







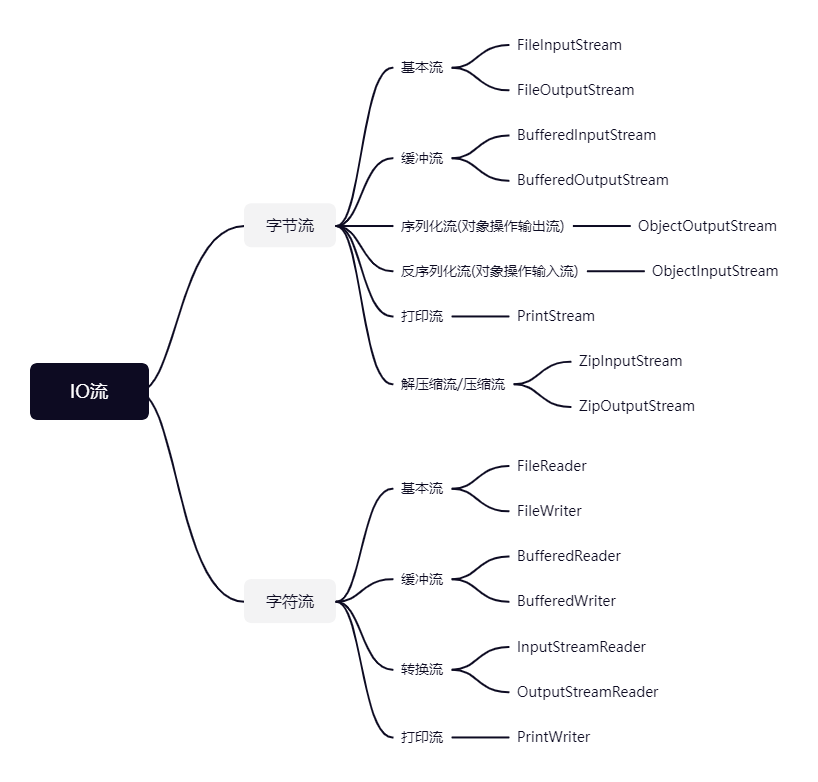
IO流
存储和读取数据的解决方案,用于读写数据(本地文件、网络)
IO流按照流向可以分类为
输出流:程序---->文件
输入流:文件---->程序
IO流按照操作文件的类型可以分类为
字节流:可以操作所有类型文件
字符流:只能操作纯文本文件(纯文本文件就是用Window系统自带的记事本打开并且能读懂的文件)
字节流和字符流的使用场景
字节流:拷贝任意类型的文件
字符流:
读取纯文本文件中的数据
往纯文本文件中写出数据
字节流
基本流
FileOutputStream
操作本地文件的字节输出流,可以把程序中的数据写到本地文件中
书写步骤
创建字节输出流对象
参数是字符串表示的路径或者是File对象都是可以的
如果文件不存在会创建一个新的文件,但是要保证父级路径是存在的
如果文件已经存在,则会清空文件
写数据
write方法的参数是整数,但是实际上写到本地文件中的是整数在ASCII上对应的字符
释放资源
每次使用完流之后都要释放资源
FileOutputStream写数据的3种方式
方法名称 | 说明 |
void write(int b) | 一次写一个字节数据 |
void write(byte[] b) | 一次写一个字节数组数据 |
void write(byte[] b,int off,int len) | 一次写一个字节数组的部分数据 |
FileOutputStream fos = new FileOutputStream("src\\a.txt");
String s ="abcd";
byte[] bytes = s.getBytes();
fos.write(bytes);
fos.close();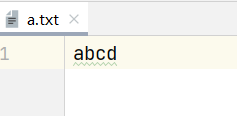
off表示起始索引,len表示字节个数
换行写
再次写出一个换行符
Window: \r\n
Linux: \n
Mac: \r
细节:在windows操作系统中,java对回车换行进行了优化,虽然完整的是\r\n,但是我们写其中一个\r或者\n java也可以实现换行,因为java底层会补全
FileOutputStream fos = new FileOutputStream("src\\a.txt");
String s = "abcd";
byte[] bytes = s.getBytes();
fos.write(bytes);
fos.write("\r\n".getBytes());
String s1 = "111";
byte[] bytes1 = s1.getBytes();
fos.write(bytes1);
fos.close();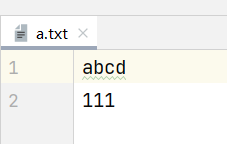
续写
如果想要续写,打开续写开关即可,即创建对象的第二个参数,默认是false,表示关闭续写,此时创建对象会清空文件,手动传递true表示打开续写,此时创建对象不会清空文件
FileInputStream
操作本地文件的字节输入流,可以把本地文件中的数据读取到程序中
书写步骤
创建字节输入流对象
如果文件不存在,就直接报错
读数据
一次读一个字节,读出来的是数据在ASCII上对应的数字
读到文件末尾了,read方法返回-1
释放资源
每次使用完流必须要释放资源
FileInputStream循环读取
