







| \s | 匹配任意空白字符 |
| \S | 除单个空白字符(包括Tab键和换行符)以外的所有字符 |
| \d | 匹配数字 |
| \D | 任意非数字 |
| \A | 从字符串开始处开始匹配 |
| \Z | 从字符串结束处开始匹配 |
| \b | 匹配一个单词的边界,单词的分解符通常是空格、标点符号或者换行 |
| \B | 匹配非单词边界 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| () | 被括起来的表达式将作为分组 |
如果想用 点 符号匹配换行符,需要加入参数re.S.
| 限定符 | 功能 | 示例 |
| — | — | — |
| ? | 匹配前边的字符串0次或1次 | hello?world可以匹配hellworld和helloworld |
| + | 匹配前边的字符串1次或多次 | hello+world可以匹配helloworld到hellooooooo…world |
| * | 匹配前边的字符串0次或1次或多次 | hello*world可以匹配hellworld和helloworld到helloooo…world |
| {n} | 匹配前边的字符串n次 | hello{3}world可以匹配helloooworld |
| {n,} | 匹配前边的字符串至少n次 | hello{3,}world可以匹配helloooworld到hellooooo…world |
| {n,m} | 匹配前边的字符串至少n次,至多m次 | hello{3,10}world可以匹配helloooworld到hellooooooooooworld |
[ ]
使用方括号[]
-
[abcdef]表示匹配字母abcdef中的任意一个
-
[a-z]表示匹配任意一个小写字母
-
[A-Z]表示匹配任意一个大写字母
-
[0-9]表示匹配任意一个数字
-
在只考虑英文的情况下,[a-z0-9A-z]则完全等同于\w
-
如果想匹配任意一个汉字,可以用[\u4e00-\u9fa5]
将^符号放在方括号中,表示排除的意思。
[^a-zA-Z]
该表达式用于匹配任何一个不是字母的字符
选择字符使用 | 符号来实现,可以理解为逻辑“或”
|
如 (\d{18}$)|(\d{17}(a|X|x))
此正则表达式表示匹配18位的数字,
或者前17位为数字且第18位为a、X或x 的18位字符
即同python中的转义字符 \ 符号。将特殊字符转化为普通字符。
\
即使用小括号 ( )。
()
=======================================================================================
match()方法从字符串开始处进行匹配,匹配成功则返回Match对象,否则返回None。
re.match(pattern, string, [flags])
-
pattern 模板字符串
-
string 要匹配的字符串
-
flags 可选参数,表示修饰符,用于控制匹配方式,
如设置为I(大写字母I)表示不区分字母大小写,
设为S表示使用 .(点)字符匹配所有字符,包括换行符,
import re
pattern = ‘hello_\w+’ # 表达式字符串
string = ‘Hello_world’ # 要匹配的字符串
match = re.match(pattern, string, re.I) # 匹配字符串,不区分大小写
print(match) # 输出匹配结果
string = ‘abc Hello_world’
match = re.match(pattern, string, re.I) # 匹配字符串,不区分大小写
print(match)
程序运行结果:
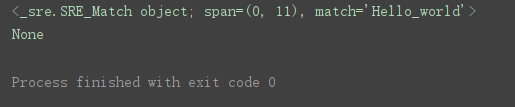
匹配成功后打印出匹配的数据则使用 group() 方法。
result = re.match(pattern, s) # 查看s里面是否有pattern这个数据
如果匹配成功了,就打印匹配的数据
if result:
print(result.group())
else:
print(‘没有匹配到’)
要获取匹配值的开始位置可以使用Match对象的start()方法
要获取匹配值的结束位置可以使用Match对象的end()方法
要获取匹配值匹配位置(开始位置和结束位置)的元组可以使用Match对象的span()方法
要获取匹配的字符串也可以用Match对象的string属性
import re
pattern = ‘hello_\w+’ # 模式字符串
string = ‘HELLO_world’ # 要匹配的字符串
match = re.match(pattern, string, re.I) # 匹配字符串,不区分大小写
print(‘匹配值的起始位置:’, match.start())
print(‘匹配值的结束位置:’, match.end())
print(‘匹配位置的元组:’, match.span())
print(‘要匹配的字符串:’, match.string)
print(‘匹配数据:’, match.group())
程序运行结果:
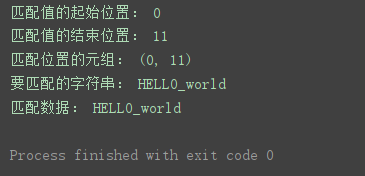
上边是示例皆在匹配以指定字符串开头的字符串,下边匹配以任意字符串开头的字符串:
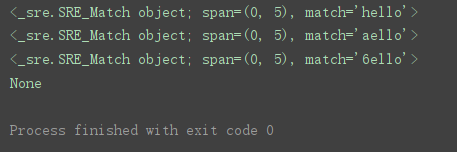
import re # 导入re模块
pattern = ‘.ello’ # 表达式
match = re.match(pattern, ‘hello’) # 匹配字符串
print(match) # 打印匹配结果
match = re.match(pattern, ‘aello’) # 匹配字符串
print(match)
match = re.match(pattern, ‘6ello’) # 匹配字符串
print(match)
