







写在前面
我们已经初步的认识到到类的内容了,但是那些都是基础的,今天我们来分享一些比较细节的内容,也是对我知识的一个梳理,难度比较大,所以这个博客我可能写的不太好,到时候有什么问题,可以直接在评论区留言,我看到立马回复,要是我也不懂的,就去给你们查资料,还请谅解.
类的6个默认成员函数
这个博客主要就是和大家分享成员函数(方法),里面的内容比较多,我一个一个来吧,我们现在来看道例题,作为今天的开篇.
请问这个类里面都有什么东西?
class Person
{
};
这不就是一个空类吗?里面什么都没有.要是你这么想,就有些简单了,是的,我们看到里面什么都没有,但是实际上编译器会自动生成六个默认的成员函数,他们存在这个类里面,至于如何验证,单机先不要着急.
我们先来看看这六个成员函数,但是我们只详细说其中的四个,另外的两个不太重要,简略的谈谈就可以了.
- 构造函数 完成对象的初始化.不是构造对象
- 析构函数 完成资源的清理
- 拷贝构造 对象拷贝必须调用拷贝函数
- 赋值重载 重新定义运算符

构造函数
构造函数又称构造方法,在C++中是帮助我们实例化对象的作用,记住是帮助我实例化对象.我们先来看看这个东西.
class Person
{
public:
void Print()
{
cout << "我叫" << _name << ",今年" << _age << "岁了" << endl;
}
void Set(const char* name, const int age)
{
strcpy(_name, name);
_age = age;
}
private:
int _age;
char _name[20];
};
int main()
{
Person per1;
per1.Set("张三", 18); //每次都要 set
per1.Print();
return 0;
}
我们每一次实例化一个对象,都要给这个对象进行Set,这是不是有点太麻烦了,有时候我们可能会忘记初始化,于是聪明的程序员想到我们可不可以在对象实例化的时候让编译器自动帮助我们初始化,这样就不谈忘的问题了,于是就出现了一个比较特别的函数-构造函数.
构造函数的特性
现在我们就可以正式认识构造函数了,构造函数存在下面的几个特性.
- 没有返回值 记住返回值是没有 不是void
- 函数名和类名一样
- 支持重载
- 对象实例化时编译器自动调用对应的构造函数
我们先来把前面的代码优化一下,写一个构造函数
class Person
{
public:
void Print()
{
cout << "我叫" << _name << ",今年" << _age << "岁了" << endl;
}
// 带有 两个 参数(编译器的那个 this 没算)的 构造函数
Person(const char* name, const int age)
{
strcpy(_name, name);
_age = age;
}
private:
int _age;
char _name[20];
};
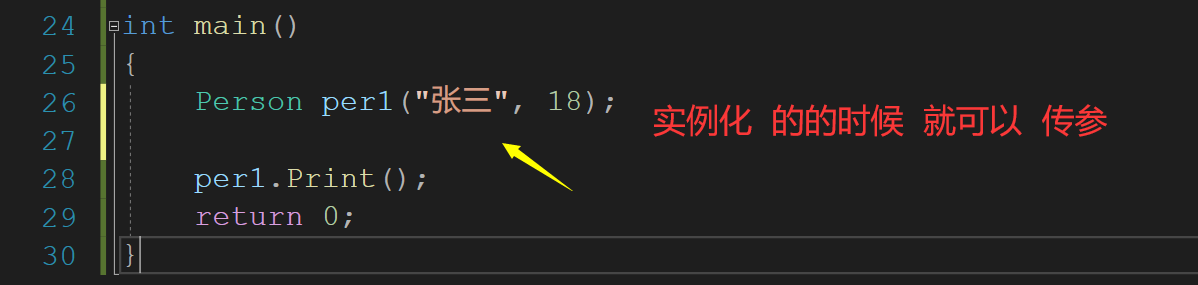
int main()
{
Person per1("张三", 18);
per1.Print();
return 0;
}

默认构造函数
这个属于构造函数的特别的一类,我们需要先看看下面的东西,只是初步认识,后面细谈.
- 编译器自动生成
- 无参的构造函数
- 全缺省的构造函数
编译器自动生成
一般情况下,构造函数谈到上面那里就可以了,但是对于我们还远远不够.我们需要理解一些东西.再刚开始的代码中,我想问问类里面存在构造函数吗?这个问题,我一开始就回答了,存在的编译器自动生成一个构造函数.
我们验证一下,假如我们在类类里面自己写了构造函数,看看会什么?
class A
{
public:
A(int a)
{
}
};
int main()
{
A _a;
return 0;
}

我们开始疑惑,我们不是写了一个构造函数,为何会报错,.我们可以一眼看出,我们实例化对象的时候没有传参,也就是问题所在,从这里我们就可以看出,实例化对象的时候编译器会自动调用相匹配的构造函数,也就是说,实例化对象的时候定会存在构造函数的参与.
但是看看下面的代码,为何不报错? 原因就是编译器自动生成了一个无参的构造函数,至于它的结构是啥,就不需要了解了.
class B
{
};
int main()
{
B b;
return 0;
}

从这里可以得到一个结论,如果我们不写构造函数,编译器自动生成一个,写了编译器就不会生成了,至于我们什么时候要写,什么时候不写,先放到这,这里要展开的话还有点困难,我们放在最后说.
无参的构造函数
我们自己写的无参的构造函数也是属于默认的构造函数,这里和大家说一下.
这里面就比较简单了,至于代码里面的那个问题,不要急,最后我会说的.
class A
{
public:
A()
{
a = 0;
}
void Print()
{
cout << "无参构造函数" << endl;
cout << "a = " << a << endl;
}
public :
int a;
};
int main()
{
A a; // 为哈 不是 写 A a()?
a.Print();
return 0;
}

