







paper: https://www.usenix.org/conference/atc21/presentation/romero
这是一篇21年的文章,引用量145,解决模型部署易用性问题。在当时来说,这是一个比较新的问题。如果你感兴趣,请你花几分钟读一下。
目录
作者介绍
Francisco Romero 是一名Stanford的博士生,蛮有意思的是,他的研究领域并不是云计算,而是视觉方向。搜索近年写的文章,依然集中于video analytics,每年都有顶会顶刊,实属羡慕。接下来就不过多介绍了qaq(人家不搞云计算)。大佬镇楼:
背景
当前许多应用都应用了机器学习模型,并且这个数量还会不断增加。机器学习的生命周期有两个阶段:训练阶段和推理阶段。模型在训练阶段进行训练;在推理阶段,已经训练好的模型为不同终端用户服务。作为用户来说,我们当然希望应答得快、应答得准确,那这就对推理服务模型提出了一系列挑战:
- 如何高效地满足不同的应用要求。不同应用对服务满意度的标准不一样,有的重视准确度,有的重视时延。但同一应用在不同的应用场景下,它的要求也会有所变化。比如在美团上点餐,你往往会被口味和价格所吸引,但当你很饿的时候,你会选离得比较近的那家饭店。需求不同,你对应用的要求也不同。
- 在异构执行环境下如何运行。利用异构的硬件资源可以在满足用户不同需求的同时,降低成本。但管理和拓展异构资源并非易事。
- 如何选择正确的模型变体。过去的模型架构采用的是图优化的方法,但与直接注册的模型不同的是,模型变体很可能存在性能差异。
这导致你的模型搜索空间变得很大,开发人员也难以选择最优模型、最合适的硬件平台和最好的弹性伸缩策略。不仅如此,由于网络的不稳定和用户需求的变化,我们也需要动态地调整模型变体、硬件平台和弹性伸缩策略。以往的系统都忽视了这个问题,他们让开发人员独自配置选择模型策略、批处理大小、硬件类型等等,如果对于一个没有经验的开发人员来做这件事,那将导致难以想象的后果。
因此,我们希望开发出一种新的分布式推理服务架构,它可以自动地完成模型选择并能很好地管理资源。
挑战
选择最优模型变体
产生不同模型变体的因素:
- 模型结构的改变
- 编程框架的改变
- 模型图优化器的改变
- 超参数的改变
- 硬件平台的改变
不同的应用场景、不同的应用都会导致模型选择的不同,如何正确地选择模型变体是一项非常重要的步骤。我们认为系统应该为每个查询自动选择一个模型变体,以保证应用需求和开发人员的理想状态一致。
负载变化时减少成本
以往的自动伸缩器仅仅为一个应用上的所有请求复制一个指定的模型变体,但指定模型不一定是最优模型。原因有二:
- 最优模型在载入时可能发生变化
- 硬件资源不足以再复制一个相同的模型变体
如何确定哪些变体可以在现有的硬件资源下运行,并且还能满足查询需求呢?
