







(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
数据范围
-
累计 164 页;
-
每页 20 条数据。
图片所在标签与页面地址
图片所在标签位置代码如下:
页面地址为
/desk/23397.htm。整理需求如下
-
生成所有列表页 URL 地址;
-
遍历列表页 URL 地址,并获取图片详情页地址;
-
进入详情页获取大图;
-
保存图片;
-
得到 2000 张图片之后,开始欣赏。
代码实现时间
提前安装完毕
requests模块,使用 pip install requests 即可,如果访问失败,切换国内 pip 源。留个课后小作业,如何设置全局的 pip 源。
代码结构如下:
import requests
抓取函数
def main():
pass
解析函数
def format():
pass
存储函数
def save_image():
pass
if __name__ == ‘__main__’:
main()
先实现 10 行代码抓美女图,举个例子,在正式开始前,需要略微了解一些前端知识与正则表达式知识。
例如通过开发者工具查看网页,得到图片素材都在
<div class="list">和<div class="page">这两个标签中,首先要做的就是拆解字符串,取出目标数据部分。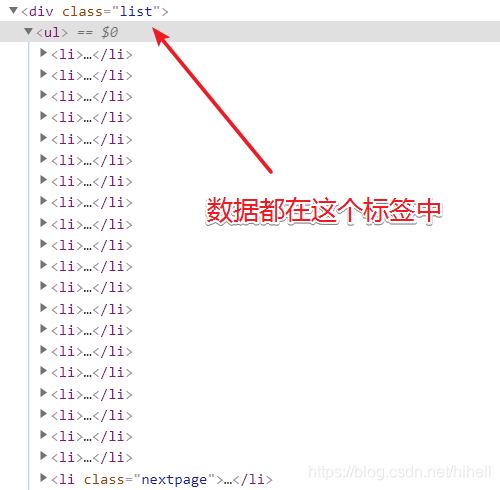
通过
requests对网页源码进行获取,代码如下。# 抓取函数
def main():
url = “http://www.netbian.com/mei/index.htm”
headers = {
“User-Agent”: “Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36”
}
res = requests.get(url=url, headers=headers, timeout=5)
res.encoding = “GBK”
print(res.text)
使用
requests模块的get方法即可获取网页数据,其中的参数分别是请求地址,请求头,等待时间。请求头字段中的
User-Agent,可以先使用我提供给你的内容,也可以通过开发者工具,进行获取。在数据返回
Response对象之后,通过res.encoding="GBK"设置了数据编码,该值可以从网页源码中获取到。
请求到数据源码,即开始解析数据,如果使用正则表达式,建议先对目标数据进行一些简单的裁剪工作。
裁剪字符串是 Python 中比较常规的操作了,直接编写代码即可实现。
用到的还是上文已经提及的两个字符串。
# 解析函数
def format(text):
处理字符串
div_html = ‘
’page_html = ‘
’start = text.find(div_html) + len(div_html)
end = text.find(page_html)
origin_text = text[start:end]
最终得到的
origin_text就是我们的目标文本。通过 re 模块解析目标文本
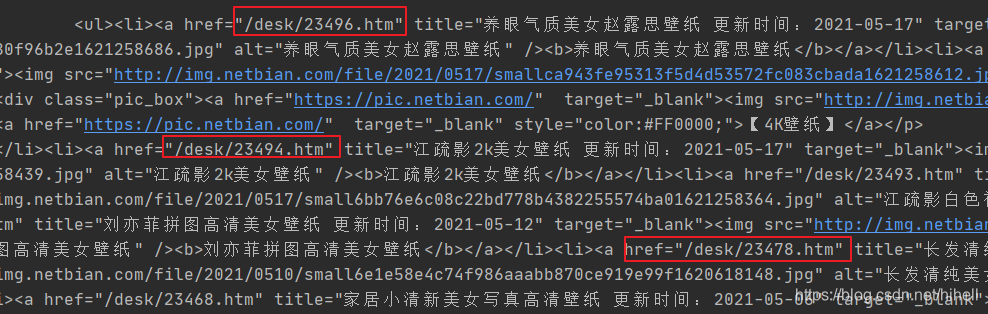
上文返回的目标文本如下所示,本小节的目标就是获取到图片详情页地址。
使用的技术是 re 模块,当然需要配合正则表达式进行使用,对于正则表达式,可以跟随橡皮擦一点点的接触。
# 解析函数
def format(text):
处理字符串
div_html = ‘
’page_html = ‘
’start = text.find(div_html) + len(div_html)
end = text.find(page_html)
origin_text = text[start:end]
pattern = re.compile(‘href=“(.*?)”’)
hrefs = pattern.findall(origin_text)
print(hrefs)
其中 re.compile 方法中传递的就是正则表达式,它是一种检索字符串特定内容的语法结构。 例如 . :表示除换行符(\n、\r)之外的任何单个字符; *:表示匹配前面的子表达式零次或多次; ?:当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的,非贪婪就是减少匹配; ():分组提取用。有这些知识之后,在回到代码中去看实现。

假设存在一个字符串:href=“/desk/23478.htm”,使用 href=“(.*?)” 可以将其中的
/desk/23478.htm匹配出来,括号的作用也是为了后续方便提取。最后输出内容如下图所示。

清洗爬取结果
其中存在部分链接地址不正确,需要从列表中进行去除,本步骤使用列表生成器即可完成任务。
pattern = re.compile(‘href=“(.*?)”’)
hrefs = pattern.findall(origin_text)
hrefs = [i for i in hrefs if i.find(“desk”)>0]
print(hrefs)
抓取内页数据
获取到列表页地址之后,就可以对图片内页数据进行获取了,这里用到的技术与前文逻辑一致。
# 解析函数
def format(text, headers):
处理字符串
div_html = ‘
’page_html = ‘
’start = text.find(div_html) + len(div_html)
end = text.find(page_html)
origin_text = text[start:end]
pattern = re.compile(‘href=“(.*?)”’)
hrefs = pattern.findall(origin_text)
hrefs = [i for i in hrefs if i.find(“desk”) > 0]
for href in hrefs:
url = f"http://www.netbian.com{href}"
res = requests.get(url=url, headers=headers, timeout=5)
res.encoding = “GBK”
format_detail(res.text)
break
在第一次循环中增加了
break,跳出循环,format_detail函数用于格式化内页数据,依旧采用格式化字符串的形式进行。由于每页只有一张图片是目标数据,故使用的是
re.search进行检索,同时调用该对象的group方法对数据进行提取。发现重复代码了,稍后进行优化。
# 存储函数
def save_image(image_src):

感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
-















 2098
2098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









