







parse 用于解析 URL,比如拆分、解析、合并等。
robotparser 用于解析 robots.txt 文件,主要是用来识别网站的robots.txt文件,然后判断哪些网站可以爬,哪些网站不可以爬。
urllib库 爬虫抓取百度贴吧示例

需要注意的是urllib不能自动判断重定向,需要自己解析重定向的链接并重新请求。
如果你只是爬取一般的网页,那么Python自带的urllib库足够用了,如果是想要爬取异步加载的动态网站,requests库会方便很多。
requests库
功能强大的爬取网页信息的第三方库,可以进行自动爬取HTML页面及自动网络请求提交的操作。

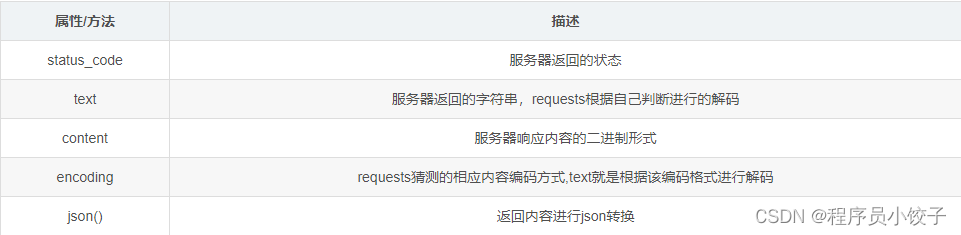
requests库的主要方法:
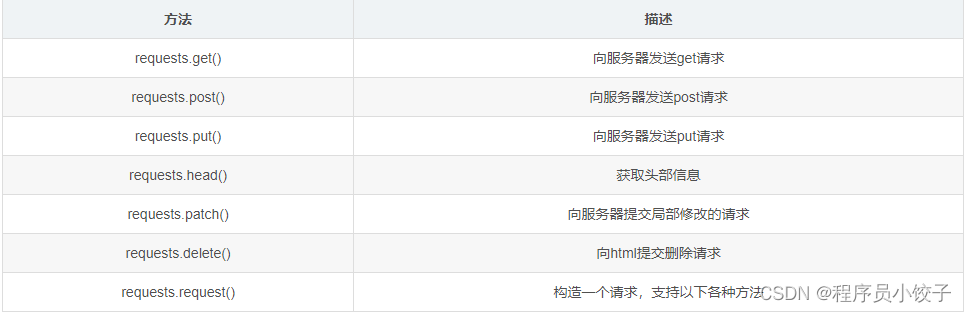
Response对象
requests库爬取豆瓣短评示例:

爬虫案例:中国高校排名

爬虫学习其实并不难,特别适合零基础入门,我这里分享一个名片,可以免费听爬虫相关公开课,并带你实操爬虫相关项目,扫描下面二维码——>添加csdn官方认证免费领取

技巧二:抓包工具分析网络请求
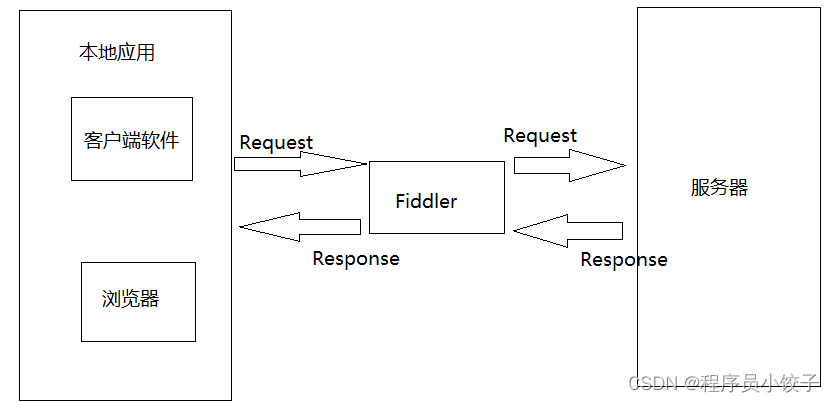
抓取工具主要有chrome firefox fidder appium,重点讲一下fidder,基本可以说目前最为全面和强大的抓包工具就是fiddler了,使用也不算麻烦。
Fiddler也在官网上有提供非常详细的文档和教程,如果使用的时候遇到问题,可以直接查阅官网文档。我们可以利用Fiddler详细的对HTTP请求进行分析,并模拟对应的HTTP请求。
fiddler程序界面
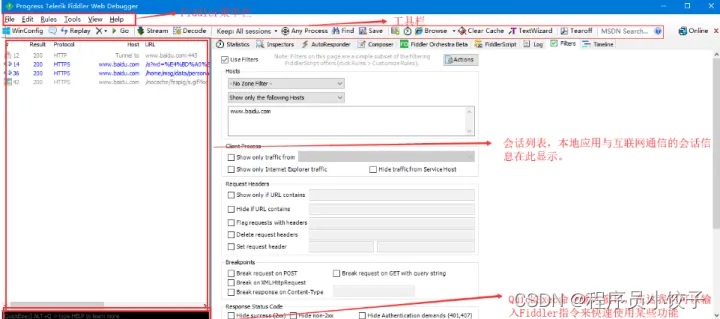
fiddler本质就是一个HTTP代理服务器,功能非常强大,除了可以清晰的了解每个请求与响应之外,还可以进行断点设置,修改请求数据、拦截响应内容。
技巧三:解析数据库
解析库有非常多可以选择,比如CSS、pyqery、re、xpath等,比较建议掌握Beautiful Soup和Xpath
Beautiful Soup解析库
为第三方库需要安装使用,在命令行用pip安装就可以了:

