







 本文提供了一份全面的Python学习规划,包括知识体系、常用开发工具、视频教程、实战项目、面试准备等内容,强调系统学习和深度实践的重要性。同时,鼓励读者加入技术交流社群以共同进步。
本文提供了一份全面的Python学习规划,包括知识体系、常用开发工具、视频教程、实战项目、面试准备等内容,强调系统学习和深度实践的重要性。同时,鼓励读者加入技术交流社群以共同进步。
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
解释一下browser.switch_to.window是获取当前一共有几个窗口
这里是2个
browser.switch_to.window这个是指定当前游标切换到哪个窗口
其实也可以这么写
all_window = browser.switch_to.window返回的是一个列表
browser.switch_to.window(all_window[1])
效果是一样的
10.我们需要的是我加入的群信息
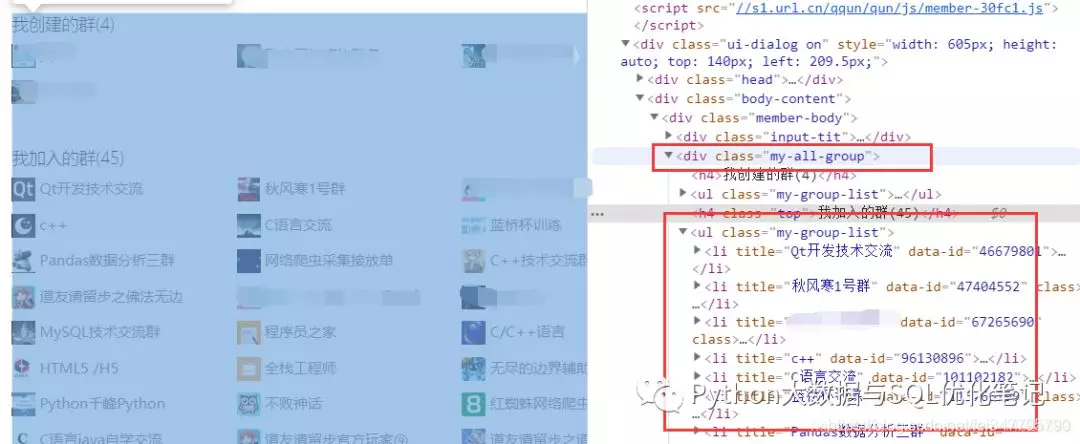
切换句柄之后,我们显示等待窗口出来
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.CLASS_NAME, ‘my-all-group’)
)
)
筛选出我加入的群标签
lis = browser.find_elements_by_xpath(‘.//div[@class=“my-all-group”]/ul[2]/li’)
11.遍历列表,取出信息
遍历
num= 0
while True:
if num == len(lis):
break
try:
按顺序选择群并获取信息
先点击该群获取成员信息
lis[num].click()
显示等待信息加载完成
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.CLASS_NAME, ‘list’)
)
)
获取该群当前有多少人,后面翻页需要
groupMemberNum = eval(browser.find_element_by_id(‘groupMemberNum’).text)
每一次翻页都会刷新21条信息,所以写个循环
这里加1是因为假如一个群有36人,那么count=1,如果循环的话就不会翻页了
也就是只能抓到一页的数据,大家可以自己想想其中的流程就知道了
count = groupMemberNum // 21 + 1
这里我只爬取每个群的一部分,如果想爬取全部成员信息
请注释下面的if语句
if count > 2:
count = 1
每次循环都进行翻页
while count:
count -= 1
browser.execute_script(‘document.documentElement.scrollTop=100000’)
time.sleep(2)
time.sleep(2)
开始获取成员信息
trs = browser.find_elements_by_class_name(‘mb’)
if trs:
遍历
for tr in trs:
tds = tr.find_elements_by_tag_name(‘td’)[2:]
if len(tds) == 8:
qq网名
qq_name = tds[0].text
群名称
group_name = tds[1].text
qq号
qq_number = tds[2].text
性别
gender = tds[3].text
qq年龄
qq_year = tds[4].text
入群时间
join_time = tds[5].text
等级(积分)
level = None
最后发言时间
end_time = tds[6].text
声明一个字典存储数据
data_dict = {}
data_dict[‘qq_name’] = qq_name
data_dict[‘group_name’] = group_name
data_dict[‘qq_number’] = qq_number
data_dict[‘gender’] = gender
data_dict[‘qq_year’] = qq_year
data_dict[‘join_time’] = join_time
data_dict[‘level’] = level
data_dict[‘end_time’] = end_time
print(data_dict)
elif len(tds) == 9:
qq网名
qq_name = tds[0].text
群名称
group_name = tds[1].text
qq号
qq_number = tds[2].text
性别
gender = tds[3].text
qq年龄
qq_year = tds[4].text
入群时间
join_time = tds[5].text
等级(积分)
level = tds[6].text
最后发言时间
end_time = tds[7].text
声明一个字典存储数据
data_dict = {}
data_dict[‘qq_name’] = qq_name
data_dict[‘group_name’] = group_name
data_dict[‘qq_number’] = qq_number
data_dict[‘gender’] = gender
data_dict[‘qq_year’] = qq_year
data_dict[‘join_time’] = join_time
data_dict[‘level’] = level
data_dict[‘end_time’] = end_time
data_list.append(data_dict)
print(data_dict)
browser.find_element_by_id(‘changeGroup’).click()
time.sleep(3)
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.CLASS_NAME, ‘ui-dialog’)
)
)
lis = browser.find_elements_by_xpath(‘.//div[@class=“my-all-group”]/ul[2]/li’)
num += 1
except Exception as e:
lis = browser.find_elements_by_xpath(‘.//div[@class=“my-all-group”]/ul[2]/li’)
num += 1
continue
完整代码附上
导入需要的包
爬取qq群的成员信息
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
import json
import csv
开始登陆
def login_spider():
url = ‘https://qun.qq.com/’
构建谷歌驱动器
browser = webdriver.Chrome()
