







print(d1.get(‘h’,‘没有’)) #通过get可以设置默认值 访问字典中没有的键就返回默认值
d1[“xiaohu”] = 21 #增
d1[“xiaohu”] = 82 #改
del d1[‘meini’] #删
#d1.clear() #清空所有元素
print(d1.keys()) #输出所有的键
print(d1.values()) #输出所有的值 列表形式
print(d1.items()) #输出每个键值对
for key,value in d1.items(): #遍历所有的键值对
print(“键=%s, 值=%s”%(key,value))
mylist = [“a”,“b”,“c”]
print(enumerate(mylist)) #枚举
for i,x in enumerate(mylist): #采用枚举的形式可以同时拿到列表的元素和对应的下标
print(i,x)
**5. 集合(set)**
* set和dict类似,也是一组key的集合,但set不存储value;
* 在集合中也没有重复的键,重复元素会在set中自动过滤(去除);
* 集合是无序的;
* set可以是数学意义上的无序集合,所有可以执行并|、差-、交&操作
s = set([1,2,3])
print(s) #{1, 2, 3}
s1 = set([1,1,1,2,2,3,2,3])
print(s1) #{1, 2, 3}

#### 2.4 python中的一些库
>
> 关键字:import
> 使用:import 或form … import 来导入相应的模块
> 将整个模块(比如:math)导入的格式:import math
> 从某个模块中导入单个函数格式:from math import pow
> 从某个模块中导入多个函数格式:from math import pow,sqrt
> import this (python之禅)
>
>
>
| 库 | 说明 |
| --- | --- |
| random | 随机库 |
| math | 数学库 |
#### 2.4 函数
**1.概念**
为了提高编写效率以及对代码进行重复利用,可以把具有独立功能的代码块组织成一个小的模块,这就是函数;
**2.函数的定义**
def 函数名 ():
代码
def add(x,y): #加法函数
return x+y
num = add(12,5)
print(num) #17
**4.常用的系统函数**
字符串相关
| 函数 | 说明 |
| --- | --- |
| lower() | 把所有字符换成小写 |
| upper() | 把所有字符换成大写 |
| swapcase() | 大小写互换 |
| capitalize() | 将字符串的第一个字符转换为大写 |
| title() | 把每个单词首字母大写,他是以所有英文字母的字符来区别是否为一个单词的 |
| strip() | 默认去掉字符串左右两边的空白 |
| replace() | 替换掉字符串中的指定内容 |
| bytes.decode(encoding=“utf-8", errors=“strict”) | Python3中没有decode方法,但我们可以使用bytes对象的decode()方法来**解码**给定的 bytes对象,这个 bytes 对象可以由str.encode()来编码返回 |
| encode(encoding=‘UTF-8’ ,errors=‘strict’) | 以encoding 指定的**编码**格式编码字符串,如果出错默认报一个ValueError的异常,除非errors指定的是’ignore’或者’replace" |
#### 2.5 文件操作
**1.文件**
文件,就是把一些数据存放起来,可以让程序下一次执行的时候直接使用。
**2. 文件使用命令(基础)**
| 访问操作 | 命令 | 例子 |
| --- | --- | --- |
| 打开文件 | open(文件名,访问模式) | f = open(‘text.txt’) |
| 关闭文件 | 文件对象.close() | f.close() |
| 读取文件 | 文件对象.read() | f.read() |
| 写入文件 | 文件对象.write(“内容”) | f.write() |
#文件的创建、写入、关闭;
f = open(“text.txt”) #打开文件,默认读取模式(如果文件本身不存在就会报错)
f = open(“text.txt”,“w”) #打开文件,写模式 文件不存在会自动新建
f.write(“hello,ajau,i am coming~”) #将字符串写入文件
f.close() #关闭文件
#文件的打开、读取、关闭;
#read方法,读取指定的字符,开始定位在文件头部,每执行一次向后移动指定字符数
f = open(“text.txt”,“r”) #打开文件,读取模式
content = f.read() #全部读取
s = f.read(5) #只读取五个字符
l = f.readline() #读取一行
ls = f.readlines() #读取文件所有行以列表显示
print(content) #hello,ajau,i am coming~
print(s) #hello
print(l) #hello,ajau,i am coming~
print(ls) #[‘hello,ajau,i am coming~’]
f.close() #关闭文件
| 访问模式 | 说明 |
| --- | --- |
| r | 只读方式打开文件,文件的指针放在文件的开头(默认模式) |
| w | 打开文件只用于写入,文件存在则将其覆盖,文件不存在则创建 |
| a | 打开文件用于追加,文件存在指针放在文件结尾,不存在则创建并写入 |
| rb | 以二进制格式打开文件用于只读,文件的指针放在文件的开头(默认模式) |
| wb | 以二进制格式打开文件用于写入,文件存在则将其覆盖,文件不存在则创建 |
| ab | 以二进制格式打开文件用于追加,文件存在指针放在文件结尾,不存在则创建并写入 |
| r+ | 打开一个文件用于读写,文件指针放在文件的开头 |
| w+ | 打开一个文件用于读写,文件存在则将其覆盖,文件不存在则创建 |
| a+ | 同上 |
| rb+ | … |
| wb+ | … |
| ab+ | … |
**3.文件相关操作(模块)**
>
> os模块功能:实现文件重命名、删除等一些操作
>
>
>
import os #导入模块
| 相关操作 | 命令 | 例子 |
| --- | --- | --- |
| 文件重命名 | rename(需要修改的文件名,新文件名) | os.rename(“test.txt”,“经典语录.txt”) |
| 删除文件 | remove(待删除的文件名) | os.remove(”test.txt“) |
| 创建文件夹 | mkdir(“文件夹名称”) | os.mkdir(“我的文件家”) |
| 获取当前目录 | getcwd() | os.getcwd() |
#### 2.6 异常处理
>
> 异常:程序运行发生中断或者结果异常等
>
>
>
**1. for example:**
操作
f = open(“nini.txt”,“r”)
s = f.read()
print(s)
结果:

原因:
>
> 打开一个不存在的文件时,系统会抛出一个IOError类型的错误,表示文件不存在不看打开或读取;
>
>
>
**2. 解决异常**
>
> “当我们要进行一个不确定的操作,这个操作可能存在一定的风险,为了使系统不报错,我们可以采用一些py语句(try-except)来试探。”
> 注:捕获异常类型需要一致
>
>
>
**还是那个栗子:**
try: #尝试进行的操作
f = open(“nini.txt”,“r”)
s = f.read()
print(s)
except IOError: #预判可能出现的问题,如果出现这个问题进行以下操作
pass #空过,do nothing
运行结果:

原因:
>
> 因为事先捕获异常,对于异常进行了预判和处理,执行结果就按异常处理代码(pass)执行
>
>
>
**3.解决不明异常的方法**
#不确定的异常,可以在捕获中全部列举出来
try:
f = open(“nini.txt”,“r”)
s = f.read()
print(s)
print(num)
except (IOError,NameError) as result: #result 错误信息原因
print(“有异常”)
print(“这个异常是:%s”%result)
#简单的方法:所有异常都可以用Exception来表示
try:
f = open(“nini.txt”,“r”)
s = f.read()
print(s)
print(num)
except Exception as result: #Exception可以承接所有异常
print(“有异常”)
print(“这个异常是:%s”%result)
**4.try…except…finally嵌套**
try:
print(num)
except Exception as result:
print(“有异常”)
print(“这个异常是:%s”%result)
finally:
print(“我不管任务完毕 玩去了~hh”)
### 3. python爬虫
#### 3.1 爬虫介绍
**1.什么是爬虫?**
网络爬虫,是按照一定的规则,自动抓取互联网信息程序或者脚本。由于互联网的数据的多样性和资源有限性,根据用户的需求定向抓取相关网页并分析已经成为如今主流的爬取策略。
**2.爬虫可以干啥?**
可以爬图片、视频、文字等;
ps:你在浏览器上可以访问到的数据都可以通过爬虫获取;
**3.爬虫的本质?**
模拟浏览器打开网页,获取网页中我们想要的那部分数据。
**4. 搜索引擎的功能**