全缺省的构造函数
这是最后一个了,一般到这里而言我们就对默认构造函数很了解了,理解这个就比较简单了.我们看看现象基本可以了.
class A
{
public:
// 全缺省
A( int a = 10)
{
_a = a;
}
void Print()
{
cout << "无参构造函数" << endl;
cout << "a = " << _a << endl;
}
public :
int _a;
};
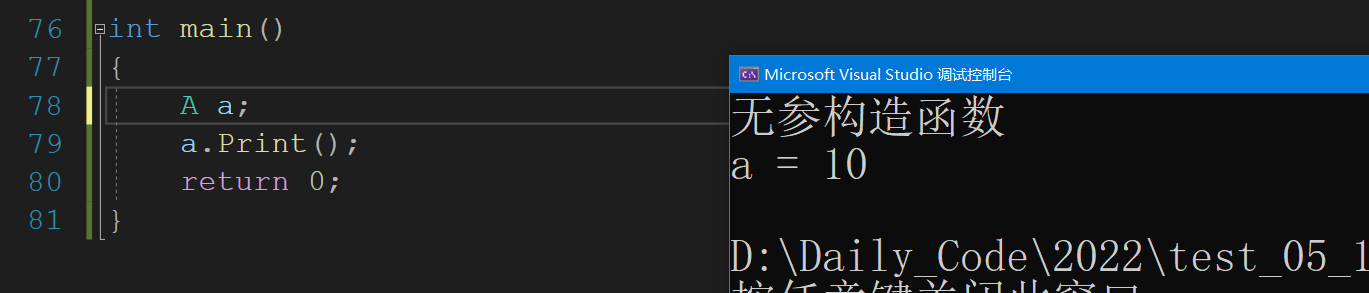
int main()
{
A a; // 为哈 不是 写 A a()?
a.Print();
return 0;
}
为哈是 Aa
这个就要来解决上面遗留的问题了,这个说实话是语法规定的,我也很难搞懂,但是我们可以通过现象来搞懂一些东西.
先解决编译器自己生成的那个,这里我们解决不了,这里现象也不看了,记住就行.
再开始解决自己写的自己写的无参的构造函数,我们看看现象.
class A
{
public:
A()
{
}
void Print()
{
cout << "你好,世界" << endl;
}
};
int main()
{
A a();
a.Print();
return 0;
}

也就是说编译器找不到相匹配的构造函数,要不让也不会报错.
最后一个就是全缺省构造函数
class A
{
public:
// 全缺省
A(int a = 10)
{
_a = a;
}
A()
{
}
void Print()
{
cout << "无参构造函数" << endl;
cout << "a = " << _a << endl;
}
public:
int _a;
};
int main()
{
A a();
a.Print();
return 0;
}