FileInputStream fis = new FileInputStream("src\\a.txt");
int b;
while ((b = fis.read()) != -1){
System.out.print((char) b);
}
fis.close();
}
FileInputStream一次读多个字节
FileInputStream fis = new FileInputStream("src\\a.txt");
byte[] bybes = new byte[2];
int len = fis.read(bybes);
System.out.println(new String(bybes,0,len));
int len1 = fis.read(bybes);
System.out.println(new String(bybes,0,len1));
int len2 = fis.read(bybes);
System.out.println(new String(bybes,0,len2));
fis.close();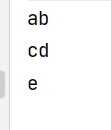
文件拷贝
FileInputStream fis = new FileInputStream("src\\a.txt");
FileOutputStream fos = new FileOutputStream("src\\a.txt");
int len;
byte[] b = new byte[1024 * 1024 * 5];
while ((len = fis.read(b)) != -1){
fos.write(b,0,len);
}
fos.close();
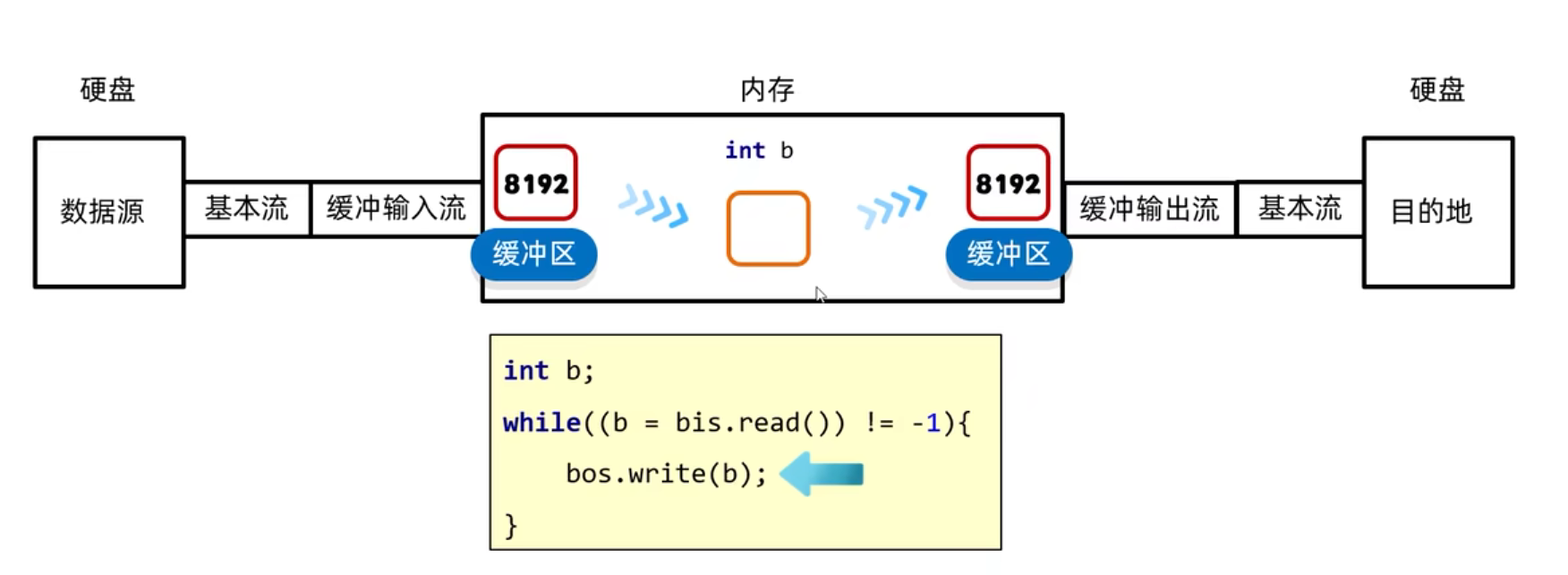
fis.close();缓冲流
原理:底层自带了长度为8192的缓冲区提高性能
把基本流包装成高级流,提高读写数据的性能
用缓冲流拷贝文件
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("src\\a.txt"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("src\\b.txt"));
int len;
byte[] bytes = new byte[2];
while ((len = bis.read(bytes)) != -1){
bos.write(bytes,0,len);
}
bos.close();
bis.close();缓冲流的读写原理
序列化流(对象操作输出流)
将java中的对象写到本地文件中,并且看不懂

使用对象操作输出流将对象保存到文件时会出现NotSerializableException异常
解决方案:需要让JavaBean类实现Serializable接口,该接口中没有方法(标志性接口)
反序列化流(对象操作输入流)
可以把序列化到本地文件中的对象,读取到程序中来
序列化流写到文件中的数据是不能修改的,一旦修改就无法再次读回来
序列化对象后,修改了Javabean类,再次序列化会有问题,会抛出InvalidClassException异常
解决方案:给Javabean类添加serialVersionUID(序列号)
