







案例分析:
今年的案例题 第一个必选题是 系统架构评估,文老师是押中了。
案例一:系统架构评估
1. 简述微服务架构 对比单体架构和微服务架构 微服务架构的优缺点。(7分)
答:微服务架构是一种分布式系统架构,将一个应用程序拆分为一组小型、独立的服务,每个服务都围绕特定的业务功能构建,并通过轻量级通信机制进行通信。相比之下,单体架构将整个应用程序作为一个单一的单元构建和部署。
微服务架构的优点:
- 灵活性和可扩展性:每个微服务都是独立的,可以独立部署和扩展,使系统更具弹性。
- 技术多样性:每个微服务可以使用不同的技术栈,使开发团队可以选择最适合其需求的技术。
- 易于理解和维护:微服务的小型化和聚焦性使得代码更易于理解、开发和维护。
微服务架构的缺点:
- 复杂性:微服务架构涉及到分布式系统,需要处理分布式事务、服务发现、服务治理等复杂问题。
- 部署和测试:由于微服务的数量增加,部署和测试变得更加复杂。
- 运维成本:微服务架构需要更多的运维工作,包括监控、日志收集、故障排查等。
2. 质量属性及其场景(质量效用树),填空6个。(6分)
就是一个质量效用树,忘了把哪几个空挖了,反正考察,安全性,可用性,功能性,可修改性
3. 用质量属性6要素描述e)和h)两条可用性的场景描述。(12分)
答:质量属性6要素描述:
e) 可连续运行时间不少于240h,断电或故障后10s内应重启
- 刺激源:断电或故障
- 刺激:系统故障或断电
- 制品:系统
- 环境:运行环境
- 响应:重启
- 响应度量:10秒内
h) 网络失效后,10s内应发起重新连接
- 刺激源:网络失效
- 刺激:网络失效
- 制品:系统
- 环境:网络环境
- 响应:重新连接
- 响应度量:10秒内
案例二:UML
1. 序列图的哪三种消息和概念。
送分题
答:序列图的三种消息和概念:
- 同步消息
- 异步消息
- 返回消息
2. 序列图补全填空。
3. 系统分析设计过程中两种交互图的选取原则。
解析:在UML中,交互图(Interaction Diagrams)主要用于描述在特定语境中对象之间的交互,它们可以在分析和设计阶段使用。交互图主要包括两种类型:序列图(Sequence Diagrams)和协作图(Collaboration Diagrams)。
- 序列图:强调消息的时间顺序,展示对象之间的动态合作关系,常用于分析阶段。
- 协作图:强调参与交互的对象以及它们如何相互关联,常用于设计阶段。
在分析阶段,你可能想要创建序列图来捕捉对象之间的动态合作,并且能够清晰地展示时序和并发。
在设计阶段,你可能想要创建协作图来定义交互模式,并且能够清晰地展示对象之间的静态关系和它们之间的关联。
