







 本文介绍了如何使用Python爬虫技术抓取豆瓣电影Top250的影片信息,包括导演、编剧、主演等,并将数据存储到本地的DOCX文档中。通过分析子网页结构,利用BeautifulSoup和requests库进行网页解析和数据提取。
本文介绍了如何使用Python爬虫技术抓取豆瓣电影Top250的影片信息,包括导演、编剧、主演等,并将数据存储到本地的DOCX文档中。通过分析子网页结构,利用BeautifulSoup和requests库进行网页解析和数据提取。
(想了想还是趁热打铁吧,之后不一定有空闲时间了哈哈哈) 紧接着上一个文章的内容,我们获取了豆瓣网页的Top250的影片内容,在这里我们将对每一个影片的详细内容网页进行获取,在之前的基础上进行操作。上一篇我们说,如果要获取每一个影片的详细信息,此时CSS已经不再适合进行标签的获取了,因为子网页的内容标签分布比较杂乱,所以使用find()和find_all()来获取标签内容,更合适一些。建议先阅读(经典网络爬虫实践内容---豆瓣网页内容爬取(初级)-CSDN博客)
在这里不仅仅是对内容更详细的子网页进行解析,同时还增加了一个功能,将爬取到的内容,存储到本地路径下的DOCX文档内。下面是本次文章的内容:
访问豆瓣电影Top250(豆瓣电影 Top 250),在上一篇文章(在同一个栏目内,可以去找找看)的基础上,获取每部电影的导演、编剧、主演、类型、上映时间、片长、评分人数以及剧情简介等信息,并将获取到的信息保存至本地文件中。
说明:
本实验与上一个实验类似,但又有不同,需要处理子网页。第一个实验采用CSS选择器获取标签,本实验通过观察网页源码发现,主页电影信息全在<div class="item">…</div>标签内,而且不同信息的class不同;子网页电影详细信息全在<div id="info">…</div>中。所以为了简化代码,本实验使用find()和find_all()获取相应的标签。
由于实验将爬取到的数据保存至本地的Word文档中,所以需要下载并导入新的包docx
关键内容:(怎么知道你要获取的内容在哪个标签内)
点击这个圆圈内的箭头,在左侧网页中选择你要获取的东西,单击一下,它所属的标签就会在右侧中显示出来。(关于怎么打开右侧的页面,另一个文章中已经写好了,可以去看看经典网络爬虫实践内容---豆瓣网页内容爬取(初级)-CSDN博客)
第一步当然是导入我们完成整个程序所以需要的包和库
和之前不同的是,我们这里多了两个东西,Document是用来对本地路径下的docx文档进行操作的,因为要对本地文件进行一些操作,所以我们导入os库。(另外的三个内容,已经在前面的文章中解释过了经典网络爬虫实践内容---豆瓣网页内容爬取(初级)-CSDN博客)

