







多通道语音增强技术
由于科研需要,最近在看一些多通道语音增强技术方面的知识,现在对已经了解的知识跟大家分享一下。同时,自己这方面刚开始学习,有些东西可能理解的不太到位希望大家指正。
简单介绍一下目前语音增强技术的常用方案:
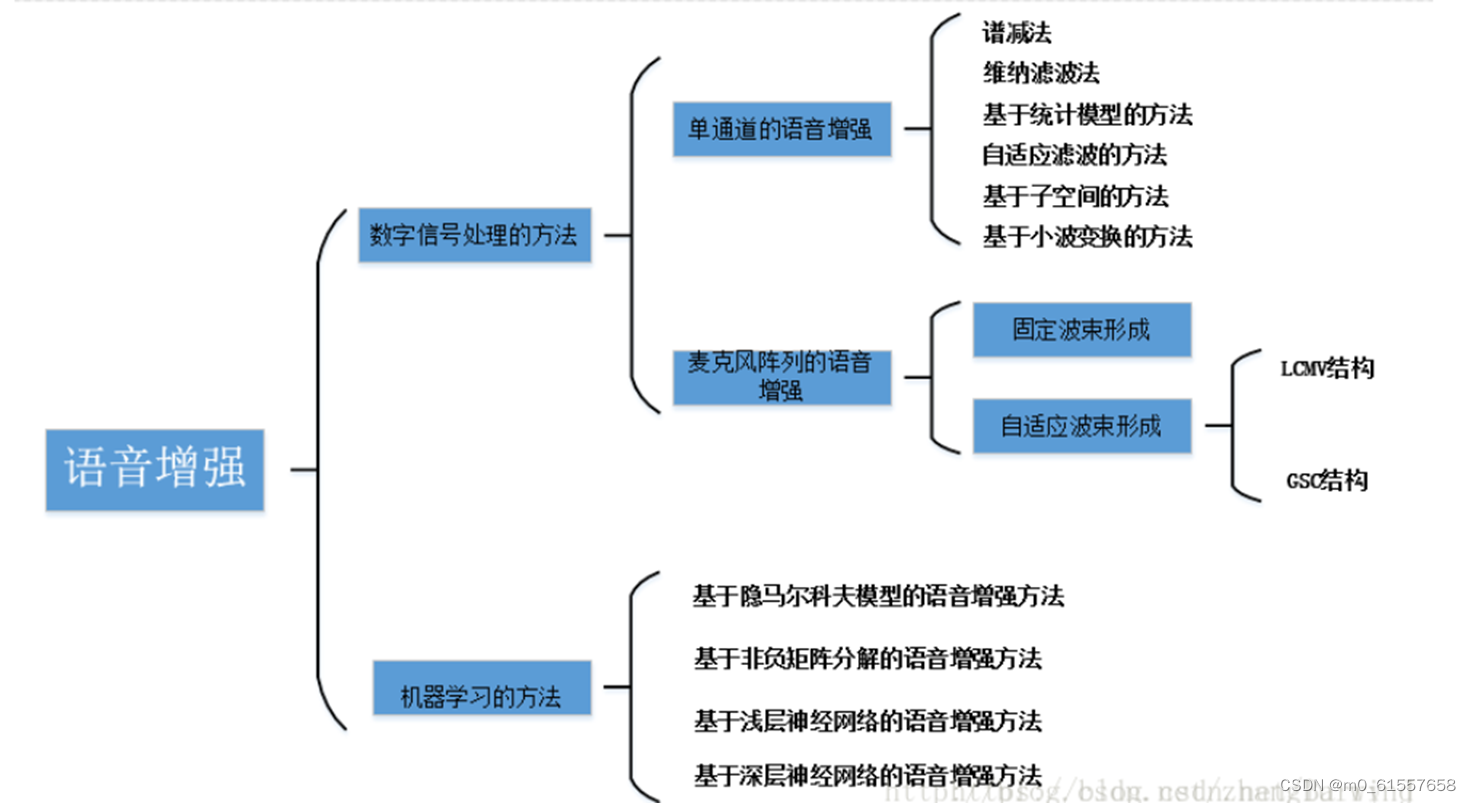
上述的整体技术方案框图来源于另一个博主的博客,如有侵权请指正,由于自己了解的还不多目前只针对数字信号处理方向进行介绍。目前数字信号处理方法中语音增强技术可以分为两个主要分支,第一个分支是单通道语音增强技术:谱减法,维纳滤波法,基于统计模型的方法,自适应滤波法,基于子空间的方法,基于小波变化的方法。另一个分支是多通道语音增强技术,其中包括固定波束形成算法:DSB,自适应滤波算法:LCMV,MVDR,后置滤波技术。现就对多通道语音增强技术进行展开讨论。
固定波束形成算法(延迟求和波束形成算法(DSB))
原理:首先对不同麦克风信号之间的延迟进行步长,然后叠加延时后的信号形成一个单一的输出。
缺点:需要麦克风的数量相对较多,如果噪声源是想干的降噪效果会强烈的依赖于噪声信号的到达方向,延迟求和波束形成在混响环境中的性能往往是不够好的。
自适应波束形成算法:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 505
505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









