







RL学习
写在前面:
本专栏是学习由Richard S. Sutton and Andrew G. Barto 所著 《Reinforcement learning》的学习笔记,如有指正请留言。
第一章:Introduction
Reinforcement Learning:
Reinforcement learning is learning what to do—how to map situations to actions—so as to maximize a numerical reward signal. The learner is not told which actions to take, but instead must discover which actions yield the most reward by trying them
强化学习就是去学习做什么能够使得数值化的收益最大化,此时会根据环境选择动作,将环境映射为动作。这
个映射成为策略。
These twocharacteristics—trial-and-error search and delayed reward—are the two most important
distinguishing features of reinforcement learning
强化学习有两个重要特征:试错和延时奖励
试错 是指需要不断地去交互试错从而学习好的策略。
延时奖励 是指需要在做出动作后才能够知道奖励是正奖励还是负奖励(奖励的优劣)
A learning agent must be able to sense the state of its environment to some extent and must be able to take actions that affect the state. The agent also must have a goal or goals relating to the state of the environment. Markov decision processes are intended to include just these three aspects—sensation, action, and goal—in their simplest possible forms without trivializing any of them.
一个学习体必须能够在一定程度上感知环境的状态,并且能够选择动作去影响环境。只能学习体必须有一个目
标或者关于环境状态的目标。马尔科夫链包括三方面:感知,动作,目标,将其以不失本质却简单的过程执行。
强化学习与当前机器学习中使用的监督学习不同:
Supervised learning is learning from a training set of labeled examples provided by a knowledgable external supervisor. Each example is a description of a situation together with a specification—the label—of the correct action the system should take to that situation, which is often to identify a category to which the situation belongs
监督学习是从外界监督者提供的一个被标注的数据集中学习,被标注是指在当前情景,系统所应该执行的动作,
也可以说是对当前状态的一个分类标签。
监督学习的优劣:
The object of this kind of learning is for the system to extrapolate, or generalize, its responses so that it acts correctly in situations not present in the training set. This is an important kind of learning, but alone it is not adequate for learning from interaction. In interactive problems it is often impractical to obtain examples of desired behavior that are both correct and representative of all the situations in which the agent has to act. In uncharted territory—where one would expect learning to be most beneficial—an agent must be able to learn from its own experience
监督学习可以说是培养机器的推断和逻辑能力,从而应对不同的情况,即使这种情况没有出现在之前的训练集
中,但是这种学习方法不适用于交互式的学习。因为在某些领域,我们无法提供准确且有代表性的例子,所以
就需要智能体自己从自己的经验中学习。
强化学习也不同于无监督学习,无监督学习是一种典型的找出未标注数据隐式结构的过程,
强化学习不同于无监督学习的原因:
reinforcement learning is trying to maximize a reward signal instead of trying to find hidden structure
强化学习是为了最大化奖励信号而不是找到隐式的结构。
One of the challenges that arise in reinforcement learning, and not in other kinds
of learning, is the trade-of between exploration and exploitation. To obtain a lot of
reward, a reinforcement learning agent must prefer actions that it has tried in the past
and found to be effective in producing reward. But to discover such actions, it has to
try actions that it has not selected before. The agent has to exploit what it has already
experienced in order to obtain reward, but it also has to explore in order to make better
action selections in the future. The dilemma is that neither exploration nor exploitation
can be pursued exclusively without failing at the task
在强化学习中,有一个需要抉择的问题。需要去权衡 "explore" 和 "exploit"。智能体肯定会更愿意选择一
个已经发现的能给自己带来收益的动作(exploit),可是不去 "explore",无法得到更好的动作。但是二者都无
法在保证不失败的前提下完成。
Another key feature of reinforcement learning is that it explicitly considers the whole problem of a goal-directed agent interacting with an uncertain environment. This is in contrast to many approaches that consider subproblems without addressing how they might fit into a larger picture
强化学习的另一个特点是,作为一个目标导向的智能体,他关注于与未知环境交互的全局性问题,其他研究方
法都关注于子问题,没有考虑子问题置于全局。
Reinforcement learning takes the opposite tack, starting with a complete, interactive, goal-seeking agent. All reinforcement learning agents have explicit goals, can sense aspects of their environments, and can choose actions to influence their environments. Moreover, it is usually assumed from the beginning that the agent has to operate despite significant uncertainty about the environment it faces
强化学习以一种相反方式出发,以一个完整的,交互的,目标导向的智能体出发。每一个智能体都有一个确定的
目标,并且可以感知环境,选择合适的动作影响环境。智能体在一开始就会工作,即使面对的是不确定的环境。
一个例子:
象棋大师下一步棋,是需要预测对手的后几步策略,并且根据局势和所选动作决定的。
All involve interaction between an active decision-making agent and its environment, within which the agent seeks to achieve a goal despite uncertainty about its environment. The agent’s actions are permitted to a↵ect the future state of the environment (e.g., the next chess position), thereby affecting the actions and opportunities available to the agent at later times. Correct choice requires taking into account indirect, delayed consequences of actions, and thus may require foresight or planning.
