







本文参考个人工作平台实现并对代码进行了详细解读。通过使用简单的CNN模型,来完成mnist手写数字识别,tensorflow版本为2.13.0
一、导入数据
import tensorflow as tf
# 导入TensorFlow中的Keras模块,并从中导入datasets、layers和models子模块
"""
datasets:包含了一些常用的数据集,例如MNIST、CIFAR10等,可以用于训练和测试深度学习模型。
layers:包含了构建神经网络模型的各种层的类,例如全连接层、卷积层、池化层等。
models:包含了构建神经网络模型的类,例如Sequential模型和Functional模型,可以用于组合各种层来构建深度学习模型。
通过导入这些子模块,我们可以方便地使用TensorFlow中提供的数据集和模型构建工具来进行深度学习任务的开发和实验。
"""
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
"""
从MNIST数据集中加载训练集和测试集的图像数据和标签数据,并将它们分别赋值给train_images、train_labels、test_images和test_labels这四个变量
MNIST是一个常用的手写数字识别数据集,包含了大量的手写数字图像样本。训练集通常用于训练模型的参数,测试集用于评估模型的性能。
datasets.mnist:表示从datasets模块中的mnist子模块中加载MNIST数据集。
load_data():是mnist子模块中的一个函数,用于加载MNIST数据集。它会返回一个元组,包含了训练集和测试集的图像数据和标签数据。
(train_images, train_labels), (test_images, test_labels):通过元组解包的方式,
将训练集和测试集的图像数据和标签数据分别赋值给train_images、train_labels、test_images和test_labels这四个变量。
加载MNIST数据集后,我们可以使用这些变量来进行模型的训练和测试。
train_images和train_labels分别包含了训练集的图像数据和标签数据,
test_images和test_labels分别包含了测试集的图像数据和标签数据。
"""
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()二、数据归一化
"""
数据归一化是将数据按比例缩放到一个特定的范围,通常是0到1之间。
这样做的目的是消除不同特征之间的量纲差异,以便更好地进行数据分析和模型训练。
代码中的train_images / 255.0表示将train_images中的每个像素值除以255.0。这样做的原因是,图像数据通常以整数形式表示,
像素值的范围在0到255之间。通过将每个像素值除以255.0,可以将像素值缩放到0到1之间的范围。
同样地,test_images / 255.0表示将test_images中的每个像素值除以255.0,以实现相同的归一化效果。
通过这样的数据归一化处理,可以使得图像数据的特征范围一致,有助于提高机器学习模型的性能和训练效果。
"""
train_images, test_images = train_images / 255.0, test_images / 255.0
"""
这段代码用于获取训练图像、测试图像、训练标签和测试标签的形状(shape)信息。
在机器学习任务中,我们通常需要知道数据的形状,即数据的维度信息。这对于构建和训练模型非常重要,因为它决定了数据的输入和输出维度。
代码中的train_images.shape表示获取train_images的形状信息,即训练图像数据的维度。通常,图像数据的形状由三个维度组成,分别是图像的高度、宽度和通道数。例如,一个形状为(60000, 28, 28)的train_images表示有60000张28x28像素的灰度图像。
同样地,test_images.shape表示获取test_images的形状信息,即测试图像数据的维度。
train_labels.shape表示获取train_labels的形状信息,即训练标签数据的维度。训练标签通常用于表示图像所属的类别或标签。
test_labels.shape表示获取test_labels的形状信息,即测试标签数据的维度。
通过获取这些形状信息,我们可以了解数据的维度结构,以便在构建和训练模型时正确处理数据。
"""
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
# 结果输出
((60000, 28, 28), (10000, 28, 28), (60000,), (10000,))二、数据可视化
# 将数据集前20个图片数据可视化显示
# 进行图像大小为20宽、10长的绘图(单位为英寸inch)
# plt.figure()函数创建一个新的图形对象。figsize参数用于指定图形的尺寸,以元组(宽度, 高度)的形式提供。
plt.figure(figsize=(20,10))