4. 顺序图表示条件分支序列片段有哪些。
答:顺序图表示条件分支序列片段包括:
- Alt(Alternative)
- Opt(Option)
- Loop(循环)
- Break(中断)
- Par(并行)
区别总结
- Alt:用于条件分支,有多个互斥的条件。
- Opt:用于可选行为,只有一个条件。
- Loop:用于循环操作,根据条件重复执行。
- Break:用于中断行为,根据条件跳出当前片段。
- Par:用于并行操作,多个消息序列同时执行。
- Critical:用于临界区,确保操作的原子性。
- Neg:用于不应发生的行为,表示错误情况。
- Ref:用于引用其他序列图,实现模块化和重用。
案例三:分布式锁
基于MySQL实现分布式锁的缺点。(9分)
答对5项即可满分 送分题
- 性能瓶颈:MySQL数据库本身可能成为性能瓶颈,特别是在高并发情况下,大量的锁请求和释放可能导致数据库性能下降。
- 单点故障:MySQL单点的特性使得其成为系统的单点故障,如果数据库出现故障,将导致整个系统的分布式锁失效。
- 锁粒度问题:MySQL的锁粒度可能过大或者过小,过大的锁粒度会导致并发性能降低,而过小的锁粒度可能会增加锁冲突的概率,影响系统的并发性能。
- 数据一致性问题:分布式系统中,不同的数据库节点之间的数据同步可能存在延迟或者不一致的情况,这可能导致分布式锁的有效性受到影响。
- 扩展性差:随着系统规模的扩大,单个MySQL数据库可能无法满足系统的性能和容量需求,需要进行垂直或者水平扩展,这会增加系统的复杂性和成本。
- 容错性差:MySQL数据库本身的容错性可能不如专门设计的分布式锁方案,例如基于ZooKeeper或者Redis的分布式锁方案,因此在面对网络分区或者其他故障时可能无法提供可靠的锁服务。
举一个产生Redis分布式锁死锁的场景。(10分)
描述清楚即可满分,送分题
一个可能导致Redis分布式锁死锁的场景是:
假设有两个客户端同时请求获取同一把分布式锁,并且两个客户端的请求几乎同时到达Redis服务器。此时,两个客户端都成功地获取了锁,并开始执行各自的任务。然而,由于某些原因(例如网络延迟、服务器负载等),其中一个客户端在执行任务时花费的时间较长,导致其持有锁的时间超过了预期。在此期间,另一个客户端一直在等待获取锁,因为它无法在锁被释放之前执行任务。
当第一个客户端最终完成任务并释放锁时,第二个客户端会立即获取到锁并开始执行任务。但此时第一个客户端可能又尝试获取锁以执行另一个任务,由于第二个客户端已经获取到了锁,因此第一个客户端将被阻塞等待获取锁,导致死锁的发生。
