 嵌入式开发核心技术笔记
嵌入式开发核心技术笔记






LINUX内核态和用户态开发的注意事项
核心概念:权限与隔离
- 内核态:操作系统核心运行的模式。
- 权限:拥有对硬件(CPU、内存、设备等)的直接、无限制的访问权限。可以执行所有特权指令。
- 目标:管理进程、内存、设备驱动等,为用户程序提供服务。
- 类比:国家的“政府”和“军队”,拥有最高权力,管理国家资源。
- 用户态:普通应用程序运行的模式。 ·
- 权限:权限受限。不能直接访问硬件,必须通过操作系统提供的“接口”来请求服务。 ·
- 目标:执行特定的应用程序逻辑。 ·
- 类比:国家的“普通公民”,必须通过法律和系统(即系统调用)来使用国家资源。
CPU通过硬件机制实现这种隔离。当用户态程序需要执行特权操作时,必须触发一个“软中断”,将CPU控制权交给内核,这个过程就是系统调用。
主要区别与编码注意事项
| 特性 | 内核态 | 用户态 | 注意事项与原因 |
|---|---|---|---|
| 头文件 | <linux/.h>, <asm/.h> | <stdio.h>, <stdlib.h> | 禁止混用。内核头文件包含内部数据结构和不安全函数,用户程序无法链接。 |
| 函数库 | 无标准C库 | 完整标准C库 | 内核禁用printf/malloc/fopen,需改用printk/kmalloc/filp_open等内核专用函数。 |
| 内存管理 | kmalloc/vmalloc/kfree | malloc/free/mmap | 内核内存不足时无法交换,分配失败后果严重,必须妥善处理错误。 |
| 错误处理 | 直接返回错误码 | errno全局变量 | 内核函数返回0表示成功,负数表示错误;用户态通过返回值+errno组合指示错误。 |
| 并发与同步 | 中断/多CPU/内核抢占 | 多线程 | 内核并发环境复杂,需谨慎使用自旋锁/信号量/RCU,避免死锁或系统崩溃。 |
| 上下文 | 进程/中断上下文 | 仅进程上下文 | 中断上下文禁止睡眠(不可调用可能调度的函数),这是常见错误根源。 |
| 浮点运算 | 需手动保存FPU状态 | 自由使用 | 内核通常避免浮点运算,因FPU状态切换开销大且复杂。 |
| 调试 | printk/oops/kgdb | gdb/printf/valgrind | 内核bug可致系统崩溃,调试困难。printk输出受日志级别控制,可能不可见。 |
| 模块化 | 可加载内核模块 | 动态链接库 | 内核模块加载后即成为系统核心组件,错误将影响全局。 |
| 资源限制 | 理论上无限制 | 受ulimit约束 | 内核代码必须严格自律,资源滥用会导致系统瘫痪。 |
| 可移植性 | 需处理架构差异 | 通常可移植 | 内核代码常通过#ifdef应对不同CPU架构(如x86/ARM)的特性差异。 |
开发中遇到内核态vs用户态例子
一些内核态和用户态开发中的错误,常发生在内核代码移植过程中:
-
BITS_PER_BYTE 未定义
-
内核:这个宏通常在内核头文件(如 <linux/bitops.h>)中定义,值为8。
-
用户态:标准C库没有这个宏。你需要自己定义(#define BITS_PER_BYTE 8)或者使用更通用的 CHAR_BIT(来自 <limits.h>),它的值也是8,表示一个char类型的位数。
-
-
fallthrough 未定义 ·
-
内核:从某个版本开始,Linux内核为了在switch-case中明确标记“故意穿透”的行为,定义了 fallthrough 这个伪关键字。 ·
-
用户态:这是C17标准引入的属性。在用户态程序中,你需要: · 确保编译器支持C17或更高版本(在编译命令中加 -std=c17)。 · 果编译包含 <stdattributes.h>(如器需要的话)。对于GCC,attribute((fallthrough)) 是更通用的方式。通常可以进行如下的特殊处理:
#ifdef __GNUC__ #define fallthrough __attribute__((fallthrough)) #else #define fallthrough // 留空或做其他处理 #endif
-
-
最初的 offsetof 静态初始化问题 ·
-
内核:内核的构建环境对“常量表达式”的定义可能比用户态宽松,或者它使用了某些编译器扩展(如GCC的 __builtin_offsetof),使得在静态初始化中使用 offsetof 成为可能。 ·
-