#### 3.2 任务介绍(movie)
爬取电影网站的基本信息,包括电影名称、评分、评价数、电影概况、电影链接等。
电影网址: <https://movie.douban.com/top250>
#### 3.3 基本流程
##### 3.3.1 准备工作:
>
> 通过浏览器查看分析目标网页,学习编程基础规范;
>
>
>
**1.URL分析**
* 页面包括250条电影数据,分10页,每页25条
* 每页的URL的不同之处:最后的数值=(页数-1)\*25
第一页:https://movie.douban.com/top250?start=0&filter=
第二页:https://movie.douban.com/top250?start=25&filter=
最后一页:https://movie.douban.com/top250?start=225&filter=
**2.网页源代码**
当我门利用爬虫给服务器发送浏览器地址,服务器去会模拟我们人去访问那个网址,服务器端看到的其实是网页的源代码;

**3.分析页面**
>
> 定位内容 :借助chrome工具(F12)来分析网页,在Elements下找到所需要的数据位置;
>
>
>
定位标题:

响应过程:(Network)

分析发送报文和响应报文

**4.规范编码**
* 一般Python程序第一行需要加入以下代码,这样可以在代码中包含中文;
#--coding: utf-8--或者# coding=utf-8
* 在Python中,使用函数实现单一功能或相关联功能的代码段,可以提高可读性和代码重复利用率。
* Python文件中可以加入main函数用于测试程序
if name == “main” :
对于if *name* == "*main*"的解释:[https://blog.csdn.net/heqiang525/article/details/]( )
**5.引入模块**
>
> 模块( module ):用来从逻辑上组织Python代码(变量、函数、类),本质就是py文件,提高代码的可维护性。Python使用import来导入模块
>
>
>
from 包 import 模块
**引入自定义模块**
在bugstudy文件夹下的test文件里创建一个test文件,文件包含add函数

在其他文件加调用此加法函数

**爬虫所需要引入的一些系统模块**
| 模块功能 | 代码 | 说明 |
| --- | --- | --- |
| | import sys | |
| 网页解析,获取数据 | import bs4 | |
| 正则表达式,进行文字匹配 | import re | |
| 指定URL,获取网页数据 | import urllib | |
| 进行excel操作 | import xlwt | |
| 进行数据库操作 | import sqlite3 | |
**安装包过程**
>
> 在cmd界面直接按照在程序文件夹路径下:
> 语句:pip3 install 包 --target=E:\pabug\venv\Lib\site-packages
>
>
>

