







文章目录
TiKV架构和作用
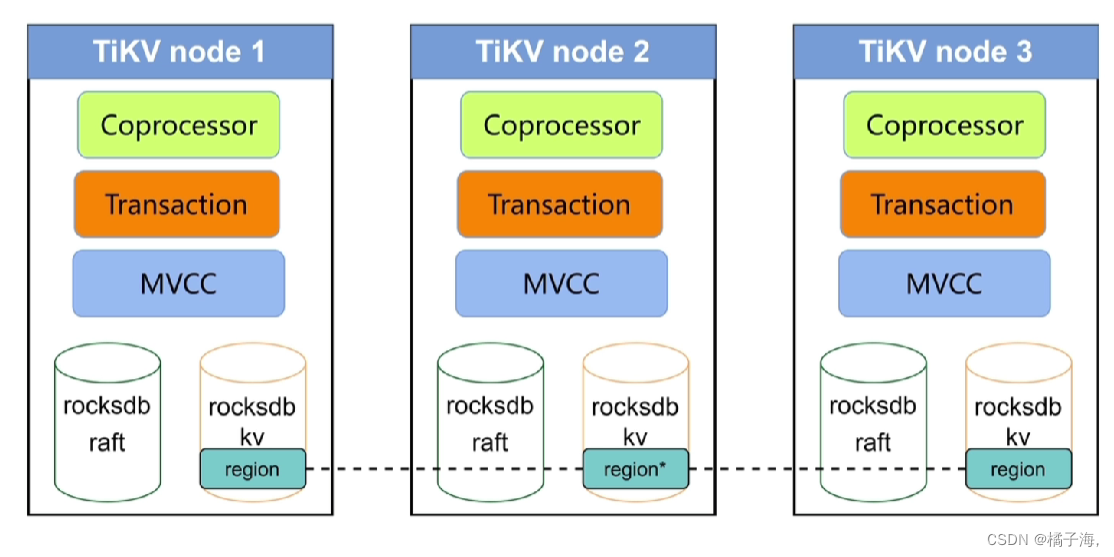
- 数据持久化
- 分布式一致性
- MVCC
- 分布式事务
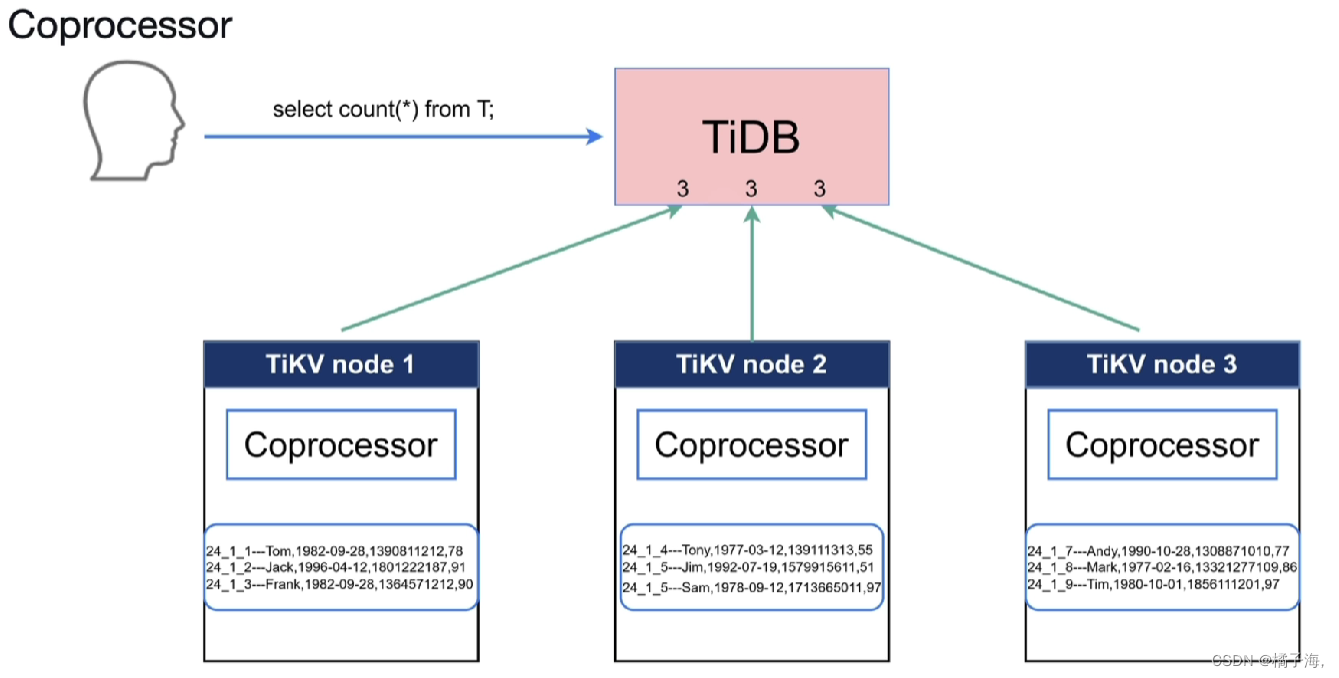
- Coprocessor
RocksDB
RocksDB针对Flash存储进行优化,延迟极小,使用LSM存储引擎
- 高性能的Key-Value数据库
- 完善的持久化机制,同时保证性能和安全性
- 良好的支持范围查询
- 为需要存储TB级别数据到本地FLASH或者RAM的应用服务器设计
- 针对存储在高速设备的中小键值进行优化,可以存储在FLASH或者直接存储在内存
- 性能随CPU数量线性提升,对多核系统友好
持久化:RocksDB:写入
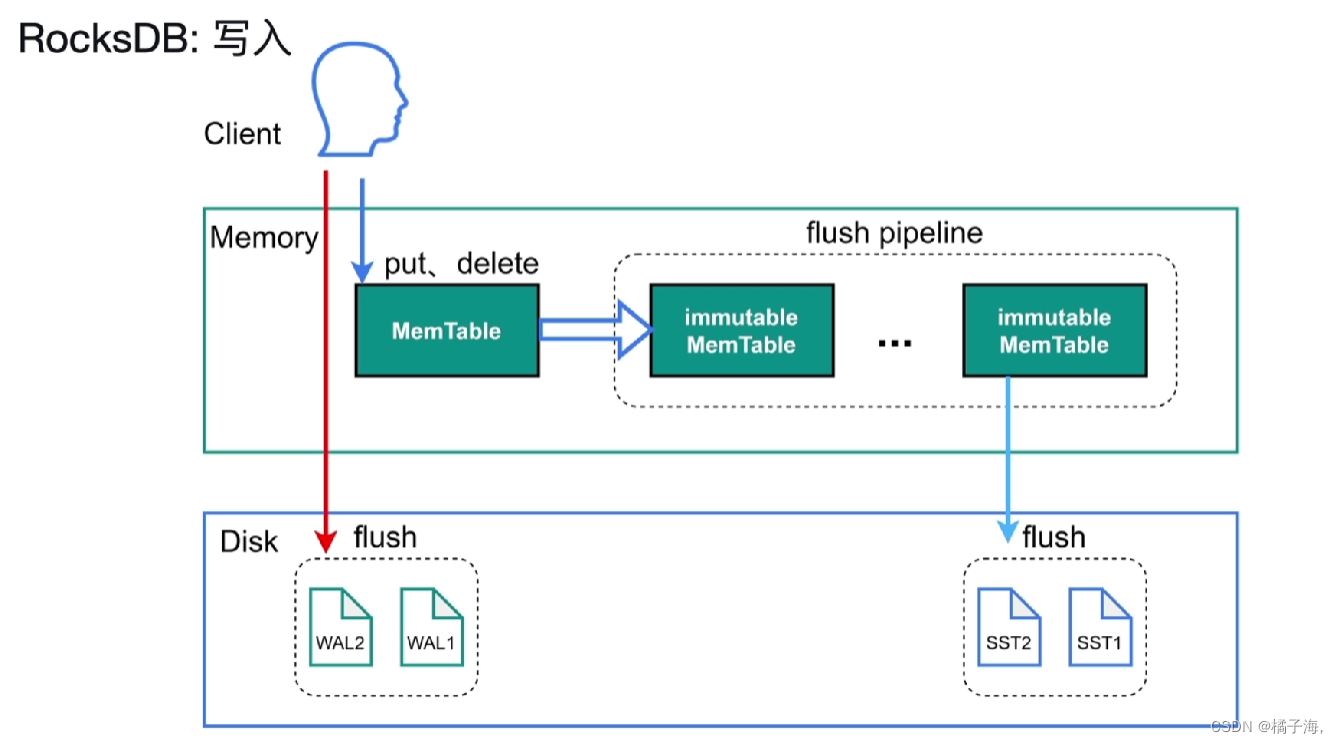