如果一个对象中的某个成员变量的值不想被序列化,给该成员变量添加transient关键字修饰,该关键字标记的成员变量不参与序列化过程
打印流(PrintStream)
打印流只操作文件目的地,不操作数据源
字节流底层没有缓冲区,开不开自动刷新都一样
成员方法 | 说明 |
public void write(int b) | 常规方法:规则和之前一样,将指定的字节写出 |
public void println(XXX xxx) | 特有方法:打印任意数据,自动刷新,自动换行 |
public void print(XXX xxx) | 特有方法:打印任意数据,不换行 |
public void printf(String format,Object... args) | 特有方法:带有占位符的打印语句,不换行 |
解压缩流
ZipInputStream
解压本质:把每一个ZipEntry按照层级拷贝到本地另一个文件夹中
压缩包里面的每一个文件或文件夹都是一个ZipEntry对象
public static void main(String[] args) throws IOException {
//创建一个File表示要解压的压缩包
File src = new File("D:\\aaa.zip");
//创建一个File表示解压的目的地
File dest = new File("D:\\aaa\\");
unzip(src,dest);
}
//定义一个方法用来解压
public static void unzip(File src,File dest) throws IOException {
//创建一个解压缩流用来读取压缩包中的数据
ZipInputStream zip = new ZipInputStream(new FileInputStream(src), Charset.forName("GBK"));
dest.mkdirs();
//表示当前在压缩包中获取到的文件或者文件夹
ZipEntry entry;
while ((entry = zip.getNextEntry()) != null){
//文件夹:需要在目的地dest处创建一个同样的文件夹
if (entry.isDirectory()){
File file = new File(dest,entry.toString());
file.mkdirs();
}else {
//文件:需要读取到压缩包中的文件,并把他存放到目的地dest文件夹中(按找层级目录行进存放)
FileOutputStream fos = new FileOutputStream(new File(dest,entry.toString()));
int b;
while ((b = zip.read()) != -1){
fos.write(b);
}
fos.close();
//表示在压缩包中的一个文件处理完毕
zip.closeEntry();
}
}
zip.close();
}压缩流
ZipOutputStream
压缩本质:把每一个(文件/文件夹)看成ZipEntry对象放到压缩包中
public static void main(String[] args) throws IOException {
//创建File对象表示要压缩的文件
File src = new File("D:\\aaa");
//创建File对象表示压缩包的位置