这种情况下,由于两个客户端的请求在一段时间内交替执行,每个客户端都等待另一个客户端释放锁,最终导致了死锁的产生。为避免这种情况,需要在设计分布式锁的使用场景时考虑合理的超时机制和重试策略,以及确保释放锁的操作能够及时执行。
3. 填写Redis命令,基于ZSet。(6分)
关于nosql平时都是关注的理论层面的,集群,主从,同步,分片等等。没想到现在考的都是实践层面的,我在这儿也翻了船,看来以后的各个培训机构要在这块开设专题了,
答案:
- 存入秒杀的分数命令:ZADD
- 获取分数范围的命令:ZRANGE
- 获取分数:ZSCORE
解析:Redis zset扩展学习
在Redis中,ZSet(有序集合)是一种数据结构,用于存储带有分数(score)的成员(member)。以下是针对ZSet的常用操作命令:
- ZADD key score member [score member ...]
将一个或多个成员元素及其分数值加入到有序集合中。
- ZCARD key
返回有序集合中的成员数量。
- ZSCORE key member
返回有序集合中指定成员的分数。
- ZRANGE key start stop [WITHSCORES]
返回有序集合中指定索引范围内的成员,可选择返回成员的分数。
- ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
返回有序集合中分数范围内的成员,可选择返回成员的分数,并可指定返回结果的偏移量和数量。
- ZREM key member [member ...]
移除有序集合中的一个或多个成员。
- ZINCRBY key increment member
将有序集合中指定成员的分数增加增量 increment 。
- ZCOUNT key min max
计算有序集合中分数范围内的成员数量。
- ZREVRANGE key start stop [WITHSCORES]
返回有序集合中指定逆序索引范围内的成员,可选择返回成员的分数。
- ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
返回有序集合中指定逆序分数范围内的成员,可选择返回成员的分数,并可指定返回结果的偏移量和数量。
案例四:嵌入式的题
1.简要分析some/ip协议及其特点 (9分)
SOME/IP是一种应用层协议,它允许在车辆内部网络中实现高效的服务交换和远程调用。这种协议支持车辆各组件之间的复杂通信需求,特别适用于具有高数据吞吐量的场景。基于TCP/IP,支持TCP和UDP。
特点:
服务导向架构 (Service-Oriented Architecture, SOA)SOME/IP实现了一种服务导向架构,允许车辆的各个电子控制单元(ECUs)以服务提供者或服务消费者的身份互动。这种架构使得车辆内部的软件组件可以更加灵活地通信和交互。
远程过程调用 (Remote Procedure Call, RPC)
通过RPC,SOME/IP支持跨网络的函数或过程调用,实现不同ECU之间的紧密协作。
高度可伸缩性和灵活性 (Scalability and Flexibility)
SOME/IP协议的设计考虑到了未来车辆网络可能的扩展,支持从小型车辆到大型车队的不同规模应用。
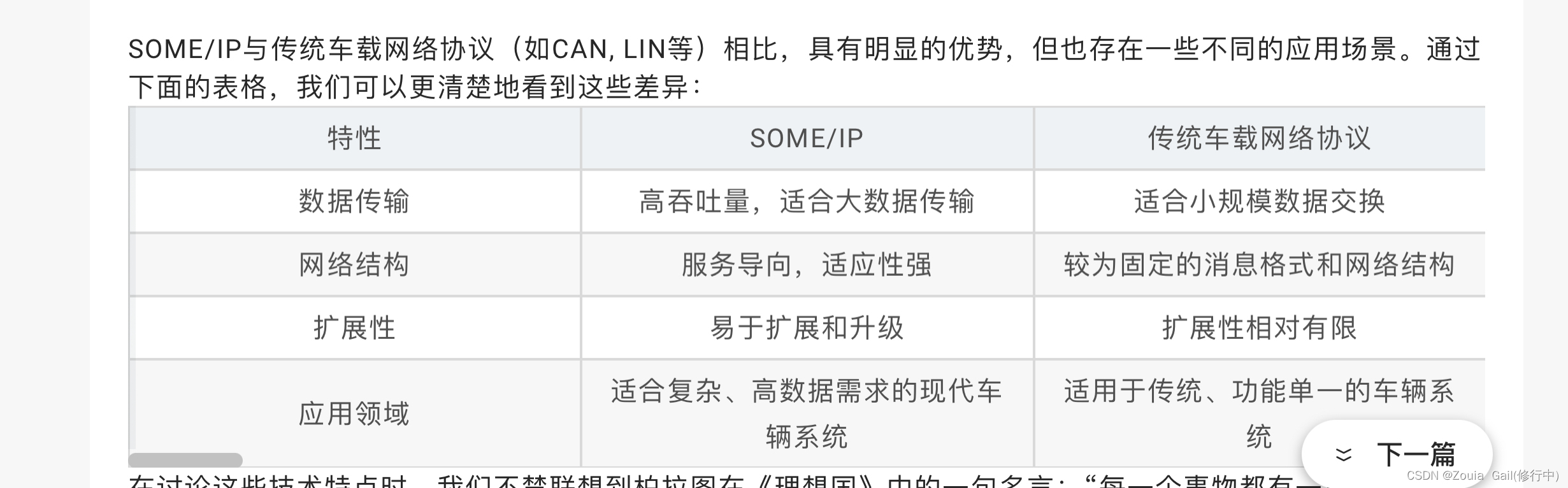
2.填写DDS协议和some/ip协议到以下框图。(6分)
分析:一般dds用于框架模块内部之间通信,some/ip用于外部设备间通信。
参考:(来源于网络,侵权可删除)
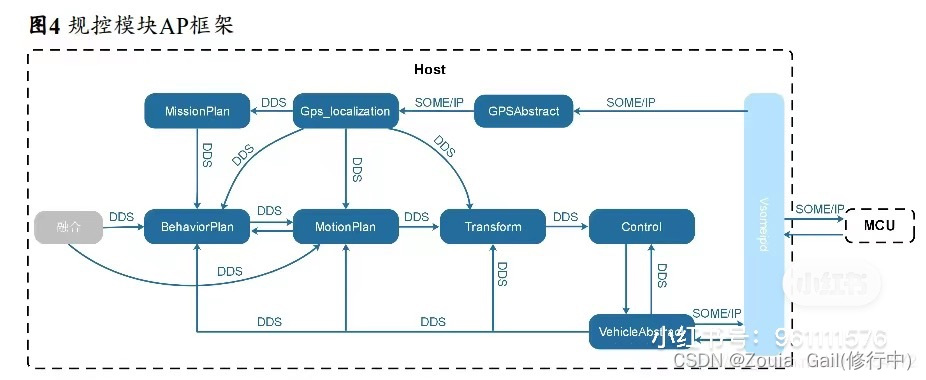
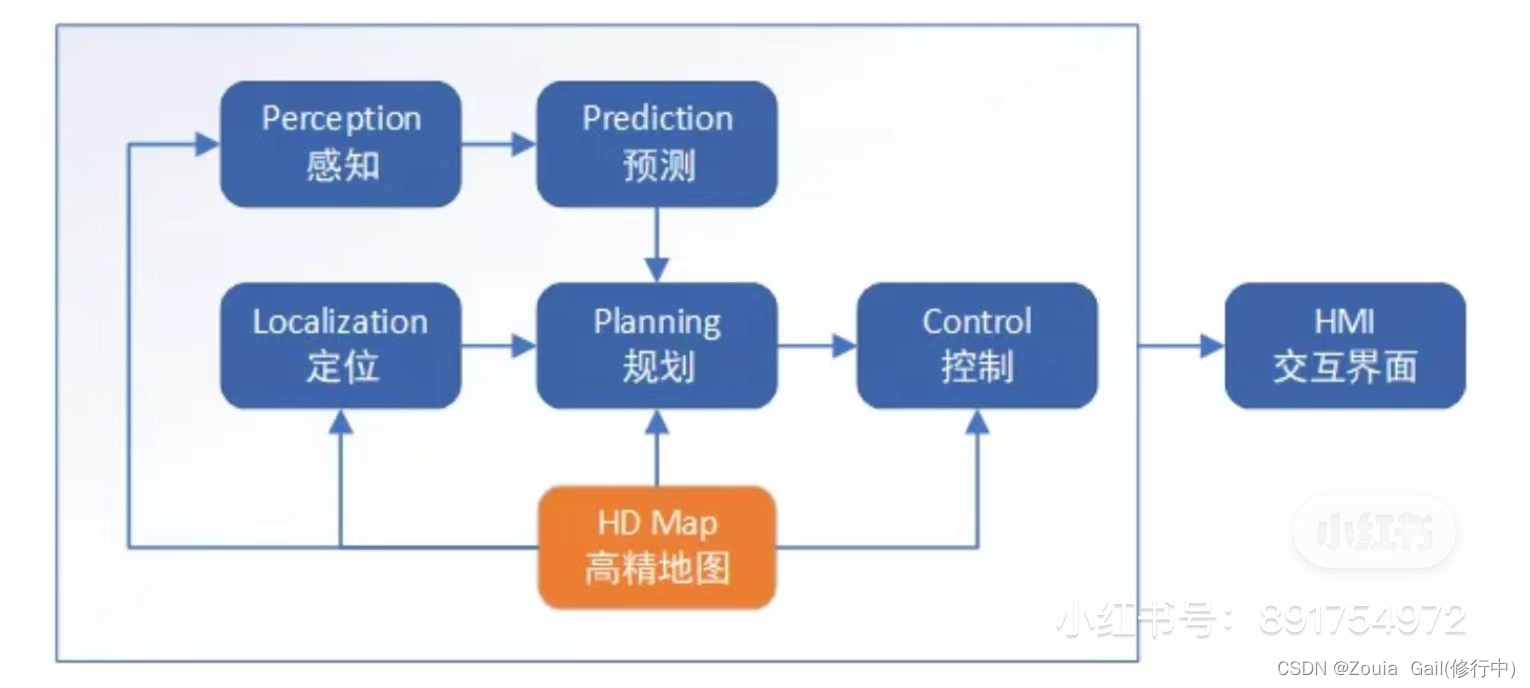
3.规控AP模块的流程框图(10分)。
分析:地图先定位,结合感知模块进行感知,对当前实时环境中的其他目标进行预测,然后规划路径,路径会考虑道路中其他参与者,有路径后交给控制决策车怎么走,然后控制信息传递给交互界面。
参考:(来源于网络,侵权可删除)
案例五:系统设计
1. 系统架构图填空,7个空。(11分)
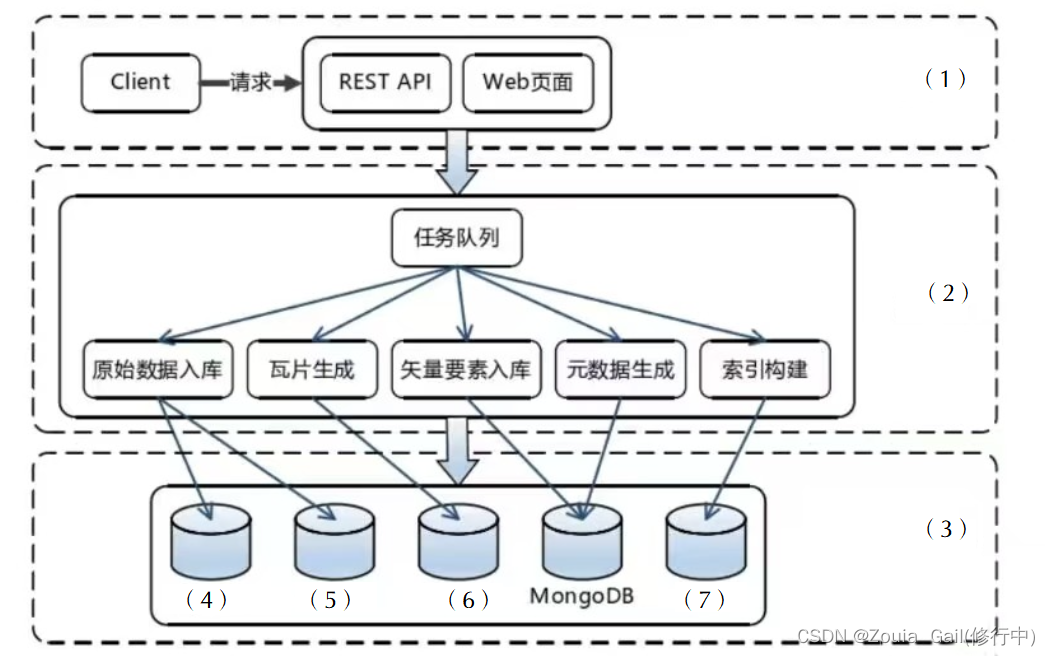
解析:
此处有争议。答案和解析仅供参考,以官方的答案为准,在此大家就不要争论了。
目前大家 对瓦片地图用 HDFS存储还是用Hbase 存储比较有争议,但是这道题来自华中科技大学的硕士论文,如下图。所以标准答案可能就按照论文里面的来了。瓦片地图一般有两种。一般我们理解的瓦片地图是栅格瓦片。这块的瓦片数据没有说明是栅格瓦片还是矢量瓦片。如果是栅格瓦片HDFS应该优先使用。矢量瓦片可能是以JSON结构组装,用Hbase。

瓦片数据和相关的存储方案在选择时确实需要根据数据类型(栅格瓦片或矢量瓦片)来决定。
1. 栅格瓦片(Raster Tiles):
- 描述:栅格瓦片是由像素组成的图像数据,通常用于地图、卫星图像等。
- 适用场景:适合存储在HDFS(Hadoop Distributed File System)中,因为HDFS擅长处理大文件和顺序读取。栅格瓦片通常是大文件,HDFS的设计优化了这种类型的数据存储和处理。
