







 Lucene是一个高性能的全文搜索引擎库,用Java编写,支持多语言包括中文,常用于构建企业搜索系统。其特点是高性能、精确查询、可扩展性,并采用倒排索引提高搜索速度。文章详细介绍了Lucene的索引结构、分析器、倒排索引、查询解析器以及索引和搜索流程,特别适合用于法律文书检索系统。
Lucene是一个高性能的全文搜索引擎库,用Java编写,支持多语言包括中文,常用于构建企业搜索系统。其特点是高性能、精确查询、可扩展性,并采用倒排索引提高搜索速度。文章详细介绍了Lucene的索引结构、分析器、倒排索引、查询解析器以及索引和搜索流程,特别适合用于法律文书检索系统。
Lucene 是一种用 Java 编写的高性能全文搜索引擎库。它提供了丰富的搜索和索引功能,支持多种语言,包括中文,常用于构建企业级搜索系统。Lucene 的基本特点包括:
支持多种语言:Lucene 支持多种语言的文本索引和搜索,包括英语、中文、日语等,可以方便地构建多语言搜索系统。
高性能:Lucene 的搜索速度非常快,可以处理大规模的文本数据。它采用了倒排索引的方法,将索引数据存储在内存中,从而提高搜索效率。
精确度高:Lucene 支持布尔查询、短语查询、通配符查询、模糊查询等多种查询方式,可以满足各种搜索需求,并且结果准确度高。
可扩展性:Lucene 提供了丰富的 API,可以根据需要进行定制和扩展。同时,Lucene 还可以与其他应用程序进行集成,例如 Solr 和 Elasticsearch。
在法律文书领域,Lucene 可以用于构建法律文书检索系统。利用 Lucene 提供的搜索和索引功能,可以快速地检索出相关的法律文书,从而提高律师和法官的工作效率。Lucene 还提供了诸如分页、高亮显示搜索关键字等功能,可以为用户提供更好的搜索体验。
基本图解
原始方式
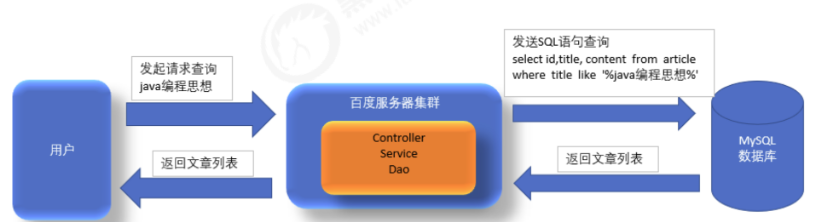
Luncene
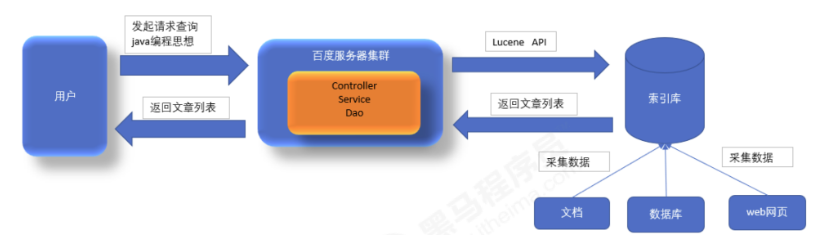
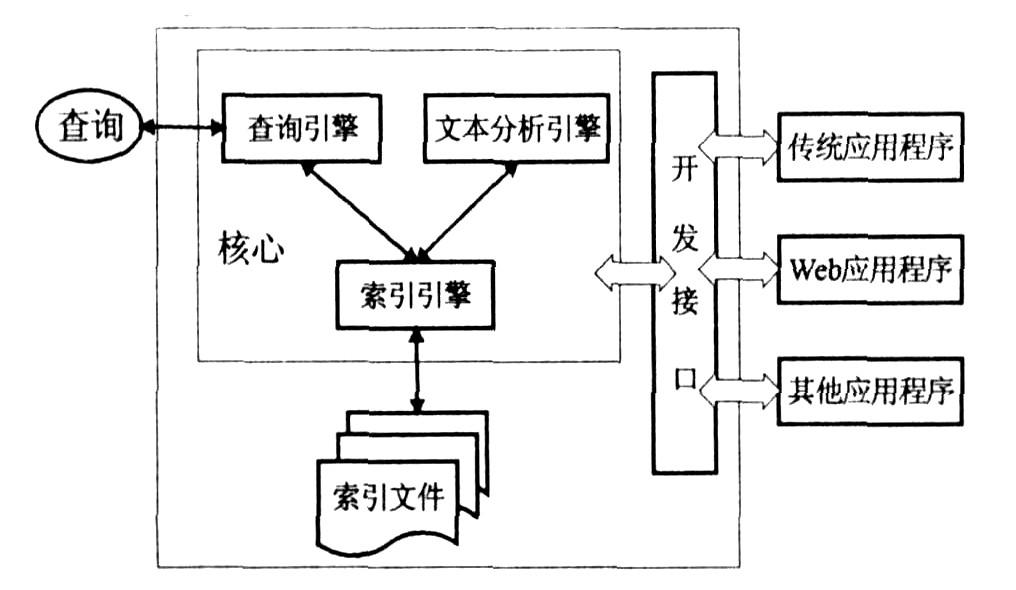
底层原理
索引结构
为了实现快速检索,Lucene采用倒排索引的数据结构。Lucene的索引结构可以分为索引(index),索引段(segment),索引文档(document),索引域(field)和索引项(term)五个层次。
Lucene的每个索引结构由一个或者多个段组成,每个段包含一个或者多个文档,每个文档又管理一个或者多个域,每个域由一个或多个索引项组成,而每个索引项就是一个索引数据。
文本分析器(Analyzer):Lucene 支持多种分析器,用于将文本数据分割成单词(Term)。分析器一般包括字符过滤器(CharFilter)、分词器(Tokenizer)和词项过滤器(TokenFilter)。字符过滤器可以对原始文本进行预处理,例如去除 HTML 标记、转换大小写等;分词器将文本分割成单词;词项过滤器可以对单词进行处理,例如去除停用词、同义词转换等。