在例子中,是一个智能体和当前环境的交互。在不确定的环境中实现一个目标。智能体当前的动作都会对未来的
状态有影响,进而影响未来的决策。所以正确的选择应该考虑后续结果,要有远见。
At the same time, in all of these examples the effects of actions cannot be fully predicted;
thus the agent must monitor its environment frequently and react appropriately.
需要时刻监控当前状态(比如关注是否获胜)以此来做出正确的决策。
Elements of Reinforcement Learning
Beyond the agent and the environment, one can identify four main subelements of a
reinforcement learning system: a policy, a reward signal, a value function, and, optionally,
a model of the environment.
除了智能体和环境外,强化学习有四个要素: 策略,奖励信号,价值函数,环境的模型
A policy defines the learning agent’s way of behaving at a given time. Roughly speaking,
a policy is a mapping from perceived states of the environment to actions to be taken
when in those states. It corresponds to what in psychology would be called a set of
stimulus–response rules or associations.
策略是智能体在特定时间的行为,或者说就是从环境到行为的映射,类似于心理学中的刺激-反应过程。
The policy is the core of a reinforcement learning agent in the sense that it alone
is sufficient to determine behavior.
策略能够决定行为,所以是强化学习的核心。
A reward signal defines the goal of a reinforcement learning problem. On each time
step, the environment sends to the reinforcement learning agent a single number called
the reward. The agent’s sole objective is to maximize the total reward it receives over
the long run
奖励信号顶一个强化学习的目标,每一个时间步环境发送给强化学习智能体一个数字叫做奖励,智能体的目标就是最大化长期总收益。收益信号就是用来分辨什么是好的什么行为是坏的。
Whereas the reward signal indicates what is good in an immediate sense, a value
function specifies what is good in the long run. Roughly speaking, the value of a state is
the total amount of reward an agent can expect to accumulate over the future, starting
from that state.
奖励信号可以短时间表示什么是好的什么是坏的,但是价值函数可以表达在长期来看,什么是好的,一个状态的价值,就是智能体从这个状态开始对于未来价值的总期望。
Rewards are in a sense primary, whereas values, as predictions of rewards, are secondary.
Without rewards there could be no values, and the only purpose of estimating values is to
achieve more reward.
从某种意义上说,奖励是最重要的,价值其次,没有收益就没有价值,评估价值的唯一目的是获得更大的收益。
Nevertheless, it is values with which we are most concerned when
making and evaluating decisions. Action choices are made based on value judgments. We
seek actions that bring about states of highest value, not highest reward, because these
actions obtain the greatest amount of reward for us over the long run.
然而,在真正选择动作是由价值决定的,我们追求更高的价值而不是更高的奖励,因为更高的价值所对应的动作对应的更大的累计收益。
Rewards are basically given directly by the environment, but values must be estimated and re-estimated from the sequences of observations an agent makes over its entire lifetime
价值比奖励更难获得,因为奖励是取决于环境的,但是价值需要综合评估,然后根据智能体的所学再次评估。
强化学习最重要的就是去学习对于价值的估计。
The fourth and final element of some reinforcement learning systems is a model of
the environment. The fourth and final element of some reinforcement learning systems is a model of
the environment. This is something that mimics the behavior of the environment, or
more generally, that allows inferences to be made about how the environment will behave.