用户态:严格遵守ISO C标准,要求静态初始化器必须是编译时常量。虽然 offsetof 看起来是常量,但标准并未强制要求它能在初始化器中使用。因此,更安全的做法是在运行时赋值。
-
总结:从用户态思维切换到内核态思维的要点
- 权限意识:你写的代码拥有“上帝权限”,一个微小的错误(如空指针解引用)就会让内核崩溃,而不是像用户程序那样仅仅产生一个段错误。
- 并发意识:默认假设你的代码会在多核上同时运行,并且可能被中断打断。同步原语不是可选项,而是必需品。
- 资源意识:内存、栈空间都是宝贵资源。分配了就要记得释放,栈溢出没有保护。
- 无后援意识:内核里没有“操作系统”来帮你。你不能睡眠等待一个可能永远不会发生的事件。
- 可移植性意识:时刻想着你的代码可能运行在不同的CPU架构上,避免对数据大小、字节序做出硬性假设。
当你将一个内核代码移植到用户空间时,就像把一辆F1赛车的发动机拆下来想装进家用轿车里,你必须处理油品、尺寸、法规等一系列适配问题。你遇到的这些编译错误,正是这个“适配过程”中需要解决的“法规”和“接口”问题。
网络性能测试工具 iperf3
服务端命令:iperf3 -s
客户端命令:iperf3 -c <服务器IP>
客户端常用参数说明:
-p:指定服务器端口(默认5201)-t:设置测试时长(秒),默认10秒-i:设置报告间隔时间(秒)-P:启用并发连接数(默认单线程)-u:使用UDP协议(默认TCP)-b:UDP测试时指定目标带宽-R:反向测试(默认客户端→服务器)-w:设置TCP窗口/UDP缓冲区大小(高级配置)--logfile:保存测试结果到指定文件-A:设置CPU亲和力(多核系统性能调优)
服务端参数说明:
-s:启动服务器模式--bind:绑定指定IP地址进行监听
网段和vlan
同一网段和同一VLAN是网络领域中两个不同的概念,它们在定义、划分方式和通信特性等方面存在显著差异。
定义与划分方式
-
同一网段:基于IP地址和子网掩码划分。当两个设备的IP地址与子网掩码进行逻辑与运算后得到相同的网络地址时,即视为同一网段。例如:
- 设备A:IP 192.168.1.10/24
- 设备B:IP 192.168.1.20/24 两者运算后网络地址均为192.168.1.0,故属于同一网段。
-
同一VLAN:通过逻辑方式划分的虚拟工作组,可基于端口、MAC地址、协议或IP子网等方式划分。例如:
- 交换机端口1-10划为VLAN 10
- 端口11-20划为VLAN 20
通信特性
- 同一网段:设备间通信无需经过三层设备,直接通过ARP获取MAC地址后进行数据传输。
- 同一VLAN:VLAN内设备可直接通信,即使IP不在同一网段。不同VLAN间通信需借助三层设备(如路由器或三层交换机)。例如:
- VLAN 10包含192.168.1.0/24和192.168.2.0/24两个网段
- 默认情况下这两个网段间设备无法直接通信
广播域特性
- 同一网段:属于同一广播域,网段内所有设备都会接收广播帧。
- 同一VLAN:每个VLAN构成独立的广播域,有效隔离广播风暴。
应用场景
- 同一网段:适用于小型网络(如家庭或部门网络),便于设备直接通信和资源共享。
- 同一VLAN:适合企业级网络,可按部门或功能划分VLAN,提升安全性和管理效率。
nand命令
NAND Flash 操作命令
nand write
将内存数据写入 NAND Flash 指定地址
格式:nand write <src_addr> <dest_addr> <size>
参数说明:
- src_addr:内存中的源数据起始地址
- dest_addr:NAND Flash 的目标写入地址
- size:要写入的数据大小
注意:写入前需先用 nand erase 擦除目标区域
nand info
显示 NAND Flash 信息,包括:
- 页大小
- OOB 域大小
- 擦除块大小等
nand device
切换当前操作的 NAND Flash 设备(需硬件支持多片 NAND)
nand erase
擦除 NAND Flash 存储区域,支持以下模式:
nand erase[.spread] [clean] off size:从指定偏移地址(off)开始擦除指定大小(size)的区域nand erase.part [clean] partition:擦除指定分区nand erase.chip [clean]:全片擦除
nand read
从 NAND Flash 读取数据到 DRAM
格式:nand read <addr> <off> <size>
参数说明:
- addr:DRAM 中的目标地址