倒排索引(Inverted Index):Lucene 使用倒排索引来存储单词与文档之间的映射关系。倒排索引是一个非常重要的数据结构,它可以快速地进行文本检索。在 Lucene 中,每个文档都有一个唯一的编号,称为文档号(DocId)。对于每个单词,Lucene 会建立一个包含文档号的倒排列表(Inverted List),该列表按照文档号进行排序,并存储每个文档中该单词出现的位置信息(位置信息可以用于短语查询等操作)。
索引文件(Index File):Lucene 将分析器处理后的数据存储到硬盘上的索引文件中。索引文件包括多个文件,例如词典文件(Term Dictionary)、倒排列表文件(Inverted List)等。Lucene 采用稀疏矩阵的方式存储倒排列表,因此索引文件通常比较小。
查询解析器(Query Parser):用户输入查询条件后,Lucene 会将查询条件解析成查询对象(Query)。查询对象包括多种类型,例如布尔查询(BooleanQuery)、短语查询(PhraseQuery)、通配符查询(WildcardQuery)等。查询对象可以组合成更复杂的查询条件,并使用倒排索引进行文本检索。
Lucene 的核心数据结构是倒排表(Inverted Index),也就是之前提到的倒排索引。倒排表是一个索引结构,它记录每个词项(Term)在哪些文档中出现过。通过倒排表,Lucene 可以快速地查找包含某个词项的所有文档。
倒排表的基本单元是 Term,它由词项(Term Text)和域(Field)组成。域指定了词项所在的字段,例如标题、内容、作者等等。一个词项可以出现在多个字段中,因此同一个词项可能会有多个 Term 对象。
倒排表的主要结构是由 Term 的词项和词项对应的倒排列表组成的。倒排列表(Posting List)是一个有序的文档列表,记录了每个文档中包含该词项的位置信息和其它统计信息,例如出现次数、文档长度等等。这些信息都用于评估文档与查询的相关性。
1、基于段的倒排表
Lucene在索引的过程中,将文档分为若干个小的段,每个段构建一张倒排表,最后将这些小的倒排表合并成一个大的倒排表。这样做的好处是,如果一个段需要被删除或更新,只需要对该段的倒排表进行操作,而不需要对整个索引进行重建。这种方法也有利于内存管理和并发控制。
2、倒排表压缩
Lucene的倒排表还可以采用各种压缩算法进行压缩,以减少磁盘空间的使用。其中最常用的压缩算法是Variable Byte Encoding(VBE)和Frame of Reference(FOR)。
3、频率信息的存储
除了词项和文档信息之外,倒排表还存储了每个文档中词项出现的频率信息。在Lucene中,频率信息是通过一种叫做Delta Encoding的方式来存储的,可以有效地减少存储空间的使用。
4、数据结构的优化
Lucene的倒排表还采用了多种数据结构来提高检索效率,如倒排表的跳表、布隆过滤器、前缀编码等等。
实践
一、索引流程
索引构建阶段主要负责从文本数据中抽取关键信息并构建索引结构
索引构建阶段需要按照如下步骤进行:
(1)创建文档对象 对于每个需要索引的文档,需要创建一个Document对象,并添加文档的字段,包括文本内容、标题、作者、日期等。
(2)分析器分词 接下来需要使用分析器对文档进行分词处理,将文档内容切分成多个词汇。可以使用StandardAnalyzer(适用于纯英文)、CJKAnalyzer等内置分析器,也可以根据需要自定义分析器。 IK-analyzer,是一个比较好的,但是这个真的比较老了。目前我正在尝试jieba