File dest = new File(src.getParentFile(),src.getName() + ".zip");
ZipOutputStream zos = new ZipOutputStream(new FileOutputStream(dest));
toZip(src,zos,src.getName());
}
public static void toZip(File src,ZipOutputStream zos,String name) throws IOException {
File[] files = src.listFiles();
for (File file : files) {
if (file.isFile()){
ZipEntry zipEntry = new ZipEntry(name + "\\" + file.getName());
zos.putNextEntry(zipEntry);
//读取文件中的数据,写到压缩包
FileInputStream fis = new FileInputStream(file);
int b;
while ((b = fis.read()) != -1){
zos.write(b);
}
fis.close();
zos.closeEntry();
}else {
toZip(file,zos,name + "\\" +file.getName());
}
}
}字符集
计算机的存储规则(GBK)
英文

英文用一个字节存储,完全兼容ASCII
GBK英文编码规则:不足8位,前面补0
汉字

汉字两个字节存储
高位字节二进制一定以1开头(区分英文和中文)
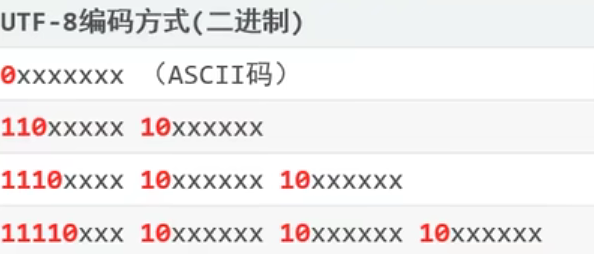
计算机的存储规则(Unicode)
UTF-8编码规则:用1~4个字节保存
黑色部分用查询到的数字的二进制形式补全
英文1个字节,中文3个字节
乱码
乱码出现的原因
读取数据时未读完整个汉字
编码和解码时的方式不统一
如何不产生乱码
不要使用字节流读取文本文件
编码解码时使用同一个码表,同一种编码方式
Java中编码的方法
String类中的方法 | 说明 |
public byte[] getByte() | 使用默认方式进行编码 |
public byte[] getByte(String charsetName) | 使用指定方式进行编码 |
Java中解码的方法
String类中的方法 | 说明 |
String(byte[] bytes) | 使用默认方式进行编码 |
String(byte[] bytes,String charsetName) | 使用指定方式进行编码 |
字符流
Reader和Writer是一个抽象类,FileReader和FileWriter分别是其子类
字符流的底层其实就是字节流
字符流 = 字节流 + 字符集
特点:
输入流:一次读一个字节,遇到中文时,一次读多个字节
输出流:底层会把数据按照指定的编码方式进行编码,变成字节再写到文件中
基本流
FileReader
read()细节
默认也是一个字节一个字节的读取的,如果遇到中文就会一次读取多个
在读取后,方法的底层还会进行解码并转成十进制,最终这个十进制作为返回值,这个十进制数据也表示在字符集上的数字
英文:文件里面二进制数据 0110 0001
read()方法进行读取,解码并转成十进制97
中文:文件里面的二进制数据 11100110 10110001 10001001
