







实验室新手进阶之路
- 在linux服务器上安装Anaconda
- 在linux服务器上安装pytorch
- 在linux服务器上使用conda
- 在linux服务器上使用git clone
- 配置vscode免密登录
- 客户端
- 服务端
- 常用linux命令
- 检查反向传播是否正确
- 在linux服务器上使用Tensorboard可视化
- linux下载文件
- Windows使用git clone遇到的各种问题
- 分布式训练 多卡并行
- PyCharm连接远程服务器
- git学习
- pip install -e .
- tmux
- 内网穿透
- deepspeed配置使用vscode进行远程debug
- deepspeed配置使用PyCharm进行远程debug
- vscode debug选项
- vscodes使用小技巧
- PyCharm项目的import使用
- wandb huggingface
- 配置vscode或者Pycharm ssh版本显示图片
- PyCharm git操作
- register_buffer
- zotero配置
- CUDA相关知识
- json文件的读写
- csv文件的读写
- png文件的读写
- jupyter使用小技巧
- 杀死僵尸进程
- 记录神奇的conda报错
- 安装python第三方库遇到的bug
- linux下载kaggle数据集
- line_profiler 分析cpu瓶颈
- Github issue实用例句
- 分割任务
在linux服务器上安装Anaconda
参考博客:
如何在Linux服务器上安装Anaconda(超详细)
简单记录几点博客里没写但我遇到的:
- 忘记输入yes默认配置环境变量。所以需要在
.bashrc文件中加添加环境变量的命令,再执行一次.bashrc文件。最大的困难是我不会写对应的linux命令。
cd 进入/home/xxx
vim .bashrc # 打开.bashrc文件
i # 进入编辑模式
在最后一行添加 export PATH=/home/xxx/anaconda3/bin:$PATH # 具体路径看自己
按esc退出编辑模式
:wq # 保存并关闭文件
source .bashrc # 激活环境
anaconda -V # 测试是否成功,V要大写
conda -V # V要大写
在linux服务器上安装pytorch
使用的服务器是RTX3090+CUDA11.4,网上通用的一些方法试过了没啥用,包括清华镜像、阿里云镜像啥的,也不能安装CUDA10.2后续跑不了代码,最后终于找到了一篇博客教程,顺利安装:
3090显卡(CUDA11.1)安装Pytorch
不需要挂梯子,运行下面的命令即可:
pip install torch===1.7.1+cu110 torchvision===0.8.2+cu110 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
在linux服务器上使用conda
windows和linux使用conda的命令也小有差异,以下纪录conda的。
虚拟环境相关命令
# 创建虚拟环境
conda create -n your_env_name python=3.7
# 复制已有环境
conda create -n 新环境名 --clone 旧环境名
# 激活虚拟环境
source activate your_env_name
# 关闭虚拟环境
source deactivate your_env_name
# 删除虚拟环境
conda remove -n your_env_name --all
# 删除虚拟环境中的包
conda remove --name $your_env_name $package_name
# 导出虚拟环境里的所有包版本, 有助于重新装环境
pip freeze > requirements.txt
跨服务器复制anaconda环境
跨服务器复制anaconda的环境(直接复制无需重复安装包)
包的管理
conda install package_name
# 镜像源
pip install package_name -i https://pypi.tuna.tsinghua.edu.cn/simple/
conda uninstall package_name
conda remove package_name
# conda安装信息
conda info
# 查看conda帮助
conda help
# 列出环境
conda env list
conda换源 vs pip换源
pip换源
- 临时换源
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
# 常用国内镜像源
https://pypi.tuna.tsinghua.edu.cn/simple
https://mirrors.aliyun.com/pypi/simple/
https://pypi.mirrors.ustc.edu.cn/simple/
https://pypi.douban.com/simple/
- 全局换源
- 编辑配置文件:
mkdir -p ~/.pip
nano ~/.pip/pip.conf
- 添加以下内容:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host = pypi.tuna.tsinghua.edu.cn
- 保存并退出:保存ctrl+s,退出ctrl+z。
conda换源
- 临时换源:
conda install numpy -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- 全局换源:
直接编辑配置文件.condarc也可以,详见博客:
conda 解决An HTTP error occurred when trying to retrieve this URL.(已经更新清华源但也无解的解决方法)
安装pytorch2.0.0,用conda开头的官方命令死活报错,改成pip开头的命令成功了:
pip install torch==2.0.0 torchvision==0.15.1 torchaudio==2.0.1
# 设置搜索时显示通道地址
conda config --set show_channel_urls yes
# 添加清华源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
# 返回默认配置
conda config --remove-key channels
# CUDA 12.1
# 适合RTX 3060
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu121
# 别开外网
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
在linux服务器上使用git clone
真的有用!
在ubuntu上使用git克隆github上的项目
直接在A6000上使用普通的git clone命令居然可以顺利下载git项目!