第四个要素是环境模型,是对外界环境反应模式的模拟,是一种对外部环境行为推断。
Models are used for planning, by which we mean any way of deciding
on a course of action by considering possible future situations before they are actually
experienced.
模型用于规划,规划就是去预测未来各种情景从而决定使用哪种动作。
Limitations and Scope
Reinforcement learning relies heavily on the concept of state—as input to the policy and
value function, and as both input to and output from the model. Informally, we can
think of the state as a signal conveying to the agent some sense of “how the environment
is” at a particular time.
强化学习很依赖于状态,状态是策略和价值函数的输入,是模型的输入输出。我们可以认为状态是传递给智能体的关于环境是怎么样的信号。
More generally,
however, we encourage the reader to follow the informal meaning and think of the state
as whatever information is available to the agent about its environment.
我们只需要将状态看做环境可知的信息即可。
These methods apply multiple static policies each interacting
over an extended period of time with a separate instance of the environment. The policies
that obtain the most reward, and random variations of them, are carried over to the
next generation of policies, and the process repeats. We call these evolutionary methods
because their operation is analogous to the way biological evolution produces organisms
with skilled behavior even if they do not learn during their individual lifetimes.
有些不用显示的计算价值函数,会应用一种静态策略,在拓展的时间内去与独立的环境个体进行交互,这些交互使得智能体选择了更高收益的方法。叫做进化算法。和生物进化很类似,在个体单独的生命周期里学习。
If the space of policies is sufficiently small, or can be structured so that good policies are common or easy to find—or if a lot of time is available for the search—then evolutionary
methods can be e↵ective. In addition, evolutionary methods have advantages on problems
in which the learning agent cannot sense the complete state of its environment.
如果策略空间小,或者可以很好地找到结构化的策略,或者有充分的时间去搜索,那么进化算法是有效的,进化算法在不能精确感知环境状态的问题上有优势。
An Extended Example: Tic-Tac-Toe
什么是Tic-Tac-Toe?
Consider the familiar child’s game of tic-tac-toe. Two players take turns playing on a three-by-three board. One player playsXs and the other Os until one player wins by placing three marksin a row,horizontally, vertically, or diagonally, as the X player has in the game shown to the right. If the board fills up with neither player getting three in a row, then the game is a draw
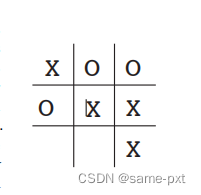
放出这个图应该会好理解很多,就是在3*3的格子里下“x”或者“o”,使其中水平竖直或者斜着有连续三个即可。
Because a skilled player can play so as never to lose, let us assume that we are playing against an imperfect player, one whose play is sometimes incorrect and allows us to win. For the moment, in
fact, let us consider draws and losses to be equally bad for us. How might we construct a player that will find the imperfections in its opponent’s play and learn to maximize its chances of winning?
玩过这个游戏的都知道,一个会玩的人是很难输掉比赛的,很容易平局。现在我们假设我们的对手是一个不太会玩的,所以我们有机会赢,在这里我们假设平局和输都是我们输,来构建一个智能体来更好的玩这个游戏。
针对这个问题,一些经典的办法是没法解决的。
For example, the classical “minimax” solution from game theory is not correct here because it assumes a particular way of playing by the opponent. For example, a minimax player would never reach a game state from which it could lose, even if in fact it always won from that state because of incorrect play by the opponent.
