






1,hive概述
Hive是基于Hadoop的数据仓库,用于处理结构化的数据集,数据结构存在于MySQL,数据存在 HDFS。Hive可以将一个类似于sql的查询语句(HQL)翻译成MR程序,将job提交给HDFS进行查询 时,hive把HDFS上的一个目录映射成一张Hive表,在查询的时候就是把job放 在HDFS上处理该文件。
Hive最适合用于数据仓库程序,使用该应用程序是进行静态数据分析,不需要快速响应结果,而且数据 本身不会频繁变化,其设计的目的是为了精通sql但是对Java编程相对较弱的分析师能够对存在于HDFS上的大规模数据快速的执行查询。
2,数据库操作
Hive中数据库的概念本质上是表的一个目录或命名空间 如果用户没有显式指定数据库,那么就会使用默认的数据库default
2.1,创建数据库
在启动hive之后,输入如下指令就可以创建数据库。
create database 数据库名;出现OK即为成功:

但是如果这个数据库存在的情况下使用这个指令就会报错,所以一般情况下可以使用如下指令来创建数据库,如果数据库已经存在,不会报错,但是也不会覆盖之前的数据库
create database if not exists 数据库名;2.2,查询数据库
show databases;执行结果如下图所示:

除此之外,还可以使用like配合正则表达式进行数据库的筛选,例如:
show databases like 'y.*';//查询名字以y开头的数据库
hive会为每一个数据库创建一个目录,数据库中的表将会以这个数据库目录的子目录形式存储。有 一个例外:default数据库中的表,因为这个数据库本身就没有自己的目录。
2.3,删除数据库
drop database 数据库名;默认情况下,hive不允许用户删除一个包含着表的数据库,如果删除一个包含表的数据库,会报异常,所以如果要删除数据库,需要先删除表,再删除数据库。 可以通过关键字 cascade 强制删除数据库,这样可以使hive自行删除数据库中的表:
drop database 数据库名 cascade;如果为了避免因数据库不存在而报异常信息,可以通过以下命令:
drop database if exists 数据库名;2.4,选中数据库
use 命令可以将某个数据库设置为当前用户使用的工作数据库,格式:
use 数据库名;3,表操作
3.1,创建表
建表语句遵循SQL语法:
create table [if not exists]
数据库名.表名(
字段1 字段类型,
字段2 字段类型,
...
)
[row format delimited fields terminated by '字段分隔符'];以上命令中,可以通过 数据库名.表名 的方式来指定表所在的数据库; 用户可以增加可选项 if not exists ,即使表已经存在,也会忽略后面的执行语句而不会有异常信息。这种方式一般常用与第一个执行时需要创建表的脚本中。 后面的 row format delimited fields terminated by '字段分隔符' 是可选的,用于指定数据文件中字段的分隔符的。
拷贝一张已经存在的表:
create table if not exists 新表名 like 已存在的表名;但是这种方式只会复制表的结构,不会拷贝数据。
3.2,查看表
查看正在使用的数据库中的所有表:
show tables;查看指定数据库下的表:
show tables in 数据库名;查看表结构:
desc 表名;3.3,内部表与外部表
内部表:先在hive中创建一个表,然后向这个表中插入数据(insert、外部文件导入),这样的表称之为内部表 对于内部表,Hive控制数据的生命周期,Hive默认情况下会将这些数据存在HDFS的/hive/warehouse 目录下,当我们删除一个内部表时,Hive也会删除表中数据。
首先在Linux上创建一个txt文件,文件内容如下:
1 喜羊羊
2 美羊羊
3 懒羊羊
4 沸羊羊
5 暖羊羊
6 灰太狼
7 红太狼创建内部表:
创建表:
create table yangc(id int,name string) row format delimited fields terminated by ' ';导入数据:
load data local inpath '/home/software/apache-hive-2.3.6-bin/test/yangcun.txt' into table yangc;
///home/software/apache-hive-2.3.6-bin/test/yangcun.txt是Linux下yangcun.txt的路径
外部表:假设HDFS上已经有数据了,此时我们通过hive创建一张表来管理这个文件数据,此时,这个表被称为外部表,对于外部表,Hive并不完全拥有这份数据,因此,如果在Hive中删除了对应的外部表,并不会删除数据,不过表的元数据信息会被删除掉。
创建外部表:
将此文件上传到HDFS的/hivetest目录下:
hdfs dfs -put yangcun.txt /hivetest/yangcun.txt
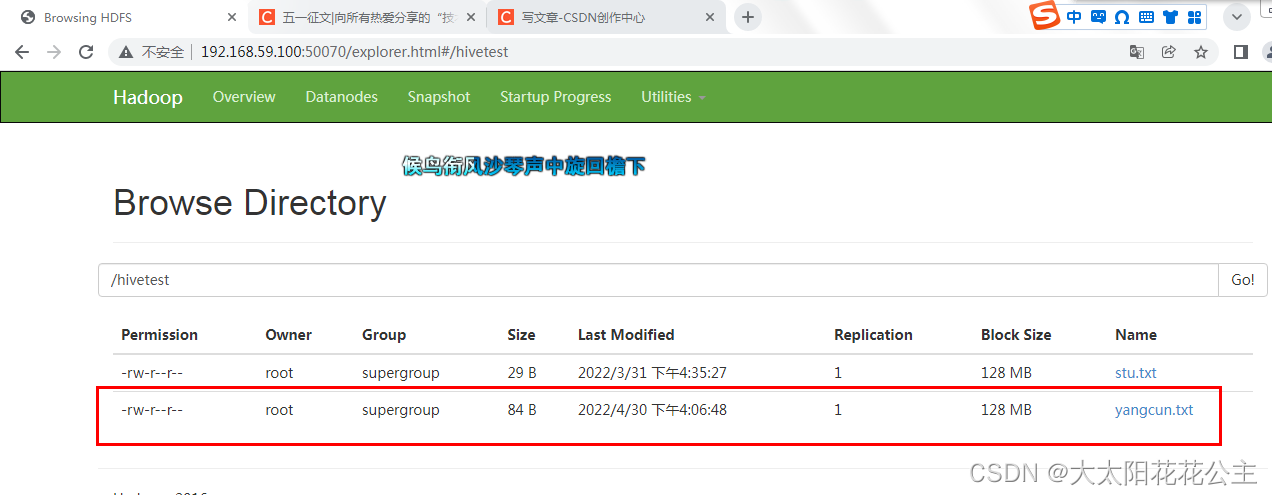
制令执行完成后我们就可以打开浏览器查看hivetest下有了一个yangcun.txt
在hive上创建外部表:
create external table yangcun(id int,name string) row format delimited fields
terminated by ' ' location '/hivetest';穿插一个小知识点:
这里是把hivetest目录下的所有文件的内容插入到表中,所以如果该目录下有其他的文件的话,需要新建一个目录再将文件上传至该目录下。这里由于我的疏忽,将hivetest目录下的txt文件里的内容全插入到yangcun表中,所以我需要删除原有的yangcun表和hivetest下的yangcun.txt,在hivetest下创建新的目录并上传文件。重新将数据导入到新的表中。
HDFS下删除文件:
hdfs dfs -rm /hivetest/yangcun.txtHDFS下创建目录
hdfs dfs -mkdir -p /hivetest/yc执行结果如下:

创建新的yangcun表:
create external table yangcun(id int,name string) row format delimited fields terminated by ' ' location '/hivetest/yc';
内部表和外部表的区别:
1.建表命令
内部表:create table ...
外部表:create external table ... location '文件所在的路径'
2.删除表
对于内部表,删除时会把表的元数据和数据一并删除
对于外部表,删除时会删除元数据,但是不删除源数据
3.4,修改表
重命名:
alter table 原表名 rename to 新表名;给表增加新字段
alter table 表名 add columns(age int);更改字段 更改字段名、数据类型、位置
alter table student3 change age hobby string;
//将student表的age字段改为hobby,类型为string。3.5,删除/清空表
删除表的时候,如果是内部表,会将元数据和源数据都删除;如果是外部表,只删除元数据,而不删除源数据。
删除表:
drop table 表名;清空表:
truncate table 表名;














 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