match = re.match(pattern, ‘ello’) # 匹配字符串
print(match)
程序运行结果:
如果想匹配多个字符串:
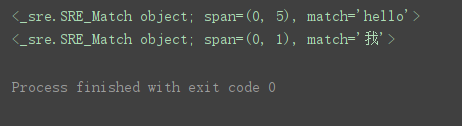
import re # 导入re模块
pattern = ‘hello|我’ # 表达式,表示需要匹配“hello”或“我”开头的字符串
match = re.match(pattern, ‘hello word’) # 匹配字符串
print(match) # 打印匹配结果
match = re.match(pattern, ‘我爱Python’) # 匹配字符串
print(match)
程序运行结果:
如果想要获取匹配的部分内容
import re # 导入re模块
表达式,“hello”开头,“\s”中间空格,“(\w+)”分组后面所有字母、数字以及下划线数据
pattern = ‘hello\s(\w+)( abc)’
match = re.match(pattern, ‘hello world abc’) # 匹配字符串
print(match) # 打印匹配结果
print(match.group()) # 打印所有匹配内容
print(match.group(0))
print(match.group(1)) # 打印分组指定内容
print(match.group(2))
程序运行结果:
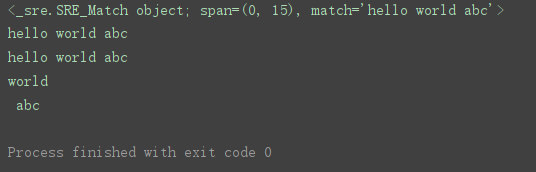
从中可以看出,group()方法默认参数为0,默认输出匹配的所有内容,如果参数为1,则输出第一个分组匹配到的部分,参数为2则输出第二个分组匹配到的部分,以此类推。(不同于一般的索引从0开始的规则)
匹配指定首位的字符串
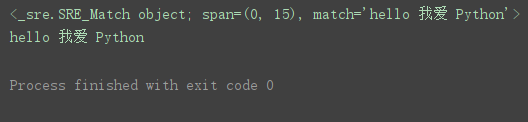
import re # 导入re模块
表达式,h开头,n$表示n结尾
pattern = ‘h\w+\s[\u4e00-\u9fa5]+\s\w+n$’
match = re.match(pattern, ‘hello 我爱 Python’) # 匹配字符串
print(match) # 打印匹配结果
print(match.group()) # 打印所有匹配内容
程序运行结果:
__
======================================================================================
search()方法用于在整个字符串中搜索第一个匹配的值,如果在第一匹配位置匹配成功,则返回Match对象,否则返回None。
re.search(pattern, string, [flags])
-
pattern 模板字符串
-
string 要匹配的字符串
-
flag 可选参数,修饰符
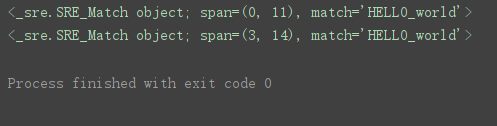
获取第一匹配值
import re
pattern = ‘hello_\w+’ # 模式字符串
string = ‘HELLO_world’ # 要匹配的字符串
match = re.search(pattern, string, re.I) # 搜索字符串,不区分大小写
print(match) # 输出匹配结果
string = ‘abcHELLO_world’
match = re.search(pattern, string, re.I) # 搜索字符串,不区分大小写
print(match) # 输出匹配结果
程序运行结果:
可选匹配
(即针对有的部分可有可无的情况)
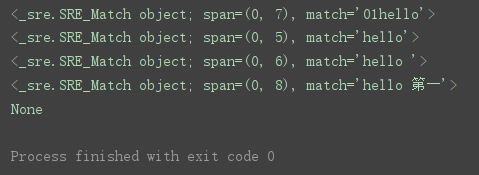
表达式’(\d?)+hello\s?([\u4e00-\u9fa5]?)+'分析:
?表示0次或1次,+表示一次或多次,?+在一起表示0次到任意次。
(\d?)+则表示多个数字可有可无,
\s?表示0个或1个空格,
([\u4e00-\u9fa5]?)+多个汉字可有可无
import re # 导入re模块
pattern = ‘(\d?)+hello\s?([\u4e00-\u9fa5]?)+’
match = re.search(pattern, ‘01hello’)
print(match)
match = re.search(pattern, ‘hello’)
print(match)
match = re.search(pattern, 'hello ')
print(match)
match = re.search(pattern, ‘hello 第一’)
print(match)
match = re.search(pattern, ‘ello 第一’)
print(match)
程序运行结果:
匹配字符串边界
\b用于匹配字符串边界,分界符通常是空格,标点符号或者换行,以及要匹配的字符串本身的两端的两个位置即便没有任何符号但也是边界
import re
pattern = r’\bhe\b’
match = re.search(pattern, ‘hello’) # 无右边界,不匹配
print(match)
match = re.search(pattern, ‘he llo’) # 左边是字符串最左端,右边是空格,匹配成功
print(match)
match = re.search(pattern, ’ hello ') # 左边是最左端,右边不是边界,不匹配
print(match)
match = re.search(pattern, ‘he.llo’) # 左边是最左端,右边是一个点符号,匹配成功
print(match)
程序运行结果:
__
========================================================================================
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