防止写到内存中的数据因为断电而丢失,所以需要首先做一个预写日志的操作(WAL),用来保障事务写入的原子性和持久性的一项重要技术。
先把数据写入磁盘的日志中,然后写入内存中,如果发生宕机,会通过日志重建Mem Table
设置参数sync_log=true,可以直接调用操作系统写入磁盘中,而不用先写入缓存中
然后不断的向Mem Table中写入数据,一直追加,当追加到一定的数据量时,当里面的数据追加到write_buffer_size时,这时候就把Mem Table转存到immutable Meme Table,然后重新开辟一个Mem Table
immutable Meme Table就是由Mem Table 转为SST文件的中间状态,防止写阻塞
当immutable Mem Table 默认达到5个时,就会触发write stall,会讲写入Mem Table的速度进行限制,从客户端来讲,就是写入的速度变慢了
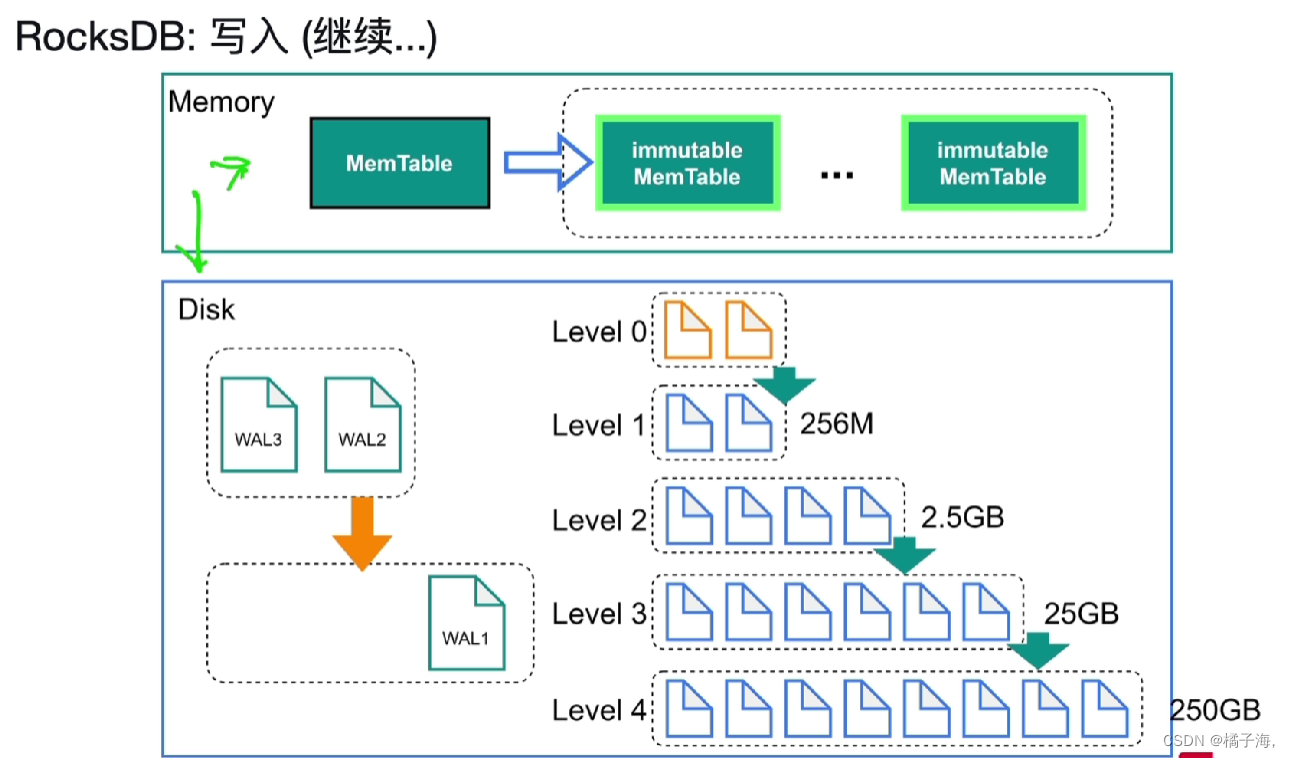
Level0就是immutable Mem Table的复刻,它默认达到四个以后就会向下一层走,这个过程叫做compaction
每一层都会被切分成一个一个的SST文件,每一个SST文件都是键值对,都是按照键值对里的key排好序的,如果需要在SST文件中定位某个key的话,就用二分查找法查找
文件的形成: 当Level0写满4个时,就开始向下一层做compaction,四个文件合并成一个SST文件,会做压缩同时把key排好序,一次类推,向下合并压缩
对于删除和修改,直接操作Mem Table,最新的数据永远在老数据的上面
RocksDB:查询
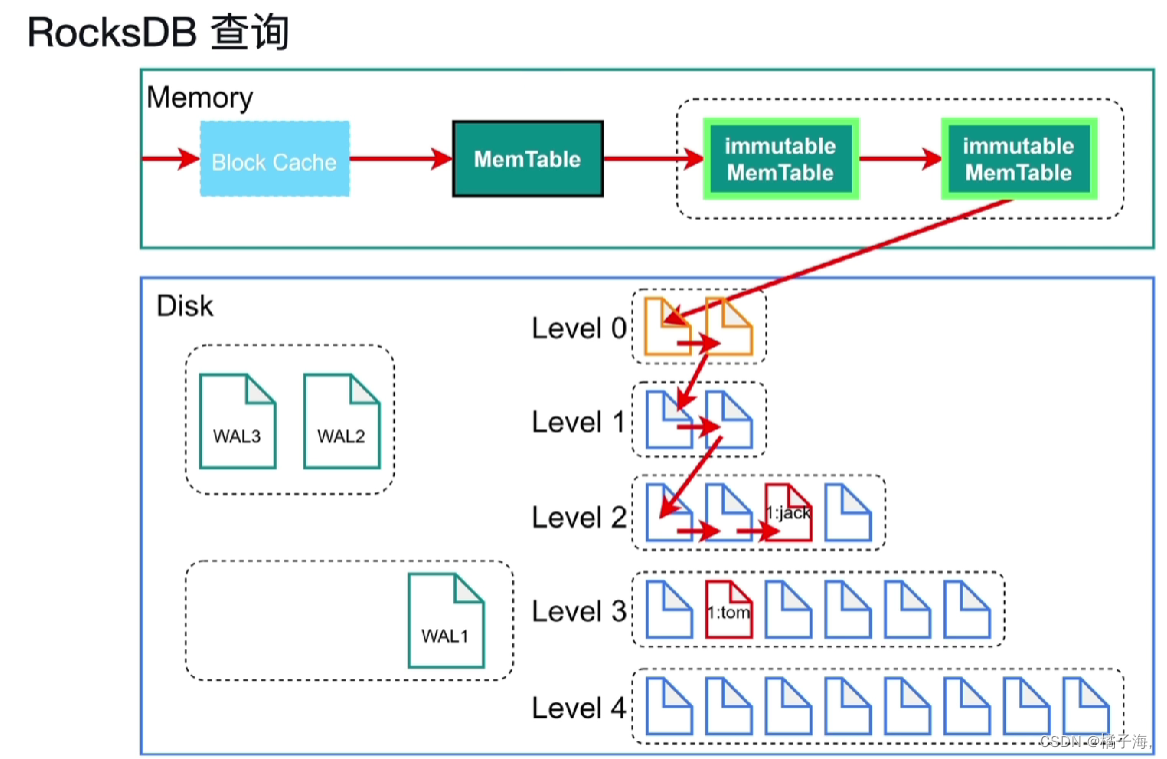
RocksDB:Column Families(列簇)
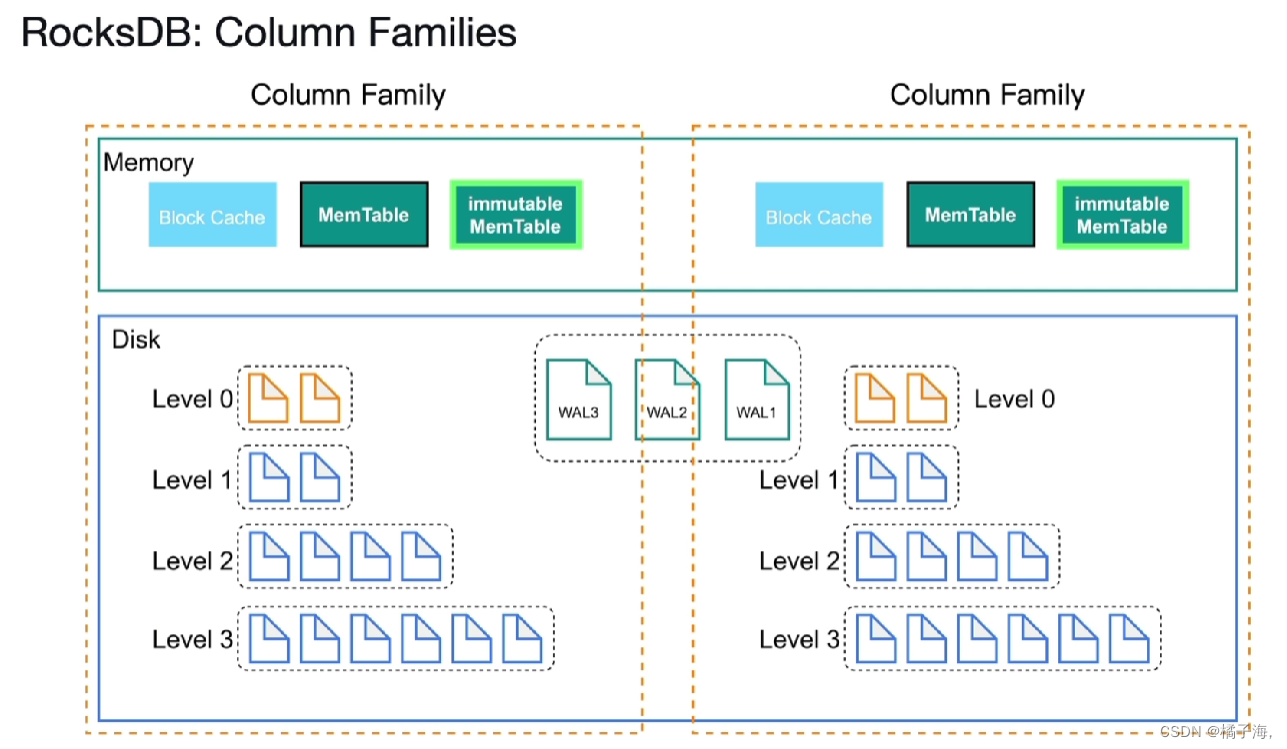
