap 的数组槽位)。
同时,相同数据必然生成相同哈希值,保证后续能反向定位到同一分组。
2. HashMap 中 “分组→定位” 的闭环流程
以 HashMap 存储和查询数据为例,哈希的作用贯穿始终:
① 存储时:分组(散列写入)
- 对键(Key)计算哈希值(如
key.hashCode()+ 扰动函数优化)。 - 通过哈希值对数组长度取模,确定数据应存入 哪个数组槽位(分组)。
- 若槽位已有数据(哈希冲突),则以链表 / 红黑树形式追加存储。
② 查询时:定位(散列读取)
- 对查询的键,使用相同哈希函数 计算哈希值。
- 同样取模定位到数组槽位,遍历该槽位的链表 / 红黑树,找到对应键值对。
3. 哈希闭环的关键保障
- 确定性:相同键必然生成相同哈希值 → 保证 “存” 和 “取” 定位到同一分组。
- 均匀性:哈希值尽可能均匀分布 → 减少冲突,避免某一分组数据过多(否则查询退化为链表遍历,效率下降)。
4. 类比理解(呼应 “人口分组” 案例)
| 场景 | 哈希逻辑映射 | 核心共性 |
|---|---|---|
| 人口分组(存) | 随机 ID → 取模 → 分组(如余数 0-3) | 无规律数据 → 哈希函数 → 分组 |
| 人口查找(取) | 已知 ID → 同样取模 → 找到对应分组 | 相同数据 → 同样规则 → 定位 |
| HashMap 存 / 取 | 键 → 哈希 → 数组槽位 → 链表 / 红黑树 | 完全复刻 “分组→定位” 逻辑 |
哈希的本质是 “给无规律数据建立可逆向追踪的分组规则”,而 HashMap 正是通过这一规则,实现了理论上 O (1) 级别的增删改查效率。理解 “存和取必须用同一套哈希规则”,是掌握哈希表设计的关键。
ConcurrentHashMap 及并发容器核心总结
一、ConcurrentHashMap 的使用与线程安全
-
API 兼容与便捷性:
用法和HashMap完全一致(get()读取、put()写入),但 内置线程安全机制,多线程场景下直接调用,无需手动加锁。 -
锁机制细节:
- 读(
get):多数情况 无锁访问(直接读节点),仅当读到null(并发写导致数据未及时可见)时,才加锁重读,平衡性能与正确性。 - 写(
put):JDK 1.8 后采用 节点级细粒度锁(synchronized修饰节点),JDK 1.7 是分段锁,确保写操作原子性,避免数据冲突。
- 读(
二、并发容器的整体特性(java.util.concurrent 包)
-
线程安全 “开箱即用”:
该包下的容器(如ConcurrentLinkedQueue、CopyOnWriteArrayList等)全部内置同步逻辑:- 多线程调用
add()、poll()、get()等方法时,内部通过 锁、CAS、写时复制 等机制保证安全。 - 开发者无需编写
synchronized或ReentrantLock代码,直接复用即可。
- 多线程调用
-
典型场景示例:
- ConcurrentLinkedQueue:链表实现的队列,多线程入队(
offer)、出队(poll)安全,内部用 CAS 优化并发。 - CopyOnWriteArrayList:读多写少场景优化,写操作复制数组(无锁读,写时加锁),避免读锁竞争。
- ConcurrentLinkedQueue:链表实现的队列,多线程入队(
三、与普通容器的对比
| 维度 | 普通容器(如 HashMap、ArrayList) | 并发容器(java.util.concurrent 包) |
|---|---|---|
| 线程安全 | 非线程安全,多线程需手动同步 | 线程安全,内部已实现同步 |
| 使用难度 | 简单,但并发场景易因锁逻辑出错 | 与普通容器用法一致,无额外学习成本 |
| 性能优化 | 无并发优化(如 Hashtable 全局锁性能差) | 细粒度锁(如 ConcurrentHashMap 节点锁)、无锁设计,并发性能更高 |
四、学习与面试重点
-
ConcurrentHashMap 核心考点:
- 对外:用法和
HashMap一致,线程安全; - 对内:JDK 1.7 分段锁、JDK 1.8 节点锁的进化,理解 “锁粒度细化提升并发” 的设计思路。
- 对外:用法和
-
并发容器选型逻辑:
根据场景选工具(如高并发哈希用ConcurrentHashMap,读多写少用CopyOnWriteArrayList),利用框架封装的线程安全能力,减少开发复杂度。