这个报错和上面一样,这个我们就不理解了,全缺省不是允许我们可以这么做吗?是的,但是这里就不允许了.
大家可能看我说了半天废话,是的,我也解释不清楚,但是我可以知道一个这样的问题
假如 一个类里面存在无参的构造函数,也存在一个全缺省的构造函数,我们使用 A a();来实例化对象,请问编译器会使用哪个构造函数,编译器也不知道,索性把这种用法给抛弃了,一了百了.
默认构造函数的优先级
这个我想和大家谈谈,也不知道我的标题名字写的准确不准确,我也不知道这个知识点的名字叫什么,这里先给大家描述一下,
假如 一个类里面存在无参的构造函数,也存在一个全缺省的构造函数,我们使用 A a;调用的是哪个构造方法?这里用现象来得到答案.
class A
{
public:
// 全缺省
A(int a = 10)
{
cout << "全缺省" << endl;
}
//无参
A()
{
cout << "无参" << endl;
}
};
int main()
{
A a;
return 0;
}
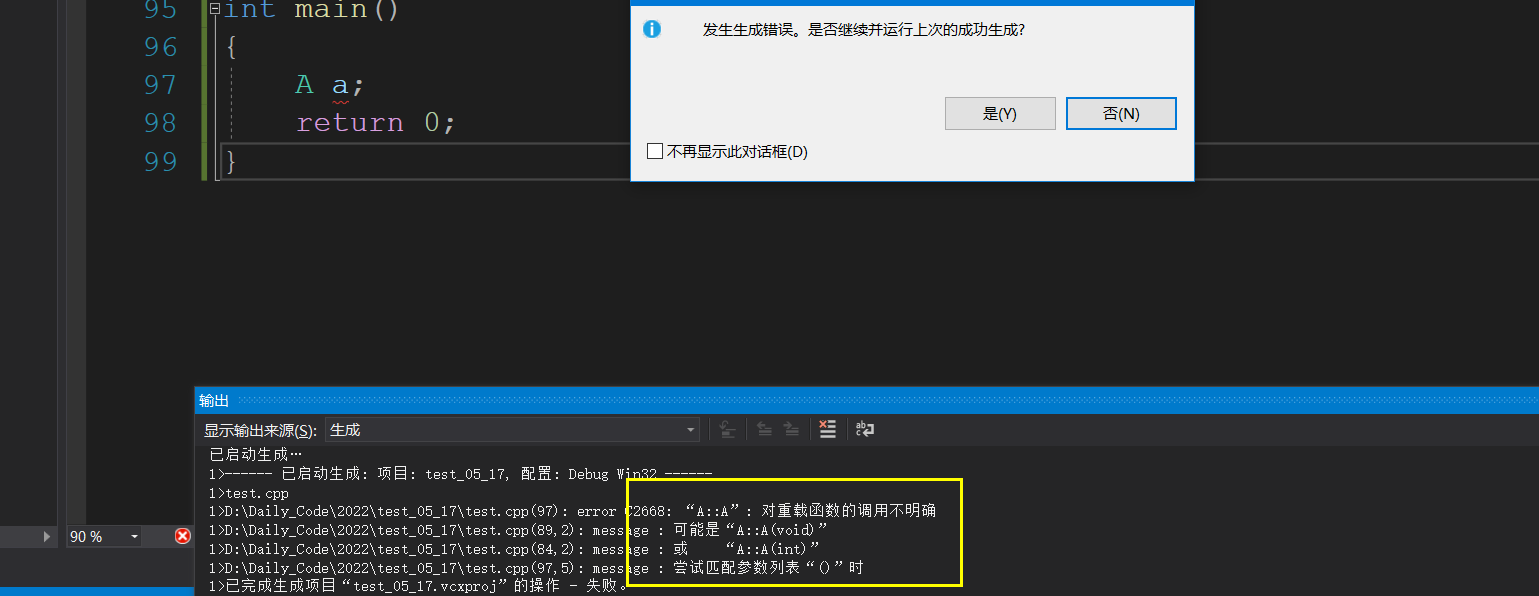
很抱歉,这个会出现错误,所以我们也谈不上优先级了,这个大家要记住这一点,无参的构造函数和全缺省的不能同时存在,我建议写全缺省的.
默认构造函数的作用
我们前面就提了,构造函数是为了我们进行初始化的.但是这个初始化也是有很大的问题的,这里C++在之前有很大的缺陷,直到C++11才弥补了一部分.
对内置类型不做改变
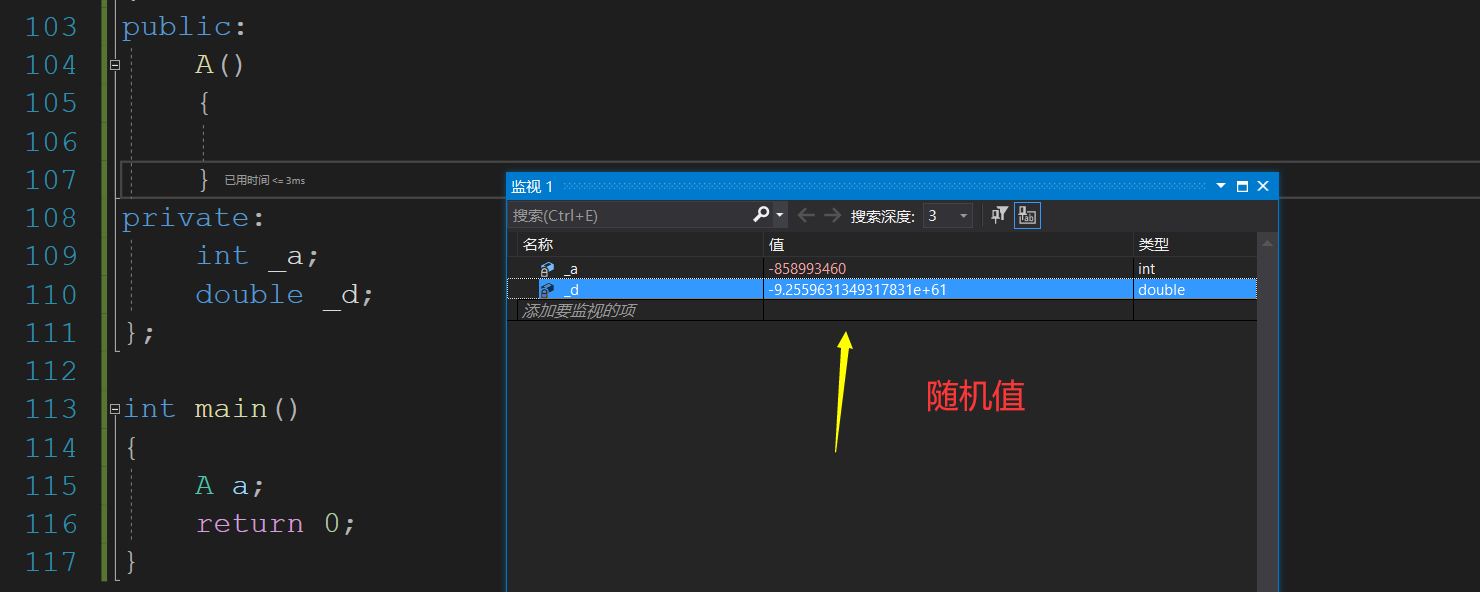
C++这个特性很让人苦恼,在使用默认构造的时候对内置类型竟然不做处理,是在是有点难以让人接受.我们一看就可以明白了.
class A
{
public:
A()
{
}
private:
int _a;
double _d;
};
int main()
{
A a;
return 0;
}
C++11填坑
这个坑太大了,反正我是相对这个问题骂骂咧咧,幸好C++11把这个坑给填了,但是这个方法也会出初学者造成很大的问题,我先说方法
class A
{
public:
A()
{
}
private:
int _a = 0; // 在这 声明
double _d = 0.0;
};
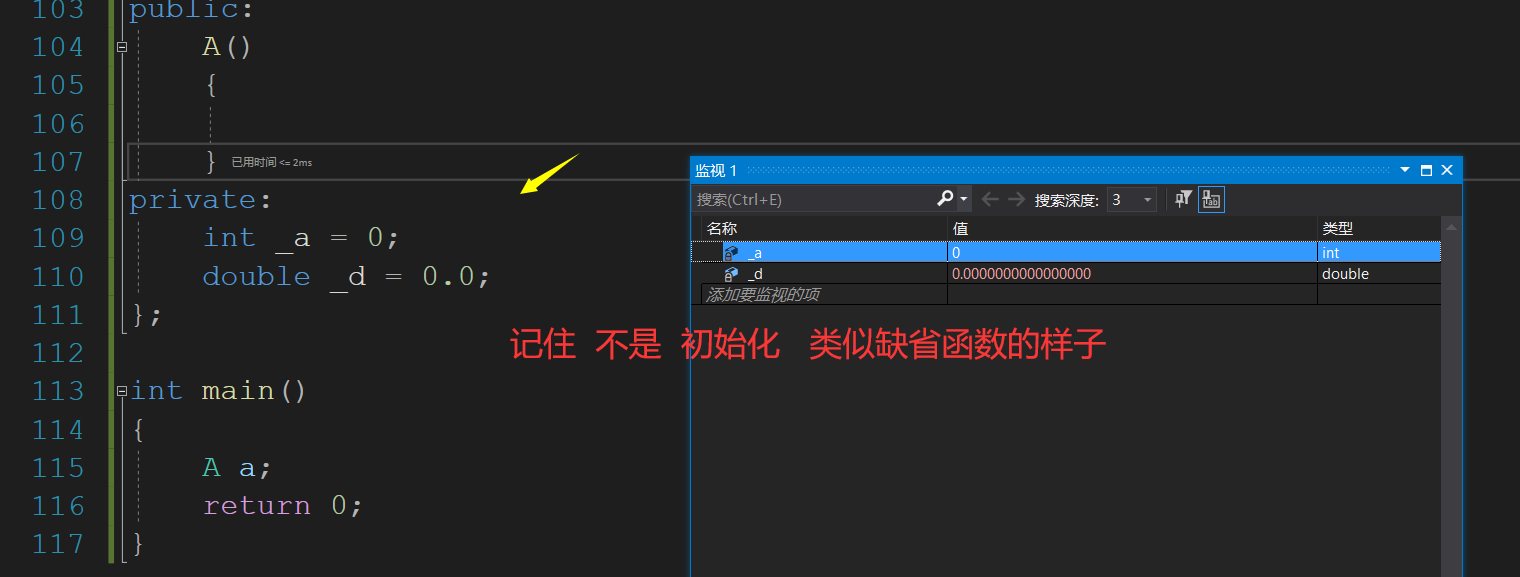
这个给初学者一个误区,认为int _a = 0; 是初始化,但是开辟空间是在实例化对象的时候,那只是一个声明,类似于缺省函数的那样作用.
对自定义类型进行初始化
上面的标题描述的也不太准确,这句话可以这样说,对于自定类型,编译器会调用这个自定义类的默认构造函数,来帮助进行初始化.
class A
{
public:
A()
{
cout << "辅助 进行 初始化" << endl;
}
private:
int _a;
double _d;
};
class B
{
public:
B()
{
}
A _aa;
};
int main()
{
B b;
return 0;
}

