







目录
99.岛屿数量-深搜
- 题目链接:卡码网题目链接(ACM模式)
文章讲解:代码随想录
题目描述:
给定一个由 1(陆地)和 0(水)组成的矩阵,你需要计算岛屿的数量。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。你可以假设矩阵外均被水包围。
输入描述:
第一行包含两个整数 N, M,表示矩阵的行数和列数。
后续 N 行,每行包含 M 个数字,数字为 1 或者 0。
输出描述:
输出一个整数,表示岛屿的数量。如果不存在岛屿,则输出 0。
输入示例:
4 5 1 1 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 0 1 1输出示例:
3
提示信息
根据测试案例中所展示,岛屿数量共有 3 个,所以输出 3。
数据范围:
- 1 <= N, M <= 50
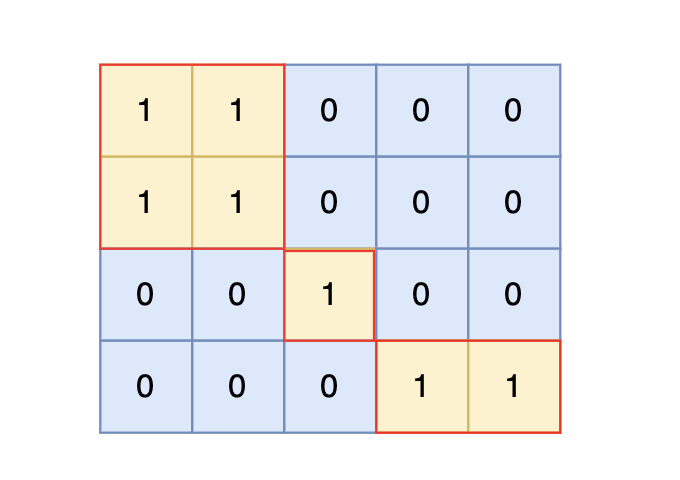
思路
注意题目中每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
也就是说斜角度链接是不算了, 例如示例二,是三个岛屿,如图:
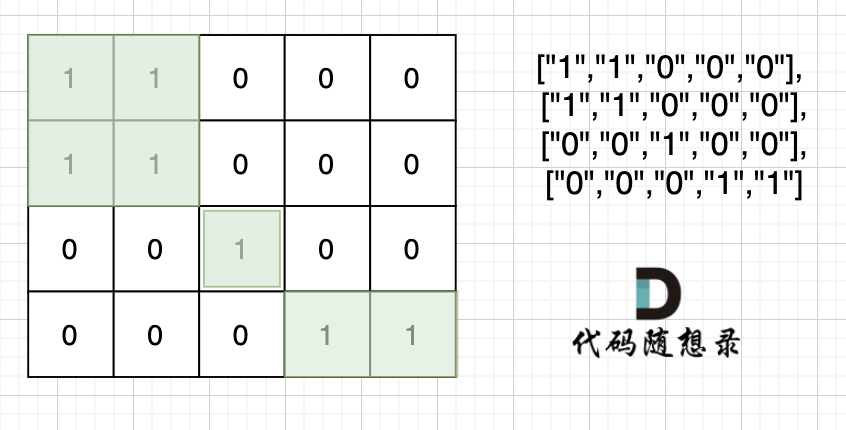
这道题题目是 DFS,BFS,并查集,基础题目。
本题思路,是用遇到一个没有遍历过的节点陆地,计数器就加一,然后把该节点陆地所能遍历到的陆地都标记上。
在遇到标记过的陆地节点和海洋节点的时候直接跳过。 这样计数器就是最终岛屿的数量。
那么如何把节点陆地所能遍历到的陆地都标记上呢,就可以使用 DFS,BFS或者并查集。
方法一: 深度优先搜索-先判断
direction = [[0, 1], [1, 0], [0, -1], [-1, 0]] # 四个方向:上、右、下、左
def dfs(grid, visited, x, y):
"""
对一块陆地进行深度优先遍历并标记
"""
for i, j in direction:
next_x = x + i
next_y = y + j
# 下标越界,跳过
if next_x < 0 or next_x >= len(grid) or next_y < 0 or next_y >= len(grid[0]):
continue
# 未访问的陆地,标记并调用深度优先搜索
if not visited[next_x][next_y] and grid[next_x][next_y] == 1:
visited[next_x][next_y] = True
dfs(grid, visited, next_x, next_y)
if __name__ == '__main__':
# 版本一
n, m = map(int, input().split())
# 邻接矩阵
grid = []
for i in range(n):
grid.append(list(map(int, input().split())))
# 访问表
visited = [[False] * m for _ in range(n)]
res = 0
for i in range(n):
for j in range(m):
# 判断:如果当前节点是陆地,res+1并标记访问该节点,使用深度搜索标记相邻陆地。
if grid[i][j] == 1 and not visited[i][j]:
res += 1
visited[i][j] = True
dfs(grid, visited, i, j)