线程池核心设计:有界队列 vs 无界队列 + 线程复用逻辑总结
一、线程池的诞生背景:解决线程 “频繁创建 / 销毁” 的损耗
- 问题:
手动创建线程时,每次任务都要new Thread()(创建栈、分配资源)和销毁(释放资源),耗时且占 CPU。 - 线程池的解法:
预先维护一批 长期存活的线程(核心线程),任务来了直接分配给线程处理,处理完不销毁,继续等新任务 → 避免重复创建 / 销毁的开销。
二、线程 “长期存活” 的矛盾:CPU 损耗 vs 响应速度
- 矛盾点:
线程长期存活(如核心线程)会持续占用 CPU 时间片(即使空闲),若核心线程数太多,空线程会拖垮系统性能。 - 平衡策略:
- 核心线程数(最小线程数):设为少量(如 CPU 核心数),保证常态下低 CPU 损耗,且响应快(无需新建线程)。
- 最大线程数:当任务积压时临时扩容,任务处理完后收缩回核心数 → 应对突发高负载。
三、任务队列的关键作用:有界 vs 无界
线程池通过 任务队列缓存待处理任务,队列特性直接决定线程池的扩容逻辑:
| 队列类型 | 核心行为 | 对 “最大线程数” 的影响 | 场景缺陷 |
|---|---|---|---|
无界队列(如 LinkedBlockingQueue 无界版) | 任务无限堆积,队列永远不会满 | 无法触发最大线程数扩容(一直用核心线程处理) | 任务积压严重时,响应延迟爆炸(用户等很久) |
有界队列(如 ArrayBlockingQueue 或指定容量的 LinkedBlockingQueue) | 队列满时,新任务无法入队 | 触发最大线程数扩容(临时新建线程处理任务) | 队列满时需处理 “任务拒绝”(需配合拒绝策略) |
四、为什么 “多数场景选有界队列”?
- 控制任务积压:
无界队列会让任务无限堆积,最终内存溢出(OOM),且核心线程忙不过来,响应极慢。 - 触发最大线程数的价值:
有界队列满时,临时扩容到最大线程数,短时间内集中处理积压任务,避免用户长时间等待。 - 资源可控性:
有界队列通过容量限制,强制开发者思考 “任务积压到多少时扩容 / 拒绝”,避免系统雪崩。
五、线程池工作流程(结合队列和线程数)
- 任务提交 → 先入队。
- 队列未满 → 核心线程处理,或入队等待。
- 队列满 → 触发最大线程数扩容(新建线程处理任务)。
- 最大线程数也满 → 执行拒绝策略(如抛异常、丢弃任务等)。
核心结论:
线程池的设计是 “用少量核心线程保响应,用有界队列控积压,用最大线程数应对突发” 的平衡术。无界队列看似 “安全”,实则隐藏任务积压风险;有界队列虽需处理拒绝策略,但能强制系统在可控范围内工作,是生产环境的首选。
线程池提交任务:execute vs submit 核心区别(面试高频考点)
1. 所属接口与方法签名
| 方法 | 所属类 / 接口 | 参数类型 | 返回值 |
|---|---|---|---|
execute() | ThreadPoolExecutor(继承自 Executor) | Runnable | void |
submit() | ExecutorService(Executor 子接口) | Runnable 或 Callable | Future<T>(封装结果或异常) |
关键差异:
execute是基础接口Executor的核心方法,仅支持无返回值的Runnable。submit是扩展接口ExecutorService的方法,支持Runnable和Callable(有返回值)。
2. 返回值与结果处理
-
execute(Runnable):
无返回值,任务执行结果无法通过方法获取。若需感知任务状态,需手动在Runnable中添加回调逻辑(如设置标志位)。 -
submit(Runnable/Callable):
返回Future<T>对象,可通过以下方式获取结果:Future<?> future = executor.submit(() -> { /* 任务逻辑 */ }); // 方式1:阻塞获取结果(可能抛出 InterruptedException/ExecutionException) Object result = future.get(); // 方式2:异步回调(JDK 8+ CompletableFuture) future.thenAccept(result -> System.out.println("处理结果:" + result));- 若提交的是
Runnable,Future.get()返回null(无结果)。 - 若提交的是