假设现在有三种模型变体均可运行,请你选择一种算法使其满足查询需求。
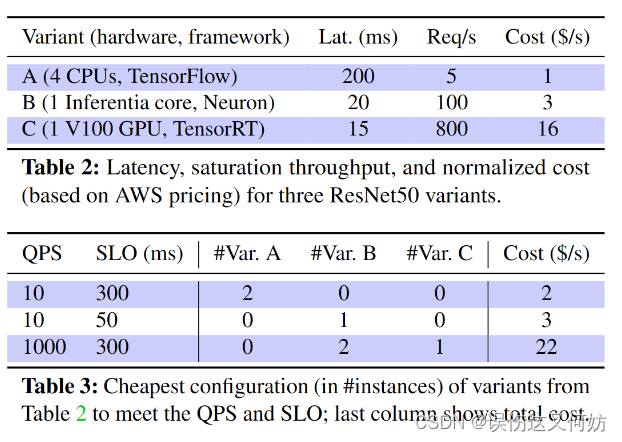
对于QPS=10,SLO=300来说,你可以选择2*A,或者B,或者C等等。对于这几个模型我们再选取成本最低的模型变体,即2*A。
提高低负载时资源的利用率
服务系统应该支持共享硬件资源,进而提高资源的利用率,但如何实现资源共享却是一件不容易的事。
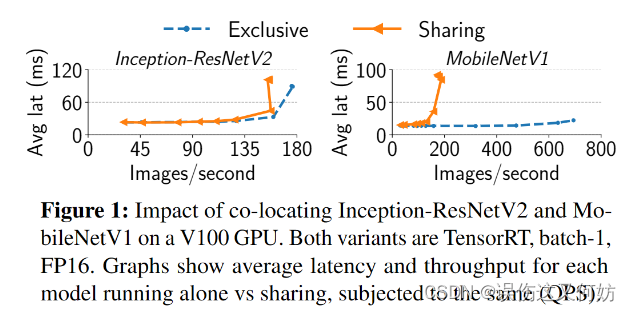
如Figure 1所示,低负载情况下,GPU共用并不会导致性能的下降;在高负载情况下,GPU共用会严重影响小模型的性能,而对大模型性能影响不大。对于不同的模型架构,影响性能的点也会不一样,如何实现资源共享也变得十分困难。
INFaaS 架构
回顾上文,INFaaS需要完成以下几个任务:
- 提供可供用户调用的api,用户可以通过api实现模型的自动部署
- 选择模型变体算法。该算法可以高效、自动地找到可以运行且满足应用需求的模型变体
- 通过共享硬件资源的方式,提高资源的利用率
- 系统具有可拓展性。为了满足不同用户的需求,选择模型变体策略也许并不相同,支持开发人员自定义模块,可有效个性化部署方案。
总体架构图
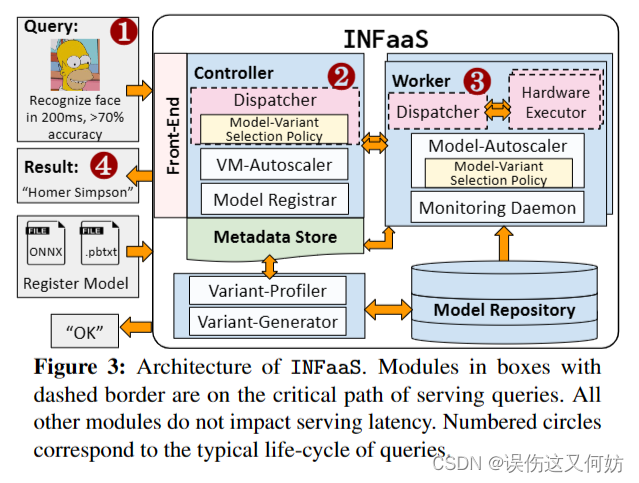
Controller 接受请求;返回请求
- Dispatcher 使用模型变体选择策略选出一个模型变体,该变体服务query
- VM-Autoscaler 基于当前负载和资源利用率自动伸缩worker的数量
- Model Registrar 模型注册
Workers 处理请求
- Dispatcher 将请求转发给特定的模型变体实例
- Model-Autoscaler 检测负载变化,若负载变化,则进行选择模型策略
- Monitoring Daemon 资源管理器,负责监控资源利用率,管理共享资源
Variant-Generator and Variant-Profiler
Variant-Generator使用模型图优化器来生成模型变体,为了帮助模型变体选择,模型分析器会对每个变体做一次性分析,包括载入时延、推理时延和最高内存利用率。这些信息和相应的app ID,准确率和最大批处理大小都被记录在Metadata Store中。在分析之后,一个变体就保存在Model Repository。
Model-Variant Selection Policy
INFaaS 在两种情况下会应用该策略。
- On arrival of a query 控制器的调度程序在接收到一个请求时
- On changes in query load 当查询负载发生变化时,worker的模型自动伸缩器就会应用该算法来决定是复制一个已有模型还是垂直缩放到不同模型变体。
为了可以应用其他模型变体选择算法,我们设计IFaaS使得策略与机制解耦。
Metadata Store
Metadata Store能对静态和动态数据进行有效访问。Metadata Store 用于模型变体选择策略和伸缩策略。内容组成
- 可用模型架构和变体信息(准确率,推理时延)
