






一、JDK1.8更新了什么?
- Lambda表达式
- 函数式接口
- 方法引用和构造器调用
- Stream API
- 接口中的默认方法和静态方法
- 新时间日期API
1.Lambda表达式
是一段可以传递的代码,减少代码量,优化匿名内部类的
//匿名内部类
Comparator<Integer> cpt = new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return Integer.compare(o1,o2);
}
};
TreeSet<Integer> set = new TreeSet<>(cpt);
System.out.println("=========================");
//使用lambda表达式
Comparator<Integer> cpt2 = (x,y) -> Integer.compare(x,y);
TreeSet<Integer> set2 = new TreeSet<>(cpt2);Lmabda表达式的语法总结: () -> ();
| 说明 | 语法 |
|---|---|
| 无参数无返回值 | () -> System.out.println(“Hello”) |
| 有一个参数无返回值 | (i) -> System.out.println(i) |
| 有且只有一个参数无返回值 | i -> System.out.println(i) |
| 有多个参数,有返回值,有多条lambda体语句 | (a,b) -> {System.out.println(“xxx”);return xxx;}; |
| 有多个参数,有返回值,只有一条lambda体语句 | (a,b) -> System.out.println(“xxx”);return xxx; |
口诀:左右遇一省括号,左侧推断类型省
2.函数式接口
只定义了一个抽象方法的接口,为了给Lambda表达式提供支持,还提供了注解@FunctionalInterface
常见的四大函数式接口
- Consumer 《T》:消费型接口,有参无返回值
@Test
public void test(){
changeStr("hello",(str) -> System.out.println(str));
}
/**
* Consumer<T> 消费型接口
* @param str
* @param con
*/
public void changeStr(String str, Consumer<String> con){
con.accept(str);
}- Supplier 《T》:供给型接口,无参有返回值
@Test
public void test2(){
String value = getValue(() -> "hello");
System.out.println(value);
}
/**
* Supplier<T> 供给型接口
* @param sup
* @return
*/
public String getValue(Supplier<String> sup){
return sup.get();
}- Function 《T,R》::函数式接口,有参有返回值
@Test
public void test3(){
Long result = changeNum(100L, (x) -> x + 200L);
System.out.println(result);
}
/**
* Function<T,R> 函数式接口
* @param num
* @param fun
* @return
*/
public Long changeNum(Long num, Function<Long, Long> fun){
return fun.apply(num);
}- Predicate《T》: 断言型接口,有参有返回值,返回值是boolean类型
public void test4(){
boolean result = changeBoolean("hello", (str) -> str.length() > 5);
System.out.println(result);
}
/**
* Predicate<T> 断言型接口
* @param str
* @param pre
* @return
*/
public boolean changeBoolean(String str, Predicate<String> pre){
return pre.test(str);
}3.Stream API
Stream操作的三个步骤
- 创建stream
- 中间操作(过滤、map)
- 终止操作
4.方法引用、构造器引用、数组引用
方法引用是基于Lambda体的,是Lambda的另一种表现形式,比Lambda更简单
(a) 方法引用
三种表现形式:
1. 对象::实例方法名
2. 类::静态方法名
3. 类::实例方法名 (lambda参数列表中第一个参数是实例方法的调用者,第二个参数是实例方法的参数时可用)
(b)构造器引用
格式:ClassName::new
(c)数组引用
格式:Type[]::new
5.接口中的默认方法、静态方法
在接口中可以直接定义默认实现方法和静态方法
public interface Test {
default String queryName(){
return "zhangsan";
}
static String queryName2(){
return "zhangsan";
}
}
6.新时间日期 API
LocalDate、LocalTime、LocalDateTime
二、JVM堆内存的分代
在基于分代的内存回收策略中,堆空间通常都被划分为3个代,年轻代,年老代(或者tenured代),永久代。在年轻代中又被划分了三个小的区域,分别为:Eden(伊甸)区,S0区(survivor 0),S1区(survivor 1)

