






一、K-Means 聚类
目标函数(损失函数)
给定一个含有N个数据点的集合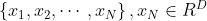 ,聚类目标是将此N个数据点聚类到K个类别中,且假设K值已经给定。
,聚类目标是将此N个数据点聚类到K个类别中,且假设K值已经给定。
- 引入K个D维均值向量,即为第k个类别的聚类中心
- 计算数据点和所有类中心的距离,类中心距离此数据点最近的类别,即为当前数据点的类别
- 根据新的聚类结果,使用当前聚集到各个类别的数据的均值来更新当前类别的聚类中心
- 返回第二步,知道满足一定的停止准则
二、GMM
EM算法的一个重要应用场景就是高斯混合模型的参数估计。高斯混合模型就是由多个高斯模型组合在一起的混合模型(可以理解为多个高斯分布函数的线性组合,理论上高斯混合模型是可以拟合任意类型的分布),例如对于下图中的数据集如果用一个高斯模型来描述的话显然是不合理的。
GMM模型基础
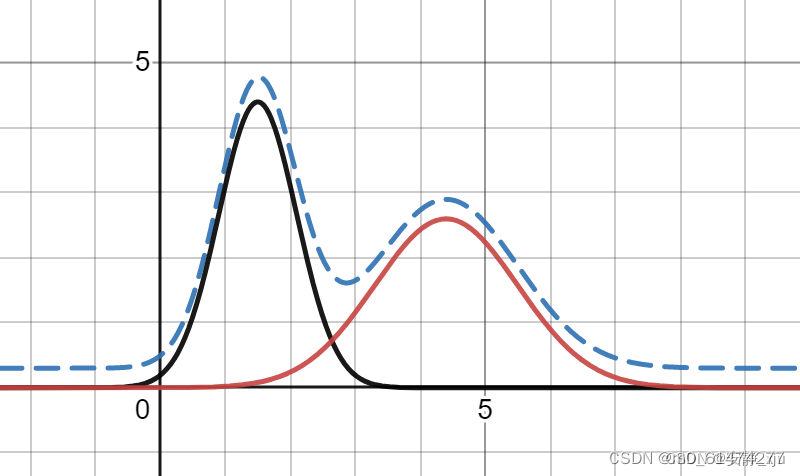
如图所示,红色实线和黑色实现分别为两个独立的高斯模型,蓝色虚线为二者的高斯混合模型。从几何角度来看,高斯混合模型可以看做多个高斯模型的加权平均,即由多个高斯分布叠加而成。
高斯混合模型常用语聚类中(现实中大多数分布都是正态分布,而在聚类中的各个类别可能是分布参数不同的正态分布)。对于高斯模型的应用大致是先随机在这K个模型中任选一个模型(αk是第k个模型被选中的概率,注意在这里的混合模型和集成学习中的模型是不一样的,这里实际应用的只是混合模型中的一个),然后再用这个模型进行预测。而且在用高斯混合模型进行聚类时,混合模型中的模型个数k事实上就是聚类的簇数k。
用EM算法来估计高斯混合模型的参数,在这里参数θ = (α1,α2,...,αk;θ1,θ2,...,θk),在估计之前我们得预先明确隐变量。先假定观测数据yj(j = 1,2,...,N),具体yj的产生过程如下,首先依照概率αk选择第k个高斯分布模型,然后用这个模型生成观测数据yj。在这里观测数据是已知的,而观测数据具体来自哪个模型是未知的(这就和之前提过的三硬币模型是很相似的,知道模型被选择的概率就好比知道选择B,C硬币的概率,但是却不知道本次预测的结果是由B得出的还是C得出的)
三、EM算法
(为什么要使用EM算法,或者说EM算法在什么情况下使用?EM算法就是来代替最大似然估计(对数似然估计)的)“如果我们已经清楚了某个变量服从的高斯分布,而且通过采样得到了这个变量的样本数据,想求高斯分布的参数,这时候极大似然估计可以胜任这个任务;而如果我们要求解的是一个混合模型,只知道混合模型中各个类的分布模型(譬如都是高斯分布)和对应的采样数据,而不知道这些采样数据分别来源于哪一类(隐变量),那这时候就可以借鉴EM算法。EM算法可以用于解决数据缺失的参数估计问题(隐变量的存在实际上就是数据缺失问题,缺失了各个样本来源于哪一类的记录)。”(引号内内容选自CSDN博主:林立民爱洗澡,原文链接:https://blog.csdn.net/lin_limin/article/details/81048411。这个问题讲述的非常清楚,给了我很大帮助)
下面将介绍EM算法的两个步骤:E-step(expectation-step,期望步)和M-step(Ma
期望最大化EM算法的标准形式:
- E-step:来自第j个组份的概率 xij=Qi(zi=j)=p(zi=j|xi;Φ,μ,Σ)xji=Qi(zi=j)=p(zi=j|xi;Φ,μ,Σ)
- S-step:估计每个组份的参数 ∑mi=1∑z(i)Qi(z(i))logP(xi,zi;Φ,μΣ)Qi(z(i))
EM算法过程:
Initilization:
First, choose some initial values for the means , covariances , and mixing coefficients .
E-Step:
Use the current values for the parameters to evaluate the posterior probabilities, or responsibilities ;
M-step:
Re-estimate the means , covariances , and mixing coefficients using the results:
Evaluate the log likelihood
(参考文献:M. Jordan, J. Kleinberg, ect. Pattern Recognition and Machine Learning. 2006)















 3204
3204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