read()方法进行读取,解码并转成十进制27721
FileReader fr = new FileReader("src\\a.txt");
int ch;
while ((ch = fr.read()) != -1){
System.out.print((char) ch);
}
fr.close();
FileWriter
成员方法 | 说明 |
void write(int c) | 写出一个字符 |
void write(String str) | 写出一个字符串 |
void write(String str,int off,int len) | 写出一个字符串的一部分 |
void write(char[] cbuf) | 写出一个字符数组 |
void write(char[] cbuf,int off,int len) | 写出一个字符数组的一部分 |
缓冲流
字符缓冲流特有方法
输入流方法 | 说明 |
public String readLine() | 读取一行数据,如果没有数据可读了,会返回null |
输出流方法 | 说明 |
public void newLine() | 跨平台的换行 |
BufferedReader br = new BufferedReader(new FileReader("src\\a.txt"));
String line;
while ((line = br.readLine()) != null){
System.out.println(line);
}
br.close();
BufferedWriter bw = new BufferedWriter(new FileWriter("src\\b.txt"));
bw.write("aaa");
bw.newLine();
bw.write("bbb");
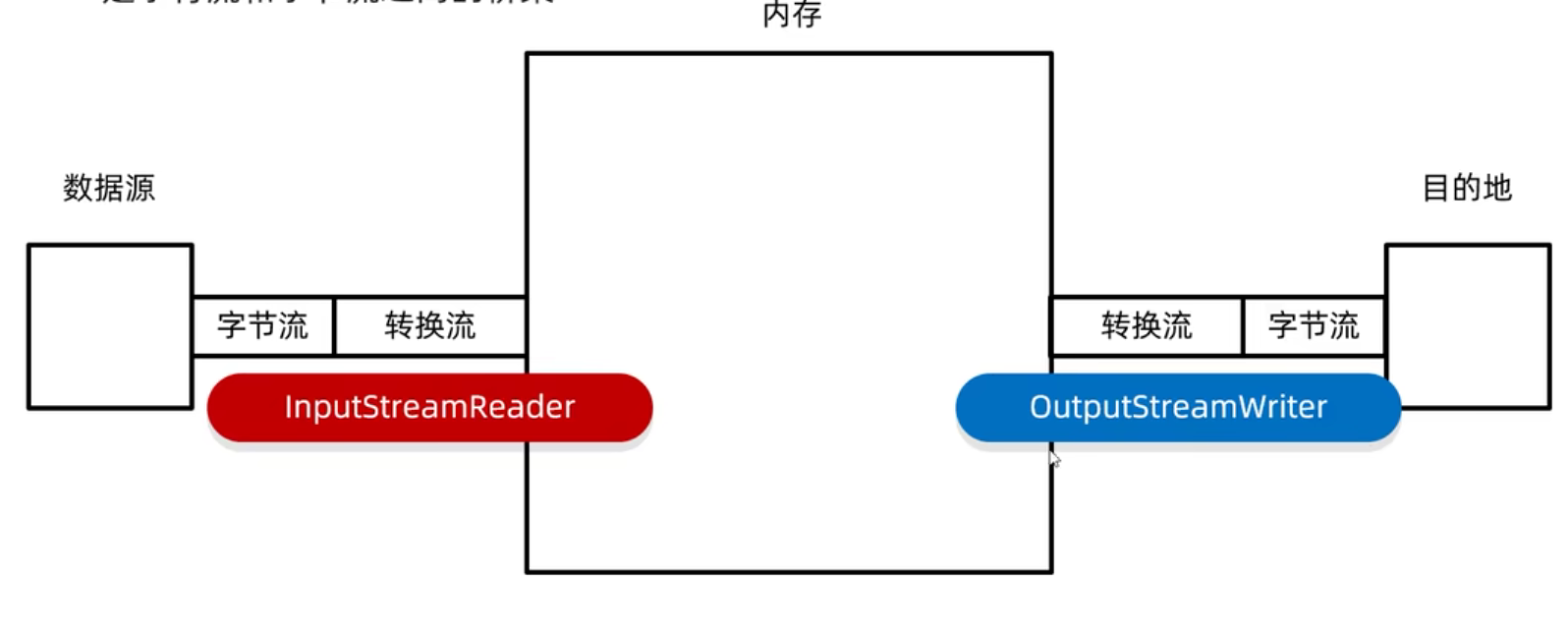
bw.close();转换流
是字节流与字符流之间的桥梁
转换流本质上就是字符流
作用:字节流想要使用字符流中的方法
打印流(PrintWriter)
字符流底层有缓冲区,想要自动刷新需要开启
其他和字节打印流基本一致
案例
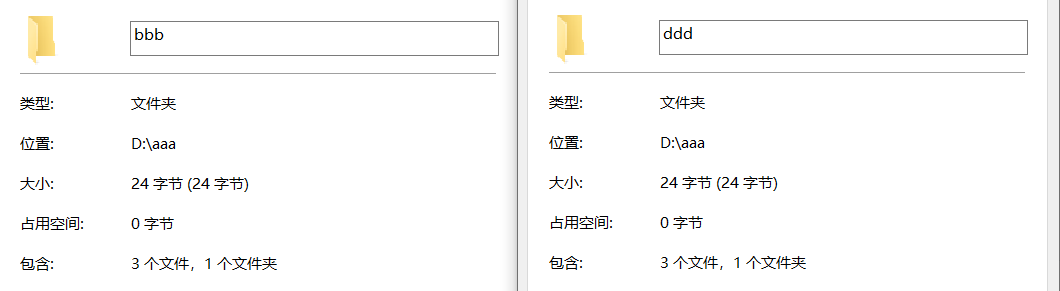
案例一
拷贝一个文件夹,考虑子文件夹
public static void main(String[] args) throws IOException {
File src = new File("D:\\aaa\\bbb");
File dest = new File("D:\\aaa\\ddd");
copyDir(src,dest);
}
private static void copyDir(File src, File dest) throws IOException {
dest.mkdirs();
//递归
//1.进入数据源
File[] files = src.listFiles();
//2.遍历数组
for (File file : files) {
if (file.isFile()){
//判断文件,拷贝
FileOutputStream fos = new FileOutputStream(new File(dest,file.getName()));