三、JVM的基本参数
根据jvm参数开头可以区分参数类型,共三类:“-”、“-X”、“-XX”,
标准参数(-):所有的JVM实现都必须实现这些参数的功能,而且向后兼容;
例子:-verbose:class,-verbose:gc,-verbose:jni……
非标准参数(-X):默认jvm实现这些参数的功能,但是并不保证所有jvm实现都满足,且不保证向后兼容;
例子:-Xms20m,-Xmx20m,-Xmn20m,-Xss128k……
非Stable参数(-XX):此类参数各个jvm实现会有所不同(用的最多:JVM调优),将来可能会随时取消,需要慎重使用;
例子:-XX:+PrintGCDetails,-XX:-UseParallelGC,-XX:+PrintGCTimeStamps……
//常见配置汇总
//堆设置
-Xms:初始堆大小
-Xmx:最大堆大小
-XX:NewSize=n:设置年轻代大小
-XX:NewRatio=n:设置年轻代和年老代的比值.如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
-XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值.注意Survivor区有两个.如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
-XX:MaxPermSize=n:设置持久代大小
//收集器设置
-XX:+UseSerialGC:设置串行收集器
-XX:+UseParallelGC:设置并行收集器
-XX:+UseParalledlOldGC:设置并行年老代收集器
-XX:+UseConcMarkSweepGC:设置并发收集器
//垃圾回收统计信息
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:filename
//并行收集器设置
-XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数.并行收集//线程数.
-XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间
-XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比.公式为1/(1+n)
//并发收集器设置
-XX:+CMSIncrementalMode:设置为增量模式.适用于单CPU情况.
-XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数.并行收集线程数.
-XX:+CMSParallelRemarkEnabled:并发清理四、SpringBoot版本与SpringCloud版本
2.1.18.RELEASE
Greenwich.SR6
SpringCloud官网说明:

五、SpringBoot自动装配原理
- 本质就是通过Spring去读取META-INF/spring.factories中保存的配置类文件然后加载bean定义的过程
- 如果是标了@Configuration注解,就是批量加载了里面的bean定义
- 如何实现”自动“:通过配置文件获取对应的批量配置类,然后通过配置类批量加载bean定义,只要有写好的配置文件spring.factories就实现了自动。

六、SQL语句union和union all的区别
union关键字用来合并两个或多个表联合查询
保证两个表有相同的列,且相同列的类型一致,列名可以不一致
区别:union会查询出来两个结果的并集,且不包括重复行,并会进行默认规则的排序;
union all会查询出来两个结果的并集,且包括重复行,不进行排序
七、SQL语句如何把多行数据放在一行展示
数据 结果
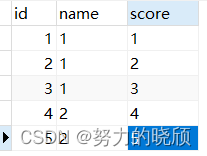
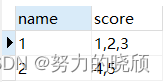
select name,GROUP_CONCAT(score) score from student group by name;
GROUP_CONCAT(字段 分隔符)
注意:MySQL在GROUP_CONCAT函数中,去重需要使用distinct 关键字,如果需要先排序再合并,也可以使用order by 关键字。
八、Redis的持久化机制
两种机制如果一起用的话,默认会使用AOF机制,AOF只会丢失1秒的数据。AOF恢复数据会比RDB更完整,但是恢复速度会比RDB慢
1.RDB机制
是一个持久化机制,它会不定时(默认五分钟甚至更久)的生成一个数据文件,每个数据文件都会记录某段时间的数据,对于redis的性能很小,在同步数据的时候只有一个子进程进行持久化,数据恢复速度很快
2.AOF机制
对每条写入的命令变为一个日志,以append-only的模式写入一个日志文件中。是以追加的方式写入数据,减少磁盘的开销,每秒都会异步刷新一次日志
九、MYSQL的三大范式
第一范式
要求任何一张表必须有主键,每一个字段原子性不可再分割
第二范式
建立在第一范式的基础之上,要求所有非主键字段完全依赖主键,不要产生部分依赖。简单来说,一张表只表示一个内容,不能同时存储其它部分内容
第三范式
建立在第二范式的基础之上,要求所有非主键字段直接依赖主键,不要产生传递依赖。简单来说,每一列都和主键有直接关系,可以根据主键查出相应值
十、开发过程中怎么避免空指针异常
列表判空
CollectionUtils.isEmpty
实体判空
ObjectUtils.isEmpty
StringUtils.isEmpty















 1767
1767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