我们需要看看里面的结果,再来一次调试.
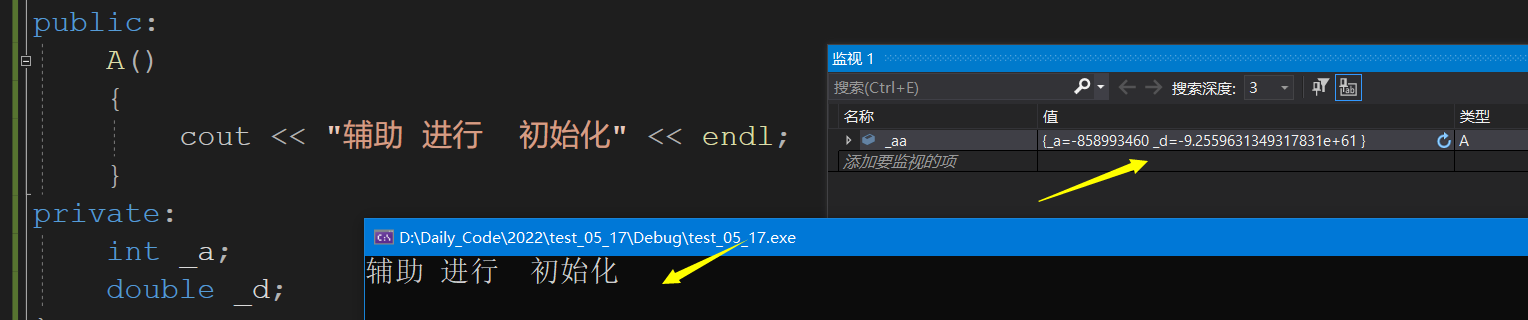
有人可能眼见,看到_aa里面的内容也没有进行初始化,这是由于我们在A类中没有把默认初始化给写好,我重新写一下A类,在调试一下.这样就可以了.
class A
{
public:
A()
{
//在这写好
_a = 0;
_d = 0.0;
}
private:
int _a;
double _d;
};
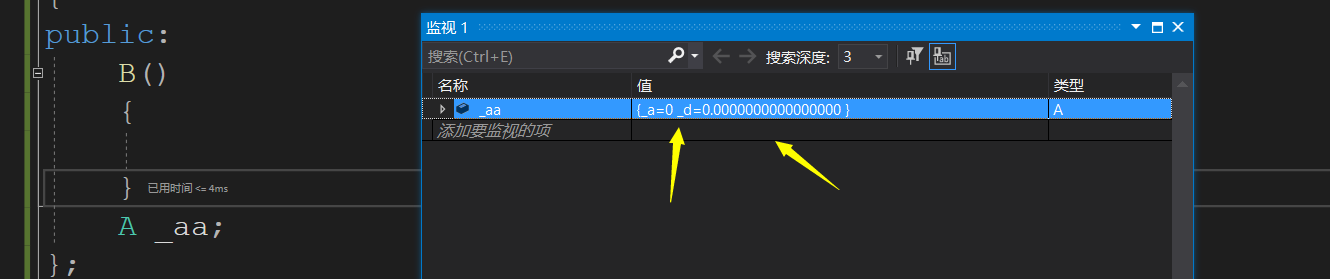
从这里就可以看出,对于类里面的内置类型我们需要给它初始化,自定义类型就不需要了.
总结
说了这么多,现在需要来个总结,我们学习了构造函数,知道了默认构造函数,也明白了构造函数的作用,这些都是比较有难度的.
析构函数
如果说构造函数是为了初始化,那么析构函数就是为了资源的清理工作,对于一些比较用以忘得程序员,这是一个福音,比如我们使用malloc开辟了一款空间,有的时候容易忘记free掉,这就会造成内存泄漏.这就会有一定得问题.但是析构函数可以在对象生命周期结束后,会自动调用这个析构函数.我们只需要在这析构函数free里面就可以了.
析构函数得特性
我们先来看看析构函数得特性,这是我们得基础.
- 析构函数名是在类名前加上字符 ~。
- 无参数无返回值。
- 一个类有且只有一个析构函数。若未显式定义,系统会自动生成默认的析构函数。
- 对象生命周期结束时,C++编译系统系统自动调用析构函数。
编译器自动调用
我们先看看个例子.
class A
{
public:
A(int cap = 4)
{
int* arr = (int*)malloc(sizeof(int) * cap);
assert(arr);
a = arr;
memset(arr, 0, sizeof(int) * cap);
_cap = cap;
}
~A()
{
_cap = 0;
free(a);
a = nullptr;
}
private:
int* a;
int _cap;
};
int main()
{
A a;
return 0;
}