# 遍历MNIST数据集下标数值0~49
for i in range(20):
# 将整个figure分成5行10列,绘制第i+1个子图。
plt.subplot(2,10,i+1)
# 设置不显示x轴刻度
plt.xticks([])
# 设置不显示y轴刻度
plt.yticks([])
# 设置不显示子图网格线
plt.grid(False)
# 图像展示,cmap为颜色图谱,"plt.cm.binary"为matplotlib.cm中的色表
plt.imshow(train_images[i], cmap=plt.cm.binary)
# 设置x轴标签显示为图片对应的数字
plt.xlabel(train_labels[i])
# 显示图片
plt.show()三、调整图片格式
"""
train_images = train_images.reshape((60000, 28, 28, 1)) 是用于重新调整训练图像数组的形状的代码。
在这段代码中,train_images是一个包含训练图像数据的数组。每个图像的初始形状是(28, 28),表示图像的高度为28像素,宽度为28像素。
通过调用reshape()函数,我们可以重新调整数组的形状。在这里,(60000, 28, 28, 1)表示我们将数组重新调整为一个四维数组,其中第一个维度是60000,表示数组中有60000个图像。
第二个和第三个维度保持为28,表示每个图像的高度和宽度仍为28像素。第四个维度是1,表示每个图像只有一个颜色通道。
这种形状调整通常在深度学习中使用,特别是在卷积神经网络(CNN)中。
CNN通常接受四维输入,其中第一个维度是批次大小,第二和第三个维度是图像的高度和宽度,最后一个维度是图像的通道数。
通过将图像数组重新调整为这种形状,我们可以将其用作CNN模型的输入。
"""
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
# 数据二次归一化
train_images, test_images = train_images / 255.0, test_images / 255.0
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
# 运行结果
((60000, 28, 28, 1), (10000, 28, 28, 1), (60000,), (10000,))四、构建CNN网络模型
# 创建并设置卷积神经网络
# 卷积层:通过卷积操作对输入图像进行降维和特征抽取
# 池化层:是一种非线性形式的下采样。主要用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的鲁棒性。
# 全连接层:在经过几个卷积和池化层之后,神经网络中的高级推理通过全连接层来完成。
"""
models.Sequential是Keras库中的一个类,用于创建序列模型(Sequential Model)。
序列模型是一种简单的线性堆叠模型,它由多个网络层按顺序连接而成,是Keras中最常见的模型类型之一。
models.Sequential类提供了一种方便的方式来定义和构建序列模型。通过将各个网络层按顺序添加到Sequential对象中,可以逐层构建模型。
"""
model = models.Sequential([
# 设置二维卷积层1,设置32个3*3卷积核,activation参数将激活函数设置为ReLu函数,input_shape参数将图层的输入形状设置为(28, 28, 1)
# ReLu函数作为激活励函数可以增强判定函数和整个神经网络的非线性特性,而本身并不会改变卷积层
# 相比其它函数来说,ReLU函数更受青睐,这是因为它可以将神经网络的训练速度提升数倍,而并不会对模型的泛化准确度造成显著影响。
"""
使用Keras库中的Conv2D函数创建一个卷积层
layers.Conv2D: 这表示我们正在创建一个卷积层对象。
32: 这是卷积层中滤波器(filter)的数量。滤波器是用于提取图像特征的小矩阵。
(3, 3): 这是滤波器的大小,它是一个3x3的矩阵。
activation='relu': 这是激活函数的类型,这里使用的是ReLU(Rectified Linear Unit)激活函数。它在神经网络中常用于引入非线性
input_shape=(28, 28, 1): 这是输入数据的形状。在这个例子中,输入图像的大小是28x28像素,且通道数为1(灰度图像)
"""
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
#池化层1,2*2采样
"""
使用Keras库中的MaxPooling2D函数创建一个最大池化层
layers.MaxPooling2D: 这表示我们正在创建一个最大池化层对象。
(2, 2): 这是池化操作的窗口大小,它是一个2x2的矩阵。
最大池化是一种降采样操作,用于减少图像的空间维度。它通过在每个窗口中选择最大值来提取图像的主要特征。
在这个例子中,池化窗口的大小是2x2,因此图像的宽度和高度将被减少一半。这有助于减少模型的参数数量,并提高计算效率