- off:NAND Flash 中的源数据偏移地址
- size:要读取的数据大小
C库函数 system/WIFEXITED/WEXITSTATUS
system函数
头文件:<stdlib.h> 原型:int system(const char *command);``
command 是要执行的系统命令字符串 如果发生错误,system 函数返回值为 -1,否则返回命令的状态
WIFEXITED宏
WIFEXITED 是一个宏,用于判断子进程是否正常结束。
通常与 system 函数结合使用,用于检查 system 函数执行的命令是否正常退出。
头文件: <sys/wait.h> 。
WIFEXITED(status) 如果子进程正常结束则为非 0 值,这里的 status 是 system 函数的返回值。一般在使用 WEXITSTATUS 之前,会先用 WIFEXITED 来判断子进程是否正常结束
WEXITSTATUS宏
获取子进程 exit() 返回的退出状态码
头文件: <sys/wait.h> 使用时建议先用 WIFEXITED 判断进程是否正常终止,只有正常终止时才使用此宏。
示例代码:
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <sys/types.h>
int main() {
pid_t status;
status = system("./test.sh");
if (-1 == status) {
printf("system error!");
} else {
if (WIFEXITED(status)) {
if (0 == WEXITSTATUS(status)) {
printf("run shell script successfully.\n");
} else {
printf("run shell script failed, exit code: %d\n", WEXITSTATUS(status));
}
}
}
return 0;
}
Swconfig 命令
OpenWrt 交换机配置命令详解
1. 基础信息查询命令
-
swconfig list
列出当前系统中所有可用的交换机设备。例如在MT7621平台上会显示类似switch0: eth0(realtek rtl8367s)的设备信息。 -
swconfig dev switch0 show
显示指定交换机的详细配置,包括:- 各物理端口状态(如Port 0对应CPU,Port 1-5对应LAN口)
- VLAN划分情况(含tagged/untagged标记)
- 示例输出会包含类似
vlan 1: ports: 0t 1 2 3 4 5的VLAN绑定信息
2. 帮助命令
swconfig --help
显示完整的命令语法和参数说明,包含以下关键参数:dev指定交换机设备vlan操作VLAN配置port操作物理端口set apply提交配置
3. VLAN配置命令
-
swconfig dev switch0 vlan 3 set ports "1 2 6t"
创建/修改VLAN 3的端口绑定:1 2表示端口1和2以untagged方式加入6t表示端口6以tagged方式加入(常用于上行端口)- 典型应用:将IPTV业务划分到VLAN 3,绑定到LAN1和LAN2口
-
swconfig dev switch0 vlan 3 set vid 3
显式设置VLAN ID(VID),某些交换机需要此命令确保802.1Q标签正确
4. 端口PVID设置
swconfig dev switch0 port 0 set pvid 3
设置端口0的默认VLAN ID(PVID)为3:- 该端口接收的untagged流量会自动归类到VLAN 3
- 典型场景:设置WAN口的PVID为运营商指定的VLAN ID
5. 配置生效命令
swconfig dev switch0 set apply
将内存中的配置写入交换机芯片,注意:- 未执行此命令前所有修改仅暂存
- 部分设备需要配合
ifconfig eth0 down/up重启接口
6. 典型配置流程示例
- 创建VLAN 100:
swconfig dev switch0 vlan 100 set ports "0t 4" - 设置端口4的PVID:
swconfig dev switch0 port 4 set pvid 100 - 设置VLAN ID:
swconfig dev switch0 vlan 100 set vid 100 - 提交配置:
swconfig dev switch0 set apply
注意:不同交换机芯片(如Realtek/Broadcom)可能存在语法差异,建议通过
swconfig dev switch0 help查看芯片特定支持的功能。
ALG 应用层网关协议
ALG网关(Application Layer Gateway,应用层网关)是一种工作在OSI模型第4-7层(传输层至应用层)的高级流量管理安全设备。与传统防火墙/NAT设备相比,它通过深度解析应用层协议报文头及载荷内容,实现对复杂网络协议的智能处理。
核心工作原理:
- 协议解析引擎:内置FTP、SIP、H.323等50+种常见协议的语法分析器
- 动态规则生成:检测到PORT/PASV等指令时自动创建临时ACL规则
- 智能NAT转换:实时修改协议载荷中的IP/端口信息(如FTP数据通道的227响应)
- 会话状态跟踪:维护完整的协议状态机(如SIP的INVITE-200OK-ACK流程)
典型应用场景:
- 企业视频会议系统:解决H.323协议穿越NAT时的媒体流建立问题
- 运营商SIP中继:实现IMS网络与PSTN的协议转换(如SIP-to-ISUP)
- 工业物联网:处理Modbus TCP等工控协议的指令级过滤
- 云游戏平台:优化RTMP协议流在混合云环境中的传输路径
技术优势对比:
| 特性 | 传统防火墙 | ALG网关 |
|---|---|---|
| 协议感知 | 仅识别L4 | 深度解析L7 |
| 端口预测 | 静态映射 | 动态预测 |
| 载荷修改 | 不支持 | 智能重写 |
| 会话完整性 | 无状态 | 全状态跟踪 |
当前主流实现包括:
- 开源方案:Kamailio(SIP ALG)、vsftpd(FTP ALG)
- 商业产品:F5 BIG-IP ASM、Palo Alto PA-Series
- 云服务:AWS Gateway Load Balancer、Azure Firewall Premium
最新演进方向包括支持HTTP/2、QUIC等新协议,以及结合AI实现异常流量检测(如识别VoIP中的DDOS攻击模式)。
Linux内核态和用户态编程区别
__read_mostly 是 Linux 内核代码中广泛使用的一个编译器属性宏,主要用于优化那些"频繁读取但很少写入"的变量。这个宏通过 __section(".data..read_mostly") 将变量放置在专门的内存区域,使得这些变量在多核处理器系统中能够获得更好的缓存性能。它的典型应用场景包括:
- 内核统计计数器
- 频繁访问的配置参数
- 常用的全局标志位
在内核源码中,这个宏通常这样定义:
#define __read_mostly __section(".data..read_mostly")
相比之下,在用户态程序中并没有直接对应的宏,因为用户态程序通常不需要处理如此精细的缓存优化。用户态程序可以使用 __attribute__((section)) 来实现类似功能,但这不是标准做法。
__be16 类型是 Linux 内核网络子系统和其他需要处理网络字节序的模块中广泛使用的重要数据类型。它的完整定义如下:
typedef __u16 __bitwise __be16;
这个类型定义可以在多个内核头文件中找到:
include/uapi/linux/types.hinclude/linux/types.htools/include/linux/types.h
__be16 的关键特性包括:
- 明确表示16位无符号整数
- 强制使用大端序(big-endian)字节序
- 通过
__bitwise属性确保类型安全,防止误用
这种类型在网络协议处理中特别重要,因为:
- 网络协议通常规定使用大端序
- 可以避免在不同字节序系统间的转换错误
- 提供编译时的类型检查
典型使用场景包括:
- 解析IP头部的长度字段
- 处理TCP/UDP端口号
- 读取网络协议中的各种16位字段
在使用时,内核提供了专门的转换函数:
__be16 cpu_to_be16(u16 x); // 主机字节序转网络字节序
u16 be16_to_cpu(__be16 x); // 网络字节序转主机字节序
这种严格的类型系统设计是Linux内核网络栈可靠性和可移植性的重要保证之一。
Linux网络连接追踪机制
Linux期望连接和实际连接的惰性创建机制 Linux内核中的期望连接(expect)和实际连接的惰性创建机制是连接跟踪(conntrack)系统的核心特性,主要用于处理协议辅助连接(如FTP、H.323等需要动态创建子连接的协议)。以下是详细解释:
-
期望连接(Expectation)机制:
◦ 当检测到控制协议(如FTP PORT命令)时,内核会创建一个期望连接项 ◦ 这个期望项包含:预期连接的五元组信息、超时时间、关联的主连接等 ◦ 存储在
nf_ct_expect_hash哈希表中,通过nf_ct_expect_find_get()查找 -
实际连接的惰性创建:
◦ 当数据包到达时,首先检查是否匹配现有连接 ◦ 如果不匹配,再检查是否匹配期望连接(通过
nf_ct_find_expectation()) ◦ 只有匹配到期望连接时,才会实际创建连接跟踪项 -
关键数据结构: c 复制
struct nf_conntrack_expect { struct nf_conntrack_tuple tuple; // 期望的连接五元组 struct nf_conntrack_tuple_mask mask; // 匹配掩码 struct nf_conn *master; // 关联的主连接 struct timer_list timeout; // 期望超时定时器 // ...其他字段 }; -
生命周期管理:
◦ 期望连接有独立超时机制(通过
timer_list实现) ◦ 超时或匹配成功后自动删除(nf_ct_unlink_expect) ◦ 主连接销毁时会清理所有关联期望(nf_ct_remove_expectations) -
性能优化:
◦ 使用哈希表加速查找(
nf_ct_expect_dst_hash) ◦ 惰性创建避免为所有可能的连接预先分配资源 ◦ 通过掩码匹配支持通配(如只关注特定端口) 这种机制使得Linux可以高效处理需要动态端口协商的协议,同时保持连接跟踪系统的资源利用率。 Linux内 Linux预期与实际连接以及SNAT和DNAT -
五元组核心字段(struct nf_conntrack_tuple):
struct nf_conntrack_tuple { struct nf_conntrack_man_proto src; // 源协议信息(端口/ICMP ID等) union nf_inet_addr dst.u3; // 目标IP地址 u_int8_t dst.protonum; // 协议类型 }; -
SNAT处理流程:
sequenceDiagram participant Client participant NAT participant Server Client->>NAT: src=3.3.3.3:1234 dst=2.2.2.2:80 NAT->>NAT: 修改tuple.dst (MANIP_DST) NAT->>Server: src=3.3.3.3:1234 dst=192.168.1.3:80 Server->>NAT: src=192.168.1.3:80 dst=3.3.3.3:1234 NAT->>NAT: 反向查找映射 NAT->>Client: src=2.2.2.2:80 dst=3.3.3.3:1234
- DNAT处理流程:
sequenceDiagram participant Client participant NAT participant Server Client->>NAT: src=3.3.3.3:1234 dst=2.2.2.2:80 NAT->>NAT: 修改tuple.dst (MANIP_DST) NAT->>Server: src=3.3.3.3:1234 dst=192.168.1.3:80 Server->>NAT: src=192.168.1.3:80 dst=3.3.3.3:1234 NAT->>NAT: 反向查找映射 NAT->>Client: src=2.2.2.2:80 dst=3.3.3.3:1234
-
关键修改点(通过nf_nat_setup_info):操作类型修改字段典型场景
NF_NAT_MANIP_SRCtuple->src.u3.ip/port内网客户端出站(SNAT)NF_NAT_MANIP_DSTtuple->dst.u3.ip/port公网服务入站(DNAT) -
实际连接创建顺序:
◦ 先创建基础五元组(包含原始IP/port) ◦ 通过
nf_ct_expect_related()注册期望连接 ◦ 触发实际连接时调用expectfn回调 ◦ 在回调中通过nf_nat_setup_info()修改五元组
GDB调试指南
GDB调试方法
GDB (GNU Debugger) 是Linux系统下功能强大的调试工具,提供了多种方式来调试正在运行的进程。以下是常用的调试方法:
1. 附加到正在运行的进程
gdb -p <PID>
或
gdb attach <PID>
其中 <PID> 是目标进程的进程ID,可以通过以下命令查找:
ps aux | grep <process_name>查看进程信息pgrep <process_name>直接获取进程IDtop或htop查看运行中的进程
2. 启动程序并调试
gdb ./executable
进入GDB后:
(gdb) run [arguments]
可以带参数运行程序,例如:
(gdb) run arg1 arg2 --option=value
3. 核心转储调试
当程序崩溃时,可以使用核心转储文件进行分析:
gdb ./executable core.<PID>
要生成核心转储文件,需要先设置:
ulimit -c unlimited
echo "core.%e.%p" > /proc/sys/kernel/core_pattern
常用GDB命令
基本调试命令
| 命令 | 描述 | 示例 |
|---|---|---|
break <function> | 在函数处设置断点 | break main |
break <file>:<line> | 在指定文件的指定行设置断点 | break src/main.c:42 |
continue | 继续执行 | c (缩写) |
next | 执行下一行代码(不进入函数) | n (缩写) |
step | 执行下一行代码(进入函数) | s (缩写) |
finish | 执行完当前函数并暂停 | fin |
print <var> | 打印变量值 | print x, p &array |
backtrace | 显示调用栈 | bt (缩写) |
多线程调试
| 命令 | 描述 | 示例 |
|---|---|---|
info threads | 显示所有线程 | info thr |
thread <id> | 切换到指定线程 | thread 2 |
thread apply all bt | 显示所有线程的调用栈 |
进程控制
| 命令 | 描述 |
|---|---|
detach | 分离调试的进程(让进程继续运行) |
kill | 终止正在调试的进程 |
quit | 退出GDB |
高级调试技巧
条件断点
break <location> if <condition>
例如:
break main.c:100 if x > 100
观察点
watch <variable> # 变量值改变时中断
rwatch <variable> # 变量被读取时中断
awatch <variable> # 变量被访问(读/写)时中断
远程调试
- 在目标机上启动gdbserver:
gdbserver :1234 ./program
- 在开发机上连接:
gdb ./program
(gdb) target remote target_ip:1234
调试优化过的代码
建议使用 -O0 编译选项禁用优化,以获得更准确的调试信息:
gcc -g -O0 -o program program.c
调试时可以使用以下命令查看优化情况:
Linux连接跟踪与NAT机制详解
期望连接与实际连接的惰性创建机制
Linux内核中的期望连接(expect)和实际连接的惰性创建机制是连接跟踪(conntrack)系统的核心特性,主要用于处理协议辅助连接(如FTP、H.323等需要动态创建子连接的协议)。以下是详细解释:
期望连接(Expectation)机制
-
创建时机:
- 当检测到控制协议(如FTP PORT命令或PASV响应)时
- SIP协议中的媒体通道协商时
- H.323协议中的动态端口分配时
-
期望连接项内容:
- 预期连接的五元组信息(源/目的IP、端口、协议)
- 超时时间(通常设置为3-5分钟)
- 关联的主连接指针
- 匹配掩码(指定哪些字段需要精确匹配)
- 回调函数(用于连接建立时的额外处理)
-
存储与查找:
- 存储在nf_ct_expect_hash哈希表中
- 通过nf_ct_expect_find_get()函数查找
- 使用期望目标地址哈希(nf_ct_expect_dst_hash)加速查找
实际连接的惰性创建流程
-
数据包处理流程:
- 数据包到达时首先通过__nf_conntrack_find_get()检查现有连接
- 若无匹配,调用nf_ct_find_expectation()检查期望连接
- 匹配成功后调用init_conntrack()创建实际连接项