列簇方便对数据进行分片,可以将键值对按照不同的属性分配给不同的Column Family,用于区别不同的表
分布式事务
场景:当修改两条数据是,而且这两条数据分别存储在不同的TiKV,当第一条修改成功后,当要修改第二条数据时,第二个TiKV出现了问题,破环了的数据的原子性
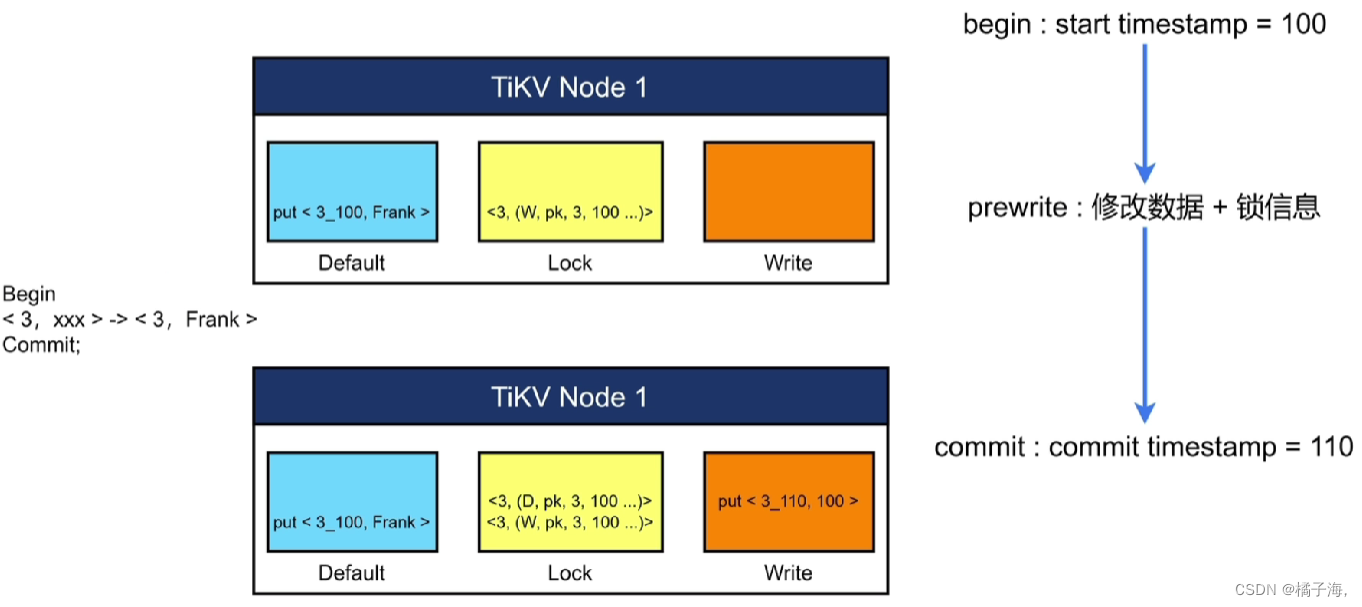
获得开始时间后,接下来把修改的数据读取到Server的内存中,首先在内存中进行修改,修改之后,当事务Commit之后,将修改的数据和锁信息写入TiKV中
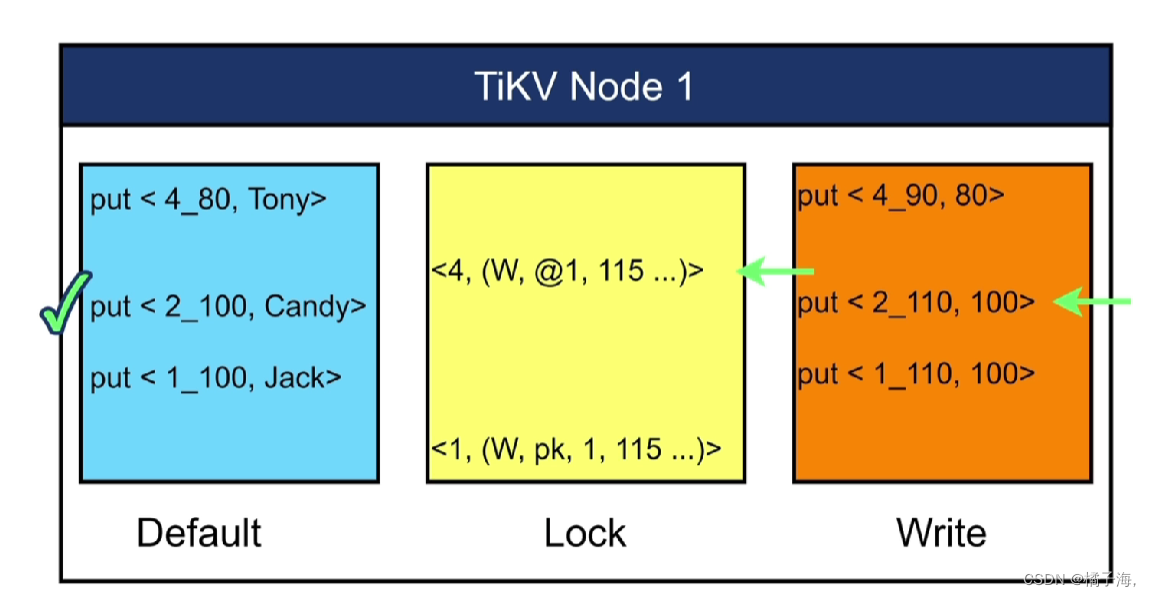
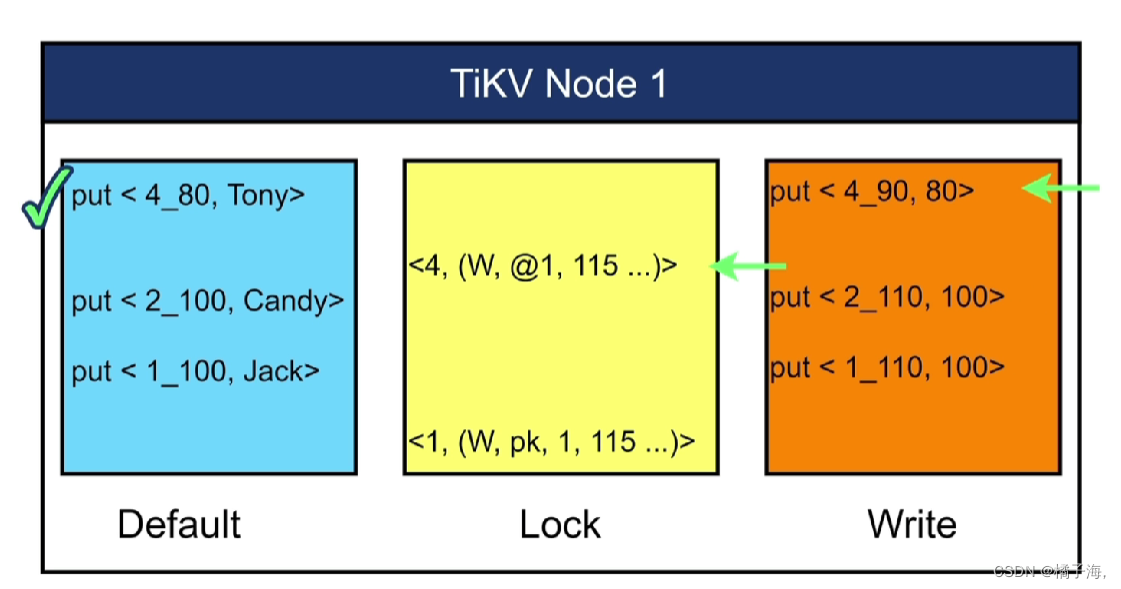
- Write列:当用户写入了一行数据时,如果该行数据长度小于255字节,那么会被存储write列中,否则的话该行数据会被存入到default列中