##### 3.3.2 获取数据
>
> 通过http库向目标站点发起请求,请求可以包含额外的header等信息,如果服务器正常响应,就会得到一个reponse,便是所要获取的页面。
>
>
>
**1. 获取页面数据**
* 对于每一个页面,调用askURL函数来获取页面内容;
* 定义一个获取页面的函数askURL,传入一个url参数,表示网站,如:https://movie.douban.com/top250?start=0&filter=
* urllib2.Request生成请求(urllib2.urlopen发送请求获取响应;read获取页面内容);
* 在访问页面如果发生错误,为了保障程序正常运行,加入异常捕获(try-except)语句;
**2.urllib库**
>
> “python中使用urllib2库获取页面”
>
>
>
**urllib模块** :python内置的一个http请求库,不需要额外安装,只需要关注请求链接,参数,提供强大的解析功能。
import urllib #导入urllib模块
| URL模块 | 代码 |
| --- | --- |
| 请求模块 | urllib.request |
| 异常处理模块 | urllib.error |
| 解析模块 | urllib.parse |
关于urllib的使用我放在这个链接:<https://blog.csdn.net/meini32/article/details/124507677>
##### 3.3.3 解析内容
>
> 得到的内容可能是HTML、json等格式的数据,可以用页面解析库、正则表达式等进行解析。
>
>
>
**1.解析页面内容**
* 使用 BeautifualSoup定位特定的标签位置;
* 使用正则表达式找到具体的内容;
**2.标签解析**
BeautifulSoup库
>
> Beautiful Soup是一个库,提供一些简单的、python式的用来处理导航、搜索、修改分析树等功能,通过解析文档为用户提供需要抓取的数据。我们需要的每个电影都在一个
>
>
> 的标签中,且每个div标签都有一个属性class="item” .
>
>
>
soup = BeautifulSoup(html,“html.parser”)
#创建BeautifulSoup对象,html为页面内容,html.parser是一种页面解析器
for item in soup.find_all(‘div’,class_=‘item’)#找到每一个影片项
#找到能够完整提取出一个影片内容的项,即页面中所有样式是item类的div
标签选中操作演示:
1. 找到网页
2. 借助chrome工具(F12)来分析网页,在Elements下找到所需要的数据位置(借助左上角箭头框选需要查找的局部网页内容);
3. 在Element源码中右键“Edit as html”便可复制所选内容;
关于BeautifulSoup的使用我放在这个链接:
**3.正则提取**
re库
>
> 正则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。Python中使用re模块操作正则表达式。
>
>
>
#影片的获取规则
findLink = re.compile(r’a href="(.?)“>‘) #创建正则表达式对象,表达规则(字符串模式)
#影片图片功能
findImgSrc = re.compile(r’<img.src="(.?)”‘,re.S)#re.S让换行符也包含
#片名
findTitle = re.compile(r’(.)‘)
#评分
findRating = re.compile(r’‘)
#评价人数
findJudge = re.compile(r’(\d)人评价‘)
#概况
findInq = re.compile(r’(.)‘)
#相关内容
findBd = re.compile(r’
(.?)
',re.S)
关于re模块的使用我放在这个链接:
##### 3.3.4 保存数据到Excel
>
> 保存形式多样,可以存文本,也可以保存到数据库,或者保存特定格式的文件。
>
>
>
**1.Excel表存储**
>
> 利用python库xlwt将抽取的数据datalist写入Excel表格;
>
>
>
步骤:
1. 以utf-8编码创建一个excel对象;
2. 创建一个sheet表;
3. 往单元格里写入内容;
4. 保存表格;
举个例子:
import xlwt
workbook = xlwt.Workbook(encoding=“utf-8”) #创建一个workbook对象
worksheet = workbook.add_sheet(‘sheet1’) #创建工作表
worksheet.write(0,0,“hello”) #行、列、参数
workbook.save(‘student.xls’)
运行结果:

再举个例子(九九乘法表):
import xlwt
workbook = xlwt.Workbook(encoding=“utf-8”) #创建一个workbook对象
worksheet = workbook.add_sheet(‘sheet1’) #创建工作表
for i in range(0,9):
for j in range(0,i+1):
worksheet.write(i,j,“%d * %d = %d”%(i+1,j+1,(i+1)*(j+1)))
workbook.save(‘99.xls’)