Callable,Future.get()返回任务的返回值。
- 若提交的是
3. 异常处理机制
-
execute(Runnable):
任务内未捕获的异常会直接抛出到调用线程(或由线程池的UncaughtExceptionHandler处理),典型表现为控制台打印堆栈:executor.execute(() -> { throw new RuntimeException("任务异常"); // 直接抛到控制台 }); -
submit(Runnable/Callable):
任务内未捕获的异常会被封装为Future的ExecutionException,需通过future.get()显式处理:Future<?> future = executor.submit(() -> { throw new RuntimeException("任务异常"); }); try { future.get(); // 抛出 ExecutionException,内部包裹原始异常 } catch (InterruptedException e) { Thread.currentThread().interrupt(); } catch (ExecutionException e) { Throwable cause = e.getCause(); // 获取原始异常 System.out.println("任务异常:" + cause); }
4. 适用场景对比
| 场景 | 推荐方法 | 原因 |
|---|---|---|
| 简单异步任务(无返回值) | execute() | 轻量,无需处理 Future,代码简洁。 |
| 异步任务需返回值 | submit(Callable) | 必须用 Callable 封装任务,并通过 Future 获取结果。 |
| 异步任务需异常处理 | submit() | 异常封装在 Future 中,便于统一管理,避免污染调用线程。 |
5. 面试经典问题
问:execute 和 submit 有什么区别?
答:
- 接口层级:
execute属于Executor基础接口,submit属于ExecutorService扩展接口。 - 参数与返回值:
execute仅接受Runnable,无返回值;submit可接受Runnable/Callable,返回Future用于获取结果或异常。
- 异常处理:
execute的未捕获异常直接抛出;submit的异常封装在Future中,需显式处理。
问:提交 Runnable 任务时,选 execute 还是 submit?
答:
- 若无需感知任务状态,选
execute(简单高效); - 若需处理任务异常或获取执行状态(如
isDone()、cancel()),选submit(返回Future提供更多控制)。
fork/join框架 任务拆分,拆分到多个线程下下去执行,执行完之后呢,就进行合并。
一、原子类(Atomic)
1. 核心作用
- 解决多线程环境下基本数据类型(如
int、long)的原子性操作问题,避免竞态条件。 - 示例:
AtomicInteger替代普通int,确保i++等操作线程安全。
2. 底层原理:CAS(Compare-And-Swap)
- 操作逻辑:
每次操作前先检查当前值是否等于预期值(expect),若相等则更新为新值(update),否则重试。public final int addAndGet(int delta) { return unsafe.getAndAddInt(this, valueOffset, delta) + delta; } - 特点:
- 无锁(Lock-Free),适合低并发场景(竞争线程少,CAS 重试成本低)。
- 不适合高并发:竞争激烈时 CAS 失败率高,频繁重试浪费 CPU(如 1000 个线程竞争,仅 1 个成功,其余 999 次重试无效)。
3. 使用注意
- 必须通过原子类提供的方法(如
incrementAndGet())操作,直接使用+等运算符无法保证原子性。 - 常见子类:
AtomicLong、AtomicBoolean、AtomicReference(原子更新引用类型)。
二、CountDownLatch:线程等待计数器
1. 核心功能
- 允许一个或多个线程等待其他线程执行完成后再继续执行,通过计数器递减实现同步。
- 典型场景:
- 主线程等待所有子线程完成数据加载后,再进行汇总计算。
- 测试时等待所有线程到达就绪状态,再同时触发执行(避免线程启动顺序影响测试结果)。
