







EasyExcel导入数据(合并单元格)
需要导入的数据格式
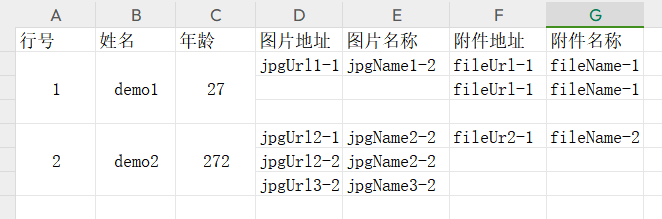
最终解析结果
[
{
"name": "demo1",
"age": 27,
"jpgList": [
{
"id": null,
"jpgUrl": "jpgUrl1-1",
"jpgName": "jpgName1-2"
}
],
"jpgUrl": "jpgUrl1-1",
"jpgName": "jpgName1-2",
"fileList": [
{
"id": null,
"fileUrl": "fileUrl-1",
"fileName": "fileName-1"
},
{
"id": null,
"fileUrl": "fileUrl-1",
"fileName": "fileName-1"
}
],
"fileUrl": "fileUrl-1",
"fileName": "fileName-1",
"rowNum": 1
},
{
"name": "demo2",
"age": 272,
"jpgList": [
{
"id": null,
"jpgUrl": "jpgUrl2-1",
"jpgName": "jpgName2-2"
},
{
"id": null,
"jpgUrl": "jpgUrl2-2",
"jpgName": "jpgName2-2"
},
{
"id": null,
"jpgUrl": "jpgUrl3-2",
"jpgName": "jpgName3-2"
}
],
"jpgUrl": "jpgUrl2-1",
"jpgName": "jpgName2-2",
"fileList": [
{
"id": null,
"fileUrl": "fileUr2-1",
"fileName": "fileName-2"
}
],
"fileUrl": "fileUr2-1",
"fileName": "fileName-2",
"rowNum": 2
}
]
1. 导入接口controller
/**
* 读取excel信息1
* @param base
*/
@PostMapping("/demo1")
public void demo1(@RequestParam("base") MultipartFile base) throws IOException {
DemoDataListener<ExcelDemoDTO> listener = new DemoDataListener<>();
EasyExcel.read(base.getInputStream(), ExcelDemoDTO.class,listener)
// 需要读取批注 默认不读取
.extraRead(CellExtraTypeEnum.COMMENT)
// 需要读取超链接 默认不读取
.extraRead(CellExtraTypeEnum.HYPERLINK)
// 需要读取合并单元格信息 默认不读取
.extraRead(CellExtraTypeEnum.MERGE).sheet(0).doRead();
List<ExcelDemoDTO> list = listener.getList();
log.info("解析到的数据:{}", JSONObject.toJSONString(list));
}
2. excel对应的实体对象
2.1. ExcelDemoDTO excel对应的实体对象
@Data
public class ExcelDemoDTO {
@ExcelProperty("行号")
@GoodsExcelImportAOP
private Integer RowNum;
@ExcelProperty("姓名")
private String name;
@ExcelProperty("年龄")
private Integer age;
@ExcelImportAOP
private List<ExcelJpgDTO> jpgList;
@ExcelProperty("图片地址")
private String jpgUrl;
@ExcelProperty("图片名称")
private String jpgName;
@ExcelImportAOP
private List<ExcelFileDTO> fileList;
@ExcelProperty("附件地址")
private String fileUrl;
@ExcelProperty("附件名称")
private String fileName;
}
2.2. ExcelJpgDTO 需要合并的图片信息
@Data
public class ExcelJpgDTO {
private Integer id;
@ExcelProperty("图片地址")
private String jpgUrl;
@ExcelProperty("图片名称")
private String jpgName;
}
2.3. ExcelFileDTO 需要合并的附件信息
@Data
public class ExcelFileDTO {
private Integer id;
@ExcelProperty("附件地址")
private String fileUrl;
@ExcelProperty("附件名称")
private String fileName;
}
2.4. 自定义注解 @GoodsExcelImportAOP(唯一标识)
这个注解标记唯一标识,主要是用于标记返回的数据;如果被标记的这个字段为空,是不会返回到返回结果里面的
/**
* @Description
* 标记excel解析数据是唯一标识,只有被标记的这个字段不为空的时候才会往excel返回结果里放