- 变体和工作机的资源使用和负载统计
Model Repository
Model Repository 是大容量持久存储介质,存储可用于服务请求的序列化变体。
主要算法----选择和伸缩模型变体
Case I: 请求到达
当请求到达控制器时,调度程序会优先考虑处于活跃状态的变体,并从中选出满足应用需求且负载最少的变体和worker;若处于活跃状态的变体都不满足应用需求,只能退而求其次,在不活跃的变体集合中找到满足用户要求的变体,并将该请求发送至相应变体硬件利用率最低的worker上。若没有变体可以满足应用需求,则选择一个最接近用户需求的变体和worker作为返回。
对于处于异常状态变体的处理
为了更好的资源利用率,INFaaS将不同的模型变体放置在同一硬件资源上。但这样做也有问题:会产生相互干扰,为了避免此类问题的发生,INFaaS不会选择处于Interfered或Overload状体的变体。对于处于Interfered 状态的变体来说,INFaaS会在后台执行一个缓解过程:若在相同变体上有可用总线资源时,INFaaS会将处于Interfered状态的变体移至可用资源上。如果没有可用资源加载变体,worker会向控制器的调用程序发出请求:请将这个变体放在别处。
对于处于Overloaded状态的变体,INFaaS 模型伸缩器将会评估是否选择别的变体是更省成本的一种选择。
Case II: 负载变化
当负载变化时,INFaaS会重新运行变体选择策略,以决定是否调整变体。INFaaS自动伸缩器将VM-level scaling和model-vertical scalling结合,避免传统伸缩所遇到的问题。
model-vertical scalling:利用利用模型变体之间的差异性,将变体改成不同的优化模型。
Model-Autoscaler at each worker
VM-Autoscaler at controller
系统评估
实验环境:
| a heterogeneous cluster of AWS EC2 instances. | |
| controller | m5.2xlarge instance(8 vCPUs, 32GiB DRAM) |
| workers | inf1.2xlarge(8 vCPUs, 16GiB DRAM, one AWS Inferentia) |
| p3.2xlarge (8 vCPUs, 61GiB DRAM, one NVIDIA V100 GPU) | |
| m5.2xlarge instance(8 vCPUs, 32GiB DRAM) | |
注:All instances feature Intel Xeon Platinum 8175M CPUs operating at 2.50GHz, Ubuntu 16.04 with 4.4.0 kernel, and up to 10Gbps networking speed.
数据集:
Twitter trace from 2018 collected over a month
对于每次实验,随机在30天里选择一天
生产工作量评估