2. 关键方法
CountDownLatch(int count):初始化计数器(如count=2表示需等待 2 个线程完成)。await():当前线程进入等待状态,直到计数器归零。countDown():线程执行完毕后调用,计数器减 1。
3. 示例逻辑
CountDownLatch latch = new CountDownLatch(2); // 需等待2个线程
// 子线程1
new Thread(() -> {
// 执行任务
latch.countDown(); // 任务完成,计数器减1
}).start();
// 子线程2
new Thread(() -> {
// 执行任务
latch.countDown(); // 计数器减至0
}).start();
latch.await(); // 主线程等待计数器归零后继续执行
System.out.println("所有子线程执行完毕");
4. 特点
- 一次性使用:计数器归零后无法重置,适合 “一次性” 同步场景。
三、CyclicBarrier:同步屏障(可循环使用)
1. 核心功能
- 让一组线程到达屏障点(Barrier)时相互等待,直到最后一个线程到达后,所有线程才一起继续执行。
- 典型场景:
- 多线程计算任务分阶段执行(如阶段 1 完成后,所有线程同步进入阶段 2)。
- 模拟 “起跑线” 效果:所有运动员就绪后,同时开始比赛。
2. 关键方法
CyclicBarrier(int parties):初始化屏障等待的线程数(如parties=2表示 2 个线程需到达屏障)。await():线程到达屏障点,调用此方法等待其他线程。CyclicBarrier(int parties, Runnable barrierAction):可选参数,所有线程到达后执行额外任务(如汇总结果)。
3. 示例逻辑
CyclicBarrier barrier = new CyclicBarrier(2); // 2个线程需到达屏障
// 线程A
new Thread(() -> {
try {
System.out.println("线程A到达屏障");
barrier.await(); // 等待线程B
System.out.println("线程A继续执行");
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}).start();
// 线程B
new Thread(() -> {
try {
System.out.println("线程B到达屏障");
barrier.await(); // 线程A和B同时唤醒
System.out.println("线程B继续执行");
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}).start();
4. 特点
- 可循环使用:计数器归零后自动重置,适合重复同步场景。
- 与
CountDownLatch的区别:维度 CountDownLatchCyclicBarrier线程角色 1 个等待线程 vs N 个任务线程 N 个线程相互等待 计数器方向 从 N 递减到 0(一次性) 从 0 递增到 N(可循环) 典型场景 等待任务完成(如加载数据) 多线程同步执行(如分阶段计算)
四、面试高频问题与开发建议
1. 面试点总结
- 原子类的线程安全如何实现?
答:通过 CAS 无锁机制,比较预期值与当前值,一致则更新,否则重试,适合低并发场景。 CountDownLatch和CyclicBarrier的区别?
答:前者是 “单向等待任务完成”,一次性使用;后者是 “多线程互相等待同步”,可循环使用。
2. 开发建议
- 低并发场景:优先使用原子类(
Atomic)或Synchronized,简单高效。 - 高并发场景:避免单纯依赖 CAS,考虑加锁(如
ReentrantLock)或线程池(ExecutorService)控制并发量。 - 同步需求:根据是否需要循环使用,选择
CountDownLatch(一次性)或CyclicBarrier(可循环)。 - 基础优先:理解工具类底层原理(如 CAS、等待 / 通知机制)比直接使用更重要,面试中常考原理而非 API 记忆。

















 7988
7988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









