







最近遇到了一些mysql的专用术语,然后整理下以备自己及需要的朋友使用
1、覆盖索引 回表
覆盖索引指的是通过索引即可查找出所有满足条件的数据,不再需要回表查询
2、一级索引 二级索引
一级索引 主键 索引和数据存储在一起
二级索引 普通索引 二级索引树的叶子节点存储的是指针而不是数据
3、mysql的mvcc原理
mvcc是指mysql数据库为事务做的并发控制机制
redo log 日志先行,在执行sql之前先将执行sql的执行记录备份存储到redo log中
undo log 备份存放回滚日志,以备发生异常时,事务回滚
mvcc多版本并发控制
插入操作
insert 记录的版本号即当前事务的版本号
更新操作
update 先将旧的原始的数据的版本号删除 然后插入新的当前事务的版本号
删除操作
delete 事务版本号作为删除版本号
补充: MVCC手段只适用于Msyql隔离级别中的读已提交(Read committed)和可重复读(Repeatable Read)
为什么脏读不可以使用MVCC?
.Read uncimmitted由于存在脏读,即能读到未提交事务的数据行,所以不适用MVCC.
原因是MVCC的创建版本和删除版本只要在事务提交后才会产生。
为什么串行化也不可以适用于MVCC?
串行化由于是会对所涉及到的表加锁,并非行锁,自然也就不存在行的版本控制问题
可知,MVCC主要作用于事务性的,有行锁控制的数据库模型
既然mvcc解决了不可重复读 为什么读已提交还是出现了不可能重复读这个问题?
读已提交:每次执行查询sql时都会重新生成最新的read-view
可重复读:执行事务中第一条查询sql时生成read-view,并且再事务结束之前都不会发生变化
4、mysql的各种锁
行锁 包含 S读锁/共享锁和X写锁/排它锁
S读锁,其他事务可以继续加共享锁,但是不能继续加排他锁
X写锁,一旦加了写锁之后,其他事务就不能加锁了
如何加读锁和写锁
LOCK TABLES tbl_name {READ | WRITE},[ tbl_name {READ | WRITE},…]
5、b树和b+树的区别
b树所有节点存储的是key和data,
b+树只有叶子节点存储的所有节点的data,并且节点只存储指针,在叶子节点上横向之间也存储了指针,因此查询效率也提升了很多,b+树层级较浅,每个磁盘空间能存储更多的数据,因此io扫盘的次数大大减少。
6、聚集索引和非聚集索引的区别
聚集索引存的就是数据,非聚集索引存的是指针
聚集索引也可以理解为主键索引即为聚集索引,或者唯一索引就是聚集索引,而非聚集索引就是普通索引
聚集索引:「聚集索引的顺序就决定了数据行的物理存储顺序」,所以我们创建的主键索引其实就是聚集索引,如果未定义主键,MYSQL会默认选择非空的唯一索引当作主键,否则会默认生成一个主键,聚集索引一个表只能有一个
非聚集索引:「索引顺序与数据行物理排列顺序无关,看下「普通索引如何创建,其作用就是加快查询速度,非聚集索引一个表可以有多个
聚簇索引:它其实并不是一种单独的索引类型,而是一种数据存储格式,表A的主键,在表B中存在表A对应的多条数据,在实际应用中可以理解为是一种主从关联关系表这种应用场景可以理解为聚簇索引。
7 事务的隔离级别
关于mysql数据库隔离级别的见解,详情见 数据库隔离级别的看法_奇点-CSDN博客
读未提交(脏读) 不可重复读 可重复度 (幻读)
解决不可重复读的方法是 锁行,解决幻读的方式是 锁表
8 spring事务失效的几种情况
第一种情况(最常见):try catch会使事务失效
第二种情况:在本类中嵌套调用事务也会使事务失效
经过 Spring 的代理类去调用此方法,才会开启事务管理,嵌套调用使用的是this关键字调用本类方法
第三种情况:非public类型方法也会使事务失效
因为spring没办法为这样的方法生成一个代理
第四种情况:spring事务只对runtimeException有效,如果异常非此异常则事务也会失效
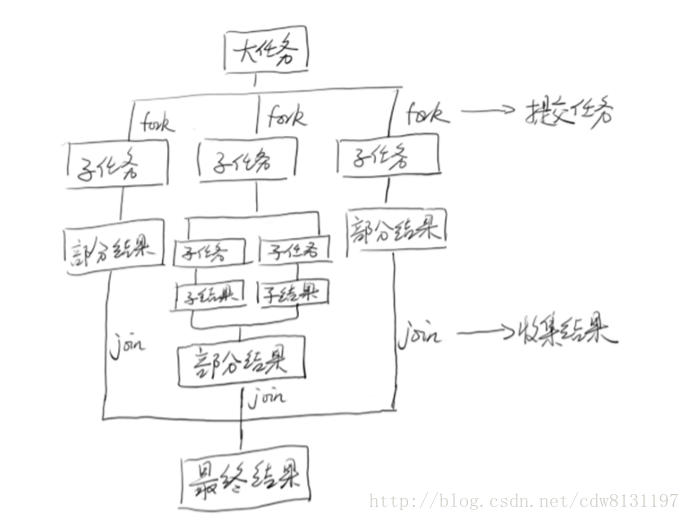
9 jdk8 list.stream.parrller使用的是什么原理?默认多少线程
parallelStream默认使用了fork-join框架,其默认线程数是CPU核心数
如果想修改线程数量则需要使用System修改java.util.concurrent.ForkJoinPool.common.parallelism属性
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "64");
public class ForkJoinPool extends AbstractExecutorService
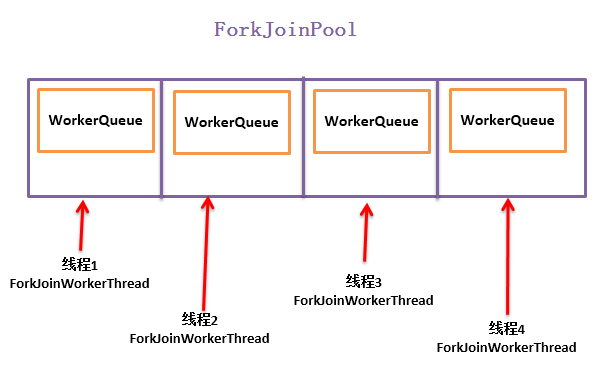
WorkQueue是ForkJoinPool的一个内部类
WorkQueue任务窃取,当前WorkQueue任务执行完毕后会从另外一个WorkQueue的ForkJoinTask数组中任务中窃取尾部的任务执行。