* @Date 15:15 2023/12/1
* @Param
* @Return
**/
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface GoodsExcelImportAOP {
}
2.5. 自定义注解@ExcelImportAOP
这个注解被标识的字段,会被合并处理;最终将不用合并单元格的数据,组装成list放到返回结果的数据里面
/**
* @Description 合并单元格注解,标记该注解,在解析数据的时候,就会往该字段的list中放入数据
* @Date 15:15 2023/12/1
* @Param
* @Return
**/
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface ExcelImportAOP {
}
3. 定义读取数据的监听器DemoDataListener
3.1. 继承ReadListener
3.1.1 重写 invoke 方法(解析到每一行都会调用该方法)
/**
* 解析到每一行数据的时候调用的方法
* 这个地方如果,没有合并单元格的话,实际上就不会读取到了,所以就不会有那么多空行的数据
* @param t one row value. It is same as {@link AnalysisContext#readRowHolder()}
* @param analysisContext analysis context
*/
@Override
public void invoke(T t, AnalysisContext analysisContext) {
log.info("解析到一条数据:{}", JSONObject.toJSONString(t));
this.dataChange(t);
}
3.1.1.1 处理数据的方法 dataChange
private void dataChange(T t) {
// 获取excel获取的行数据
Class<?> dataClass = t.getClass();
// 获取字段信息
Field[] declaredFields = dataClass.getDeclaredFields();
for (Field field : declaredFields) {
field.setAccessible(true);
//判断唯一标识,并且唯一标识的值不为空的时候,往放回结果中增加一条记录
this.onlyflagSetData(t, field);
//处理需要合并子项的数据
this.processingMegerData(t, declaredFields, field);
}
}
3.1.1.2 判断唯一标识,处理方法 onlyflagSetData
这个方法的目的其实就是为了,判断唯一标识的数据不为空的时候才往返回结果的list中放入;并且会将需要合并的数据放入对应的list对象当中
这个唯一标识实际上是一个注解标识过的也就是上面提到的**@GoodsExcelImportAOP **自定义注解
/**
* @Description 判断唯一标识,并且唯一标识的值不为空的时候,往放回结果中增加一条记录
* @Date 11:45 2023/12/1
* @Param [t, field]
* @Return void
**/
private void onlyflagSetData(T t, Field field) {
// 判断是否有唯一标识的注解
GoodsExcelImportAOP onlyflag = field.getAnnotation(GoodsExcelImportAOP.class);
if (Objects.nonNull(onlyflag)){
try {
Object fieldvalue = field.get(t);
// 判断唯一标识的值不为空的时候才能添加返回数据
if (Objects.nonNull(fieldvalue)) {
list.add(t);
}
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
}
}
3.1.1.3 处理合并单元格的数据 processingMegerData(其实就是将不需要合并单元格的数据放到对应的list当中)
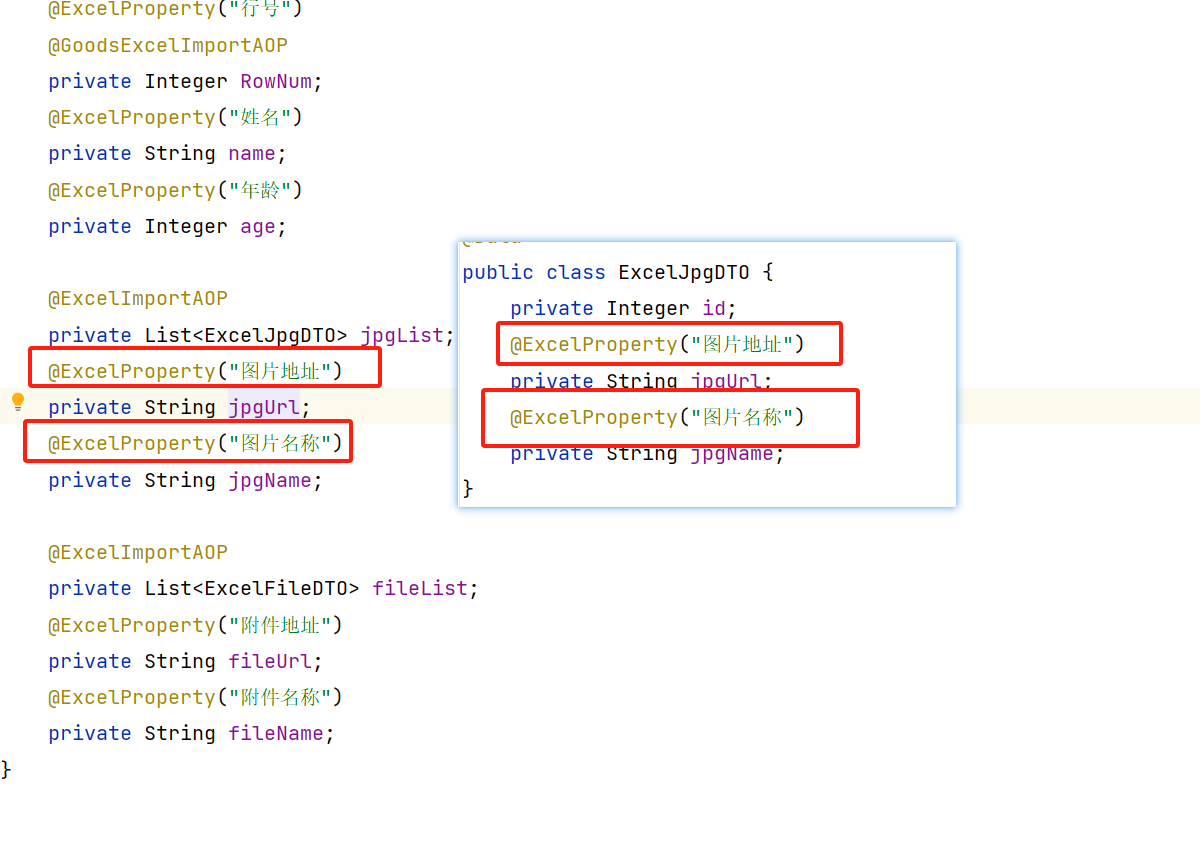
这里其实也是通过自定义注解实现的也就是上面提到的 **@ExcelImportAOP **被标识的字段,会被解析为list,最终会往这个list中放入数据;(这里其实可以被优化一下,目前只能被解析为list数据);
另外需要注意的是,被标记的这个字段的泛型类型对象,被标记的@ExcelProperty,这个标记是easyexcel自带的注解,这个注解里面的value值要和原来数据的面被标记**@ExcelProperty**这个注解字段的value值保持一致,只有这样才能被解析出来,并通过放射的方式初始化,并设置相应的值
上面说的还是有些抽象,下面通过代码来说明一下:
其实就是需要对应字段被**@ExcelProperty**中的value值一样的会被解析到对应的数据当中
/**
* @Description 处理需要合并子项的数据
* @Date 11:47 2023/12/1
* @Param [t, declaredFields, field]
* @Return void
**/
private void processingMegerData(T t, Field[] declaredFields, Field field) {
// 判断字段上是否有注解
ExcelImportAOP excelImportAOP = field.getAnnotation(ExcelImportAOP.class);