"""
layers.MaxPooling2D((2, 2)),
"""
第一个卷积层通常用于捕捉低级别的特征,例如边缘和纹理。
第二个卷积层则可以在第一个卷积层的基础上进一步提取更抽象和复杂的特征,例如形状和物体的部分。
通过多次堆叠卷积层,网络可以逐渐构建一个更深的特征层次结构,从而提高模型的性能和泛化能力。
这种层次结构的设计是为了更好地捕捉图像中的各种特征,并使模型能够更好地理解和区分不同的图像类别
"""
# 设置二维卷积层2,设置64个3*3卷积核,activation参数将激活函数设置为ReLu函数
layers.Conv2D(64, (3, 3), activation='relu'),
#池化层2,2*2采样
layers.MaxPooling2D((2, 2)),
"""
在深度学习中,layers.Flatten()是一个用于数据转换的层。它将输入数据的形状从多维数组(例如图像)转换为一维数组
具体来说,layers.Flatten()层将输入数据展平为一个向量,将多个维度的数据压缩成一维,但不改变数据的内容。
例如,如果输入是一个28x28像素的图像,经过layers.Flatten()层后,数据将被转换为一个长度为784的一维向量。
这个层通常用于连接卷积层和全连接层之间,以便将卷积层提取的特征转换为全连接层可以处理的形式。
全连接层通常用于最终的分类或回归任务。
layers.Flatten()层的作用是将输入数据展平为一维向量,以便后续的全连接层可以对其进行处理。
"""
layers.Flatten(), #Flatten层,连接卷积层与全连接层
"""
layers.Dense(64, activation='relu')是一个用于构建深度学习模型的层。
它是一个全连接层(也称为密集层),其中包含64个神经元,并使用ReLU(修正线性单元)作为激活函数。
全连接层是深度学习模型中最常用的层之一。每个神经元都与前一层的所有神经元相连接,其中每个连接都有一个权重。
在这个特定的层中,有64个神经元,每个神经元都与前一层的所有神经元相连接。
layers.Dense(64, activation='relu')表示创建一个具有64个神经元的全连接层,并使用ReLU作为激活函数。
这个层将接收前一层的输出作为输入,并产生一个64维的输出向量
"""
layers.Dense(64, activation='relu'), #全连接层,特征进一步提取,64为输出空间的维数,activation参数将激活函数设置为ReLu函数
"""
"layers.Dense(10)"表示创建一个具有10个神经元的全连接层。在深度学习中,全连接层是一种常见的神经网络层类型,
每个神经元都与上一层的所有神经元相连接。这意味着每个神经元都接收来自上一层的所有输入,并生成一个输出。
在这个特定的代码中,全连接层的输出维度设置为10。这意味着该层将生成一个具有10个元素的输出向量。
每个元素代表网络对不同类别或特征的预测或表示
"""
layers.Dense(10) #输出层,输出预期结果,10为输出空间的维数
])
# 打印网络结构
"""
Layer (type):模型的总体架构:显示模型的层次结构和连接方式,以及每个层的名称。
Output Shape: 每个层的输出形状:显示每个层的输出形状,这对于理解数据在模型中的流动很有帮助。
Param:模型的总参数数量:显示模型中的可训练参数的总数量,包括权重和偏差等
"""
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
max_pooling2d (MaxPooling2 (None, 13, 13, 32) 0
D)
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
max_pooling2d_1 (MaxPoolin (None, 5, 5, 64) 0
g2D)
flatten (Flatten) (None, 1600) 0
dense (Dense) (None, 64) 102464
dense_1 (Dense) (None, 10) 650
=================================================================
总参数:Total params: 121930 (476.29 KB)
可训练参数:Trainable params: 121930 (476.29 KB)
不可训练参数:Non-trainable params: 0 (0.00 Byte)
五、编译模型
"""
model.compile()用于配置模型的训练过程。在深度学习中,模型的编译是在训练之前必须进行的一步,它定义了模型的优化器、损失函数和评估指标。
优化器(optimizer):用于控制模型参数的更新方式。
常见的优化器包括随机梯度下降(SGD)、Adam、RMSprop等。优化器的选择取决于具体的任务和模型需求。
损失函数(loss):用于衡量模型在训练期间的性能。
损失函数通常与任务类型相关,例如分类问题可以使用交叉熵损失函数,回归问题可以使用均方误差损失函数。
