







一、问题描述
k均值、合并聚类和DBSCAN聚类算法对鸢尾花数据集聚类,并且比较结果。
二、实验目的
学习k均值、合并聚类和DBSCAN聚类算法,并且比较结果。
三、实验内容
3.1数据导入
from sklearn import datasets
iris = datasets.load_iris()
3.2数据预处理
X = iris.data
y = iris.target
3.3算法描述
1.基于划分的聚类,k均值算法。
先选取k个作为中心点,将每个数据样本分配至与其距离最近的中心,使得所有样本到分配到的中心的距离之和最小。分配到同一中心的样本就聚成一类。
class KMeans:
def __init__(self, n_clusters = 1, max_iter = 50, random_state=0):
self.k = n_clusters
self.max_iter = max_iter
np.random.seed(random_state)
def assign_to_centers(self, centers, X):
assignments = []
for i in range(len(X)):
distances = [np.linalg.norm(X[i] - centers[j], 2) for j in range(self.k)]
assignments.append(np.argmin(distances))
return assignments
def adjust_centers(self, assignments, X):
new_centers = []
for j in range(self.k):
cluster_j = [X[i] for i in range(len(X)) if assignments[i] == j]
new_centers.append(np.mean(cluster_j, axis=0))
return new_centers
def fit_transform(self, X):
idx = np.random.randint(0, len(X), self.k)
centers = [X[i] for i in idx]
for iter in range(self.max_iter):
assignments = self.assign_to_centers(centers, X)
centers = self.adjust_centers(assignments, X)
return np.array(centers), np.array(assignments)
2.基于层级的聚类合,并聚类算法。
假设需要将m个数据样本聚为k个类,合并聚类算法聚类时,先将每一个数据样本自成一类,随后每一步都合并距离最近的两个类,直至将m个数据样本聚为k个类为止。
import numpy as np
import heapq
class AgglomerativeClustering:
def __init__(self, n_clusters = 1):
self.k = n_clusters
def fit_transform(self, X):
m, n = X.shape
C, centers = {}, {}
assignments = np.zeros(m)
for id in range(m):
C[id] = [id]