- Default列:用于存储超过255字节长度的数据
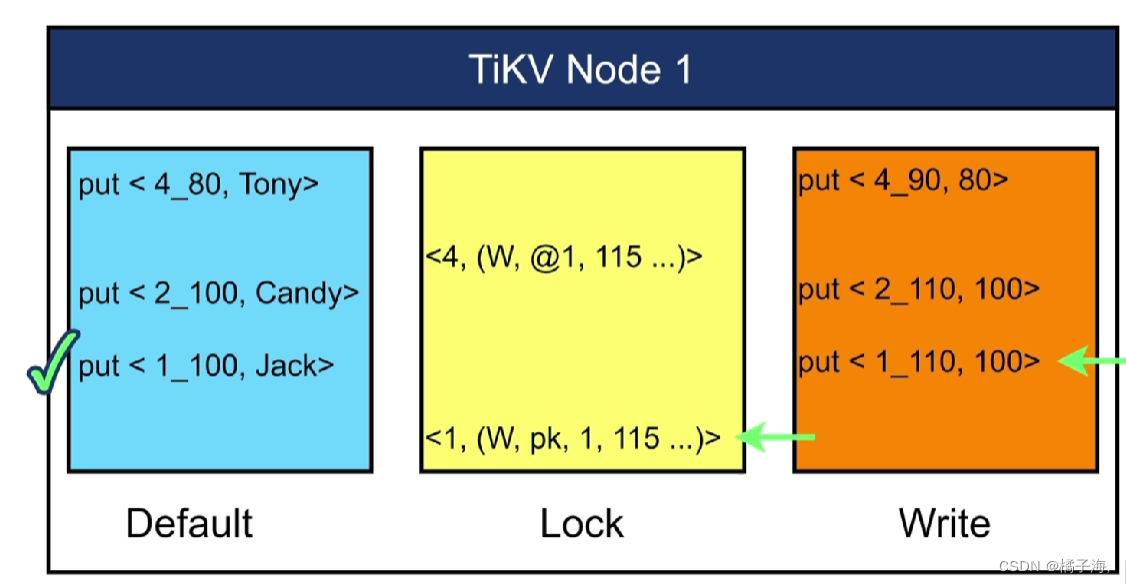
MVCC(多版本并发控制)
想让修改依然没有提交的时候可以读到这个值
在修改数据的时候会新生成一个副本,改其中一个,在此期间如果要读就读原来的数据,数据修改完成后提交后会给一个时间戳,以后读数据会读最新的数据

在此案例中,事务一已经提交,事务二没有提交,要在时间戳TSO=120的时候读取key=1,2,4的值,如果没有MVCC,只能读到2,如果有MVCC那么都能读出来
接下来看看它的具体实现
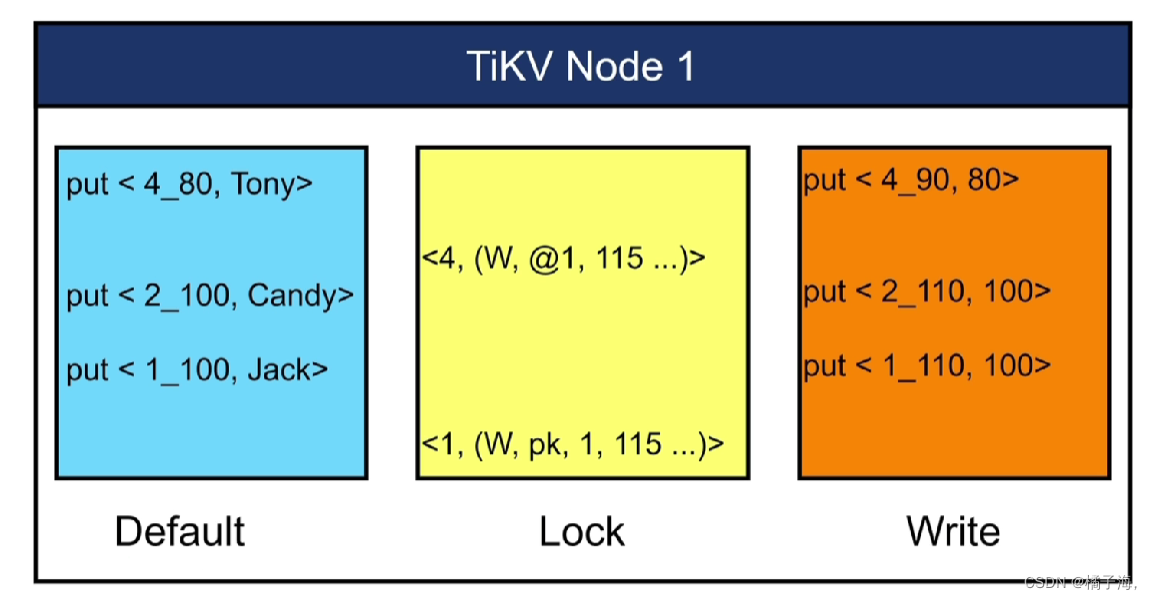
事务都是TiDB的悲观事务模式,也叫悲观锁:如果事务在修改的过程中,没有被commit,哪一行被修改这一行上面的锁能被其他会话感知到的,其他会话如果要修改这一行,那么会被阻塞。