遇到的坑:
坑:ssh: connect to host github.com port 22: Connection refused
配置vscode免密登录
配置vscode 远程开发+ 免密登录
上述博客的评论区比较有效:
# 1. cat 本地的id_rsa.pub
cat C:\Users\26308\.ssh\id_rsa.pub
# 2. 将本地的公钥内容复制到服务器的 authorized_keys
vim ~/.ssh/authorized_keys
# 3. 修改vscode:远程资源管理器-->设置-->打开.ssh/config文件,加入 IdentityFile 和对应的本机私钥路径
IdentityFile C:\Users\26308\.ssh\id_rsa
客户端
cat ~/.ssh/id_rsa.pub
服务端
vim ~/.ssh/authorized_keys
常用linux命令
基础命令
# 列出当前目录下的文件和文件夹
ls(list)
# 列出文件和文件夹的详细信息
ls -l
# 新建路径a
mkdir a(make directory)
# 创建文件
touch 文件名
# 进入a路径
cd a
# 上一级目录
../
# 当前目录
./
# 查看当前路径
pwd
# 将test目录重命名为dir
mv test/ dir
# 将a移动到b目录下,如果b目录不存在,即把a重命名为b
mv a b/
# 看文件树
tree
# 将a文件夹拷贝到b文件夹下
# -r代表递归
# -n代表跳过相同文件, 适合中断后继续复制
cp -r -n a b
#删除a文件夹 rm(remove) -r代表递归 -f代表强制
rm -rf a
# 删除a文件夹下的所有文件
rm -rf a/*
# 设置环境变量:全局有效
export PATH=/home/xxx/anaconda/bin:$PATH # 将export命令写入文件:~/.bashrc
source ~/.bashrc
env | grep PATH # 查看是否设置成功
# 编辑文本文件
vim
# 查看GPU信息
nvidia-smi
# 查看每张GPU的可用显存
nvidia-smi --query-gpu=memory.free --format=csv
# 每隔一秒查看每张GPU的显存
watch -n 1 nvidia-smi --query-gpu=memory.used --format=csv
# 查看进程
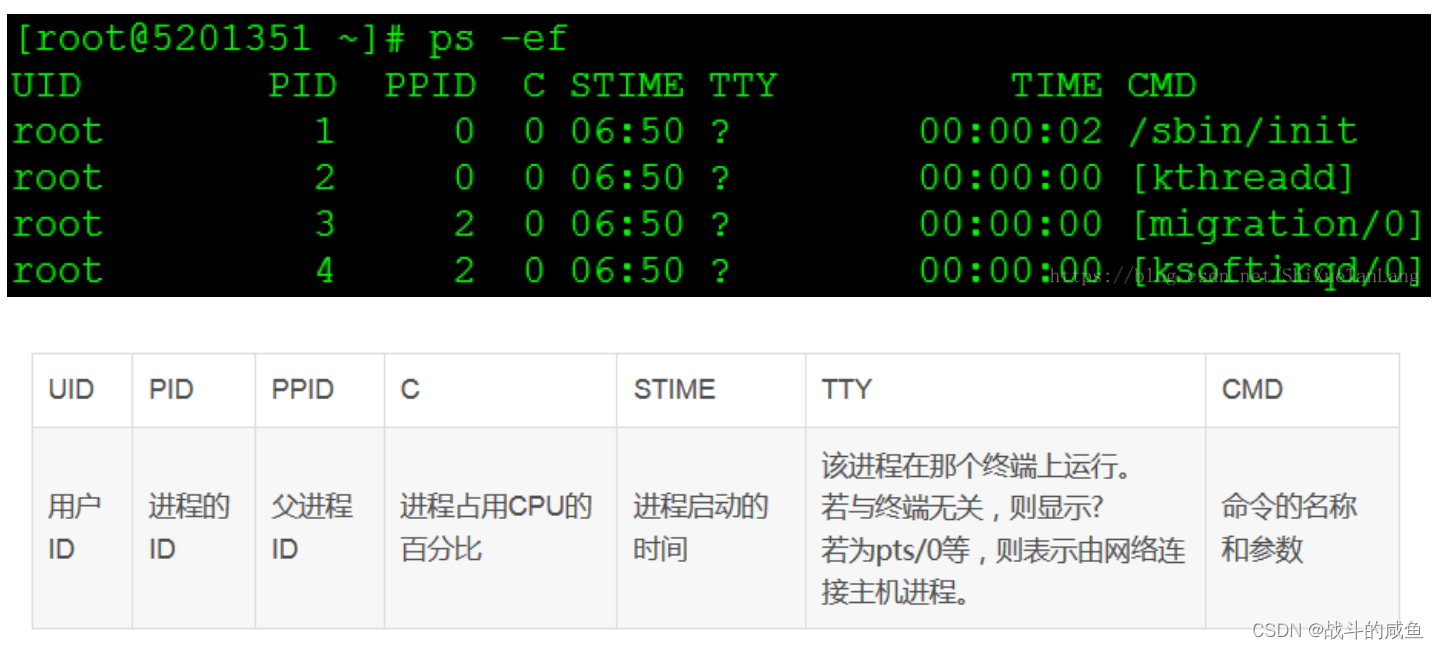
ps -ef
# 查看进程的CPU和内存占用
# %CPU RES
top
# 重定向日志
# 一般情况日志会输出到stdout/stderr中
# 重定向到train.log文件中,2代表stderr,1代表stdout
python train.py > ./train.log 2>&1
# &: 后台运行
python train.py > ./train.log 2>&1 &
# 将日志文件的内容打印在stdout
# cat: concatenate files to standard output
cat ./train.log
# 比较2个文档的差别
vimdiff single_gpu.py mp_train.py
压缩与解压命令
# 解压zip文件
unzip a.zip -d 新名称
# 将a文件夹压缩为a.tar.gz的压缩包
tar czf a.tar.gz a/
# 将a.tar.gz压缩包解压
tar xzf a.tar.gz
# .tar 只打包,不压缩文件
# .gz 只压缩,不打包文件
# .tar.gz 打包压缩文件
跨服务器复制目录和文件
# 在服务器之间复制文件和目录
# 从本地复制到远程
scp -P 远程端口号 -r 本地文件夹路径 远程用户名@远程IP:远程文件夹路径 # 复制目录
# -r: 递归复制整个目录
scp -P 远程端口号 file.txt root@IP:/path # 复制文件
# 从远程复制到本地: 将上面命令的后2个参数调换
scp -P 远程端口号 -r 远程用户名@远程IP:远程文件夹路径 本地文件夹路径
scp [可选参数] 源文件 目标文件
linux文件系统
- linux查看磁盘空间
# linux查看每个用户使用的存储空间
sudo du -sh /home/*
# -s: 不包含子目录的大小
# -h: 提高可读性, 以K M G为单位
# 查看当前目录总共占的容量,而不单独列出各子项占用的容量
# -h: 以K,M,G为单位,提高信息的可读性
# -s: 仅显示总计
du -sh
# 单独列出各子项占用的容量
du -sh ./*
# 列出子项占用的容量, 深度为1
du -hl --max-depth=1 .