评估指标(metrics):用于评估模型性能的指标。常见的评估指标包括准确率(accuracy)、精确率(precision)、召回率(recall)等。
"""
# model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
model.compile(
# 设置优化器为Adam优化器
optimizer='adam',
"""
配置模型的损失函数
我们使用了tf.keras.losses.SparseCategoricalCrossentropy作为损失函数。
这个损失函数适用于多分类问题,特别是当标签是整数形式(而不是one-hot编码)
from_logits=True表示我们的模型的输出是未经过softmax激活的原始预测值(也称为logits)。
在这种情况下,损失函数会自动应用softmax函数来计算预测类别的概率分布,并与真实标签进行比较。
如果from_logits=False,则假设模型的输出已经是经过softmax激活的概率值。
使用SparseCategoricalCrossentropy作为损失函数的好处是,它能够处理整数标签,而不需要将标签转换为one-hot编码。
这在训练过程中可以节省内存,并且更方便地与数据集进行配对。
"""
# 配置了一个适用于多分类问题的损失函数,并指定了模型输出是未经过softmax激活的原始预测值。
# 设置损失函数为交叉熵损失函数(tf.keras.losses.SparseCategoricalCrossentropy())
# from_logits为True时,会将y_pred转化为概率(用softmax),否则不进行转换,通常情况下用True结果更稳定
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# 设置性能指标列表,将在模型训练时监控列表中的指标
metrics=['accuracy']六、训练模型
"""
model.fit()是用于训练模型的方法。它接受输入数据和目标数据,并通过多次迭代的方式来调整模型的权重,以使其能够更好地拟合训练数据。
下面是model.fit()方法的一些关键参数和功能:
输入数据和目标数据:通常是将训练数据集分成输入特征数据和对应的目标标签数据。模型将根据输入数据来预测目标数据。
批次大小(batch size):指定每次迭代中要使用的样本数量。较大的批次大小可以提高训练速度,但可能会占用更多内存。
迭代次数(epochs):指定训练过程中要进行的迭代次数。每个迭代周期都会遍历整个训练数据集。
验证数据集(validation data):可选参数,用于在训练过程中评估模型的性能。模型将根据验证数据集的表现来判断是否需要调整权重。
回调函数(callbacks):可选参数,用于在训练过程中执行额外的操作。例如,可以使用回调函数来保存模型的权重、动态调整学习率等。
在调用"model.fit()"方法后,模型将开始训练过程。它会根据给定的训练数据和参数进行多次迭代,逐渐调整模型的权重,以最小化损失函数并提高模型的性能。
训练过程中的进展和性能指标将被打印出来,包括每个迭代周期的损失值和准确率等。
"""
history = model.fit(
# 输入训练集图片
train_images,
# 输入训练集标签
train_labels,
# 设置10个epoch,每一个epoch都将会把所有的数据输入模型完成一次训练。
epochs=10,
# 设置验证集
validation_data=(test_images, test_labels))Epoch 1/10 1875/1875 [==============================] - 32s 17ms/step - loss: 0.6728 - accuracy: 0.7796 - val_loss: 0.2862 - val_accuracy: 0.9147 Epoch 2/10 1875/1875 [==============================] - 31s 17ms/step - loss: 0.2351 - accuracy: 0.9287 - val_loss: 0.1627 - val_accuracy: 0.9504 Epoch 3/10 1875/1875 [==============================] - 33s 18ms/step - loss: 0.1459 - accuracy: 0.9556 - val_loss: 0.1078 - val_accuracy: 0.9676 Epoch 4/10 1875/1875 [==============================] - 37s 20ms/step - loss: 0.1114 - accuracy: 0.9663 - val_loss: 0.0903 - val_accuracy: 0.9717 Epoch 5/10 1875/1875 [==============================] - 35s 