博弈论里极大极小的方法是不适用的,因为他假设对手以一种特定的方式去玩游戏。一个极大极小的玩家一定会保证自己不输,但是遇到某些情况,以这些状态也能够赢下比赛。
Classical optimization methods for sequential decision problems, such as dynamic programming, can compute an optimal solution for any opponent, but require as input a complete specification of that opponent, including the probabilities with which the opponent makes each move in each board state. Let us assume that this information is not available a priori for this problem, as it is not for the vast majority of problems ofpractical interest. On the other hand, such information can be estimated from experience, in this case by playing many games against the opponent. About the best one can do on this problem is first to learn a model of the opponent’s behavior, up to some level of confidence, and then apply dynamic programming to compute an optimal solution given the approximate opponent model。
序列决策的经典方法,比如动态规划,可以计算出对手下一步合适的解,但是这需要对手的完整信息,包括对手走每一步的可能性。我们假设这些内容未知,因为现实情况就是这样的。对于这样的问题,之前所需要的对手的信息可以通过交手的经验获得,也就是说可以学习一个走棋的模型,然后以一定的置信度,用动态规划方法来计算下一步正确的解。
An evolutionary method applied to this problem would directly search the space of possible policies for one with a high probability of winning against the opponent. Here, a policy is a rule that tells the player what move to make for every state of the game—every possible configuration of Xs and Os on the three-by-three board.
用于解决这个问题的进化算法,会直接在可能的概率空间中找到一个赢下比赛最大概率的策略,所谓策略,就是告诉玩家在某种状态下怎么走棋。
. For each policy considered, an estimate of its winning probability would be obtained by playing
some number of games against the opponent.
对于每种策略赢下比赛的概率可以在与对手多次博弈中估计。
A typical evolutionary method would hill-climb in policy space, successively generating and evaluating policies in an attempt to obtain incremental improvements. Or, perhaps, a genetic-style algorithm could be used that would maintain and evaluate a population of policies.
经典的进化算法回去在策略空间中hill-climb搜索,连续生成和评估策略来获取提升最大的策略,或者用类似遗传算法的进化算法来维护一个策略构成的集合。
下面让我们来看看怎么用价值函数来处理这个经典问题。
First we would set up a table of numbers, one for each possible state of the game. Each number will be the latest estimate of the probability of our winning from that state. We treat this estimate as the state’s value, and the whole table is the learned value function.
首先构建一个每个状态下的价值表,列上可能赢得概率作为价值,整张表就是一个学习价值函数。如果A的值比B的高,这说明A赢的概率比较大,当有三个连着的X时,获胜概率为1,三个连着的O获胜概率为0。
We then play many games against the opponent. To select our moves we examine the states that would result from each of our possible moves (one for each blank space on the board) and look up their current values in the table. Most of the time we move greedily, selecting the move that leads to the state with greatest value, that is, with the highest estimated probability of winning. Occasionally, however, we select randomly from among the other moves instead. These are called exploratory moves because they cause us to experience states that we might otherwise never see. A sequence of moves made and considered during a game can be diagrammed as in Figure 1.1.
接下来我们和对手玩这个游戏,每走一步前,要查看可能的价值函数列表,来选取最大的值的走法。一般来说我们会比较贪婪,即走最大值的方法。但是,我们一般还会有explor,来经历我们没走过的状态,如下图所表示:
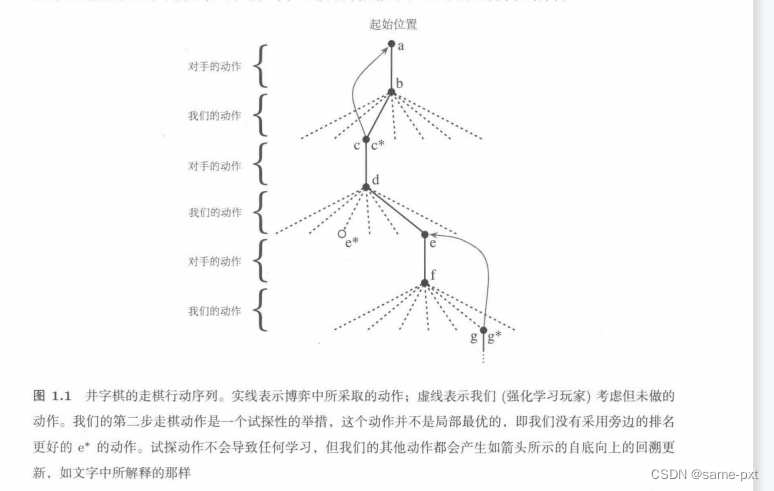