centers[id] = X[id]
assignments[id] = id
H = []
for i in range(m):
for j in range(i+1, m):
d = np.linalg.norm(X[i] - X[j], 2)
heapq.heappush(H, (d, [i, j]))
new_id = m
while len(C) > self.k:
distance, [id1, id2] = heapq.heappop(H)
if id1 not in C or id2 not in C:
continue
C[new_id] = C[id1] + C[id2]
for i in C[new_id]:
assignments[i] = new_id
del C[id1], C[id2], centers[id1], centers[id2]
new_center = sum(X[C[new_id]]) / len(C[new_id])
for id in centers:
center = centers[id]
d = np.linalg.norm(new_center - center, 2)
heapq.heappush(H, (d, [id, new_id]))
centers[new_id] = new_center
new_id += 1
return np.array(list(centers.values())), assignments
3.基于密度的聚类,DBSCAN算法。
算法首先从任意一个样本点开始向外扩充出一个类。扩充的方法类似广度优先搜索算法。算法不断地将样本的ε邻域加入到类中,直到没有新的样本可以加入其中为止。这样就生成了第一个类。然后,算法再任选一个不属于第一个类的样本点,重复上述过程,生成第二个类。如此重复,直到所有的样本点都被归类完毕为止。
class DBSCAN:
def __init__(self, eps = 0.5, min_sample = 5):
self.eps = eps
self.min_sample = min_sample
def get_neighbors(self, X, i):
m = len(X)
distances = [np.linalg.norm(X[i] - X[j], 2) for j in range(m)]
neighbors_i = [j for j in range(m) if distances[j] < self.eps and j != i]
return neighbors_i
def fit_transform(self, X):
assignments = np.zeros(len(X))
plt.figure(-1)
plt.scatter(X[:,0], X[:,1], c = assignments)
plt.show()
assignments[0] = 1
plt.figure(0)
plt.scatter(X[:,0], X[:,1], c = assignments)
plt.show()
n0 = self.get_neighbors(X, 0)
n1 = []
for j in n0:
assignments[j] = 1
n1 += self.get_neighbors(X, j)
plt.figure(1)
plt.scatter(X[:,0], X[:,1], c = assignments)