Raft 与 Multi Raft
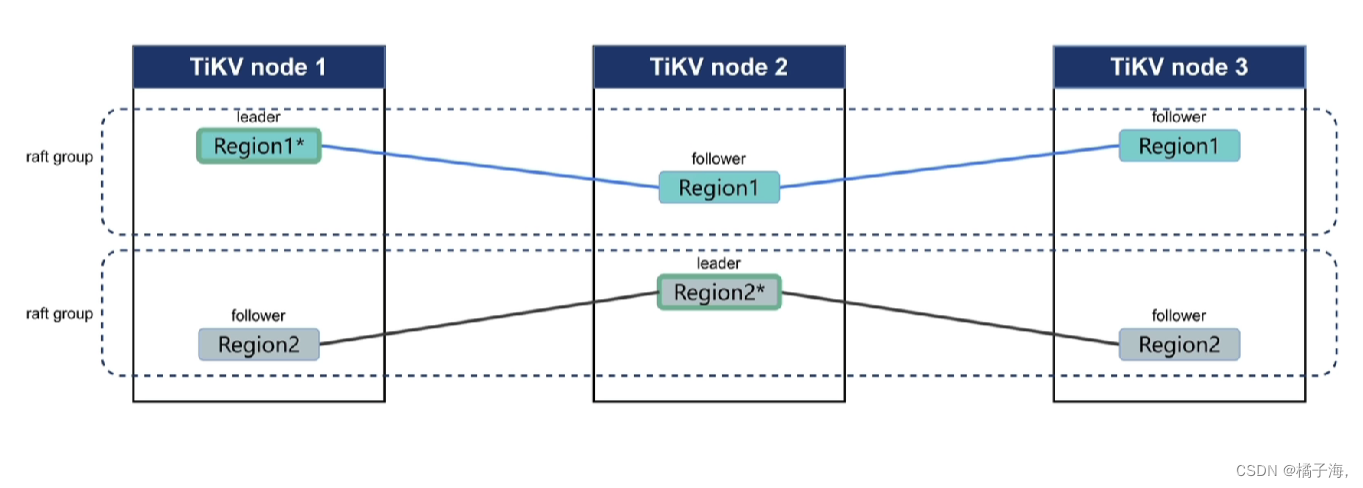
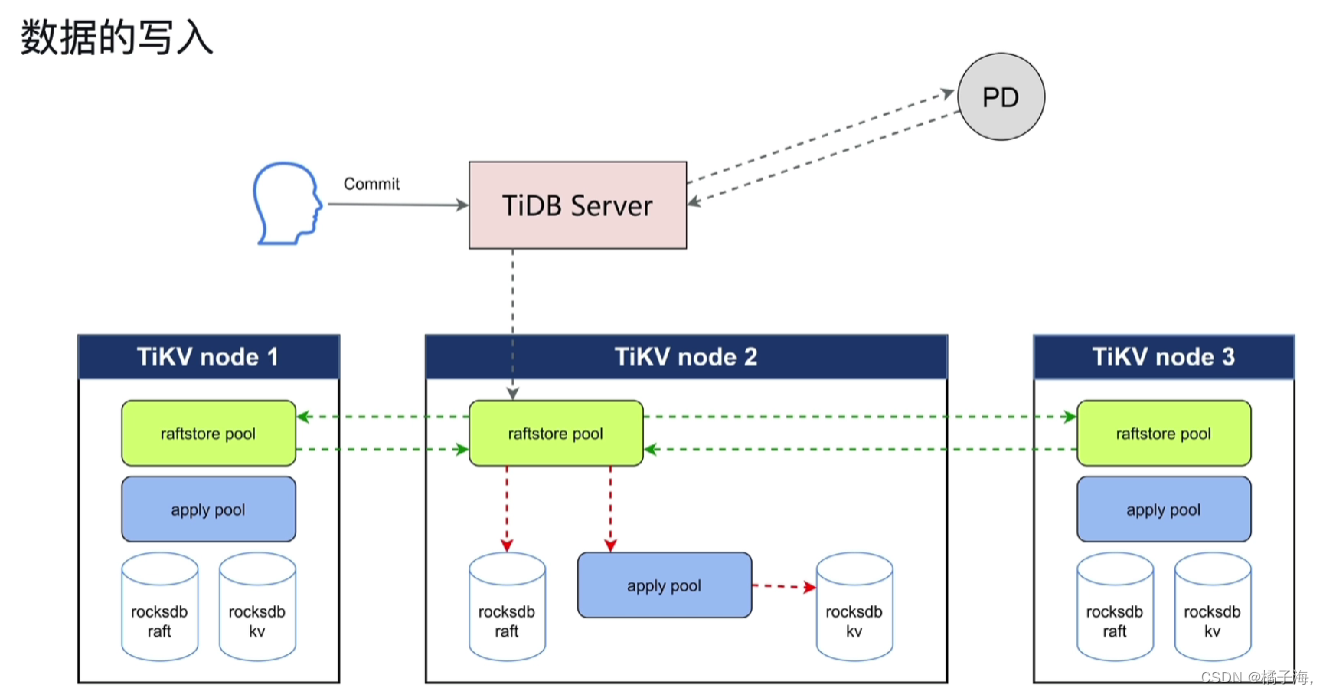
Leader: 整个集群的管理者,数据默认有三个副本,其中一个Region就是Leader,所有客户端的读写流量都是走Leader的,它会定期性的向follower发出通知信息,同时会把写的数据通过日志的方式传递给follower
follower: 就是被管理者,如果长时间收不到leader的统治信息,它就会把自己的角色转换为candidate,进行投票选新的leader
写数据的数据只写leader,然后通过日志方式向follower复制
region是可以分裂和合并的
一个region构成一个raft group
Raft日志复制
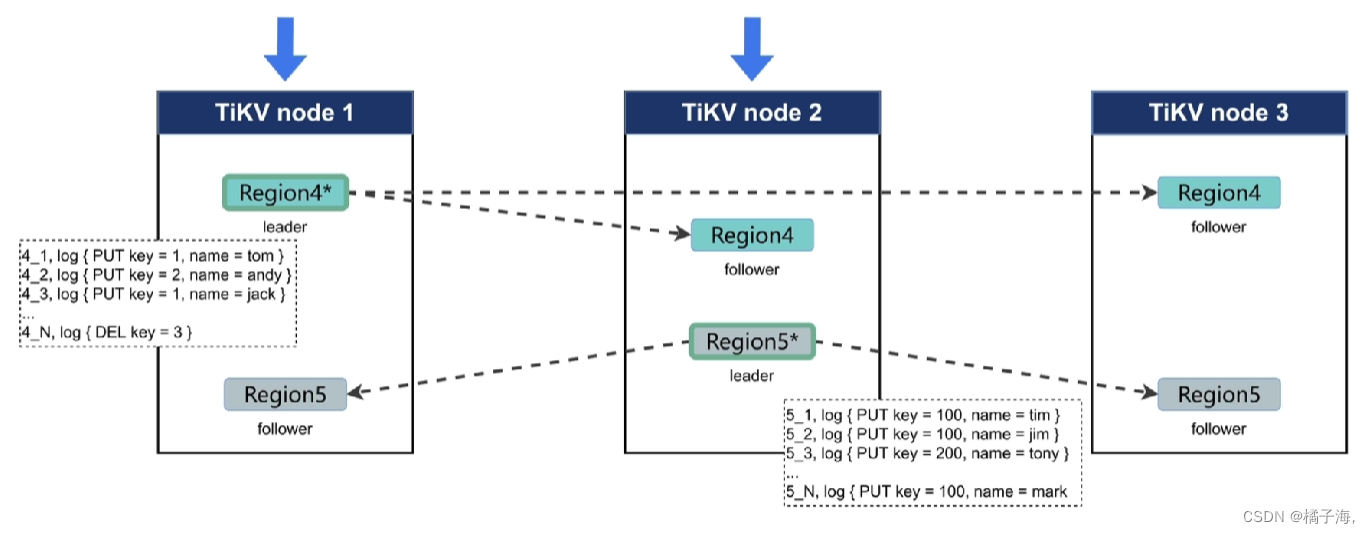