**项目实现(dbtop250 )**
#-- coding = utf-8 --
#@Time : 2022/4/29 19:50
#@Author : meini
#@File : spider.py
#@software:
#引入模块
from bs4 import BeautifulSoup #进行具体的网页解析
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定url,获取网页数据
import xlwt #进行excel操作
import sqlite3 #进行数据库操作
def main():
baseurl = “https://movie.douban.com/top250?start=0&filter=” #初始网页(第一页)
dataList = getData(baseurl) #爬取网页
savepath = "豆瓣电影Top250.xls" #保存路径(excel文件)
saveData(dataList,savepath) #保存数据
#askURL("https://movie.douban.com/top250?start=&filter=")
#影片的获取规则
findLink = re.compile(r’a href="(.?)“>‘) #创建正则表达式对象,表达规则(字符串模式)
#影片图片功能
findImgSrc = re.compile(r’<img.src="(.?)”‘,re.S)#re.S让换行符也包含
#片名
findTitle = re.compile(r’(.)‘)
#评分
findRating = re.compile(r’‘)
#评价人数
findJudge = re.compile(r’(\d)人评价‘)
#概况
findInq = re.compile(r’(.)‘)
#相关内容
findBd = re.compile(r’
(.?)
',re.S)#爬取网页
def getData(baseurl):
dataList = []
for i in range(0,10): #调用获取页面信息的函数,10次
url = baseurl + str(i*25)
html = askURL(url) #保存获取到的网页源码
# 逐一解析数据
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"): #查找符合要求的字符串 形成列表
data = [] #保存电影所有信息
item = str(item)
#获取影片超链接
link = re.findall(findLink,item)[0] #re库通过正则表达式来查找指定字符串
data.append(link) #添加链接
imgSrc = re.findall(findImgSrc,item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if(len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/","")
data.append(otitle) #片面
else:
data.append(titles[0])
data.append('')
bd = re.findall(findBd, item)[0] #标签
bd = re.sub('<br(\s+)?/>(\s+)?'," ",bd)
bd = re.sub('/'," ",bd)
data.append(bd.strip())
inq = re.findall(findInq, item) #概述
if len(inq) != 0:
inq = inq[0].replace("。","")
data.append(inq)
else:
data.append(" ")
judgeNum = re.findall(findJudge, item)[0] #评价人数
data.append(judgeNum)
rate = re.findall(findRating, item)[0] #评分
data.append(rate)
dataList.append(data)
#print(dataList)
return dataList
#保存一个指定的URL网页内容
def askURL(url):
head = {“User-Agent”:" Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/100.0.4896.127 Safari/537.36"}
#head是用户代理,为了伪装爬虫模拟浏览器头部信息,向浏览器发送消息,表示告诉豆瓣我们是什么样的机器,本质告诉浏览器,我们可以接受什么样的文件内容
request = urllib.request.Request(url,headers=head) #封装
html = “”
try:
response = urllib.request.urlopen(request)
html = response.read().decode(“utf-8”)
#print(html)
except urllib.error.URLError as e:
if hasattr(e,“code”):
print(e.code)
if hasattr(e,“reason”):
print(e.reason)
return html
#保存数据
def saveData(datalist,savepath):
print(“saving…”)
book = xlwt.Workbook(encoding=“utf-8”,style_compression=0) # 创建一个workbook对象
sheet = book.add_sheet(‘豆瓣电影top250’,cell_overwrite_ok=True) # 创建工作表
col = (“电影详情链接”,“图片链接”,“影片中文名”,“影片外国名”,“标签”,“概述”,“评价人数”,“评分”)
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
print(“第%d条”%i)
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save('douban.xls')
if name == ‘main’:
main()
print(“爬取完毕”)
运行结果:

#### 3.3.5 保存数据到SQLite
**1.SQLite数据库**
**2.sqlite3 模块**
import sqlite3
### 4.数据可视化分析
### 关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,Python自动化测试学习等教程。带你从零基础系统性的学好Python!
>
> 👉[[[CSDN大礼包:《python安装包&全套学习资料》免费分享]]]( )(**安全链接,放心点击**)
>
>
>
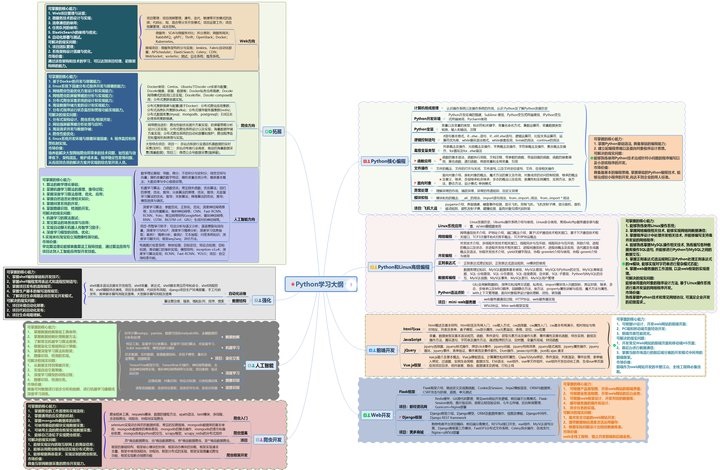
#### 一、Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
#### 二、Python必备开发工具