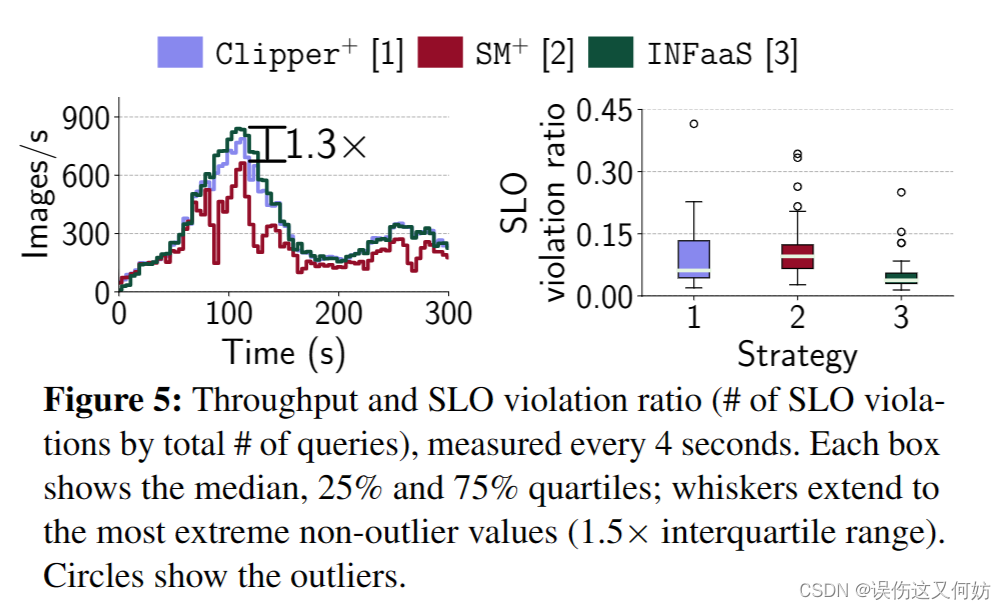
结果分析:
吞吐量方面,INFaaS比
S
M
+
SM^+
SM+高1.3倍,比
C
l
i
p
p
e
r
+
Clipper^+
Clipper+高1.1倍。SLO违反率方面,INFaaS有着最低的SLO违反率。
选择变体策略评估

a. a flat, low load (4 QPS)
b. a steady, high load (slowly increase from 650 to 700 QPS)
c. a fluctuating load (ranging between 4 and 80 QPS)
结果分析
在低负载时,INFaaS选择CPU变体;在负载高峰时,INFaaS就会升级成一个Inferentia batch-1 variant。
INFaaS节省3倍的成本,
图6a-6c表示,单个变体既不是最具成本效益的,也不是在所有场景下的最佳性能。通过模型垂直缩放利用针对不同硬件优化的变体,INFaaS能够适应负载和查询模式的变化。
共享资源有效性评估
现在将展示INFaaS在不影响查询性能的情况下如何跨模型管理和共享加速器。
不同模型部署在同一块Inferentia chip上不会造成显著影响。因此我们主要关心GPU共享。INFaaS检测模型变体合适进入Overload/Interfered状态,当在GPU上的变体都处于Overload/Interfered状态时,要么将变体转移到不同GPU,要么扩展一个新的GPUworker。
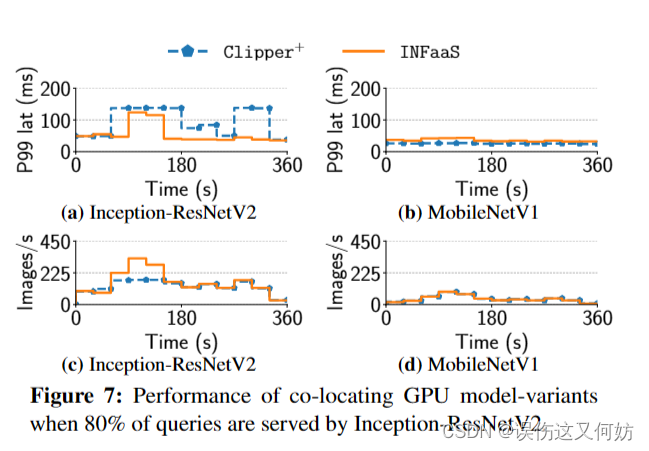
workload:Inception-ResNetV2 serving 80% QPS and MobileNetV1 serving 20% QPS
结果分析:与Clipper不同,INFaaS可以通过增加GPU worker的方式进一步减少延时。由于INFaaS在低负载时采用装箱算法且仅仅在高负载情况下添加GPU,INFaaS比clipper+节省10%的成本。
决策开销评估
在查询的关键路径上,INFaaS共做了两个决策:选择模型变体和选择worker。图7展示了INFaaS做这些决策时的中值延迟。
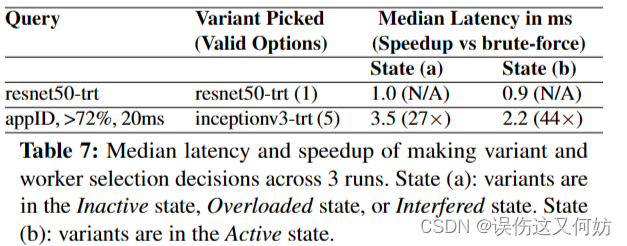
当query指定模型变体时,INFaaS产生的开销很低,因为它仅仅选择一个worker。当仅指定query的需求且模型变体还未载入时(state a),INFaaS花费3.5ms,当处于state b时,需要2.2ms。
总结
INFaaS是一种用于分布式推理服务的自动无模型系统。INFaaS的自动无模型特性让应用开发人员指定高水平的性能,比如请求所需要的延迟和准确度,而不用负责选择和部署变体模型、硬件资源和伸缩策略。INFaaS会根据开发人员指定的性能自动地管理资源。我们验证了模型变体选择策略和资源共享可以使系统有更高的吞吐量,更低的时延,更小的成本。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