if (Objects.nonNull(excelImportAOP)){
// 获取到list 的参数类型
ParameterizedType genericType = (ParameterizedType) field.getGenericType();
// 获取对应list泛型的class
Class<?> actualTypeArgument = (Class<?>)genericType.getActualTypeArguments()[0];
// 获取到泛型类型的所有字段信息
Field[] actualDeclaredFields = actualTypeArgument.getDeclaredFields();
try {
// 创建泛型类型的实体对象
Object o = actualTypeArgument.newInstance();
// 循环泛型的字段信息
for (Field declaredField : actualDeclaredFields) {
declaredField.setAccessible(true);
ExcelProperty excelProperty = declaredField.getAnnotation(ExcelProperty.class);
if (Objects.nonNull(excelProperty)){
String string = JSONObject.toJSONString(excelProperty.value());
// 循环原本的字段,如果设置的excel标题名称一致就赋值
for (Field declaredField1 : declaredFields) {
declaredField1.setAccessible(true);
ExcelProperty annotation = declaredField1.getAnnotation(ExcelProperty.class);
if (Objects.nonNull(annotation)){
String string1 = JSONObject.toJSONString(annotation.value());
// 如果写的名称一致,就设置值
if (string1.equals(string)){
declaredField.set(o, declaredField1.get(t));
}
}
}
}
}
// 获取字段中最后一个值
T tdata = list.get(list.size() - 1);
Object mergeObject = field.get(tdata);
List mergeList = Objects.nonNull(mergeObject) ? (List) mergeObject : new ArrayList<>();
mergeList.add(o);
// 设置合并字段的值
field.set(t,mergeList);
} catch (InstantiationException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
}
}
3.1.2. 额外信息解析 extra(批注、超链接、合并单元格)
额为信息的解析需要手动开启,既需要在解析数据里面加上一下信息
EasyExcel.read(base.getInputStream(), ExcelDemoDTO.class,listener)
// 需要读取批注 默认不读取
.extraRead(CellExtraTypeEnum.COMMENT)
// 需要读取超链接 默认不读取
.extraRead(CellExtraTypeEnum.HYPERLINK)
// 需要读取合并单元格信息 默认不读取
.extraRead(CellExtraTypeEnum.MERGE).sheet(0).doRead();
/**
* 解析到的额外信息
* @param extra extra information
* @param context analysis context
*/
@Override
public void extra(CellExtra extra, AnalysisContext context) {
switch (extra.getType()) {
case COMMENT:
log.info("额外信息是批注,在rowIndex:{},columnIndex;{},内容是:{}", extra.getRowIndex(), extra.getColumnIndex(),
extra.getText());
break;
case HYPERLINK:
if ("Sheet1!A1".equals(extra.getText())) {
log.info("额外信息是超链接,在rowIndex:{},columnIndex;{},内容是:{}", extra.getRowIndex(),
extra.getColumnIndex(), extra.getText());
} else if ("Sheet2!A1".equals(extra.getText())) {
log.info(
"额外信息是超链接,而且覆盖了一个区间,在firstRowIndex:{},firstColumnIndex;{},lastRowIndex:{},lastColumnIndex:{},"
+ "内容是:{}",
extra.getFirstRowIndex(), extra.getFirstColumnIndex(), extra.getLastRowIndex(),
extra.getLastColumnIndex(), extra.getText());
} else {