FileInputStream fis = new FileInputStream(file);
byte[] bytes = new byte[1024];
int len;
while ((len = fis.read(bytes)) != -1){
fos.write(bytes,0,len);
}
fis.close();
fos.close();
}else {
//判断文件夹,递归
copyDir(file,new File(dest,file.getName()));
}
}
}
案例二
为了保证文件的安全性,就需要对原始文件进行加密存储,再使用的时候再对其进行解密处理
加密原理:对原始文件中的每一个字节数据进行更改,然后将更改以后的数据存储到新的文件中
解密原理:读取加密之后的文件,按照加密的规则反向操作,变成原始文件
//加密处理
FileInputStream fis = new FileInputStream("D:\\aaa\\1.jpg");
FileOutputStream fos = new FileOutputStream("D:\\aaa\\ency.jpg");
int b;
while ((b = fis.read()) != -1){
fos.write(b ^ 10);
}
fos.close();
fis.close();
//解密处理
FileInputStream fis1 = new FileInputStream("D:\\ency.jpg");
FileOutputStream fos1 = new FileOutputStream("D:\\redu.jpg");
int b1;
while ((b1 = fis1.read()) != -1){
fos1.write(b1 ^ 10);
}
fos1.close();
fis1.close();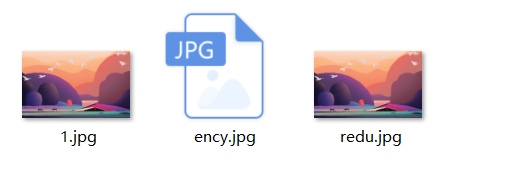
案例三
文件中有以下的数据:2-1-8-9-3-4
将文件中的数据进行排序,变成一下的数据:1-2-3-4-8-9
//读取数据
FileReader fr =new FileReader("src\\a.txt");
StringBuffer sb = new StringBuffer();
int ch;
while ((ch = fr.read()) != -1){
sb.append((char)ch);
}
fr.close();
//排序
Integer[] arr = Arrays.stream(sb.toString().split("-"))
.map(Integer::parseInt)
.sorted()
.toArray(Integer[]::new);
//写出
FileWriter fw = new FileWriter("src\\a.txt");
String s = Arrays.toString(arr).replace(", ", "-");
String result = s.substring(1, s.length() - 1);
fw.write(result);
fw.close();细节:
文件中的数据不要换行
文件以UTF-8形式存储不要带bom头















 6134
6134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