- 最后调用nf_conntrack_confirm()确认连接
-
关键优势:
- 资源节省:避免预先分配所有可能连接
- 灵活性:支持通配匹配(如仅指定目标端口)
- 协议兼容:完美支持FTP等复杂协议
关键数据结构
struct nf_conntrack_expect {
struct hlist_node lnode; // 哈希表节点
struct nf_conntrack_tuple tuple; // 期望连接五元组
struct nf_conntrack_tuple_mask mask; // 匹配掩码
struct nf_conn *master; // 关联的主连接
struct timer_list timeout; // 期望超时定时器
void (*expectfn)(struct nf_conn *new); // 回调函数
atomic_t use; // 引用计数
unsigned int flags; // 标志位
// ...其他辅助字段
};
生命周期管理
-
超时机制:
- 通过timer_list实现超时回调
- 默认超时时间根据协议类型设置(FTP通常300秒)
- 超时后调用nf_ct_unlink_expect()移除期望
-
清理机制:
- 匹配成功后自动删除期望项
- 主连接销毁时通过nf_ct_remove_expectations()清理关联期望
- 通过垃圾回收机制定期清理过期期望
性能优化措施
-
哈希加速:
- 使用双重哈希(nf_ct_expect_hash和nf_ct_expect_dst_hash)
- 基于五元组计算哈希值
- 支持掩码匹配减少哈希冲突
-
资源管理:
- 惰性创建避免内存浪费
- 引用计数控制对象生命周期
- 限制最大期望连接数防止DoS攻击
NAT处理机制详解
核心数据结构
struct nf_conntrack_tuple {
struct nf_conntrack_man src; // 源端信息
struct {
union nf_inet_addr u3; // 目标IP地址
union {
__be16 all; // 所有协议
struct {
__be16 port; // TCP/UDP端口
} tcp;
struct {
__be16 port; // TCP/UDP端口
} udp;
struct {
u_int8_t type, code; // ICMP类型/代码
} icmp;
} u;
u_int8_t protonum; // 协议号
u_int8_t dir; // 方向
} dst;
};
SNAT处理流程
-
出站数据包处理:
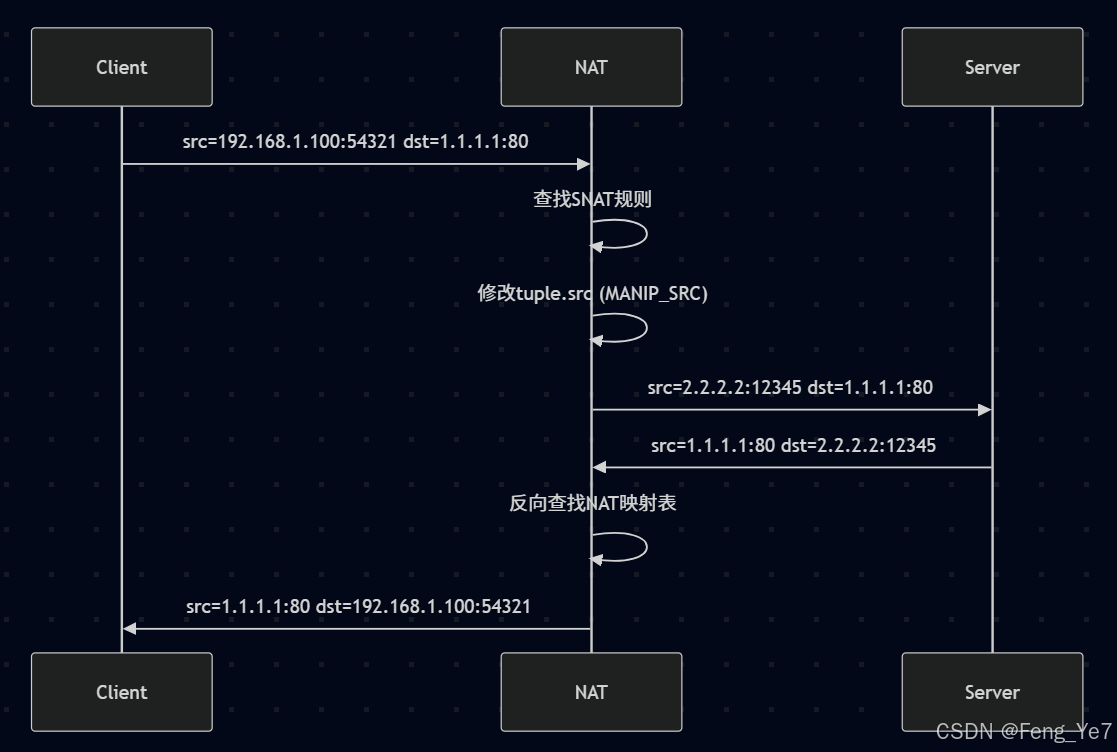
-
关键修改点:
- 修改源IP为公网地址
- 修改源端口(可选)
- 建立反向映射关系
DNAT处理流程
-
入站数据包处理:
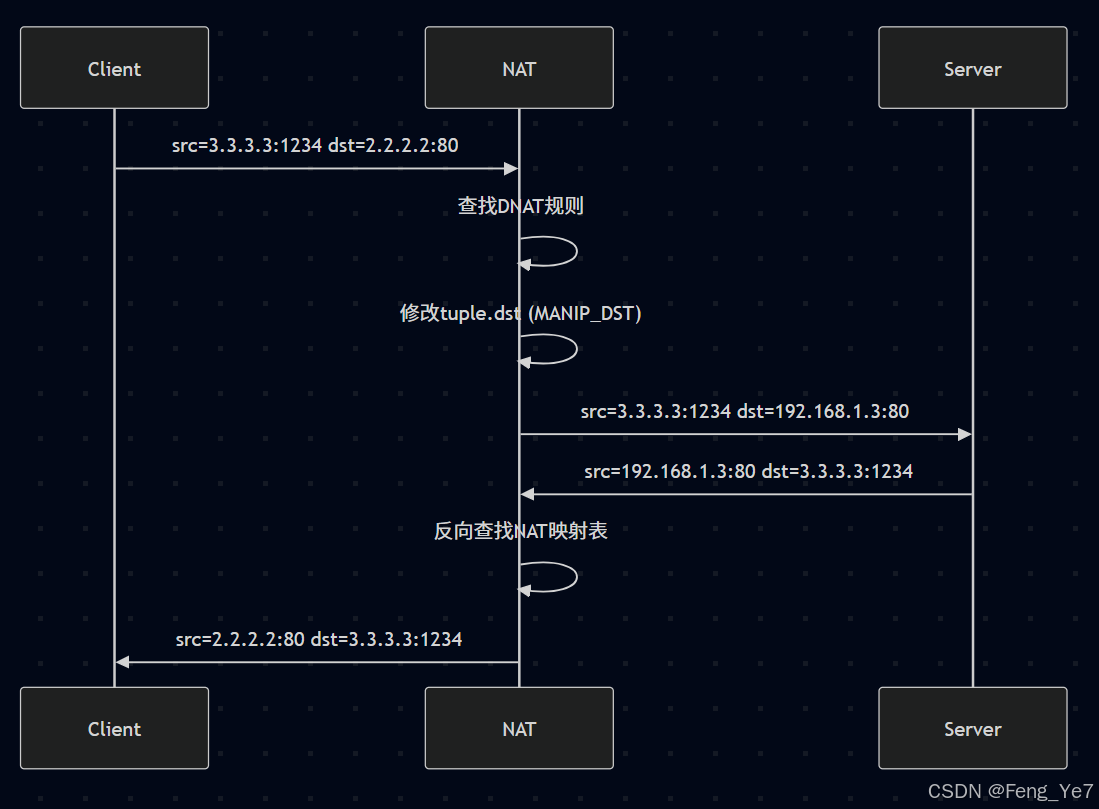
-
关键修改点:
- 修改目标IP为内网地址
- 修改目标端口(可选)
- 建立反向映射关系
NAT类型与修改点
| 操作类型 | 修改字段 | 典型场景 |
|---|---|---|
| NF_NAT_MANIP_SRC | tuple->src.u3.ip/port | 内网客户端出站(SNAT) |
| NF_NAT_MANIP_DST | tuple->dst.u3.ip/port | 公网服务入站(DNAT) |
| NF_NAT_MANIP_BOTH | 同时修改源和目标 | 特殊转发场景 |
实际连接创建顺序
-
基础连接创建:
- 解析原始数据包五元组
- 创建基础连接跟踪项
- 设置连接状态(NEW/ESTABLISHED等)
-
期望连接处理:
- 通过nf_ct_expect_related()注册期望
- 设置期望超时时间
- 关联主连接和回调函数
-
NAT转换阶段:
- 触发实际连接时调用expectfn回调
- 在回调中通过nf_nat_setup_info()执行NAT
- 修改五元组并建立映射关系
- 确认连接(nf_conntrack_confirm)
-
完整示例(FTP数据连接):
1. 客户端发送PORT 192,168,1,100,15,203(IP:192.168.1.100 端口:15*256+203=4043) 2. 内核解析出期望连接:proto=TCP, src=1.1.1.1:20, dst=192.168.1.100:4043 3. 当数据连接到达时,匹配期望并创建实际连接 4. 执行SNAT转换:src=192.168.1.100:4043 → 2.2.2.2:60001 5. 建立完整的连接跟踪项
