








目录
为什么学习JVM?
-
面试的需要,学习理解更高层次的内容的需要
-
架构级别的需要
JVM概述
作用:把一套程序,可以在不同的平台上运行,可以实现内存管理,自动的垃圾回收功能。
-
类加载系统
负责从硬盘上加载字节码文件
-
运行时数据区
存储运行时数据的,分为5大区:
方法区、堆、虚拟机栈、本地方法栈、程序计数器
-
执行引擎
负责将字节码解释或编译为真正的机器码
-
本地方法接口
负责调用操作系统本地方法。
简图

详细图

垃圾回收功能
类加载系统
什么是类加载?
字节码存储在硬盘上,需要的时候运行,由类加载系统负责将类的信息加载到内存中(方法区),为每个类创建一个Class对象,使用的是ClassLoader进行加载,ClassLoader充当一个快递员角色。
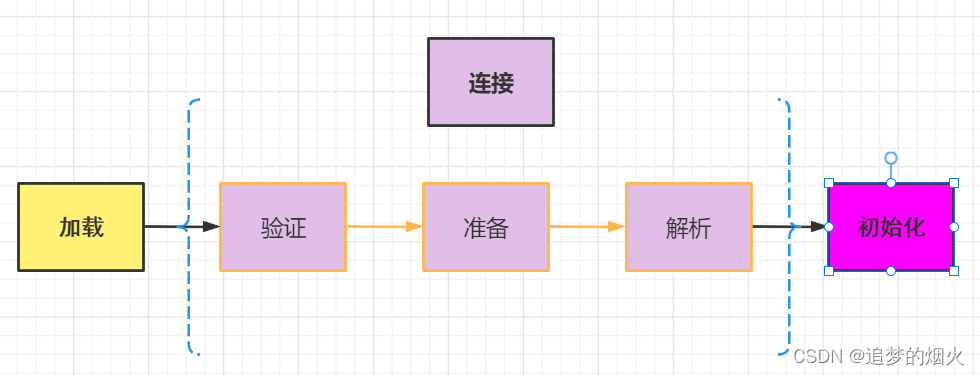
类加载过程
1. 加载
将硬盘上的字节码文件加载到内存中,生成此类的Class对象,将硬盘上的结构转为内存结构。
2. 链接
验证
- 验证字节码格式,是否被修改(污染)验证类的结构是否是否正确。
- 验证语法,例如类是否继承final的类...,这个类是否有父类。
准备
在准备阶段将类中的静态变量赋予初始值。
不包含用 final 修饰的 static 常量,在编译时进行初始化。
例如:
public static int num = 123;
在准备阶段:num = 0;
在后面初始化阶段:num = 123;
在准备阶段不为静态的常量进行赋值。
static final int sum = 100; 在编译期间赋值
public class ClassInit {
static int num = 10; //准备阶段为静态的变量赋默认值 0 初始化阶段赋值10
static final int sum = 100;//static final 在编译期间赋值
int age =10;
//静态代码块
static {
System.out.println("aaaaa");//随着类的加载而加载
}
}
public class TestClassInit {
public static void main(String[] args) {
System.out.println(ClassInit.sum);//当我们仅仅的只访问了类中静态常量,发现类并没有被加载(jvm的优化)
System.out.println(ClassInit.num);//访问静态变量 是要加载类 整个流程都会执行
}
}
执行结果:

解析:
将符号引用(Class文件中的逻辑引用)转为直接引用(内存中的实际地址)
3. 初始化
对类中的静态成员进行赋值
类什么时候进行初始化?
- new 对象
- 访问某个类或接口的静态变量
- 调用类的静态方法
- 反射动态加载类(Class.foeName(""))
- 子类被加载(父类也被加载)
特殊地,只访问类中某个静态变量
一般的 初始化顺序为:父类static ----> 子类static ----> 父类构造方法 ----> 子类构造方法
(1) 先进行准备(静态变量默认值为0),再执行初始化(先执行静态变量赋值,再执行静态代码块)
public class ClassInit {
static int num = 10; //准备阶段为静态的变量赋默认值 0 初始化阶段赋值10
//静态代码块
static {
System.out.println("aaaaa");//随着类的加载而加载
num = 20;
}
public static void main(String[] args) {
// num 从准备到初始化值变化过程 num = 0 ---> num = 10; ---> num = 20;
System.out.println(ClassInit.num);
}
}
(2) 先进行准备(静态变量默认值为0),再执行初始化(先执行静态代码块,再执行静态变量赋值)
public class ClassInit {
//静态代码块
static {
System.out.println("aaaaa");//随着类的加载而加载
num = 20;
}
static int num = 10; //准备阶段为静态的变量赋默认值 0 初始化阶段赋值10
public static void main(String[] args) {
// num 从准备到初始化值变化过程 num = 0 ---> num = 20; ---> num = 10;
System.out.println(ClassInit.num);
}
}执行结果:
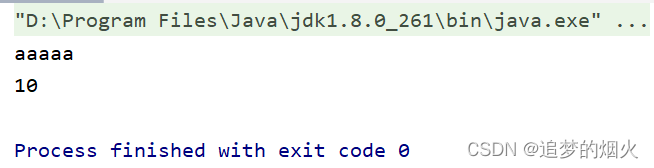
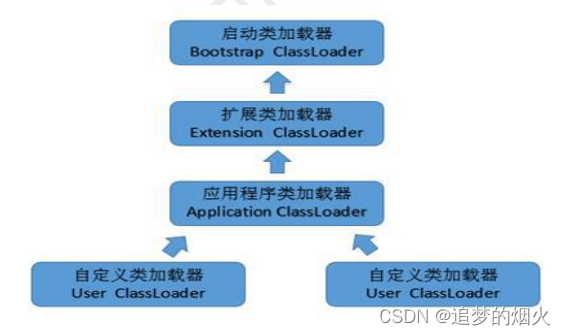
类加载器
站在JVM角度上:
启动类加载器(引导器加载器):这部分不是用java语言写的。
其他类加载器:这部分指的是用java语言写的类加载器。
从程序员的角度上:
启动类加载器:负责加载java的核心类库。默认负责加载%JAVA_HOME%lib下的jar包和class文件
扩展类加载器:负责加载\jre\lib\ext 目录下的类,包含应用程序类加载类加载器。负责加载%JAVA_HOME%/lib/ext文件下的jar包和class类。
应用程序类加载器:负责加载自己写的程序中的类。负责加载classpath下的类文件。
通过一个简单的代码说明类加载器的关系:
public class ClassLoaderDemo extends ClassLoader{
public static void main(String[] args) {
/*
* 启动类加载器:null
* 由于底层基于C++实现,所以返回null.因为Object类位于rt.jar包中,由启动类加载器进行加载.
*/
/*ClassLoader classLoader = String.class.getClassLoader();
System.out.println(classLoader);*/
System.out.println(String.class.getClassLoader());
/*
* 应用程序类加载器: sun.misc.Launcher$AppClassLoader@18b4aac2
* 对于自定义的类,如Test.java。默认都是应用程序类加载器
*/
ClassLoader classLoader1 = ClassLoaderDemo.class.getClassLoader();
System.out.println(classLoader1);
/*
* 扩展类加载器:sun.misc.Launcher$ExtClassLoader@1540e19d
* 应用程序类加载器的父类是扩展类加载器
*/
System.out.println(classLoader1.getParent());
/*
* 启动类加载器:null
* 扩展类加载器的父类是启动类加载器
*/
System.out.println(classLoader1.getParent().getParent());
}
@Override
public Class<?> loadClass(String name) throws ClassNotFoundException {
return super.loadClass(name);
}
}
运行结果:

双亲委派机制
问题:假如我们自己定义一个String类(在自己定义的java.lang包中),原来的Java中的java.lang包存在这个类,会将Java中的String类替换掉吗?
为了确保类加载的正确性、安全性,在加载类时采用双亲委派机制,当需要加载程序中一个类时,会先让加载器的父级去加载,直到最顶级的启动类加载器,如果父级找到了返回使用,如果依然没有找到,那就会委派给子类去加载,找到了就返回,如果所有的类加载器都没有找到,就报类找不到异常(抛出ClassNotFound 异常)。

package java.lang;
public class String {
public String(){
System.out.println("自定义的String");
}
}public class TestClassInit {
public static void main(String[] args) {
new java.lang.String();
}
}运行结果:

优点:
- 安全,避免自己写的类替换了系统中的类
- 避免类的重复加载
如何打破双亲委派机制?
java中提供了一个ClassLoader类。定义哪些方法可以加载类。
如:
- loadClass(String classpath):底层使用双亲委派机制加载类
- findClass(String classpath) :如果需要自定义,可以重写findClass()
- defineClass():将读到class文件的数据,构造出一个Class的对象
- 再有就像tomcat这种服务器软件,里面会自定义加载器。
- JDBC就打破了双亲委派机制。它通过Thread.currentThread().getContextClassLoader()得到线程上下文加载器来加载Driver实现类。因为JDBC只提供了接口,并没有提供实现。
类何时加载?
主动使用:
new 对象;调用某个类的静态变量、静态方法;反射动态调用;子类被加载(首先父类被加载)
被动使用:不会加载初始化
访问类中的静态常量 代码如下:
public class ClassInit {
static final int sum = 100;//static final 在编译期间赋值
static {
System.out.println("aaaaa");//随着类的加载而加载
num = 20;
}
static int num = 10; //准备阶段为静态的变量赋默认值 0 初始化阶段赋值10
}
public class TestClassInit {
public static void main(String[] args) {
System.out.println(ClassInit.sum);//当我们仅仅的只访问了类中静态常量,发现类并没有被加载(jvm的优化)
}
}
将类作为类型,例如,创建数组,用类作为类型使用;代码如下:
public class TestClassInit {
public static void main(String[] args) {
ClassInit[] classInits = new ClassInit[10];
}
}执行结果:

运行时数据区
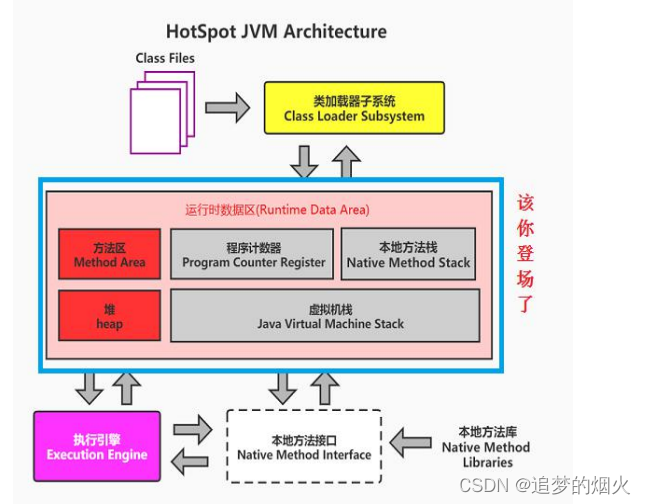
程序计数器:记录线程运行的位置(行号),线程需要记录程序执行的位置。
虚拟机栈:运行Java方法的区域,每个方法生成一个栈桢。
本地方法栈:java经常需要调用一些本地方法。
操作系统的方法:例如,hashCode() --- Object类中的;read() --- IO流;start() --- 线程启动; arraycopy() --- 数组复制等
堆:存放程序中产生的对象,也是虚拟机中内存占比最大的一块。
方法区: 存放类的信息。

堆、方法区:线程共享的。
程序计数器虚拟机栈、本地方法栈:线程私有的,线程独立的
堆、方法、栈:会出现内存溢出错误。
程序计数器
是一块内存很小的区域,主要用来记录每个线程中执行的的位置,便于线程在切换执行时记录位置,是线程私有的,生命周期与线程一样。运行速度快,不会出现内存溢出。
虚拟机栈
栈是运行单位,存储一个一个的方法,当调用一个方法的时候,创建一个栈桢,将方法中的信息存储到栈桢。
操作只有两个:调用方法,入栈;方法执行完成后,出栈,先进后出的结构。
运行速度非常快,仅次于程序计数器,当入栈的方法过多时,会出现栈溢出。
栈桢的内部结构:
局部变量池:方法内声明的局部变量,方法参数。
操作数栈:运算区域。 a+b
动态链接:调用的方法地址,字面量地址
方法返回地址
本地方法栈
本地方法:native 修饰的方法,没有方法体。本地方法不是用java语言写的,例如操作系统方法。
如果调用本地方法,那么本地方法在本地方法栈中运行,也会出现内存溢出。
堆内存
创建对象 内存引用
堆空间是JVM内存中的一块空间,主要用来存储对象,是JVM中空间最大的块,是线程共享的。
JVM启动,堆内存就创建了,大小确定了,但是可以通过参数改变大小,这就是我们所说的JVM调优。
在物理上是不联系的,逻辑上是联系的,堆是垃圾回收的重点区域。
堆的分区?
创建的对象在这些区域中如何分布?
新生代:伊甸园区、幸存者1区、幸存者2区
老年代

