







import time
import aiohttp
import aiofiles
import requests
from lxml import etree
import os
import re
from fake_useragent import UserAgent
from functools import wraps
from asyncio.proactor_events import _ProactorBasePipeTransport
def silence_event_loop_closed(func):
@wraps(func)
def wrapper(self, *args, **kwargs):
try:
return func(self, *args, **kwargs)
except RuntimeError as e:
if str(e) != ‘Event loop is closed’:
raise
return wrapper
_ProactorBasePipeTransport.del = silence_event_loop_closed(_ProactorBasePipeTransport.del)
ua = UserAgent()
headers = {‘User-Agent’: ua.random, ‘Referer’: ‘http://www.tulishe.com’}
class tulishe:
def init(self):
self.write_num = 0
async def get_url(self, url):
async with aiohttp.ClientSession() as client:
async with client.get(url, headers=headers) as resp:
if resp.status == 200:
return await resp.text()
async def html_parse(self, html):
semaphore = asyncio.Semaphore(5)
html_parse = etree.HTML(html)
url_list = html_parse.xpath('//div[@class="img"]//a[@rel="bookmark"]/@href')
tasks = [asyncio.create_task(self.img_parse(url, semaphore)) for url in url_list]
await asyncio.wait(tasks)
async def img_parse(self, h_url, sem):
async with sem:
semaphore = asyncio.Semaphore(5)
h_html = await self.get_url(h_url)
h_html_parse = etree.HTML(h_html)
title = h_html_parse.xpath('//h1[@class="article-title"]/text()')[0]
img_demo_url = h_html_parse.xpath(
'//*[@id="gallery-2"]/div[@class="gallery-item gallery-blur-item"]/img/@src')
img_url_list = []
for d_url in img_demo_url:
img_url = d_url.split('=')[1].split('&')[0]
img_url_list.append(img_url)
i_u_l = h_html_parse.xpath(
'//div[@class="gallery-item gallery-fancy-item"]/a/@href')
full_list = i_u_l + img_url_list
index_list = list(range(1, len(full_list) + 1))
index_dict = dict(zip(full_list, index_list))
tasks = [asyncio.create_task(self.img_con(i_url, i_num, title, semaphore)) for i_url, i_num in
index_dict.items()]
await asyncio.wait(tasks)
async def img_con(self, url, num, title, semaphore):
async with semaphore:
async with aiohttp.ClientSession() as client:
async with client.get(url, headers=headers) as resp:
if resp.status == 200:
img_con = await resp.read()
await self.write_img(img_con, num, title)
else:
print('请求出错,请尝试调低并发数重新下载!!')
async def write_img(self, img_con, num, title):
if not os.path.exists(title):
os.makedirs(title)
async with aiofiles.open(title + '/' + f'{num}.jpg', 'wb') as f:
print(f'正在下载{title}/{num}.jpg')
await f.write(img_con)
self.write_num += 1
else:
async with aiofiles.open(title + '/' + f'{num}.jpg', 'wb') as f:
print(f'正在下载{title}/{num}.jpg')
await f.write(img_con)
self.write_num += 1
async def main(self, ):
q_start_num = input('输入要从第几页开始下载(按Entry默认为1):') or '1'
start_num = int(q_start_num)
total_num = int(input('请输入要下载的页数:')) + start_num
print('*' * 74)
start_time = time.time()
for num in range(start_num, total_num + 1):
url = f'http://www.tulishe.com/all/page/{num}'
html = await self.get_url(url)
print('开始解析下载>>>')
await self.html_parse(html)
end_time = time.time()
print(f'本次共下载写真图片{self.write_num}张,共耗时{end_time - start_time}秒。')
a = tulishe()
asyncio.run(a.main())
### 结语:
可以看到,虽然有反爬限制,但1秒10张的速度是完全可以实用的,虽然之前想尝试用代{过}{滤}理池规避,但实际实验后发现,免费的完全不靠谱,可用的又太贵,只是用来日常学习实用,还是采用限制并发比较实际。
### 关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析学习等教程。带你从零基础系统性的学好Python!
#### 一、Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
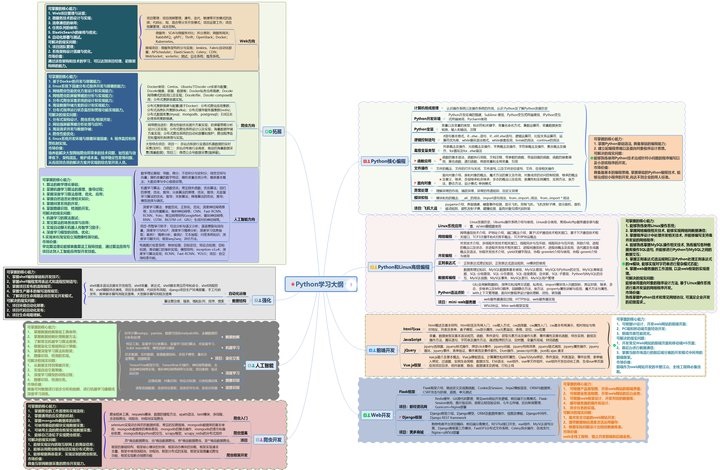
#### 二、Python必备开发工具

做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
* * *
**(1)Python所有方向的学习路线(新版)**
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

**(2)Python学习视频**
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

**(3)100多个练手项目**
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

**(4)200多本电子书**
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
**(5)Python知识点汇总**
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

**(6)其他资料**
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

**这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。**
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里无偿获取](https://bbs.csdn.net/topics/618317507)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1362
1362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