log.error("Unknown hyperlink!");
}
break;
case MERGE:
log.info(
"额外信息是合并单元格,而且覆盖了一个区间,在firstRowIndex:{},firstColumnIndex;{},lastRowIndex:{},lastColumnIndex:{}",
extra.getFirstRowIndex(), extra.getFirstColumnIndex(), extra.getLastRowIndex(),
extra.getLastColumnIndex());
break;
default:
}
}
3.1.3. excel解析完成会调用的方法 doAfterAllAnalysed
这个方法,我也处理了一下,实际上就是为了解析一下,被合并单元格的数据如果为空的需要排除出去,并且如果所解析的数据都为空的话,该字段会设置为null
/**
* 解析完成之后调用的方法
* @param analysisContext
*/
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
log.info("数据解析完成");
// 最后处理一下合并单元格的数据,把空的数据排除出去
if (CollectionUtils.isNotEmpty(list)){
// 循环解析出来的数据
for (T item : list) {
// 获取所有的字段信息
Field[] fields = item.getClass().getDeclaredFields();
for (Field field : fields) {
field.setAccessible(true);
// 判断数据是否有 合并单元格的注解
ExcelImportAOP excelImportAOP = field.getAnnotation(ExcelImportAOP.class);
if (Objects.nonNull(excelImportAOP)){
try {
List dataList = (List) field.get(item);
// 之后放入的合并单元格的数据不为空的时候才处理
if (CollectionUtils.isNotEmpty(dataList)){
// 获取合并单元格的迭代器,因为不符合的数据需要从list删掉
Iterator iterator = dataList.iterator();
while (iterator.hasNext()){
Object datum = iterator.next();
Field[] declaredFields = datum.getClass().getDeclaredFields();
// 是否删除的标识
boolean deleteFalge = true;
for (Field declaredField : declaredFields) {
declaredField.setAccessible(true);
// 获取泛型数据的值
Object declaredFieldValue = declaredField.get(datum);
// 只要一个不为空就不删除
if (Objects.nonNull(declaredFieldValue)){
deleteFalge = false;
}
}
if (deleteFalge){
iterator.remove();
// 判断是是否都已经删除玩了,如果都删完了,就设置为空
if (CollectionUtils.isEmpty(dataList)){
field.set(item,null);
}
}
}
}
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
}
}
}
}
}
3.2. 解析数据的监听类(完整代码)
package com.easyexcel231130.demos.listener;
import com.alibaba.excel.annotation.ExcelProperty;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.metadata.CellExtra;
import com.alibaba.excel.read.listener.ReadListener;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections4.CollectionUtils;
import java.lang.reflect.Field;
import java.lang.reflect.ParameterizedType;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Objects;
@Slf4j
public class DemoDataListener<T> implements ReadListener<T> {
List<T> list = new ArrayList<>();
/**
* 解析到每一行数据的时候调用的方法
* 这个地方如果,没有合并单元格的话,实际上就不会读取到了,所以就不会有那么多空行的数据
* @param t one row value. It is same as {@link AnalysisContext#readRowHolder()}
* @param analysisContext analysis context
*/
@Override
public void invoke(T t, AnalysisContext analysisContext) {
log.info("解析到一条数据:{}", JSONObject.toJSONString(t));