从上面得动图我们就可以知道了,在对象a得声明周期结束后,编译器会自动调用析构函数,完成资源得清理.
默认生成得析构函数
我们需要看看默认生成得析构函数会怎样,这样可以帮助我们更高效得写出代码.
析构函数会对内置类型进行资源清理吗
很抱歉,并不能帮助我们把内置类型给清理掉.
class A
{
public:
A(int cap = 4)
{
int* arr = (int*)malloc(sizeof(int) * cap);
assert(arr);
a = arr;
memset(arr, 0, sizeof(int) * cap);
_cap = cap;
}
private:
int* a;
int _cap;
};

析构函数可以清理自定义类型吗
这个是可以得,不过需要调用自定义类型得析构函数,这个和默认构造函数的初始化一样的.
会调用自定义了类型的析构函数
class A
{
public:
~A()
{
cout << "自定义类型的析构函数" << endl;
}
};
class B
{
private:
A _aa;
};
int main()
{
B b;
return 0;
}

我们也可以看看是如何调用的析构函数.
class A
{
public:
A(int cap = 4)
{
int* arr = (int*)malloc(sizeof(int) * cap);
assert(arr);
a = arr;
memset(arr, 0, sizeof(int) * cap);
_cap = cap;
}
~A()
{
_cap = 0;
free(a);
a = nullptr;
}
private:
int* a;
int _cap;
};
class B
{
public:
B()
{
}
private:
A _aa;
};
int main()
{
B b;
return 0;
}