# 查看系统空间的使用情况
df -hl
# 查看磁盘剩余空间
df -hl 目录名
- 统计当前文件夹下的文件数目
# 统计当前文件夹下的文件数目
# 统计当前文件夹下 以.jpg结尾的文件数目
find -name "*.jpg" | wc -l # wc -l: 统计行数
# 列出当前文件夹下的所有文件->查找以-开头的所有文件名->统计行数
ls -l | grep "^-" | wc -l # grep: 文本搜索工具
# -type f: 只查找文件file
find ./ -type f -name "*.tif" | wc -l
在 linux 终端下载文件
# 文件或网页的url
wget URL
# 下载多个文件:将url保存至一个文本文件中
wget -i download_files.txt
# 为下载的文件重命名
wget -O filename URL
# 恢复未完成的下载
wget -c
# 下载百度网盘链接
# 文件下载链接:在浏览器下载管理中可以复制
wget -c --referer=网盘分享链接 -O 文件名 "文件下载链接"
Linux命令不受终端断开的影响,保持在后台运行
nohup python train.py > train.log 2>&1 &
# nohup可以让命令忽略挂起信号
# 第一个 > 表示将命令的标准输出重定向到 train.log
# 2>&1表示将标准错误重定向到标准输出,此处也是train.log
# 最后一个&表示让命令在后台运行
CUDA_VISIBLE_DEVICES=1 nohup python train.py > nohup.log 2>&1 &
# 指定显卡编号 写在nohup前面
ps -ef|grep train # 返回nohup启动的所有相关进程(能识别你的进程名称的关键词)
ps -ef|head -1;ps -ef|grep train # 获取标题头
kill -9 pid # pid为每一行的第二个id编码,表示的是该进程的父进程
kill -TERM pid # 杀死多进程程序命令
# linux批量杀死多个进程
ps -ef|grep "关键字"|grep -v "关键字"|cut -c 9-15|xargs kill -9
ps -ef | grep train的显示结果:
linux执行.sh(shell)脚本
# 进入shell脚本所在文件夹
# 给shell文件授权
chmod +x shell.sh
# 执行.sh文件
./shell.sh
sh shell.sh
bash shell.sh
linux+git git版本控制+PyCharm
# 安装包 可以在全局使用
pip install git+Github地址
# 把库安装在项目下
git clone git@github.com:facebookresearch/segment-anything.git
cd segment-anything; pip install -e .
# 复制存储库
git clone Github地址
git clone git@github.com:CSMMLab/KiT-RT.git # 类似这种格式
# 查看所有的历史版本信息, reference log参考日志
# 一般用来恢复本地错误操作
git reflog # 显示commit id
# 查看当前分支
git branch
# 切换分支
git checkout 分支名
# 创建新分支
git checkout -b 新分支名
# 修改分支名
git branch -m oldName newName
# 删除本地分支(删除之前要checkout到其他分支
git branch -D 本地分支名 # 强制删除本地分支
git branch -d 本地分支名 # 分支不包含未合并的更改和未推送的提交,才可以成功删除
# 查看git日志: 可以查看commit的SHA
git log
# detached HEAD状态: HEAD指向一个commit, 而不是一个branch
# 撤销commit, 但保留add, 不删除工作空间的改动代码(适用于没有push到远程)
# HEAD^: 上一个版本的commit; HEAD^^回滚两个版本的commit
git reset --soft HEAD^
# 撤销commit和add, 删除工作空间的改动代码(适用于没有push到远程)
git reset --hard HEAD^
# 合并分支: 将tmp分支合并到当前所在分支
git merge tmp
# 如果发生冲突, 可以在PyCharm中解决冲突, 再手动commit一个新的版本
# 取消合并分支
git merge --abort
修改本地commit的提交信息:
## 修改最近一次commit的注释(提交信息)
git commit --amend
## 修改历史commit的注释(提交信息)
# step1: 切换到想要修改commit注释的分支
git checkout clip+lm-loss
# step2: 指定想要修改的commit
git rebase -i HEAD~2 # 打开一个文本编辑器, 显示最近2次commit的列表
# step3: 将想要修改的commit提交信息前面的pick修改为reword, 保存并退出编辑器
# step4: 自动打开另一个文本编辑器, 修改提交信息保存并退出
取消文件的版本控制:
# 取消文件的版本控制
# 未git add
在.gitignore中添加
# 已git add
# --cached: 只去除版本控制而不删除本地文件
# -n: 展示要去除版本控制的文件列表
step1: git rm -r --cached 文件夹名 # 移除某文件夹的版本控制
# 展示待删除的文件预览: git rm -r -n --cached 文件夹名
step2: git commit -m "移除版本控制" # 提交到本地
step3: git push origin main:3090 # 提交到远程服务器, 本地的main分支提交到origin的3090分支, 3090分支是新创建的
step4: 在.gitignore中添加
git push报错timed out:
参考博文:ssh: connect to host github.com port 22: Connection timed out fatal
ssh -T -p 443 git@ssh.github.com # 然后输入yes
vim ~/.ssh/config
# 更改ssh端口, 编辑文件内容
Host github.com
HostName ssh.github.com
Port 443
git fetch简单用法:把远程的代码更新拉取到本地仓库,但不会对本地项目的main分支造成影响,安全拉取。
# step1: cd到项目根目录下,查看远程分支的信息
git remote -v
# step2: 将origin的main分支拉取到本地,并在本地新建一个temp分支
git fetch origin main:temp
# step3: 比较本地temp分支和main分支的差异
# 如果没有任何显示,表示没有区别
git diff temp > diff.log
# step4: 将temp分支合并到main分支(当前所在分支)
git merge temp
# 如果merge失败:
git stash
git stash pop
# step5: 合并后可以删除temp分支
git branch -d temp
监控服务器状态
# nvitop库: NVIDIA-GPU设备运行状况的实时监控工具
pip install nvitop
nvitop
# disk free: 检查文件系统的磁盘占用情况
df -hl # -h: 方便阅读 -l: 本地文件系统
# disk usage: 该目录下所有文件夹所占空间的大小
du -hl --max-depth=1
软链接
软链接与原文件的关系:
原文件是软链接指向的实际文件或目录,软链接是原文件的镜像或快捷方式。
软链接本身是一个独立的文件,软链接的内容是它所指向的原文件的路径。
当访问软链接时,系统会自动将其解析为原文件,并访问原文件。
# 创建目标文件目录, 是源文件目录的软链接
# 原、目标文件的目录都不要在后面加 / !!
ln -s 源文件目录 目标文件目录
# 删除软链接
unlink 目录
# 修改软链接: 让目标文件目录指向新的源文件目录
ln -snf 新的源文件目录 目标文件目录
检查反向传播是否正确
参考博客:
Pytorch 分析反向梯度检查网络
pytorch学习(2):通过检查梯度参数,判断是否正常反向传播
在loss.backward()后打印网络的回传梯度:
for n,p in net.named_parameters():
print(n, '->', p.is_leaf, '->', p.grad, '->', p.requires_grad)
训练过程打印中间变量的grad会显示None,因为当中间变量完成了反向传播的使命就会被释放掉。因此需要hook函数来打印中间变量的梯度。
# y是一个中间变量
# 函数定义:hook(grad) -> Tensor or None
y.register_hook(lambda grad: print(y, '->', grad))
# 打印网络的backward梯度
# 函数定义:hook(module, grad_input, grad_output) -> tuple(Tensor) or None
torch.nn.Module.register_backward_hook (lambda module, grad_input, grad_output: print(module, '->', grad_input, '->', grad_output))
在linux服务器上使用Tensorboard可视化
参考博客:
很感动,按照步骤来一个问题都没出,狠狠三连了!
【最全最细】Linux系统服务器使用Tensorboard实现可视化操作
我设置的侦听端口也是16666,目标端口也是6006。
首先代码中要使用pytorch的Tensorboard。
然后在xshell终端输入:
source activate [环境全称]
tensorboard --logdir=【你模型保存的绝对路径/相对路径】 --port 6006
localhost:16666 # 在浏览器中输入网址
linux下载文件
修改huggingface的默认下载位置
参考博客:Huggingface 默认下载位置更改
# 初始默认位置:~/.cache/huggingface/
vim ~/.bashrc
export HF_HOME="xxx/.cache/huggingface" # 保存并退出
source ~/.bashrc
env | grep HF_HOME # 查看环境变量
linux从huggingface下载文件
1. huggingface-cli+hf_transfer
多文件并行,不支持单文件多线程
pip install -U huggingface_hub
# 每个ssh连接都要export一下
export HF_ENDPOINT="https://hf-mirror.com"
huggingface-cli download --resume-download 存储库名称 --local-dir 本地位置 --local-dir-use-symlinks False
# local-dir-use-symlinks: 真实模型是否存储在~/.cache/huggingface下
# 下载数据集, 增加参数--repo-type
huggingface-cli download --resume-download --repo-type dataset 存储库名称
使用hf_transfer加速
没有进度条【v0.19.0+开始支持进度条了】
启动失败!
pip install -U hf-transfer
export HF_HUB_ENABLE_HF_TRANSFER=1
huggingface-cli download --resume-download 存储库名称 --local-dir 本地位置 --local-dir-use-symlinks False
# 没有进度条说明开启加速成功
2. snapshot_download
需要配置代理,所以不打算使用。
linux从Google Drive下载文件
获取可下载的直接链接 并在Linux命令行下载Google Drive或Onedrive大文件到服务器
用命令行下载Google Drive文件的方法
对于一般的大文件,主要用gdown命令:
A6000的 base 环境里有gdown包。
gdown -c https://drive.google.com/uc?id=ID
# 把ID替换为Google Drive的FileID即可
# -c表示中断后继续
对于更大的文件,参考这篇博客里提到的access token技术:
gdown/命令行下载Google Drive文件(大文件也可以)
下载一个Google Drive的文件时,建议先用第一种方法试试。如果文件不够大,使用第二种方法也有可能失效。目前尝试了一个12G的文件,只能使用第一种gdown方法下载。
Windows使用git clone遇到的各种问题
问题1
问题描述:
fatal: unable to access 'xxx':
Failed to connect to 127.0.0.1 port 7890 after 2081 ms:
Couldn't connect to server
解决方法:
解决git clone报错Failed to connect to 127.0.0.1 port 7890 after 2059 ms: Connection refused
问题2
问题描述:
fatal: unable to access 'xxxx':
Failed to connect to github.com port 443 after 21256 ms:
Couldn't connect to server
解决方法:
分布式训练 多卡并行
霹雳啪啦我的神仙导师!