plt.show()
n2= []
for j in n1:
assignments[j] = 1
n2 += self.get_neighbors(X, j)
plt.figure(2)
plt.scatter(X[:,0], X[:,1], c = assignments)
plt.show()
n3= []
for j in n2:
assignments[j] = 1
n3 += self.get_neighbors(X, j)
plt.figure(3)
plt.scatter(X[:,0], X[:,1], c = assignments)
plt.show()
n4= []
for j in n3:
assignments[j] = 1
n4 += self.get_neighbors(X, j)
plt.figure(4)
plt.scatter(X[:,0], X[:,1], c = assignments)
plt.show()
3.4主要代码
k均值算法
import numpy as np
import matplotlib.pyplot as plt
from k_means import KMeans
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
plt.figure(-1)
plt.scatter(X[:, 0], X[:, 1])
model = KMeans(n_clusters = 3, max_iter = 100)
centers, assignments = model.fit_transform(X)
plt.figure(0)
plt.scatter(X[:, 0], X[:, 1], c = assignments)
plt.scatter(np.array(centers)[:,0], np.array(centers)[:,1], c='r', s=80)
plt.show()
并聚类算法
import numpy as np
import matplotlib.pyplot as plt
from k_means import KMeans
from agglomerative_clustering import AgglomerativeClustering
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
agg = AgglomerativeClustering(n_clusters = 2)
agg_centers, agg_assignments = agg.fit_transform(X)
plt.figure(7)
plt.scatter(X[:,0], X[:,1], c='y')
plt.figure(9)
plt.scatter(X[:,0], X[:,1], c='y')
plt.scatter(agg_centers[:,0], agg_centers[:,1], c='b', marker='*', s=300)
plt.show()
DBSCAN算法
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
class DBSCAN:
def __init__(self, eps = 0.5, min_sample = 5):
self.eps = eps
self.min_sample = min_sample