To do this, we “back up” the value of the state after each greedy move tothe state before the move, as suggested by the arrows in Figure 1.1. More precisely, the current value of the earlier state is updated to be closer to the value of the later state.This can be done by moving the earlier state’s value a fraction of the way toward the value of the later state. If we let St denote the state before the greedy move, and St+1 the state after the move, then the update to the estimated value of St, denoted V (St),can be written as *V (St) + alpha [V (St+1) − V (St)]
在这个过程中,我们不断更新自己的状态的价值,来使其更加的准确。如图中所示,我们通过greedy选择状态后,会通过回溯将对应的价值返回给之前的状态上。更加准确的说,我们是通过修改之前的状态价值来使得他更接近后面状态所对应的价值。期中alpha是步长参数,反映的是学习速率。
The method described above performs quite well on this task. For example, if the step-size parameter is reduced properly over time, then this method converges, for any fixed opponent, to the true probabilities of winning from each state given optimal play by our player.
上述方法对于解决我们当前的问题效果很好。如果步长参数随时间不断减小,对于固定的对手,将会收敛于最优策略下,每个状态获胜的概率。
Furthermore, the moves then taken (except on exploratory moves) are in fact the optimal moves against this (imperfect) opponent. In other words, the method converges to an optimal policy for playing the game against this opponent. If the step-size parameter is not reduced all the way to zero over time, then this player also plays well against opponents that slowly change their way of playing.
另外,我们在每个状态下,除了explor,都选择了最佳的策略,说明该方法收敛于针对于该对手的最优策略。即使我们不减少步长参数,也可以逐渐获取到最佳策略。
价值函数方法和进化方法有一定的不同:
To evaluate a policy an evolutionary method holds the policy fixed and plays many games against the opponent, or simulates many games using a model of the opponent. The frequency of wins gives an unbiased estimate of the probability of winning with that policy, and can be used to direct the next policy selection. But each policy change is made only after many games, and only the final outcome of each game is used: what happens during the games is ignored.
进化方法有着固定的策略然后和玩家玩很多次,或者和对手模型进行多次的博弈。最终得到的获胜概率是该策略获胜概率的无偏估计,可以用来指导下一次的策略选择。但是策略再多次博弈后改变,只有最终结果被使用,过程被忽略了。
For example, if the player wins, then all of its behavior in the game is given credit, independently of how specific moves might have been critical to the win. Credit is even given to moves that never occurred!
例如,一个玩家获胜以后,他会归功于整个过程中的所有步骤,甚至是没有出现过的步骤,也不会去分析每个步骤有多关键。
Value function methods, in contrast, allow individual states to be evaluated. In the end,
evolutionary and value function methods both search the space of policies, but learning a
value function takes advantage of information available during the course of play
与此形成对比,价值函数方法,允许每个单个状态被评估,最后,进化方法和价值函数方法都会在策略空间搜索,但是学习价值函数的过程利用了博弈过程的可用信息。
这个例子说明了强化学习的很多特性:
First, there is the emphasis on learning while interacting with an environment, in this case with an opponent player. Second, there is a clear goal, and correct behavior requires planning or foresight that takes into account delayed effects of one’s choices. For example, the simple reinforcement learning player would learn to set up multi-move traps for a shortsighted opponent. It is a striking feature of the reinforcement learning solution that it can achieve the effects of planning and lookahead without using a model of the opponent and without conducting an explicit search over possible sequences of future states and actions.