实操教程 | GPU多卡并行训练总结(以pytorch为例)
对应github代码地址
分布式训练并不能将同1个模型分开放在不同的卡上,所以我用autodl租了A40来跑。贵死!
DistributedDataParallel(DDP)
参考的博客:
深度学习训练方法实操(DP/DDP/DeepSpeed)
单机多卡
使用DDP进行单机多卡训练步骤如下:
- 初始化:
# 初始化通信
n_gpus = 2
torch.distributed.init_process_group("nccl", world_size=n_gpus)
# 获取当前进程的rank(每个进程在不同的GPU/rank上)
local_rank = torch.distributed.get_rank()
# 获取当前进程使用的GPU设备
device = torch.device("cuda", local_rank)
# 设置当前进程使用的GPU设备, local_rank表示GPU设备的序号
torch.cuda.set_device(local_rank)
- 包装模型:
model = torch.nn.parallel.DistributedDataParallel(model.to(device), device_ids=[local_rank])
- 数据加载:
# 设置分布式采样, 设置分布式采样后, shuffle=False即可
# batch_size是每个GPU上的batch_size
trainsampler = torch.utils.data.distributed.DistributedSampler(trainset, rank=local_rank)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=False, sampler=trainsampler)
- 数据打乱:
for epoch in range(epochs):
# 设置采样器的当前训练epoch, 以便采样器可以根据不同的训练周期执行不同的采样策略
trainsampler.set_epoch(epoch)
for input, label in trainloader:
input, label = input.to(device), label.to(device)
...
loss.backward()
optimizer.step()
- 模型保存:使用
model.module.state_dict()来保存。
# 只在local_rank=0时保存模型
if step%save_step_interval == 0 and local_rank == 0:
os.makedirs(save_path, exist_ok=True)
save_file = os.path.join(save_path, f"save_{step}.pth")
torch.save({'epoch': epoch,
'model_state_dict': model.module.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss}, save_file)
- 结束处理:
# 结束分布式进程
torch.distributed.destroy_process_group()
- 执行方式:
# torch.distributed.launch启动多个进程
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 train.py
多机多卡
使用DDP进行多机多卡训练步骤如下:
- 直接使用DDP单机多卡的代码。确保多机之间可以互相访问。
- 在每台机器上运行下列脚本:
# 在第一个机器节点上执行
# nproc_per_node: 每台机器上要使用的GPU数量
# nnodes: 节点/机器数量
# node_rank: 当前节点/机器的rank
# master_addr和master_port:指定主节点的IP和端口号
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=2 --node_rank=0 --master_addr=10.38.234.187 --master_port=29500 train.py
# 在第二个机器节点上执行
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=2 --node_rank=1 --master_addr=10.38.234.187 --master_port=29500 train.py
DeepSpeed
DeepSpeed执行多机多卡的训练步骤如下:
- 初始化:
args = get_args()
# 初始化分布式训练环境
deepspeed.init_distributed(dist_backend=args.backend, dist_init_required=True)
args.local_rank = torch.distributed.get_rank()
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
- 数据加载:
- 包装模型:
- 训练处理:
- 模型保存:
- 执行方式:
PyCharm连接远程服务器
按照这个博客的教程来,以前弄的好像有错误:
Pycharm远程连接服务器并运行代码(详细!)
超详细pycharm(专业版)+远程调试+本地和服务器代码同步
注意:
如果项目文件夹下有ckpt/ output/ dataset 文件夹,则需要加入排除的路径。
git学习
相关教程:
Git入门图文教程(1.5W字40图)–深入浅出、图文并茂
Git使用教程(看完会了也懂了)
Linux上传GitHub【超详细】
github合并分支~
Linux上传github
- 新建一个github仓库(最好没有readme.md)。
- 把本地项目变成 git 仓库,并将文件添加到仓库里。
git init -b main # 指定分支名为main
git add .
git status # 查看缓存区内容
git ls-files # 查看放在本地仓库的内容
git commit -m "描述内容"
# 修改origin的关联
git remote set-url origin 仓库.git
git remote add origin 仓库.git # 关联远程仓库
git remote # 查看目前已经关联的远程仓库
git pull origin main --allow-unrelated-histories # 把远程仓库pull到本地, 适合远程仓库有readme.md时
git push origin main # 把本地内容push到远程仓库
虚拟环境导出
activate your_environment
conda env export > environment.yaml
conda env create -f environment.yaml
pip freeze > requirements.txt
pip install -r requirements.txt
pip install -e .