为什么要分区?
不同的对象,它的生命周期不同,这样可以将不同的对象存储在不同的区域,不同的区域采用不同的垃圾回收算法,扬长避短。
创建的对象在这些区域是如何分布的?
当一个对象刚刚新创建后,会被存放到伊甸园去,当垃圾回收时,会把伊甸园区中存活下来的对象,移动到幸存者区。
幸存者有两个区域:幸存者1区和幸存者2区。首先将伊甸园存活的对象放到幸存者1区,当下一次垃圾回收到来时,会把伊甸园区和幸存者1区存活下来的对象放到幸存者2区中,清空幸存者1区,之后再次回收时,把伊甸园区和幸存者2区存活下来的对象放到幸存者1区中,清空幸存者2区,交替执行下去。
什么时候将对象移动到老年区?
垃圾回收的时候每次都会对对象进行标引,在对象头中有一块空间用来记录被标引的次数,在对象头中记录分代年龄,只有4个bit位空间,只能记录15次。在到达16次的时候,会将对象移到老年代。
在对象头中,它是由 4 位数据来对 GC 年龄进行保存的,所以最大值为 1111, 即为 15。所以在对象的 GC 年龄达到 15 时,就会从新生代转到老年代
注:若养老区执行了 Major GC 之后发现依然无法进行对象保存,就会产生 OOM 错误. Java.lang.OutOfMemoryError:Java heap space
例如:
public class Demo {
public static void main(String[] args) {
List<Integer> list = new ArrayList();
while(true){
list.add(new Random().nextInt());
}
}
}执行结果:

堆空间的比例
新生代与老年代的比例为 1 : 2,可以通过参数(-XX:NewRatio)进行设置。
伊甸园和幸存者1区、幸存者2区比例:8:1:1,也可以通过参数(-XX:SurvivorRatio)进行设置。
一个对象要经过15次的垃圾回收依然存活移动到老年区,可以通过参数进行设置,设置最大为15次。

分代收集思想
JVM垃圾回收可以分为不同的区域进行回收,针对新生代进行频回收,称为young GC。较少的回收老年代,称为old GC,当调用System.gc(),老年代内存不足;方法区空间不足的时候会触发,称为Full GC(整堆回收)。在开发的过程中,我们尽量避免整堆回收,因为他会导致其他用户线程暂停的时间较长。
字符串常量池
字符串常量池的位置为什么调整?
jdk7之后将字符串常量池的位置由方法区转移到堆中,因为方法区只用触发了FULL GC时才会进行回收,回收的效率低,所以将字符串常量池转移到堆中,提高垃圾回收效率。
public static void main(String[] args) {
String temp = "world";
for (int i = 0; i < Integer.MAX_VALUE; i++) {
String str = temp + temp;
temp = str;
str.intern();//将字符串存储到字符串常量池中
}
}执行结果:

方法区
目的:存储类信息的区域
类信息:方法、属性、静态常量、静态变量,即时编译后的代码。运行时常量池(字面量值)
方法区是线程共享的,也可能会出现内存溢出,也会涉及垃圾回收。
方法区的生命周期也是虚拟机,启动就创建,虚拟机关闭销毁。

方法区设置大小
方法区会涉及垃圾回收的
主要回收的是静态常量类信息。
类信息何时被卸载?
满足三个条件进行回收:
-
该类产生的对象都被回收了
-
该类对应的Class对象不再被其他地方引用
-
该类对应的类加载器也被回收了
本地方法接口
通过本地方法接口模块与操作系统接口进行访问。
什么是本地方法?
使用native修饰的方法,不是java语言实现的,是操作系统实现的。
为什么要使用Native Method?
-
例如需要获取硬件的一些信息,如内存地址,启动线程IO,调用本地方法,接口就很方便
-
JVM底层进行字节码解释或编译部分也有C语言实现
执行引擎
作用:负责装载字节码文件到执行引擎中,字节码不是机器码,只是JVM规范中定义的指令码,执行引擎需要将字节码解释/编译为不同平台识别的机器码。
解释器:JVM运行程序时,逐行对字节码指令进行翻译、效率低
JIT(即时)编译器:对某段代码整体编译后执行,效率高,编译需要耗费一定的时间。
为什么是半解释型半编译型?
起初Java中只提供了解释执行的方式,但是解释执行效率低。后来引入编译器,可以对程序执行中的热点代码进行编译,并把编译后的内容缓存起来,后期执行效率高。
热点代码采用计数器方法来记录。
程序启动后可以通过解释器立即对代码进行解释执行,不需要等待编译,提高响应速度,之后对热点代码采用编译器编译执行,从而提高后续效率。















 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