19ms/step - loss: 0.0932 - accuracy: 0.9717 - val_loss: 0.0804 - val_accuracy: 0.9744 Epoch 6/10 1875/1875 [==============================] - 34s 18ms/step - loss: 0.0821 - accuracy: 0.9742 - val_loss: 0.0847 - val_accuracy: 0.9726 Epoch 7/10 1875/1875 [==============================] - 35s 19ms/step - loss: 0.0743 - accuracy: 0.9769 - val_loss: 0.0731 - val_accuracy: 0.9773 Epoch 8/10 1875/1875 [==============================] - 35s 19ms/step - loss: 0.0676 - accuracy: 0.9784 - val_loss: 0.0632 - val_accuracy: 0.9797 Epoch 9/10 1875/1875 [==============================] - 31s 17ms/step - loss: 0.0613 - accuracy: 0.9809 - val_loss: 0.0604 - val_accuracy: 0.9823 Epoch 10/10 1875/1875 [==============================] - 33s 18ms/step - loss: 0.0579 - accuracy: 0.9824 - val_loss: 0.0663 - val_accuracy: 0.9785
七、预测
"""
plt.imshow(test_images[1])是使用Matplotlib库中的imshow函数来显示测试图像数组中索引为1的图像
test_images[1]表示测试图像数组中索引为1的图像。索引从0开始,所以索引为1表示第二张图像。
该代码会将索引为1的测试图像显示在屏幕上。
"""
plt.imshow(test_images[1])
"""
代码含义model.predict(test_images)用于使用已经训练好的模型对测试图像进行预测
model是已经训练好的模型对象。
predict()是模型对象的方法,用于进行预测操作。
test_images是测试图像的数组,包含了要进行预测的图像数据。
将测试图像输入到已经训练好的模型中,然后模型会对这些图像进行预测,并返回预测结果。
预测结果通常是一个包含了每个类别的概率分布的数组,其中概率最高的类别即为模型预测的类别
通过这段代码,我们可以获取模型对测试图像的预测结果,进而评估模型的性能和准确度。
"""
pre = model.predict(test_images) # 对所有测试图片进行预测
pre[1] # 输出第一张图片的预测结果
313/313 [==============================] - 2s 5ms/step
Out[12]:
array([ 0.60474336, 5.2106943 , 14.697648 , -2.2932158 ,
-16.026781 , -8.530423 , -3.4754536 , -15.972552 ,
1.4163063 , -17.320127 ], dtype=float32)
MNIST手写数字数据集介绍
MNIST手写数字数据集来源于是美国国家标准与技术研究所,是著名的公开数据集之一。数据集中的数字图片是由250个不同职业的人纯手写绘制,数据集获取的网址为:http://yann.lecun.com/exdb/mnist/ (下载后需解压)。我们一般会采用(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()这行代码直接调用,这样就比较简单
MNIST手写数字数据集中包含了70000张图片,其中60000张为训练数据,10000为测试数据,70000张图片均是28*28,数据集样本如下:

如果我们把每一张图片中的像素转换为向量,则得到长度为28*28=784的向量。因此我们可以把训练集看成是一个[60000,784]的张量,第一个维度表示图片的索引,第二个维度表示每张图片中的像素点。而图片里的每个像素点的值介于0-1之间。

网络结构说明
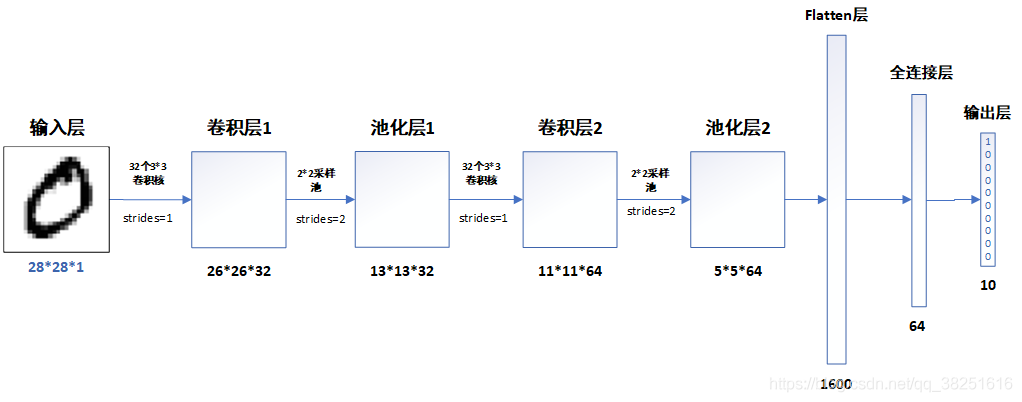
各层的作用
输入层:用于将数据输入到训练网络
卷积层:使用卷积核提取图片特征
池化层:进行下采样,用更高层的抽象表示图像特征
Flatten层:将多维的输入一维化,常用在卷积层到全连接层的过渡
全连接层:起到“特征提取器”的作用
输出层:输出结果















 1575
1575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