总结
这样我们也可以得到一个结果,对于自定类型我们不需要写析构函数,对于内置类型需要进行资源清理,避免内存泄漏.
拷贝构造
那在创建对象时,可否创建一个与一个对象一某一样的新对象呢?拷贝构造是构造函数的一种,也是我们未来写类比较关键的内容,我们需要了解一下。
构造函数:只有单个形参,该形参是对本类类型对象的引用(一般常用const修饰),在用已存在的类类型对象
创建新对象时由编译器自动调用
值拷贝
我们起初在学习函数的时候,大多时候都会给函数传入参数,也就是编译器另开辟一块空间,把要出传入的内容拷贝一份放到这块空间里面.这就是简单的值拷贝.
我们确实需要好好看看这个值拷贝,我们发现它们的地址是不一样的.
void func(int b)
{
cout << "&a" << &b << endl;
}
int main()
{
int a = 10;
func(a);
cout <<"&a" << &a << endl;
return 0;
}
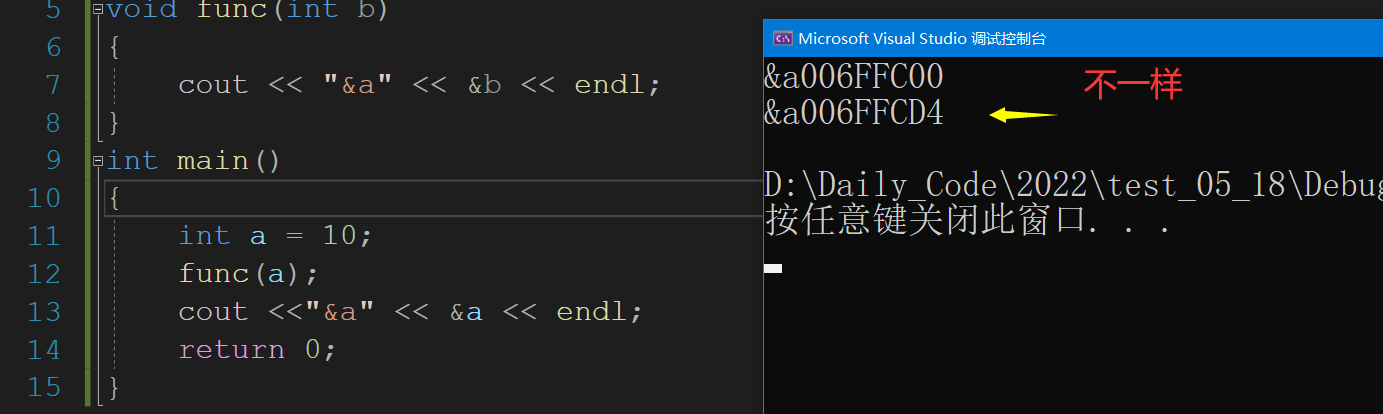
对于一些简单的类型,这个拷贝是没有问题的,但是现在我要和大家看看这个.
void func(int* pb)
{
free(pb);
}
int main()
{
int* arr = nullptr;
arr = (int*)malloc(sizeof(int) * 4);
func(arr);
free(arr);
return 0;
}
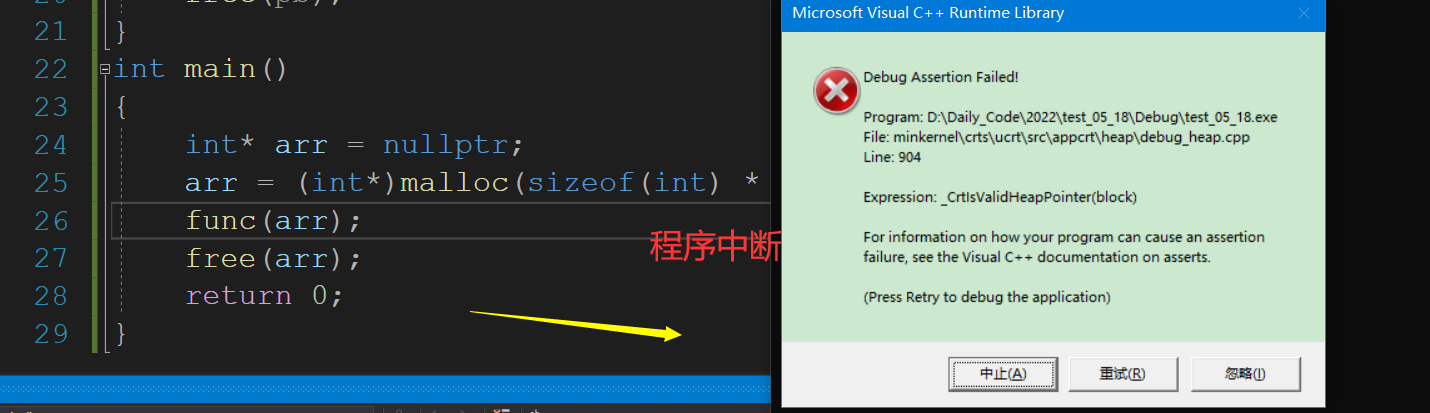
我们就会发现一个问题,对于一些类型,简单的值拷贝完全不够,上面为何会报错?原因就是我们把数组名作为参数,编译器简单的把它当做了一个指针,拷贝给了pb,但是pb的所指向的内容是没有变的,所以我们free掉了两次,程序会中断.
拷贝构造的特性
我们认识到了值拷贝,现在我们就可以说拷贝构造了,拷贝构造也是编译器默认生成的构造函数,函数名和类名一样.
- 拷贝构造函数是构造函数的一个重载形式。
- 拷贝构造函数的参数只有一个且必须使用引用传参,使用传值方式会引发无穷递归调用。
第二个话题我们先不谈,最后分享.
默认生成的拷贝构造
我们先来看看默认生成的拷贝构造作用如何,来看看我们何时需要自己写拷贝构造
class A
{
public:
A(int a = 0,double d = 0.0)
{
_a = a;
_d = d;
}
~A()
{
_a = 0;