正常情况下,我们使用 pip install package 来安装一个包,该包将被复制到 Python 的 site-packages 目录下。这样做的结果是,无论我们修改了该包的代码与否,我们使用的永远都是 site-packages 目录下的安装版本。
pip install -e 允许我们创建一个软链接,链接到我们开发目录下的包文件夹,而不是复制到 site-packages 目录中。
pip install -e .的.表示当前目录。我们在开发过程中只需修改代码,并在测试过程中立即看到结果,而无需每次都重新安装包。
-e : editable
tmux
terminal multiplexer终端复用器
Tmux 使用教程
会话和窗口命令
# 启动tmux窗口
tmux
# 退出tmux窗口
exit
ctrl+d
# 前缀键: 快捷键需要前缀键唤起
ctrl+b
# 新建会话: 取名
tmux new -s 会话名
# 当前会话和窗口分离
tmux detach
# 查看当前所有tmux会话
tmux ls
# 重新接入已存在的会话
tmux attach -t 会话编号/会话名
# 杀死会话
tmux kill-session -t 会话编号/会话名
# 切换会话
tmux switch -t 会话编号/会话名
# 重命名会话
tmux rename-session -t 0 新会话名
多个窗格和窗口
# 划分窗格
tmux split-window # 上下
tmux split-window -h # 左右
# 移动光标
tmux select-pane -U
tmux select-pane -D
tmux select-pane -L
tmux select-pane -R
# 交换窗格位置
tmux swap-pane -U
tmux swap-pane -D
# 新建窗口
tmux new-window -n 窗口名
# 切换窗口
tmux select-window -t 窗口编号/窗口名
# 重命名窗口
tmux rename-window 窗口名
# 设置鼠标滚动支持
tmux set mouse on
tmux相关bug
【Tmux】窗口周围出现大量点点导致窗口面积减小
简单总结一下解决方法:
- 在tmux窗口内执行:
ctrl + b,shift + d(也就是大写D)。 - 选择分辨率最小的一项,enter后执行
ctrl+b+d退出窗口,然后重新进入窗口。
内网穿透
待学习:
frp配置内网穿透教程(超详细)
deepspeed配置使用vscode进行远程debug
写得很好的博客:
deepspeed使用vscode进行远程调试debug环境配置与解读
deepspeed配置使用PyCharm进行远程debug
写得很好的博客(好像是全网唯一一个)
如何在pycharm中调试deepspeed
vscode debug选项
继续 F5:继续执行,直到下一个断点处
单步跳过F10:光标运行到有函数的地方时,点击运行即完成该函数
单步调试F11:运行一行代码
单步跳出Shift+F11:跳出到即将进入函数的指令,此时函数未执行
重启:重新启动调试,直到第一个断点停下
vscodes使用小技巧
快捷键ctrl+:放大界面字体
PyCharm项目的import使用
import语句的写法标准:
- import语句写在文件的顶部,在注释或说明文字后。
- 根据导入内容的不同分成 3 类。第一类:导入 python 内置模块;第二类,导入第三方库模块;第三类,导入当前项目的模块。
- 导入不同类别的模块时,要用空行分开。
绝对导入
绝对导入的参照物是项目的根文件夹,必须从最顶层的文件夹开始,为每个包提供完整的导入路径。
project项目的目录结构如下:
project
├─package1
│ module1.py
│ module2.py
│
└─package2
│ module3.py
│ module4.py
│ __init__.py
│
└─subpackage
module5.py
则使用绝对路径导入的示例如下:
from package1.import module1
from package1.module2 import func1
from package2 import class1
from package2.subpackage.module5 import func2
相对导入
相对导入的参照物是当前位置,
如果在package2.module3.py中引用module4.py,写法如下:
import module4
from . import module4 # 推荐使用这个
from package2 import module4
如果在package1.module1.py中引用package1.module2.func1,写法如下:
from .module2 import func1
如果在package2.module3.py中引用package2.class1和package2.subpackage.module5.func2,写法如下:
from . import class1
from .subpackage.module5 import func2
wandb huggingface
参考文档:
Hugging Face Transformers
os.environ["WANDB_API_KEY"] = "xx"
os.environ["WANDB_MODE"] = "offline"
os.environ["WANDB_PROJECT"] = "<my-amazing-project>"
配置vscode或者Pycharm ssh版本显示图片
# 在MobaXterm中找到IP
# 输出:localhost:15.0
echo $DISPLAY
# 在命令行里设置DISPLAY的环境变量
export DISPLAY="localhost:15.0"
# 接下来就可以愉快地显示图片啦
PyCharm git操作
PyCharm git commit
commit文件中的部分更改:
双击commit窗口中的文件名,可以选择想提交的代码块。
register_buffer
zotero配置
zotero配置同步:坚果云+zotfile
zotero同步pdf文件:
Zotero | 两台设备的pdf文件同步问题
zotero style用法
zoterot同步的bug
iPad 上无法打开链接文件,报错信息如下:
Error:Linked files are not supported on iOs.You can open them using the Zotero desktop app.
解决方案:
工具——>管理附件——>转换已链接文件为以存储文件。
CUDA相关知识
看起来似乎写得很全面的一篇博客:
显卡,显卡驱动,nvcc, cuda driver,cudatoolkit,cudnn区别?
GPU型号含义
- 显卡:即GPU,尤其是NVIDIA公司生产的GPU系列,硬件。cuda、cudann都是NVIDIA公司针对自家GPU设计的。
- 显卡驱动:一般指NVIDIA Driver,是一个驱动软件。
- GPU架构:硬件的设计方式,每一代架构是一种思想,如何去更好完成并行的思想。如:Tesla、Fermi、Kepler、Maxwell、Pascal等。
- 芯片型号:芯片是对GPU架构思想的实现,芯片型号第2个字母代表哪一代架构。比如GT200和GT100的芯片,基本设计思路和这一代架构保持一致,只是细节上做了区分。
- 显卡系列:GeForce用于家庭娱乐、Quadro用于工作站、Tesla用于服务器。Tesla系列没有显示输出接口,专注于数据计算而不是图形显示。
- GeForce显卡型号:不同的硬件定制,越往后性能越好,G/GS、GT、GTS、GTX。
CUDA名称含义
- CUDA:全名为Compute Unified Device Architecture(计算统一设备体系结构),CUDA是NVIDIA公司推出的通用并行计算架构,使GPU可以解决复杂的计算问题。
- cudnn:专门为深度学习计算设计的软件库,提供了很多专门的计算函数,如卷积。其他类似的软件库和中间件有:实现C++ STL的thrust、实现GPU版本blas的CUBLAS、实现快速傅里叶变换的cuFFT、实现稀疏矩阵运算操作的cuSparse、实现深度学习网络加速的cuDNN等。
- CUDA Toolkit:NVIDIA公司提供的完整软件开发套件,提供基础的CUDA编程接口和工具,支持多种编程语言。CUDA Toolkit包括CUDA驱动程序、CUDA运行时库、编译器(nvcc)、数学库、调试和分析工具、样例和文档。CUDA Toolkit和CUDA Driver的版本应该对应起来。
nvcc & nvidia-smi
- nvcc:CUDA的编译器,类似于gcc是C语言的编译器。CUDA程序有2种代码,在CPU上运行的host代码和在GPU上运行的device代码,所以nvcc编译器要保证两部分代码能编译成二进制文件在不同的机器上执行。
- nvidia-smi:全名为NVIDIA System Management Interface,NVIDIA系统管理接口。
nvcc和nvidia-smi显示的CUDA版本不同?