submit方法有返回值 ForkJoinTask
excute方法没有返回值
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
fork()方法 判断如果当前线程是ForkJoinWorkerThread则加入到workQueue,否则,重新提交任务
10 jar包和war包有什么区别
JAR包是类的归档文件,springboot下的jar包包含BOOT-INF、META-INFO、springboot loader
war包是JavaWeb程序打的包,包含WEB-INFO、META-INFO两部分
普通的spring项目打war包即可部署,springboot项目打两种包都可以部署
11 zookeeper脑裂问题?如何结局
譬如一个zk集群,分布在两个机房片区(a,b)一个机房,(c,d,e)在一个机房,当zk的一个leader a服务器突然宕机时,c,d,e 则从following状态变成looking状态,选举投票,又重新选举出一个leader,譬如是c,此时a服务器又恢复正常,此时集群存在了两个leader,这就是脑裂问题。
如何解决脑裂问题,引用过半机制,还是上面的机房配置(a,b)一个机房,(c,d,e)在一个机房,由于引入了过半机制 n>n/2,也就是必须三台机器都投一个server才会变成leader,如果leader 被选在了c节点,c挂了之后 c依然是leader,ab 无法选出leader,de 也无法选出,因此会一直等着c恢复。要么没有leader,要么一直一个leader
12 反射的应用场景
场景一:当调用第三方api,传参数时,不用知道具体参数和值,只需要反射获取然后传给第三方
13 双亲委派?和好处
双亲委派就是当特定的类装载器收到加载类请求时,不是自己去加载而是上父装载器去装在那个class,如果父类装载器还存在父类装载器依次类推给父父类装载器,依次递归,直至找到最顶层的装载器依次装在此类,发现没有再给子类装载器,这样的装在流程即为双亲委派。
好处是:可以避免java API核心类被篡改
14 分布式订单号ID解决方案有哪些?
分布式ID 无非就是保证全局id唯一,幂等性即可,方案有很多
⑴UUID,优点:最简单,缺点:无序,且mysql性能不佳
⑵推特的雪花算法 优点:根据系统时间戳移位,可以保证自增 缺点:测试环境,如果更改系统时间,可能会存在重复订单号
⑶实际业务逻辑+日期时间+全局唯一递增的num
全局唯一递增的num如何实现?
方案1:使用redis锁,然后incr自增获取id
如果获取redis锁获取失败,存入每个服务器的队列中,然后依次循环队列,获取锁,如果依然获取失败,如何保证高可用?
方案2:使用zk的DistributedAtomicLong获取唯一性id
//任意位置的SharedCount,只要使用相同的path,都可以得到这个计数值。
String path = "/path/count";
CuratorFramework client = initClient(path);
DistributedAtomicLong count = new DistributedAtomicLong(client, path, new RetryNTimes(10, 10));
AtomicValue<Long> result = count.trySet(l);
if (result.succeeded()) {
System.out.println(result.postValue() + "设置成功");
System.out.println(result.preValue() + "->" + result.postValue());
} else {
System.out.println(result.postValue() + "设置失败");
System.out.println("计数器仍是旧值:" + result.preValue());
}
或者
DistributedAtomicLong baseCount = new DistributedAtomicLong(client, path, new ExponentialBackoffRetry(1000, 3));
15 数据库索引失效的场景
①select *
②单键值b树索引 存在null值
③like '%'开头
④or not in not exist !=或者 <>
⑤联合索引,where后面条件 未使用第一个索引
⑥where 后面 列上使用函数运算
⑦隐式转换导致不走索引。譬如字段是varchar,却没有传''
16 为什么select * from table不建议使用
① select 无用的列会增加数据传输时间和网络开销
② select varchar text等类型的字段 会加大io频次
③ 失去 mysql优化器 “覆盖索引”策略优化的可能
















 146
146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