_d = 0.0;
}
public:
int _a;
double _d;
};
int main()
{
A _aa(1, 3.0);
cout<< "_aa._a = " << _aa._a;
cout<< " _aa._d = " << _aa._d << endl;
A _bb(_aa);
cout << "_bb._a = " << _bb._a;
cout << " _bb._d = " << _bb._d << endl;
return 0;
}
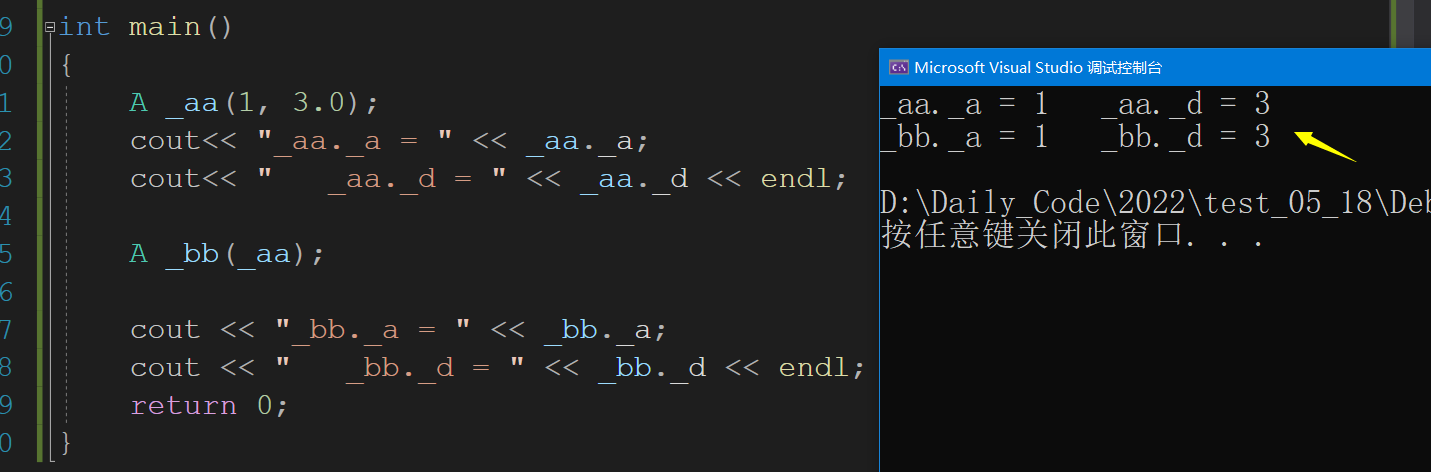
这个构造可以可以说是一样,所以我们不用担心编译器这一次不会不管内置类型了,这一点很好,但是也出现问题了,下面来看.
默认构造函数是值拷贝吗
这个问题很严重,要知道我们对象在生命周期结束后是会调用析构函数的,要是出现两次free这个情况,我想谁都会骂娘.
看看吧
class A
{
public:
A(int cap = 4)
{
int* pa = (int*)malloc(sizeof(int) * cap);
assert(pa);
_array = pa;
}
~A()
{
free(_array);
_array = nullptr;
}
public:
int* _array;
};
void func(A _bb)
{
cout << _bb._array << endl;
}
int main()
{
A _aa;
func(_aa);
cout << _aa._array << endl;
return 0;
}
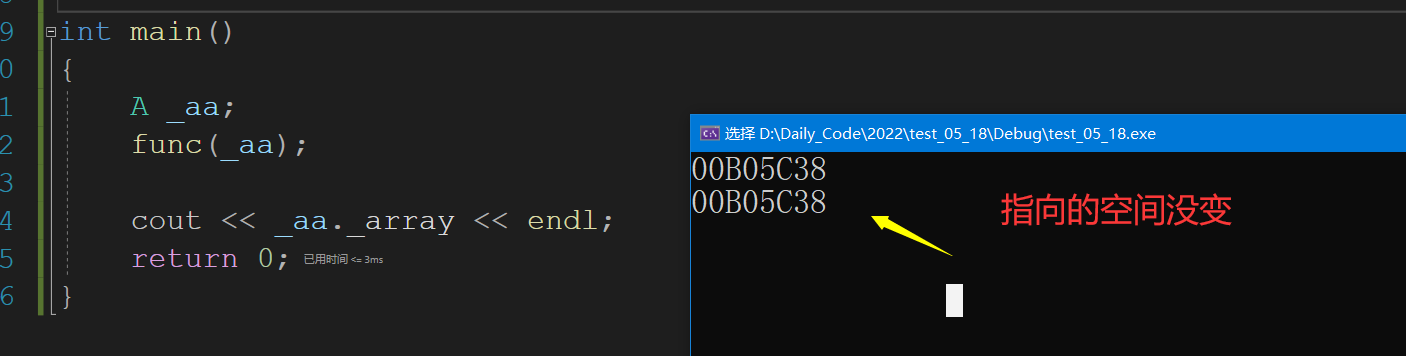
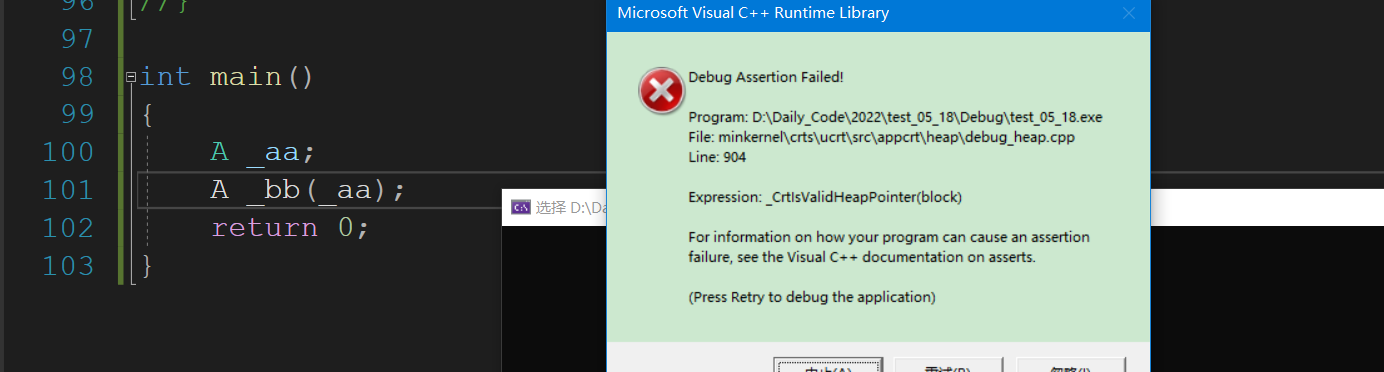
这也就意味着默认生成的只是简单的值拷贝,也就是说下面的代码会被中断,又多次free了同一片空间.
int main()
{
A _aa;
A _bb(_aa);
return 0;
}
手写构造函数
分享了这么多,我们好象还没有手写构造函数,这个来个普通的,但是里面的细节也很多.
class A
{
public:
A(int a = 0, double d = 0.0)
{
_a = a;
_d = d;
}
A(const A& a)
{
_a = a._a;
_d = a._d;
}
private:
int _a;
double _d;
};