CUDA有两种API,Runtime API和Driver API,两种API都有对应的CUDA版本。
nvidia-smi属于Driver API,支持Driver API的必要文件是由GPU driver installer安装的。
支持runtime API的必要文件是由CUDA Toolkit Installer安装的,nvcc是与CUDA Toolkit一起安装的CUDA compiler-driver tool,它只知道它自身构建时的CUDA Runtime API版本,它不知道安装了什么版本的GPU Driver API。
因此,如果nvcc和nvidia-smi显示的cuda版本不一致,可能是因为安装CUDA时使用了单独的GPU Driver Installer,而不是CUDA Toolkit Installer。
解决方案,主要是热评帮助很大:
nvcc-V显示信息与安装的CUDA版本不一致问题解决方案
有用的命令:
重点是新加入的路径要写在最前面!!
LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda/bin:$PATH
export CUDA_HOME=/usr/local/cuda:$CUDA_HOME
Runtime API与Driver API的区别
两者在大部分情况下是等价的,但是不能混用这两种API,因为它们是互斥的。在开发过程中,只能选择其中一种API。
二者的区别简单说来就是:Runtime API是更高级的封装,开发人员用起来更方便,而Driver API更接近底层,速度可能更快。
Linux中的PATH、LIBRARY_PATH、LD_LIBRARY_PATH的区别
- PATH:可执行文件路径。命令行中每句能运行的命令,如ls、top等,都是系统通过PATH找到该命令执行文件的位置,再run该可执行文件。比如
~/mycode/bin/文件夹下存放了可执行的二进制文件和shell脚本,若想在任意目录下都能运行上述bin文件夹下的可执行文件,那么把该路径添加到PATH即可。
# 修改环境变量
vim ~/.bashrc
PATH=$PATH:~/mycode/bin
# 查看环境变量
echo $PATH
- LIBRARY_PATH:程序编译期间查找动态链接库时,指定查找共享库的路径。
LD_LIBRARY_PATH:程序加载运行期间查找动态链接库时,除了系统默认路径之外的其他路径。
多版本CUDA切换
# 检查当前虚拟环境需要的cuda
python -c "import torch; print(torch.__version__, torch.cuda.is_available())"
安装的cuda版本在/user/local/目录下。
将~/.bashrc或~/.zshrc下与cuda相关的路径都改为/usr/local/cuda/,而不是使用具体的/usr/local/cuda-11.1这种。
## 切换cuda版本: 需要sudo权限
# 1. 删除之前创建的软链接
rm -rf /usr/local/cuda
# 2. 创建新的软链接
sudo ln -s /usr/local/cuda-11.7/ /usr/local/cuda/
# 3. 查看当前的cuda版本
nvcc --version
json文件的读写
本人经常需要用到对json文件的处理,但是脑子老是记不住代码,遂记录一下。
import json
# 读取json文件
json_file = 'data.json'
with open(json_file, 'r') as f:
datas = json.load(f)
# 写入json文件
datas = [
{id=0, name='Lisa'},
{id=1, name='Alice'},
]
# indent=4: 缩进4个space
with open(json_file, 'w') as f:
json.dump(datas, f, indent=4)
# 读取jsonl文件
jsonl_file1 = []
with open(jsonl_path1, 'r') as f:
for line in f:
item = json.loads(line.strip())
jsonl_file1.append(item)
# 写入jsonl文件
data = [{}, {}, ...]
with open(jsonl_path1, 'w') as f:
for item in data:
json.dump(item, f)
f.write('\n')
csv文件的读写
import pandas as pd
# 1. 读取csv文件
df = pd.read_csv(csv_path)
# 2. 遍历csv文件
for index, row in df.iterrows():
image = row.iloc[1] # 每一行第二列数据,索引从0开始
image = row['image'] # 每一行列名为image的数据
# 3. 生成csv文件
df.to_csv(out_path)
png文件的读写
- png图片(P模式):用PIL的Image.open()函数读取时,默认是P模式,即一个单通道的图像。背景的像素值为0,目标边缘处的像素值为255(训练时一般会忽略像素值为255的区域),目标区域内根据类别索引信息进行填充。
# 调色板模式 保存图像
# 将array格式的mask转换为PIL.Image格式,然后添加调色板
# 最后保存PIL.Image格式的图像
def save_colored_mask(mask, save_path):
lbl_pil = Image.fromarray(mask.astype(np.uint8), mode="P")
colormap = imgviz.label_colormap()
lbl_pil.putpalette(colormap.flatten())
lbl_pil.save(save_path)
# 调色板模式 读取图像(不能用cv2库来读取)
label = np.asarray(Image.open(label_path), dtype=np.int32)
- png图片(L模式):灰度模式。
# 灰度模式 保存图像
cv2.imwrite()
# 灰度模式 读取图像
label = cv2.imread(path, 0)
label = np.asarray(Image.open(label_path), dtype=np.int32)
- png图片(rgba模式):Red Green Blue Alpha,是RGB通道加上Alpha通道。png是一种使用RGBA的图像格式。Red Green Blue通道的取值范围在0255,Alpha为透明度,取值为0255,255表示完全不透明,0表示完全透明。
- png图片(RGB模式)。
# 将三通道的图片保存为png
img_array = np.zeros((100, 100, 3), dtype=np.uint8)
img = Image.fromarray(img_array)
img.save("image.png")
jupyter使用小技巧
在jupyter notebook中指定GPU编号:
import torch
torch.cuda.set_device(3) # 3 指的是第三块 GPU
vscode+jupyter:使jupyter在后台运行
# 在virtual env里安装jupyter包
pip install jupyter
# 确保virtual env里有nbconvert包
pip show nbconvert
# cd至对应文件路径处
# 运行.ipynb文件: --inplace可以将文件运行的输出保存至原jupyter文件
jupyter nbconvert --execute mycodee.ipynb --inplace
杀死僵尸进程
僵尸进程:nvidia-smi查不到进程号,但是占用显存。
# 查看占用显存的进程
sudo fuser -v /dev/nvidia*
# 查看某进程具体的显存使用情况
pmap -d PID
# 强行关掉所有的僵尸进程
kill -9 PID
记录神奇的conda报错
Conda时出现CondaHTTPError: HTTP 404 问题解决方法
conda报错:CondaValueError: Malformed version string ‘~’: invalid character(s).