- 存储建议:使用HDFS存储栅格瓦片数据,因为HDFS提供了高吞吐量的读写性能,并且能够很好地扩展来处理大量的数据。
2. 矢量瓦片(Vector Tiles):
- 描述:矢量瓦片是基于矢量数据的瓦片格式,通常以JSON、MVT(Mapbox Vector Tiles)等格式存储,包含点、线、多边形等地理信息。
- 适用场景:适合使用HBase存储,因为HBase是一个分布式、面向列的数据库,擅长处理大量的小文件和随机读写操作。矢量瓦片的数据结构(如JSON)可以很好地映射到HBase的列族和列中。
- 存储建议:使用HBase存储矢量瓦片数据,因为HBase提供了低延迟的随机读写性能,并且可以高效地存储和查询结构化和半结构化数据。
总结:
- 栅格瓦片:优先使用HDFS存储,以利用其高吞吐量和大文件处理能力。
- 矢量瓦片:优先使用HBase存储,以利用其高效的小文件处理和低延迟随机读写能力。
2.MongoDB如何存储非结构性数据的,MongoDB 矢量化存储的优点(10分)
MongoDB 是一个基于分布式文件存储的NoSQL数据库,它使用一种灵活的、面向文档的数据模型来存储非结构化数据。以下是MongoDB存储非结构化数据的方式及其矢量化存储(虽然MongoDB官方并没有直接使用“矢量化存储”这一术语,但我们可以理解为处理和存储复杂数据结构的能力)的一些优点:
MongoDB存储非结构化数据的方式:
1. 文档存储:MongoDB以BSON(Binary JSON)格式存储数据,这是一种类JSON的二进制格式,支持更丰富的数据类型(比如Date、ObjectId等),比传统的JSON更高效。每个文档可以包含任意数量的字段,字段值可以是数组、嵌套文档等多种复杂数据结构,非常适合存储半结构化和非结构化数据。
2. 灵活的数据模型:MongoDB不强制要求数据遵循固定的模式,同一个集合(相当于关系数据库中的表)中的文档可以有不同的字段和结构。这使得MongoDB能轻松适应不断变化的数据需求,特别适合存储那些模式不固定或经常演变的数据。
3. 动态模式:MongoDB的集合不需要预先定义结构,字段可以随时添加或删除,这为非结构化数据的存储提供了极大的灵活性。
4. 索引支持:尽管数据是非结构化的,MongoDB仍然支持对文档中的任何字段创建索引,包括嵌套字段,这大大提升了查询性能。
MongoDB矢量化存储(处理复杂数据结构)的优点:
1. 高效存储与查询:BSON格式不仅支持复杂数据类型,还能高效地存储和查询这些数据。通过利用索引,即使是嵌套文档和数组也能实现快速查询。
2. 简化数据模型:通过文档嵌套和数组,可以将相关数据聚合在一个文档中,减少了数据的连接操作,简化了数据模型,提高了查询效率。