令牌桶算法
限流算法详解
计数器算法(固定窗口算法)
计数器算法是最简单的限流方式,通过统计固定时间窗口内的请求次数来判断是否限流。
工作原理:
- 设定一个时间窗口(如1秒)和最大请求数阈值(如100次)
- 每个请求到来时,计数器+1
- 如果当前时间窗口内计数超过阈值,则拒绝后续请求
- 时间窗口结束时重置计数器
特点:
- 实现简单,内存消耗小
- 存在临界问题:如果请求集中在两个时间窗口交界处,可能瞬时通过两倍阈值的请求
- 不适用于平滑限流场景
示例场景:API每分钟最多调用100次,前59秒没有请求,最后一秒来了100个请求,下一秒开始又来了100个请求,这样在2秒内实际通过了200个请求。
漏桶算法(Leaky Bucket)
漏桶算法模拟物理漏桶的工作原理,无论请求速率如何变化,系统都以恒定速率处理请求。
工作原理:
- 请求进入漏桶(队列)
- 漏桶以固定速率"漏水"(处理请求)
- 当桶满时(队列达到容量上限),新请求被丢弃或等待
特点:
- 输出速率恒定,可以平滑突发流量
- 无法应对突发带宽需求增加的情况
- 可能导致请求延迟增加
应用场景:适用于需要严格控制处理速率的场景,如数据库写入操作限流。
令牌桶算法(Token Bucket)
令牌桶算法比漏桶算法更灵活,允许一定程度的突发流量。
工作原理:
- 系统以固定速率向桶中添加令牌
- 每个请求需要获取一个令牌才能被处理
- 当桶中有足够令牌时,请求可以立即被处理
- 当桶空时,请求需要等待或被拒绝
特点:
- 允许突发流量(只要桶中有足够令牌)
- 可以动态调整令牌生成速率
- 实现相对复杂
参数配置:
- 桶容量:最大允许的突发请求数
- 令牌生成速率:限流阈值(如100个/秒)
应用场景:适用于需要允许合理突发流量的场景,如Web API限流、网络流量控制等。
对比:
- 计数器算法简单但不够精确
- 漏桶算法强制固定输出速率
- 令牌桶算法更灵活,允许可控的突发流量
在实际应用中,令牌桶算法因其灵活性而被广泛采用,如Google Guava的RateLimiter、Nginx限流模块等都实现了令牌桶算法。
令牌桶算法实例
令牌桶算法是一种常用的流量整形和速率限制算法。它的基本思想是有一个令牌桶,按照一定的速率往桶里放入令牌,每个数据包需要从桶中获取一个或多个令牌才能被发送。如果桶中没有足够的令牌,数据包就会被延迟发送或者丢弃。该算法广泛应用于网络流量控制、API限流等场景,能够有效防止突发流量对系统造成冲击。
在具体实现中,通常会使用双桶机制:C桶(承诺桶)和E桶(额外桶)。C桶对应承诺速率(CIR)和承诺突发量(CBS),E桶对应额外速率(EIR)和额外突发量(EBS)。以下是对配置参数的详细说明:
-
cfg->rb.pps.cir_pps = limit_pps;
- cfg: 指向配置结构体的指针
- rb: 表示速率限制(Rate Limiting)相关的子结构体
- pps: 用于配置基于数据包速率限制的部分
- cir_pps: 承诺信息速率(Committed Information Rate),单位是PPS(每秒数据包数)
- limit_pps: 预先定义的变量,表示承诺的速率上限
- 示例:设置limit_pps=1000时,表示系统承诺每秒最多允许1000个数据包通过
-
cfg->rb.pps.eir_pps = 0;
- eir_pps: 额外信息速率(Excess Information Rate),单位PPS
- 设置为0表示禁用E桶,仅使用C桶进行速率限制
- 这意味着系统不允许任何超过承诺速率的流量通过
-
cfg->rb.pps.cb_ms = 1000;
- cb_ms: 承诺突发尺寸(Committed Burst Size),单位毫秒
- 设置为1000ms(1秒)表示允许短时突发流量
- 突发期间可超过cir_pps,但长期平均速率不超过cir_pps
- 示例:当cir_pps=1000时,允许在1秒内突发处理2000个数据包
-
cfg->rb.pps.eb_ms = 0;
- eb_ms: 额外突发尺寸(Excess Burst Size),单位毫秒
- 设置为0表示禁用E桶的突发能力
- 与eir_pps=0配合,完全关闭额外速率桶的功能

















 5685
5685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