请求url
browser.get(url)
模拟登陆,首先找到登陆的id,并点击
browser.find_element_by_css_selector(‘#headerInfo p a’).click()
点击之后会弹出一个登陆框,这时候我们用显示等待来等待这个登陆框加载出来
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.CSS_SELECTOR, ‘#loginWin iframe’)
)
)
print(‘登陆框已加载’)
登陆框加载之后,我们发现整个登陆框其实就是另一个网网页
如果在原网页操作这个登陆框的话,是不能操作的
所以我们只需要提取iframe标签的src属性,然后再去访问这个url即可实现
自动登陆
找到iframe标签并获取是如此熟悉
iframe_url = browser.find_element_by_css_selector(‘#loginWin iframe’).get_attribute(‘src’)
再访问这个url
browser.get(iframe_url)
找到快捷登陆的头像并点击
首先用显示等待这个头像已经加载完成
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.ID, ‘qlogin_list’)
)
)
browser.find_element_by_css_selector(‘#qlogin_list a’).click()
print(‘登陆成功’)
return browser
切换句柄操作
def switch_spider(browser):
登陆成功之后,我们就找到群管理的标签并点击,首先等待这个元素加载完成
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.XPATH, ‘.//ul[@id=“headerNav”]/li[4]’)
)
)
browser.find_element_by_xpath(‘.//ul[@id=“headerNav”]/li[4]’).click()
点击之后,我们找到成员管理标签并点击
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.CLASS_NAME, ‘color-tit’)
)
)
browser.find_element_by_class_name(‘color-tit’).click()
打印全部窗口句柄
print(browser.window_handles)
打印当前窗口句柄
print(browser.current_window_handle)
注意这里点击成员管理之后会自动跳转到一个新窗口打开这个页面
所以我们需要将窗口句柄切换到这个新窗口
browser.switch_to.window(browser.window_handles[1])
解释一下browser.switch_to.window是获取当前一共有几个窗口
这里是2个
browser.switch_to.window这个是指定当前游标切换到哪个窗口
其实也可以这么写
all_window = browser.switch_to.window返回的是一个列表
browser.switch_to.window(all_window[1])
效果是一样的
return browser
开始采集数据
def start_spider(browser):
声明一个列表存储字典
data_list = []
切换句柄之后,我们显示等待窗口出来
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.CLASS_NAME, ‘my-all-group’)
)
)
筛选出我加入的群标签
lis = browser.find_elements_by_xpath(‘.//div[@class=“my-all-group”]/ul[2]/li’)
遍历
num = 0
while True:
try:
按顺序选择群并获取信息
先点击该群获取成员信息
lis[num].click()
显示等待信息加载完成
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.CLASS_NAME, ‘list’)
)
)
获取该群当前有多少人,后面翻页需要
groupMemberNum = eval(browser.find_element_by_id(‘groupMemberNum’).text)
每一次翻页都会刷新21条信息,所以写个循环
这里加1是因为假如一个群有36人,那么count=1,如果循环的话就不会翻页了
也就是只能抓到一页的数据,大家可以自己想想其中的流程就知道了
count = groupMemberNum // 21 + 1
这里我只爬取每个群的一部分,如果想爬取全部成员信息
请注释下面的if语句
if count > 5:
count = 5
每次循环都进行翻页
while count:
count -= 1
browser.execute_script(‘document.documentElement.scrollTop=100000’)
time.sleep(2)
time.sleep(3)
开始获取成员信息
trs = browser.find_elements_by_class_name(‘mb’)
if trs:
遍历
for tr in trs:
tds = tr.find_elements_by_tag_name(‘td’)[2:]
if len(tds) == 8:
qq网名
qq_name = tds[0].text
群名称
group_name = tds[1].text
qq号
qq_number = tds[2].text
性别
gender = tds[3].text
qq年龄
qq_year = tds[4].text
入群时间
join_time = tds[5].text
等级(积分)
文末有福利领取哦~
👉一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
👉二、Python必备开发工具

👉三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉 四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末领读者福利)

👉五、Python练习题
检查学习结果。

👉六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉因篇幅有限,仅展示部分资料,这份完整版的Python全套学习资料已经上传
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1486
1486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