3. 易于扩展与演变:由于数据模型的灵活性,MongoDB能够轻松应对数据结构的变化,无需进行复杂的模式迁移,简化了系统升级和扩展的过程。
4. 高性能:MongoDB使用内存映射文件技术,能够将热数据加载到内存中,提高读写性能。同时,支持水平扩展和分片,能够处理大量数据和高并发请求。
5. 数据处理能力:对于非结构化数据的分析和处理,MongoDB提供了丰富的聚合框架,支持复杂的数据转换和分析操作,如聚合管道、地图reduce等,便于从非结构化数据中提取有价值的信息。
3.使用热数据、温数据和冷数据存储的原因。(4分)
使用热数据、温数据和冷数据存储的原因及好处主要包括以下几点
答出原因或者优点 任意4点即可满分
解析:
原因:
1. 资源优化:不同数据的访问频率差异巨大,将数据按照热度分类可以更合理地分配存储资源。热数据通常需要快速访问,因此存储在高性能、高成本的媒介上;而冷数据访问较少,可以存储在低成本、低速的媒介上。
2. 成本效率:通过区分数据的访问频率,企业可以将有限的预算投入到最关键的数据存储上,如使用SSD或RAM存储热数据,而冷数据则存储在磁带或蓝光光盘上,这样既能保证关键业务的性能,又能控制存储成本。
3. 性能提升:将频繁访问的热数据放置在快速存储设备上,如SSD或内存,可以显著减少数据访问延迟,提高应用响应速度。而冷数据存储在低速设备上对整体系统性能影响较小。
4. 数据保护:对于冷数据,虽然访问频率低,但可能需要长期保存,使用耐久性高的存储介质可以确保数据的安全与持久。
5. 扩展性和灵活性:随着数据量的增长,分层存储策略提供了更好的扩展性,可以根据数据增长和访问模式的变化灵活调整存储策略。
优点:
1. 提升效率:确保高访问频度的数据能够迅速被获取,提升用户体验和业务处理速度。
2. 降低成本:通过将不常访问的数据转移到成本较低的存储介质,减少整体存储成本。
3. 资源利用率最大化:高效利用存储资源,避免高性能存储资源被低访问频度数据占用。
4. 增强数据管理能力:便于数据生命周期管理,如数据归档、备份和恢复策略的实施。
5. 适应业务变化:灵活调整数据存储布局,快速响应业务需求变化,支持业务的持续创新与发展。
综上所述,依据数据热度进行分类存储是一种策略,旨在通过智能地分配存储资源,平衡成本与性能,确保关键业务数据的高效访问,同时合理管理数据生命周期,从而实现整体IT架构的优化。



















 1509
1509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