- propose:操作被leader收到了,leader准备开始同步,它会把写入请求变成一条一条的日志
- append:将raftDB日志写入到本地的RocksDB中
- replicate:leader通过raft算法将日志复制给follower,follower收到日之后也会把日志持久化到自己本地的RocksDB中,然会返回一个信息给leader,当leader收到大多数结点的成功信息后就会认为这条信息成功了
- committed
- apply
Raft Leader选举
term:就是被分成了一段一段的term,没有固定的长度
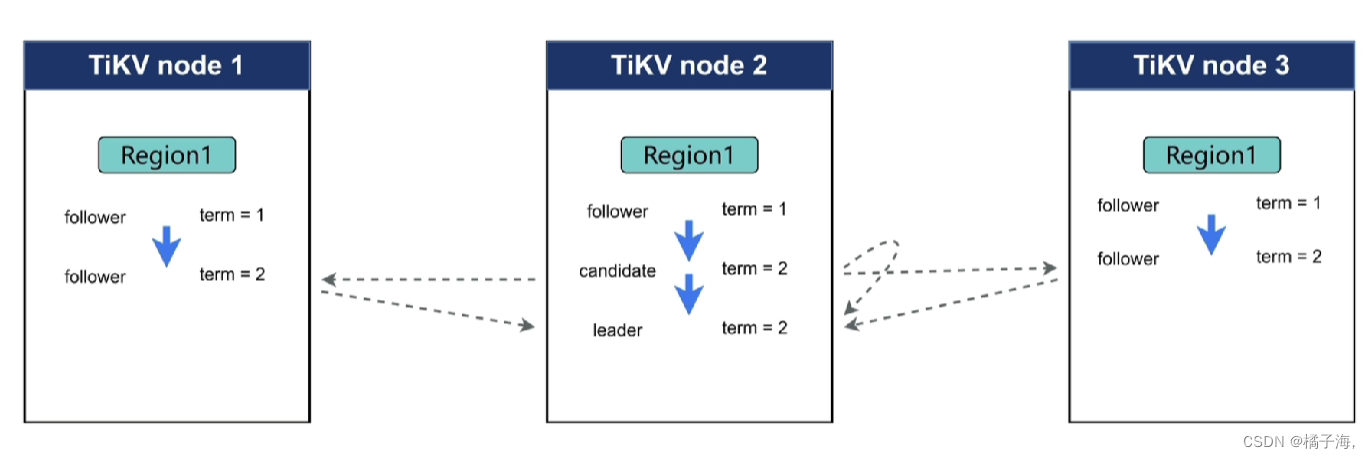
集群刚开始创建的时候是没有leader的,初始状态都是follower,每一个region都有一个计时器,叫做election timeout