this.dataChange(t);
}
private void dataChange(T t) {
// 获取excel获取的行数据
Class<?> dataClass = t.getClass();
// 获取字段信息
Field[] declaredFields = dataClass.getDeclaredFields();
for (Field field : declaredFields) {
field.setAccessible(true);
//判断唯一标识,并且唯一标识的值不为空的时候,往放回结果中增加一条记录
this.onlyflagSetData(t, field);
//处理需要合并子项的数据
this.processingMegerData(t, declaredFields, field);
}
}
/**
* @Description 处理需要合并子项的数据
* @Date 11:47 2023/12/1
* @Param [t, declaredFields, field]
* @Return void
**/
private void processingMegerData(T t, Field[] declaredFields, Field field) {
// 判断字段上是否有注解
ExcelImportAOP excelImportAOP = field.getAnnotation(ExcelImportAOP.class);
if (Objects.nonNull(excelImportAOP)){
// 获取到list 的参数类型
ParameterizedType genericType = (ParameterizedType) field.getGenericType();
// 获取对应list泛型的class
Class<?> actualTypeArgument = (Class<?>)genericType.getActualTypeArguments()[0];
// 获取到泛型类型的所有字段信息
Field[] actualDeclaredFields = actualTypeArgument.getDeclaredFields();
try {
// 创建泛型类型的实体对象
Object o = actualTypeArgument.newInstance();
// 循环泛型的字段信息
for (Field declaredField : actualDeclaredFields) {
declaredField.setAccessible(true);
ExcelProperty excelProperty = declaredField.getAnnotation(ExcelProperty.class);
if (Objects.nonNull(excelProperty)){
String string = JSONObject.toJSONString(excelProperty.value());
// 循环原本的字段,如果设置的excel标题名称一致就赋值
for (Field declaredField1 : declaredFields) {
declaredField1.setAccessible(true);
ExcelProperty annotation = declaredField1.getAnnotation(ExcelProperty.class);
if (Objects.nonNull(annotation)){
String string1 = JSONObject.toJSONString(annotation.value());
// 如果写的名称一致,就设置值
if (string1.equals(string)){
declaredField.set(o, declaredField1.get(t));
}
}
}
}
}
// 获取字段中最后一个值
T tdata = list.get(list.size() - 1);
Object mergeObject = field.get(tdata);
List mergeList = Objects.nonNull(mergeObject) ? (List) mergeObject : new ArrayList<>();
mergeList.add(o);
// 设置合并字段的值
field.set(t,mergeList);
} catch (InstantiationException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
}
}
/**
* @Description 判断唯一标识,并且唯一标识的值不为空的时候,往放回结果中增加一条记录
* @Date 11:45 2023/12/1
* @Param [t, field]
* @Return void
**/
private void onlyflagSetData(T t, Field field) {
// 判断是否有唯一标识的注解
GoodsExcelImportAOP onlyflag = field.getAnnotation(GoodsExcelImportAOP.class);
if (Objects.nonNull(onlyflag)){
try {
Object fieldvalue = field.get(t);
// 判断唯一标识的值不为空的时候才能添加返回数据
if (Objects.nonNull(fieldvalue)) {
list.add(t);
}
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
}
}
public List<T> getList(){