尝试了几个网上的博客,都没用。原因是我的conda版本太旧了,于是卸载Anaconda后重装了一个新版本。
安装OpenSlide库:pip install openslide-python openslide-bin
遇到了神奇的报错: ERROR: Problem encountered: Mo openslide-bin whel is available for your platform, Instal! 0penSlide from source
解决办法:在openslide-bin官网下载了openslide bin-4.0.0.5-py3-none-manylinux_2_28_x86_64.whl,重命名为openslide bin-4.0.0.5-py3-none-manylinux_2_27_x86_64.whl(把28修改为27),然后pip install openslide bin-4.0.0.5-py3-none-manylinux_2_27_x86_64.whl。
查看当前python版本匹配的文件:pip debug --verbose。
安装python第三方库遇到的bug
一些import和pip install 不一致的情况:
import cv2:pip install opencv-python。
linux下载kaggle数据集
主要参考如下博客,有效!
Linux通过kaggle api下载kaggle数据集
目前只在2x的base环境中配置好了,未来可能需要在其他服务器上重新配置。
记录一下遇到的几个问题:
pip install kaggle报错:ERROR: Cannot uninstall ‘certifi‘. It is a distutils installed project and thus we cannot accurately。解决办法是命令行运行:pip install kaggle --ignore-installed certifi。
参考博客:ERROR: Cannot uninstall ‘certifi‘. It is a distutils installed project and thus we cannot accurately- 输入数据集下载命令时报错:
ImportError: urllib3 v2.0 only supports OpenSSL 1.1.1+, currently the ‘ssl‘ module is compiled。解决办法是:安装更高版本的urlib3库,pip install urllib3==1.26.15。
参考博客:【已解决】 ImportError: urllib3 v2.0 only supports OpenSSL 1.1.1+, currently the ‘ssl‘ module is compiled
line_profiler 分析cpu瓶颈
- 在python代码中,用
@profile装饰器来标记需要进行性能分析的函数。注意,这个装饰器在正常运行代码时会导致错误,因为他没有被定义。后面使用line_profiler工具运行代码时会正确识别。 - 使用kernprof命令来运行python脚本:
kernprof -l -v scripts.py,-l参数表示逐行分析,-v参数表示在分析完成后立即输出详细的分析结果。 - 运行完成后,会生成一个以
.lprof为后缀的文件。可以执行python -m line_profiler your_file.lprof命令来查看该文件。这个文件里显示了每一行代码的执行时间,与在总运行时间里的占比。
Github issue实用例句
Any help and guidance would be much appreciated!
任何帮助和指导都将不胜感激!
Hi and thank you for continuing help and support.
您好,感谢您一直以来的帮助和支持。
Many thanks.
非常感谢!
Thanks again for helping me with this.
再次感谢你帮我做这件事。
Never expected to receive a reply!
从未想过会收到回复!
Thank you for selflessly sharing this great work.
感谢您无私分享这项伟大的工作!
This is very inspiring to me, but I still have some questions.
这对我来说非常有启发,但我仍然有一些问题。
Thanks and kind regards.
感谢并致以亲切的问候。
I would second this.
我会附议这一点。
I have the same question.
我有同样的问题。
分割任务
- 全景分割 panoptic segmentation:同时进行语义分割和实例分割,每个像素被分配一个类别label和实例label。在实例分割的基础上,不仅需要对前景物体进行分割,还需要对背景进行检测和分割。测试指标是PQ、AP、mIoU。
- 语义分割 semantic segmentation:将图像中每个像素分配给一个特定的类别。常用于医学图像分析。测试指标是mIoU。
- 实例分割 instance segmentation:在语义分割的基础上,标注出同类物体的不同个体。如,两只不同的狗会被标记为狗1和狗2。测试指标是AP。
语义分割
参考博客:【霹雳吧啦】手把手带你入门语义分割1:语义分割的定义 & 常见数据集 & 评价指标 & 标注工具
语义分割mask可视化:
# OpenCV方式:
image = cv2.imread('2007_000033.jpg')
mask = cv2.imread('2007_000033.png')
mask_img = cv2.addWeighted(image, 0.5, mask, 0.7, 0.9)
cv2.imwrite("vis.jpg", mask_img)
# PIL方式:
image = Image.open('2007_000033.jpg')
mask = Image.open('2007_000033.png')
mask_img = Image.blend(image.convert('RGBA'),
mask.convert('RGBA'), 0.7)
mask_img.save("vis2.png")



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