具体用法:变量名称 = BeautifulSoup(需要解析的数据,"html.parser’)
它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序,能自动转换编码。
BeautifulSoup支持的解析器
1.Python标准库:内置库、执行速度适中、文档容错能力强;
2.lxml HTML解析器:速度快,文档容错能力强(推荐);
3.lxml XML解析器:速度快,唯一支持xml的解析器;
4.html5lib:最好的容错性、以浏览器方式解析文档,生成HTML5格式的文档。
具体用法:soup=BeautifulSoup(markup,from_encoding=“编码方式”)
Beautiful Soup模块抓取网页信息示例:

备注:1. BeautifulSoup()内的第一个参数,即需要解析的数据,类型必须为字符串,否则运行时系统会报错。
Xpath解析库
提供了非常简洁明了的路径选择表达式,XPath相对于正则表达式显得更加简洁明了,对于网页的节点来说,它可以定义id、class或其他属性。而且节点之间还有层次关系,在网页中可以通过XPath来定位一个或多个节点
规则:
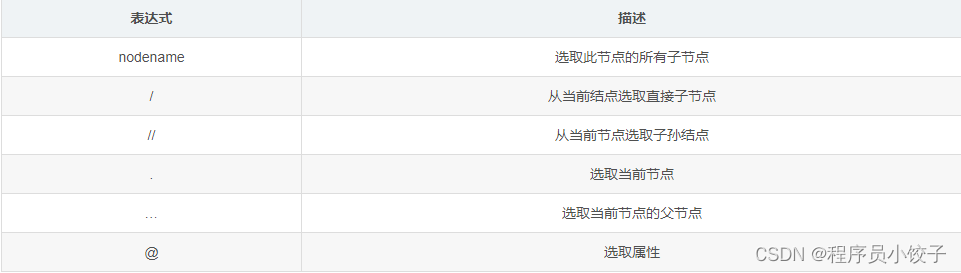
Xpath比Beautiful Soup更省事,省略了一层一层检查元素代码的工作,一般的静态网站压根不是问题。
Xpath爬取58房源信息示例:

技巧四:保存数据
学到这里就比较容易了,主要是对数据的存储和处理,有两种方式:
小规模数据可以使用txt文件、json文件、csv文件等方式来保存文件。
大规模数据就需要使用数据库了像mysql,mongodb、redis等,就比较方便查询管理。
这一块掌握主流的MongoDB 就可以了,可以方便你去存储一些非结构化的数据,比如各种评论的文本,图片的链接等等。
以上这些核心技巧Python都有相应的库帮你去做,你只需要知道如何去应用它们,掌握精通每一部分的一到两种方法就可以了。
还想对爬虫了解更多的话继续往下看吧
反爬虫应对
当你能够独自爬取80%以上的网站后,再学点反爬技巧,爬虫之路不会有太大的阻碍。
一般爬虫过程中可能会碰到像奇奇怪怪的验证码、被封IP(例如豆瓣和github,在检测到某一客户端频繁访问后,会直接封锁ip)、userAgent访问限制、动态数据加载、加密数据等这种反爬虫的手段。
简单一点的根据User-Agent过滤,例如知乎,我们只需要设置为和浏览器相同即可。常规的解决办法通常有比如控制访问频率、抓包、反加密字体、验证码OCR处理、使用代理IP池等,简单一点的根据User-Agent过滤,例如知乎,我们只需要设置为和浏览器相同即可。能够掌握常规的反爬技巧,绝大部分的网站爬虫不是问题。
这里需要提示一点的是:不要去挑战某宝的反爬!后果很严重!
如果不满足自己的爬虫效率,觉得爬取速度太慢了,可以去学习爬虫框架scrapy和分布式爬虫。
爬虫框架scrapy:
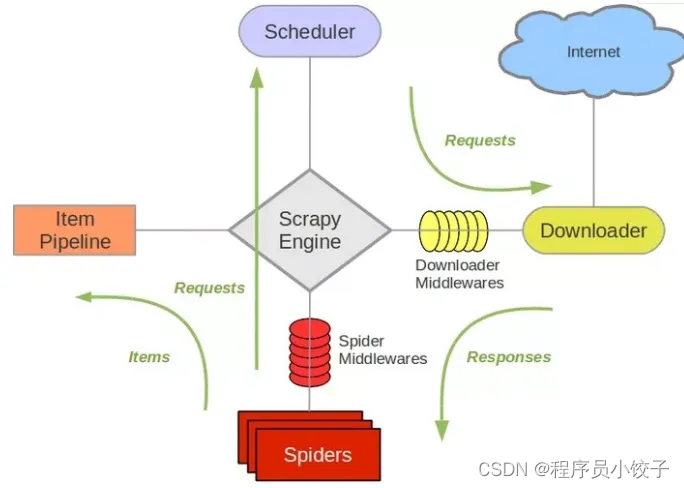
Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试.
Scrapy框架主要由五大组件组成,分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item Pipeline)、Scrapy引擎(Scrapy Engine)。
在复杂的情况下,scrapy框架不仅能够便捷地构建request,还有强大的 selector 能够方便地解析 response,这是一个功能十分强大的爬虫框架,可以实现爬虫工程化和模块化。
分布式爬虫
企业级爬虫,能实现数据的大规模采集,通俗一点来理解就是它可以实现多台电脑使用一个共同的爬虫程序,同时将爬虫任务部署到多台电脑上运行,这样可以提高爬虫速度和效率,需要掌握 Scrapy + MongoDB + Redis 这三种工具。
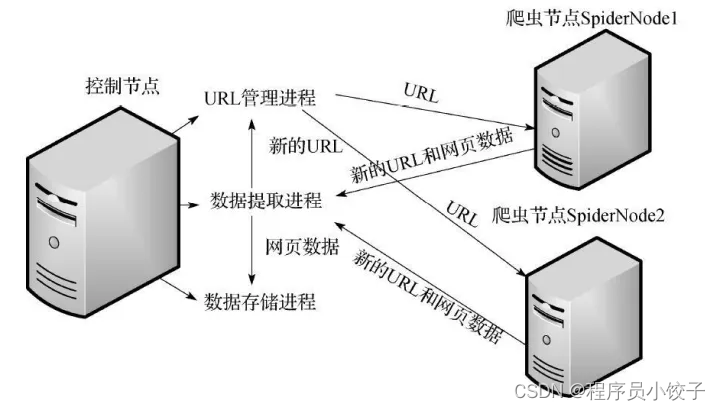
但是分布式爬虫对电脑的CPU和网速都有一定的要求,这个看个人需要,如果你需要用于大规模的数据爬取,分布式爬虫可以帮你解决很多的麻烦。大部分情况下单一爬虫都能满足一般的爬取需要,只是爬取效率比不了分布式爬虫,有条件的可以尝试学学分布式爬虫。
新手小白掌握Python爬虫相对来说是比较简单的,只要大概掌握爬虫的每一步操作原理,能够熟练运用一到两个库就可以实现简单的爬虫,不过还是需要自己多学多练哦!
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。
点此免费领取:CSDN大礼包:《python学习路线&全套学习资料》免费分享
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 836
836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









