







文章目录
-
摘要
-
mobilenetv2简介
-
- 线性瓶颈
-
倒残差
-
ONNX
-
TensorRT
-
项目结构
-
训练
-
- 数据增强Cutout和Mixup
-
导入包
-
设置全局参数
-
图像预处理与增强
-
读取数据
-
设置模型
-
定义训练和验证函数
-
测试
-
模型转化及推理
-
- 转onnx
-
onnx推理
-
转TensorRT
-
TensorRT推理
=============================================================
本例提取了植物幼苗数据集中的部分数据做数据集,数据集共有12种类别,演示如何使用pytorch版本的mobilenetv2图像分类模型实现分类任务。将训练的模型转为onnx,实现onnx的推理,然后再将onnx转为TensorRT,并实现推理。
通过本文你和学到:
1、如何从torchvision.models调用mobilenetv2模型?
2、如何自定义数据集加载方式?
3、如何使用Cutout数据增强?
4、如何使用Mixup数据增强。
5、如何实现训练和验证。
6、如何使用余弦退火调整学习率。
7、如何载入训练的模型进行预测。
8、pytorch转onnx,并实现onnx推理。
9、onnx转TensorRT,并实现TensorRT的推理。
希望通过这篇文章,能让大家对图像的分类和模型的部署有个清晰的认识。
========================================================================
mobileNetV2是对mobileNetV1的改进,是一种轻量级的神经网络。mobileNetV2保留了V1版本的深度可分离卷积,增加了线性瓶颈(Linear Bottleneck)和倒残差(Inverted Residual)。
MobileNetV2的模型如下图所示,其中t为瓶颈层内部升维的倍数,c为特征的维数,n为该瓶颈层重复的次数,s为瓶颈层第一个conv的步幅。
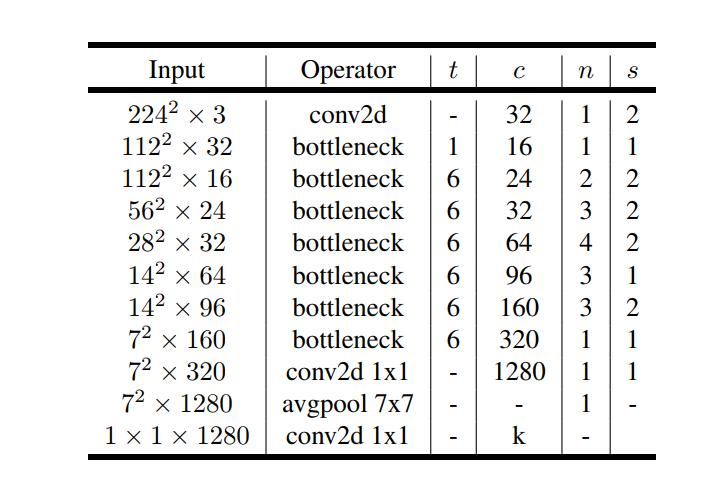
除第一层外,整个网络中使用恒定的扩展率。 在实验中,发现在 5 到 10 之间的扩展率会导致几乎相同的性能曲线,较小的网络在扩展率稍低的情况下效果更好,而较大的网络在扩展率较大的情况下性能稍好。
MobileNetV2主要使用 6 的扩展因子应用于输入张量的大小。 例如,对于采用 64 通道输入张量并产生具有 128 通道的张量的瓶颈层,则中间扩展层为 64×6 = 384 通道。
对于mobileNetV1的深度可分离卷积而言, 宽度乘数压缩后的M维空间后会通过一个非线性变换ReLU,根据ReLU的性质,输入特征若为负数,该通道的特征会被清零,本来特征已经经过压缩,这会进一步损失特征信息;若输入特征是正数,经过激活层输出特征是还原始的输入值,则相当于线性变换。
瓶颈层的具体结构如下表所示。输入通过1的conv+ReLU层将维度从k维增加到tk维,之后通过3×3conv+ReLU可分离卷积对图像进行降采样(stride>1时),此时特征维度已经为tk维度,最后通过1*1conv(无ReLU)进行降维,维度从tk降低到k维。

残差块已经在ResNet中得到证明,有助于提高精度构建更深的网络,所以mobileNetV2也引入了类似的块。经典的残差块(residual block)的过程是:1x1(降维)–>3x3(卷积)–>1x1(升维), 但深度卷积层(Depthwise convolution layer)提取特征限制于输入特征维度,若采用残差块,先经过1x1的逐点卷积(Pointwise convolution)操作先将输入特征图压缩,再经过深度卷积后,提取的特征会更少。所以mobileNetV2是先经过1x1的逐点卷积操作将特征图的通道进行扩张,丰富特征数量,进而提高精度。这一过程刚好和残差块的顺序颠倒,这也就是倒残差的由来:1x1(升维)–>3x3(dw conv+relu)–>1x1(降维+线性变换)。
结合上面对线性瓶颈和倒残差的理解
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