def get_neighbors(self, X, i):
m = len(X)
distances = [np.linalg.norm(X[i] - X[j], 2) for j in range(m)]
neighbors_i = [j for j in range(m) if distances[j] < self.eps and j != i]
return neighbors_i
def fit_transform(self, X):
assignments = np.zeros(len(X))
plt.figure(-1)
plt.scatter(X[:,0], X[:,1], c = assignments)
plt.show()
assignments[0] = 1
plt.figure(0)
plt.scatter(X[:,0], X[:,1], c = assignments)
plt.show()
n0 = self.get_neighbors(X, 0)
n1 = []
for j in n0:
assignments[j] = 1
n1 += self.get_neighbors(X, j)
plt.figure(1)
plt.scatter(X[:,0], X[:,1], c = assignments)
plt.show()
n2= []
for j in n1:
assignments[j] = 1
n2 += self.get_neighbors(X, j)
plt.figure(2)
plt.scatter(X[:,0], X[:,1], c = assignments)
plt.show()
n3= []
for j in n2:
assignments[j] = 1
n3 += self.get_neighbors(X, j)
plt.figure(3)
plt.scatter(X[:,0], X[:,1], c = assignments)
plt.show()
n4= []
for j in n3:
assignments[j] = 1
n4 += self.get_neighbors(X, j)
plt.figure(4)
plt.scatter(X[:,0], X[:,1], c = assignments)
plt.show()
X, y = make_blobs(n_samples=200, centers=2, random_state=0, cluster_std=0.5)
model = DBSCAN(eps = 0.5, min_sample = 2)
model.fit_transform(X)
plt.show()
四、实验结果及分析
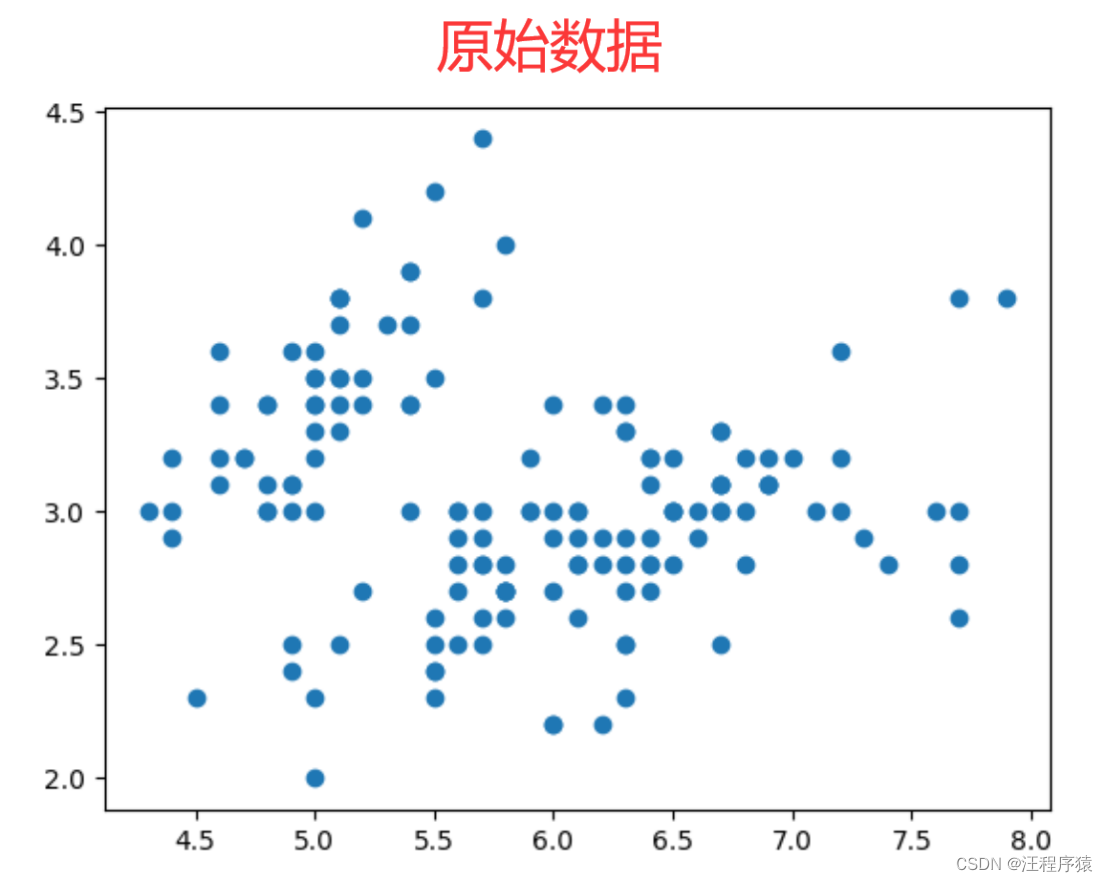
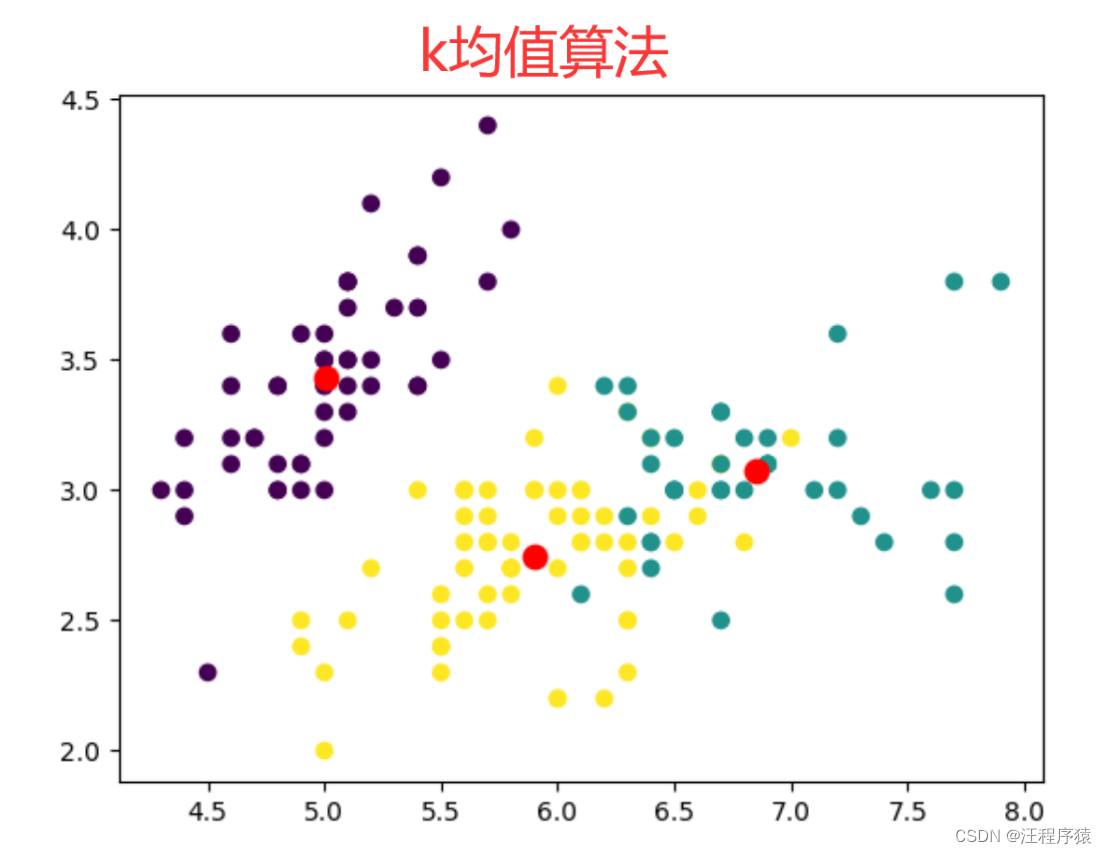

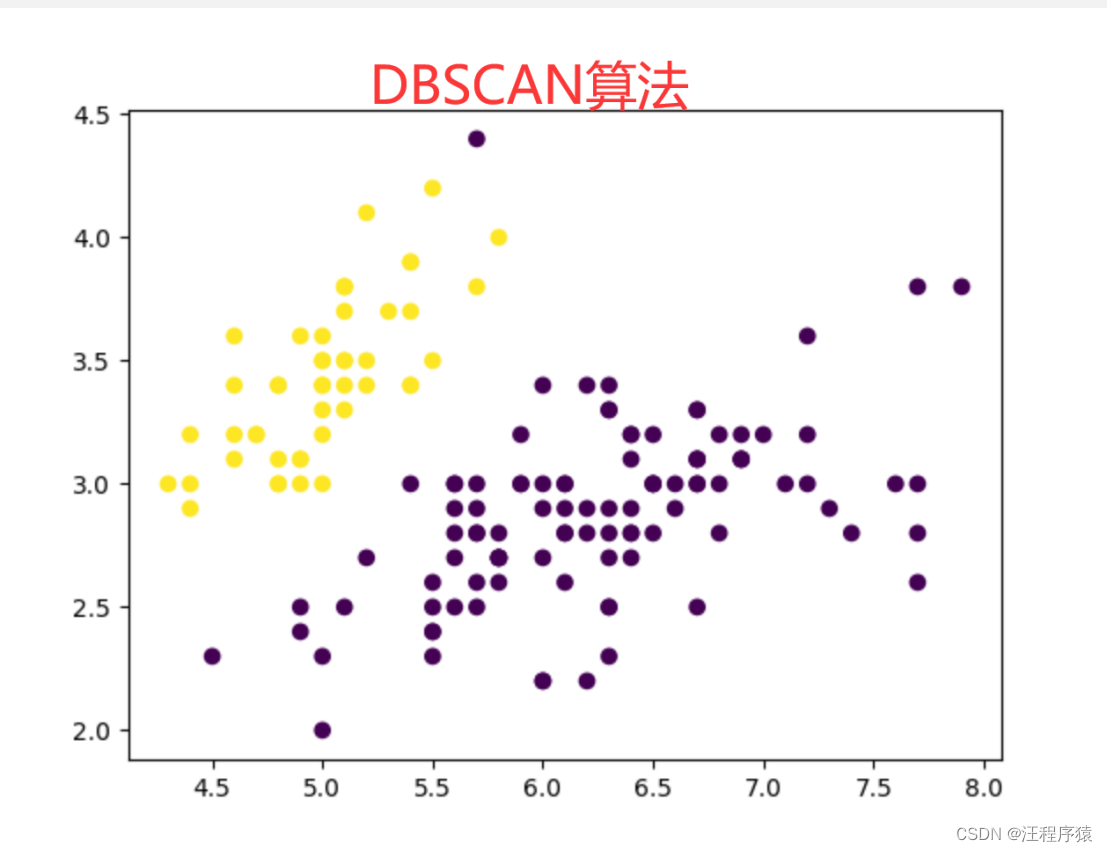
这三个算法所划分的结果是不一样的,因为算法的核心思想不一样。它们是从三个角度进行分类:基于划分的聚类是k均值算法;基于层级的聚类是合并聚类算法;基于密度的聚类:DBSCAN算法。
五、资料下载


















 912
912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