第一,强调了和环境的交互,目前交互的对象是对手。第二,他有一个清晰的目标,正确的行为需要规划和预测,这样才能考虑每次选择的长远影响。例如:简单的强化学习会给短见的对手设置陷阱。强化学习很重要的特点就是不用知道对手的模型,也不需要显式的搜索未来可能的状态和序列,就能够达到预测的效果。
强化学习的其他方面
reinforcement learning also applies in the case in which there is no external adversary, that is, in the case of a “game against nature.” Reinforcement learning also is not restricted to problems in which behavior breaks down into separate episodes, like the separate games of tic-tac-toe, with reward only at the end of each episode. It is just as applicable when behavior continues indefinitely and when rewards of various magnitudes can be received at any time.Reinforcement learning is also applicable to problems that do not even break down into discrete time steps like the plays of tic-tac-toe.
强化学习也适用于没有对手的情况,也就是与自然博弈。也适用于将行为分成一个个片段,例如可以将井字棋的每一步后看做一个片段,收益在每个片段后结算。强化学习也在动作空间无限连续,适用于不同幅度收益可以实时获取的情况。也适用于如井字棋这样不能分解为离散时间步长的问题。
Tic-tac-toe has a relatively small, finite state set, whereas reinforcement learning can
be used when the state set is very large, or even infinite.
井字棋是一个小的,有限的状态集,强化学习还可以用于很大的,无限的状态集。(例如Gerry Tesauro设计的玩西洋棋(backgammon)的程序)
The artificial neural network provides the program with the ability to generalize from its experience, so that in new states it selects moves based on information saved from similar states faced in the past, as determined by its network. How well a reinforcement learning system can work in problems with such large state sets is intimately tied to how appropriately it can generalize from past experience. It is in this role that we have the greatest need for supervised learning methods with reinforcement learning
神经网络为程序提供了从其经验中进行归纳的能力,因此在新的状态中,他根据过去保存的相似状态的信息来选择动作,并由神经网络来做最后的决策。强化学习系统能有多大的作用,取决于他从过去经验中总结推广的能力。
In this tic-tac-toe example, learning started with no prior knowledge beyond the rules of the game, but reinforcement learning by no means entails a tabula rasa view of learning and intelligence. On the contrary, prior information can be incorporated into reinforcement learning in a variety of ways that can be critical for efficient learning.e also have access to the true state in the tic-tac-toe example, whereas reinforcement learning can also be applied when part of the state is hidden, or when di↵erent states appear to the learner to be the same.
在井字棋案例中,智能体没有先验知识,但是强化学习不会像一个婴儿一样学习,以多种方式将先验知识整合到强化学习中是至关重要的。在这个游戏,我们能知道真实的状态,强化学习也适用于部分状态被隐藏或者智能体对不同状态感知不出区别的情况。
Finally, the tic-tac-toe player was able to look ahead and know the states that would result from each of its possible moves. To do this, it had to have a model of the game that allowed it to foresee how its environment would change in response to moves that it might never make. Many problems are like this, but in others even a short-term model of the effects of actions is lacking. Reinforcement learning can be applied in either case. A model is not required, but models can easily be used if they are available or can be learned
玩家需要知道施加每个动作之后可能产生的状态,为做到这一点必须有一个状态模型,使他知道环境会随着动作如何改变,这些动作可能是做不出的动作。强化学习的优势就是不管有没有模型都可以实现,但是有模型必然是锦上添花。
On the other hand, there are reinforcement learning methods that do not need any kind of environment model at all. Model-free systems cannot even think about how their environments will change in response to a single action. The tic-tac-toe player is model-free in this sense with respect to its opponent: it has no model of its opponent of any kind. Because models have to be reasonably accurate to be useful, model-free methods can have advantages over more complex methods when the real bottleneck in solving a problem is the difficulty of constructing a sufficiently accurate environment model. Model-free methods are also important building blocks for model-based methods. In this book we devote several chapters to model-free methods before we discuss how they can be used as components of more complex model-based methods.
有一些强化学习方法不需要环境模型,无模型的系统无法预测环境因动作产生的变化。这样来说,井字棋游戏玩家就是无模型的方法。无模型方法在解决难以建立一个充分精确的环境模型的问题时,比复杂的方法更有优势。
Summary
















 1526
1526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