return list;
}
/**
* 解析到的额外信息
* @param extra extra information
* @param context analysis context
*/
@Override
public void extra(CellExtra extra, AnalysisContext context) {
// log.info("读取到了一条额外信息:{}", JSON.toJSONString(extra));
switch (extra.getType()) {
case COMMENT:
log.info("额外信息是批注,在rowIndex:{},columnIndex;{},内容是:{}", extra.getRowIndex(), extra.getColumnIndex(),
extra.getText());
break;
case HYPERLINK:
if ("Sheet1!A1".equals(extra.getText())) {
log.info("额外信息是超链接,在rowIndex:{},columnIndex;{},内容是:{}", extra.getRowIndex(),
extra.getColumnIndex(), extra.getText());
} else if ("Sheet2!A1".equals(extra.getText())) {
log.info(
"额外信息是超链接,而且覆盖了一个区间,在firstRowIndex:{},firstColumnIndex;{},lastRowIndex:{},lastColumnIndex:{},"
+ "内容是:{}",
extra.getFirstRowIndex(), extra.getFirstColumnIndex(), extra.getLastRowIndex(),
extra.getLastColumnIndex(), extra.getText());
} else {
log.error("Unknown hyperlink!");
}
break;
case MERGE:
log.info(
"额外信息是合并单元格,而且覆盖了一个区间,在firstRowIndex:{},firstColumnIndex;{},lastRowIndex:{},lastColumnIndex:{}",
extra.getFirstRowIndex(), extra.getFirstColumnIndex(), extra.getLastRowIndex(),
extra.getLastColumnIndex());
break;
default:
}
}
/**
* 解析完成之后调用的方法
* @param analysisContext
*/
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
log.info("数据解析完成");
// 最后处理一下合并单元格的数据,把空的数据排除出去
if (CollectionUtils.isNotEmpty(list)){
// 循环解析出来的数据
for (T item : list) {
// 获取所有的字段信息
Field[] fields = item.getClass().getDeclaredFields();
for (Field field : fields) {
field.setAccessible(true);
// 判断数据是否有 合并单元格的注解
ExcelImportAOP excelImportAOP = field.getAnnotation(ExcelImportAOP.class);
if (Objects.nonNull(excelImportAOP)){
try {
List dataList = (List) field.get(item);
// 之后放入的合并单元格的数据不为空的时候才处理
if (CollectionUtils.isNotEmpty(dataList)){
// 获取合并单元格的迭代器,因为不符合的数据需要从list删掉
Iterator iterator = dataList.iterator();
while (iterator.hasNext()){
Object datum = iterator.next();
Field[] declaredFields = datum.getClass().getDeclaredFields();
// 是否删除的标识
boolean deleteFalge = true;
for (Field declaredField : declaredFields) {
declaredField.setAccessible(true);
// 获取泛型数据的值
Object declaredFieldValue = declaredField.get(datum);
// 只要一个不为空就不删除
if (Objects.nonNull(declaredFieldValue)){
deleteFalge = false;
}
}
if (deleteFalge){
iterator.remove();
// 判断是是否都已经删除玩了,如果都删完了,就设置为空
if (CollectionUtils.isEmpty(dataList)){
field.set(item,null);
}
}
}
}
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
}
}
}
}
}
}















 2470
2470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