因为涉及两次网页请求,所以为了减少参数传递,我们和上一实验不同的是把请求头内容放在了请求网页函数中,避免参数传入过多。
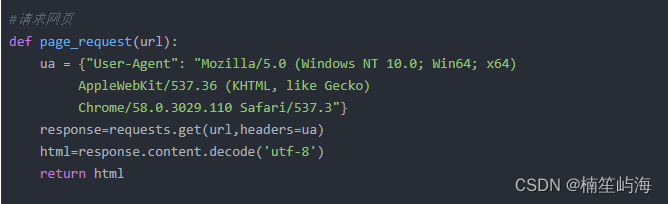
对豆瓣主网页的解析中,我们就不需要获取过多的内容,只需要得到链接内容就可以了,在解析网页函数内,我们把获取到的link链接,传给解析网页的函数,紧接着对得到的子网页进行解析。
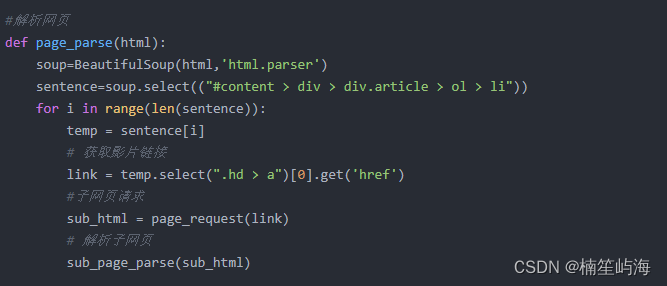
这个实践的重要任务是对子网页的解析,并且把解析到的内容,存入本地的docx文档里面:
(这里因为个别语句过长,所以为了更好的可读性,使用了Pycharm来展示这段代码。显得颜色有一些突兀,理解一下下哈)
对子网页的解析,在本质上来讲和对主网页的解析过程几乎一样,不同的是我们在这里使用find()和find_all()。根据我们所要获取的内容,定位它们的标签以及类别。为了方便区分,所以我们需要获取影片的名称。
但是经过对网页html元素的分析,我们发现title的标签和其他的内容标签不相同,其他内容都存在于'div', class_='grid-16-8 clearfix' 这个标签/类别下,只有title除外,所以我们对title进行单独获取。
因为要实现将获取的内容存在本地docx文档中,所以我们先启动一个文档(最好是和这个项目在一个路径下),把每一个影片的名称,作为一级标题存入,便于区分。
使用find_all()来得到位于'div', class_='grid-16-8 clearfix' 这个标签/类别下我们想得到的东西。对于要获取的内容,需要格外注意的是,导演/编剧/主演这三个内容可以一次获取,因为他们位于同一个标签/类别下面,所以只需要获取一次就可以,使用一个列表表达式:[writer.text for writer in movie.find_all('span', class_='attrs')] 我这里是只对编剧/导演进行了这个操作,为了方便你可以省去director的获取语句,因为director的内容就是writers[0]的内容。
最后,把获取到的内容,以添加段落的方式,加入到本地路径下的docx文件中。
保存路径一定是本地路径(不要有中文)
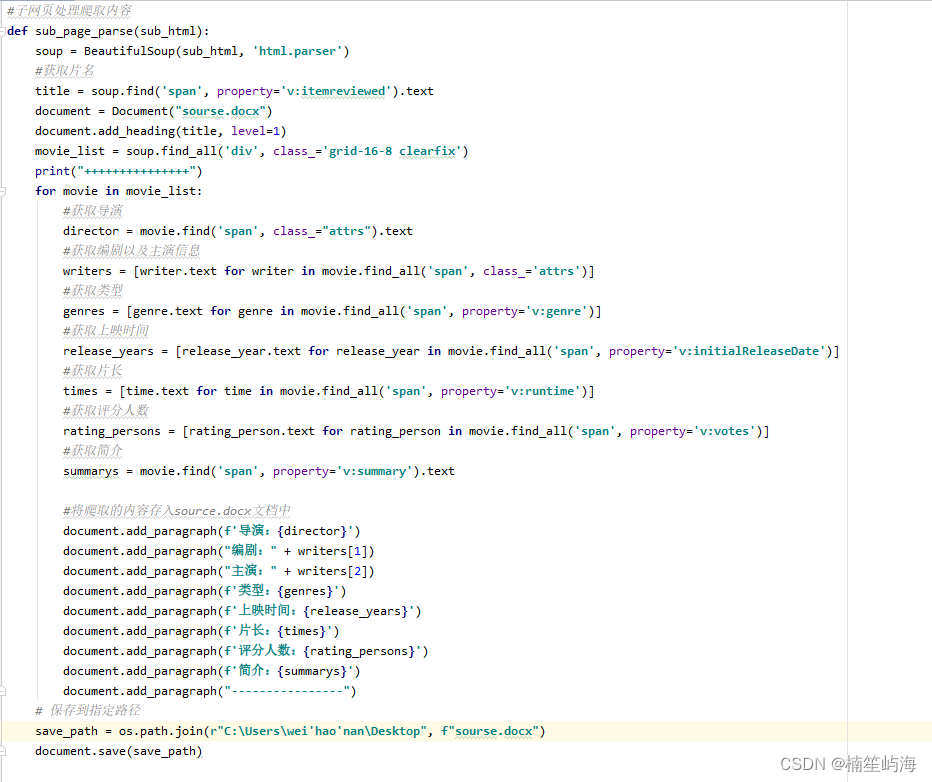
完整代码如下:
import requests from bs4 import BeautifulSoup import time from docx import Document import os #请求网页 def page_request(url): ua = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"} response=requests.get(url,headers=ua) html=response.content.decode('utf-8') return html #解析网页 def page_parse(html): soup=BeautifulSoup(html,'html.parser') sentence=soup.select(("#content > div > div.article > ol > li")) for i in range(len(sentence)): temp = sentence[i] # 获取影片链接 link = temp.select(".hd > a")[0].get('href') #子网页请求 sub_html = page_request(link) # 解析子网页 sub_page_parse(sub_html) #子网页处理爬取内容 def sub_page_parse(sub_html): soup = BeautifulSoup(sub_html, 'html.parser') #获取片名 title = soup.find('span', property='v:itemreviewed').text document = Document("sourse.docx") document.add_heading(title, level=1) movie_list = soup.find_all('div', class_='grid-16-8 clearfix') print("+++++++++++++++") for movie in movie_list: #获取导演 director = movie.find('span', class_="attrs").text #获取编剧以及主演信息 writers = [writer.text for writer in movie.find_all('span', class_='attrs')] #获取类型 genres = [genre.text for genre in movie.find_all('span', property='v:genre')] #获取上映时间 release_years = [release_year.text for release_year in movie.find_all('span', property='v:initialReleaseDate')] #获取片长 times = [time.text for time in movie.find_all('span', property='v:runtime')] #获取评分人数 rating_persons = [rating_person.text for rating_person in movie.find_all('span', property='v:votes')] #获取简介 summarys = movie.find('span', property='v:summary').text #将爬取的内容存入source.docx文档中 document.add_paragraph(f'导演:{director}') document.add_paragraph("编剧:" + writers[1]) document.add_paragraph("主演:" + writers[2]) document.add_paragraph(f'类型:{genres}') document.add_paragraph(f'上映时间:{release_years}') document.add_paragraph(f'片长:{times}') document.add_paragraph(f'评分人数:{rating_persons}') document.add_paragraph(f'简介:{summarys}') document.add_paragraph("----------------") # 保存到指定路径 save_path = os.path.join(r"C:\Users\wei'hao'nan\Desktop", f"sourse.docx") document.save(save_path) if __name__=='__main__': print("开始爬取") for i in range(1,11): url = f'https://movie.douban.com/top250?start={(i - 1) * 25}' time.sleep(1) html=page_request(url) info_list=page_parse(html) print("爬取完成")
这就是对于豆瓣Top250的可以说是全部操作了,实现的功能,可以根据自己的需求进行更改。再往下一个阶段就是针对微博热搜这种实时变化的网页内容的爬取了。
(老样子~ 如果你觉得文章内容还看得过去,那就麻烦给个五星好评吧 哈哈哈哈 谢谢啦)


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