(3)添加索引 将每个词汇添加到文档的字段中,可以使用TextField、StringField等不同类型的字段,根据需要指定是否需要存储、是否需要索引等选项
(4)创建索引目录 首先需要指定一个索引目录,用于存储构建好的索引文件。可以使用FSDirectory工具类来创建本地文件系统目录或使用其他存储引擎,如RAMDirectory或NIOFSDirectory。
(5)创建索引写入器 接下来需要创建IndexWriter对象,该对象负责管理索引构建和写入过程。可以使用IndexWriterConfig类来配置IndexWriter,例如设置分析器、合并因子、最大缓存文档数等参数。
(6)提交文档 当一个文档的所有字段都添加完毕后,需要将该文档提交给IndexWriter进行处理。IndexWriter会将文档加入缓存区,等待提交到磁盘。
(7)提交索引 当需要提交所有文档时,需要调用IndexWriter的commit方法来将缓存中的索引写入到磁盘中。如果要取消索引构建,可以调用rollback方法来回滚未提交的更改。
二、搜索流程
Lucene的搜索流程分为两个部分:查询构建和搜索执行。查询构建阶段主要负责解析查询请求,并将查询语句转换成Lucene能够理解的查询对象。搜索执行阶段主要负责在索引中查找满足查询条件的文档,并返回查询结果。
查询构建
查询构建阶段需要按照如下步骤进行:
(1)创建查询解析器
首先需要创建一个QueryParser对象,该对象用于解析查询语句并生成查询对象。需要指定搜索的字段、使用的分析器等参数。
(2)解析查询语句
将查询语句传入QueryParser的parse方法中,该方法会将查询语句解析成一个Query对象,可以使用该对象来执行搜索。
(3)构建过滤器
如果需要对搜索结果进行过滤,可以使用Filter类来创建过滤器对象。可以根据需要创建不同类型的过滤器,例如TermFilter、RangeFilter等。
搜索执行
搜索执行阶段主要负责在索引中查找满足查询条件的文档,并返回查询结果。可以按照如下步骤进行:
(1)创建索引读取器
首先需要创建一个IndexReader对象,该对象用于从磁盘中读取索引文件。可以使用DirectoryReader.open方法打开之前创建的索引目录,也可以使用MultiReader对象读取多个索引目录。
(2)创建搜索器
接下来需要创建一个IndexSearcher对象,该对象用于在索引中执行查询。需要传入之前创建的IndexReader对象。
(3)执行查询
将之前创建的Query对象传入IndexSearcher的search方法中,该方法会返回满足查询条件的文档,以及每个文档的得分。
(4)处理查询结果
对于返回的每个文档,可以获取其相关信息,例如文档ID、得分、文档内容等。可以使用IndexReader的doc方法获取文档内容,使用ScoreDoc的doc和score属性获取文档ID和得分。
以上就是Lucene的工作流程,包括索引流程和搜索流程。下面以法律文书为例,展示一下Lucene的


















 1043
1043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