#### 三、入门学习视频
#### 四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
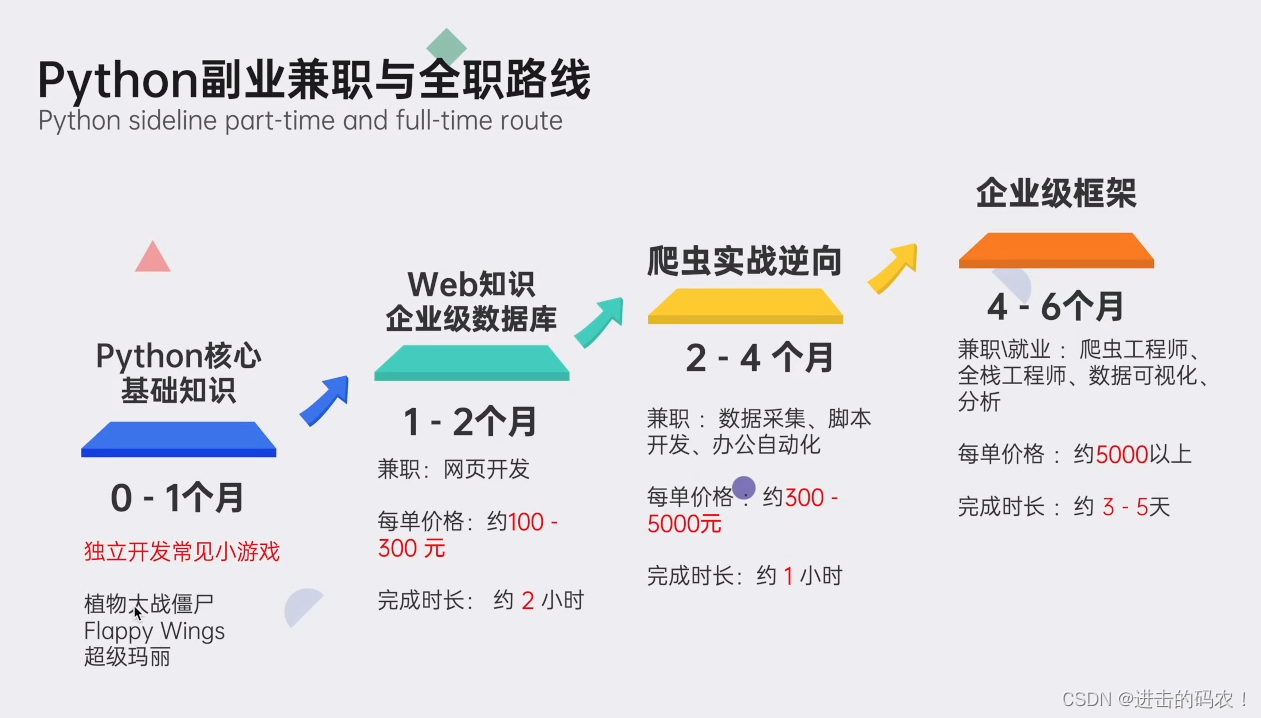
#### 五、python副业兼职与全职路线
**上述这份完整版的Python全套学习资料已经上传CSDN官方,如果需要可以微信扫描下方CSDN官方认证二维码 即可领取**
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。**






**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)**

现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**

ae54be168b93cf63939786134ca.png)



**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)**
[外链图片转存中...(img-Ahz5FXei-1712858420944)]
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
[外链图片转存中...(img-P1yHv0Kl-1712858420945)]















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