当超出这个时间没有收到leader的通知,谁首先突破了election timeout,就会打破这个关系,角色变成candidate,发起选举,当一个TiKV收到的选举请求发起者的term比自己大是它就会同意这个请求
收到超过一半的结点都同意自己为leader,它的状态就会变成leader

数据的写入
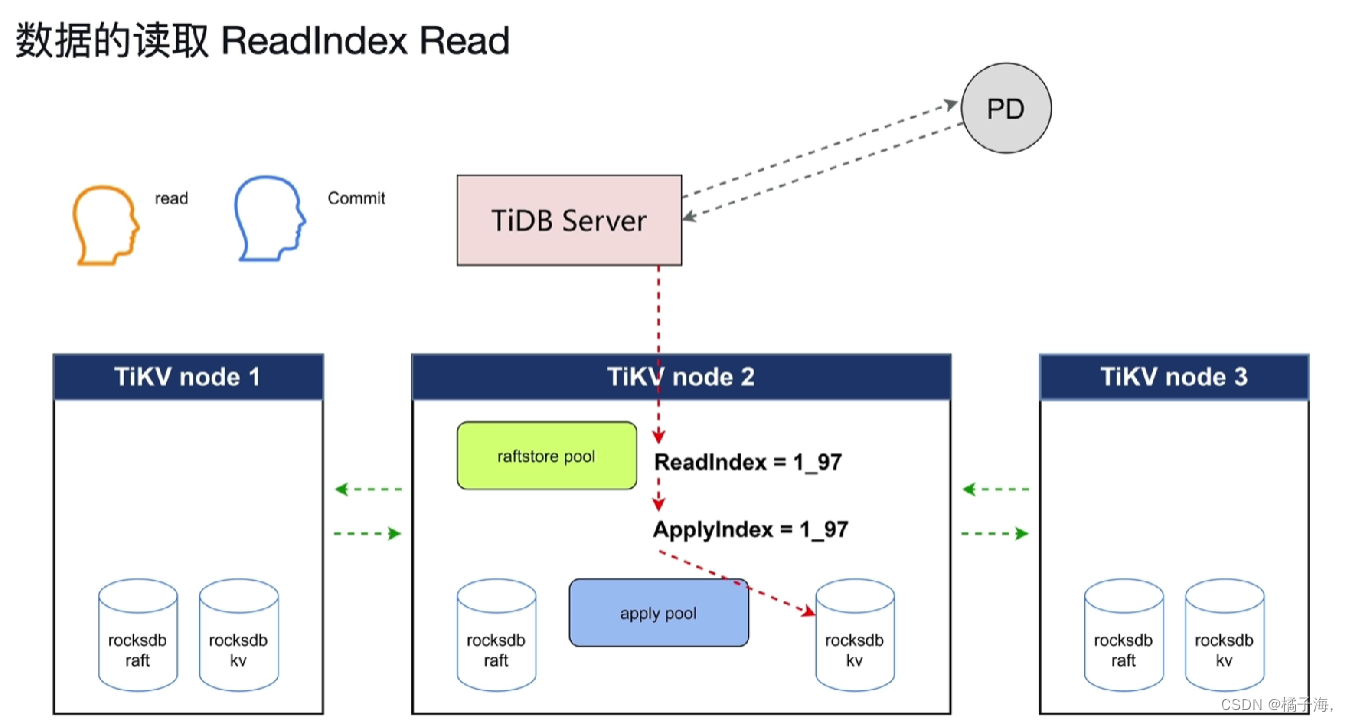
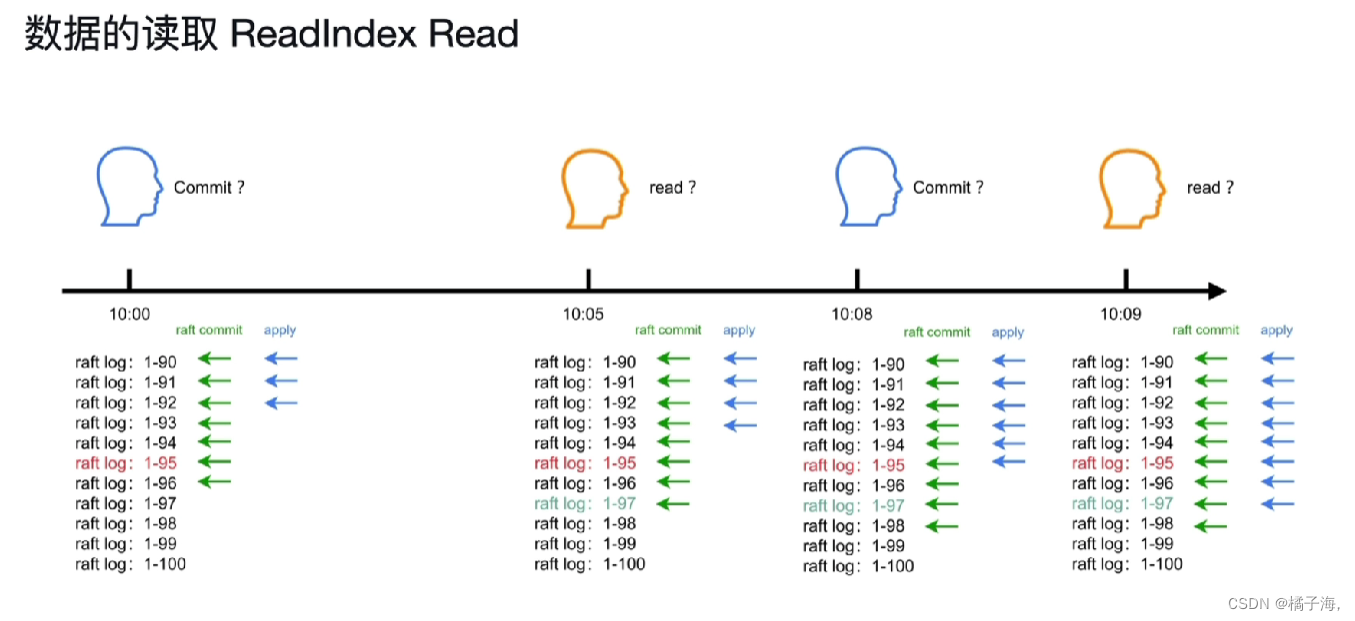
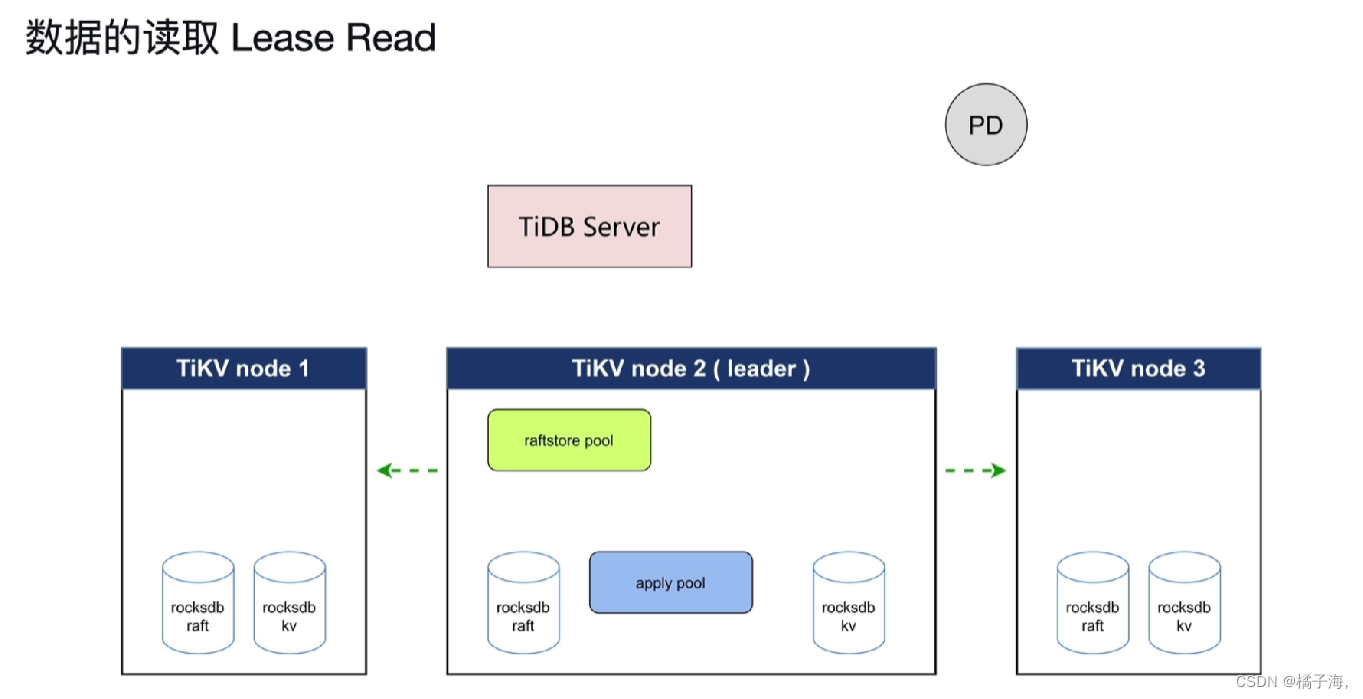
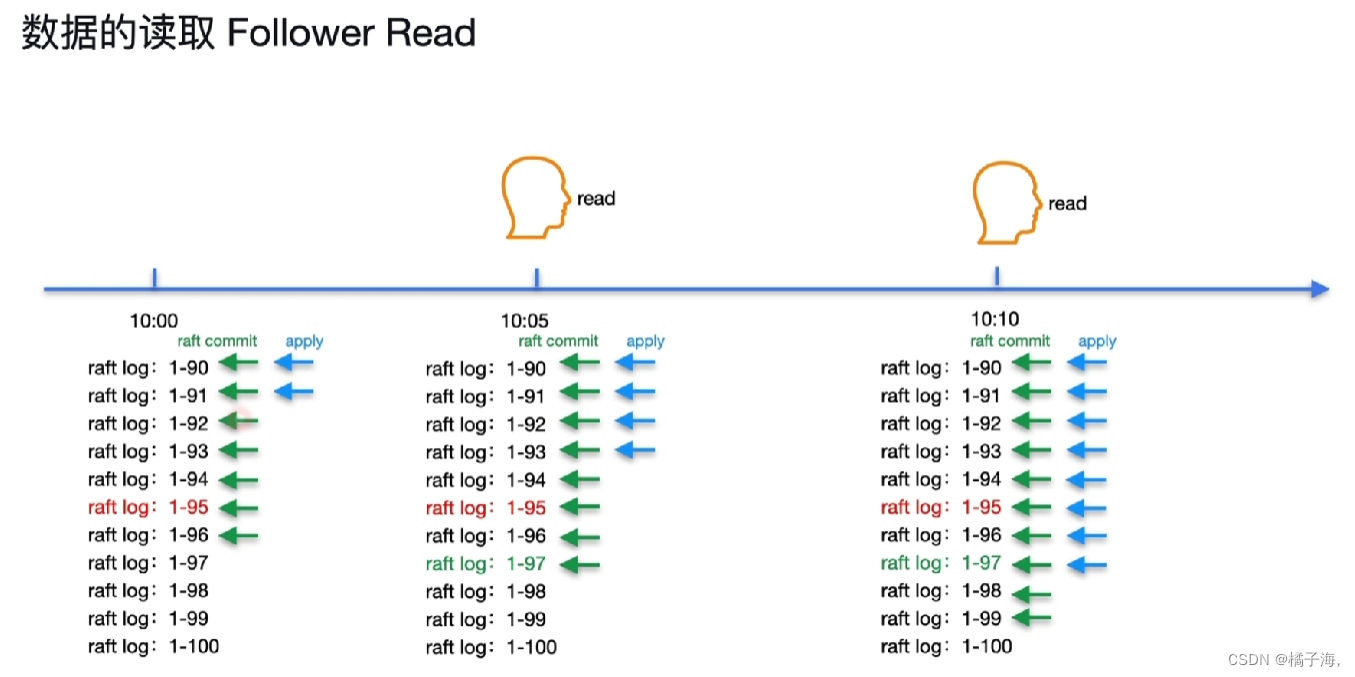
数据的读取

Coprocessor















 1149
1149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