我们开始抠细节了.
为何用 const 修饰
很好,我们可以不用const修饰,但是有时候会写出这样的代码.
A(const A& a)
{
a._a = _a; //写反了
_d = a._d;
}
用const修饰就可以避免这种失误,因为它编译不过,可以很快的查出问题所在.
为何使用引用
你发现了最为重要的东西,首先要记住一点,自定义类型要实现拷贝,必须先调用构造函数,如果你写的是普通传参,那也要进行拷贝,需要构造函数,编译器开始寻找构造函数,找到构造函数发现要进行拷贝,寻找构造函数…出现死循环,所以我们要使用别名,避免拷贝.
构造函数对内置类型怎么办
这个我们前面已经说的很详细了,这里就给出一个结论,如果你的类里面没有指向同一片空间的这种类似的属性,用默认的就可以了,但是要是存在,就需要自己来写,至于如何写这涉及到深浅拷贝的知识了,这里就不谈了.这个规律适合大部分情况.
构造函数对自定义类型怎么办
这个我就不放动图了,它和构造函数以及析构函数一样,去寻找自定义类型自己的构造函数.
构造函数的现代的写法
我们之前写的构造函数都是很传统的一个写法,这里有人已提出一个资本家写法,大家先来看看.
我们在拷贝构造里面实例化一个一摸一样对象,然后经行交换,最终还让编译器把实例化的对象给析构了,老资本家了.
class A
{
public:
A(const char* str = "")
:_str(new char[strlen(str) + 1])
{
strcpy(_str, str);
}
A(const A& a)
{
A tmp(a._str); // 我实例化一个 对象
std::swap(_str, tmp._str);
}
private:
char* _str;
};
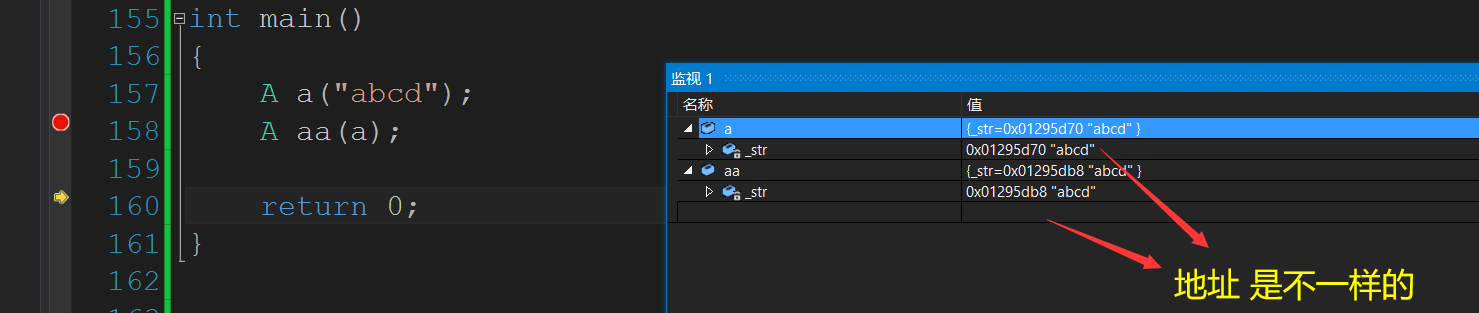
对于自定义类行也是也一样的
class A
{
public:
A(int a = 0, int b = 0)
:_a(a)
, _b(b)
{
}
A(const A& a)
{
A tmp(a._a, a._b);
std::swap(_a, tmp._a);
std::swap(_b, tmp._b);
}
private:
int _a;
int _b;
};
int main()
{
A a(1, 2);
A aa(a);
return 0;
}
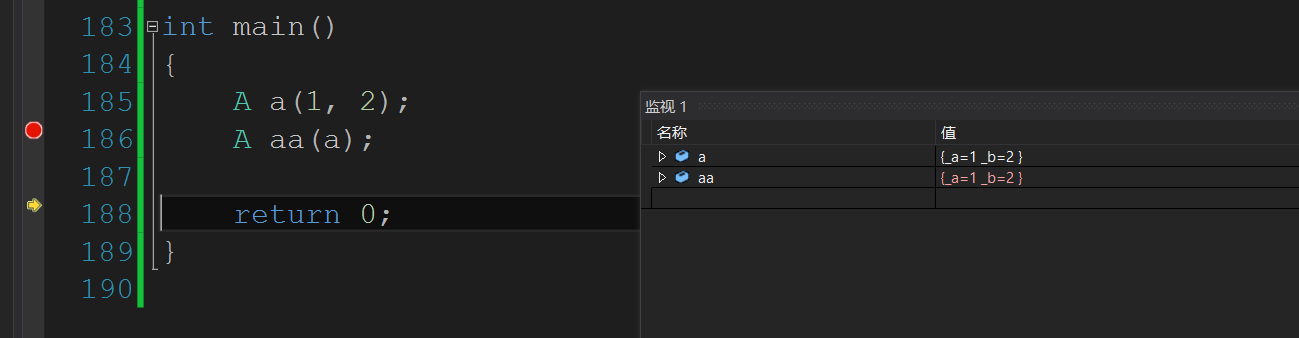















 9522
9522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