print(res)方法二:深度优先搜索-终止条件
direction = [[0, 1], [1, 0], [0, -1], [-1, 0]] # 四个方向:上、右、下、左
def dfs(grid, visited, x, y):
"""
对一块陆地进行深度优先遍历并标记
"""
# 与版本一的差别,在调用前增加判断终止条件
if visited[x][y] or grid[x][y] == 0:
return
visited[x][y] = True
for i, j in direction:
next_x = x + i
next_y = y + j
# 下标越界,跳过
if next_x < 0 or next_x >= len(grid) or next_y < 0 or next_y >= len(grid[0]):
continue
# 由于判断条件放在了方法首部,此处直接调用dfs方法
dfs(grid, visited, next_x, next_y)
if __name__ == '__main__':
# 版本二
n, m = map(int, input().split())
# 邻接矩阵
grid = []
for i in range(n):
grid.append(list(map(int, input().split())))
# 访问表
visited = [[False] * m for _ in range(n)]
res = 0
for i in range(n):
for j in range(m):
# 判断:如果当前节点是陆地,res+1并标记访问该节点,使用深度搜索标记相邻陆地。
if grid[i][j] == 1 and not visited[i][j]:
res += 1
dfs(grid, visited, i, j)
print(res)心得收获
为什么 以上方法一代码中的dfs函数,没有终止条件呢? 感觉递归没有终止很危险。
其实终止条件 就写在了 调用dfs的地方,如果遇到不合法的方向,直接不会去调用dfs。
这里大家应该能看出区别了,无疑就是版本一中 调用dfs 的条件判断 放在了 版本二 的 终止条件位置上。
版本一的写法是 :下一个节点是否能合法已经判断完了,传进dfs函数的就是合法节点。
版本二的写法是:不管节点是否合法,上来就dfs,然后在终止条件的地方进行判断,不合法再return。
理论上来讲,版本一的效率更高一些,因为避免了 没有意义的递归调用,在调用dfs之前,就做合法性判断。 但从写法来说,可能版本二 更利于理解一些。
99.岛屿数量-广搜
- 题目链接:卡码网题目链接(ACM模式)
文章讲解:代码随想录
给定一个由 1(陆地)和 0(水)组成的矩阵,你需要计算岛屿的数量。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。你可以假设矩阵外均被水包围。
输入描述:
第一行包含两个整数 N, M,表示矩阵的行数和列数。
后续 N 行,每行包含 M 个数字,数字为 1 或者 0。
输出描述:
输出一个整数,表示岛屿的数量。如果不存在岛屿,则输出 0。
输入示例:
4 5 1 1 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 0 1 1输出示例:
3
提示信息
根据测试案例中所展示,岛屿数量共有 3 个,所以输出 3。
数据范围:
- 1 <= N, M <= 50
思路
广度优先搜索
如果不熟悉广搜,建议先看 广搜理论基础。
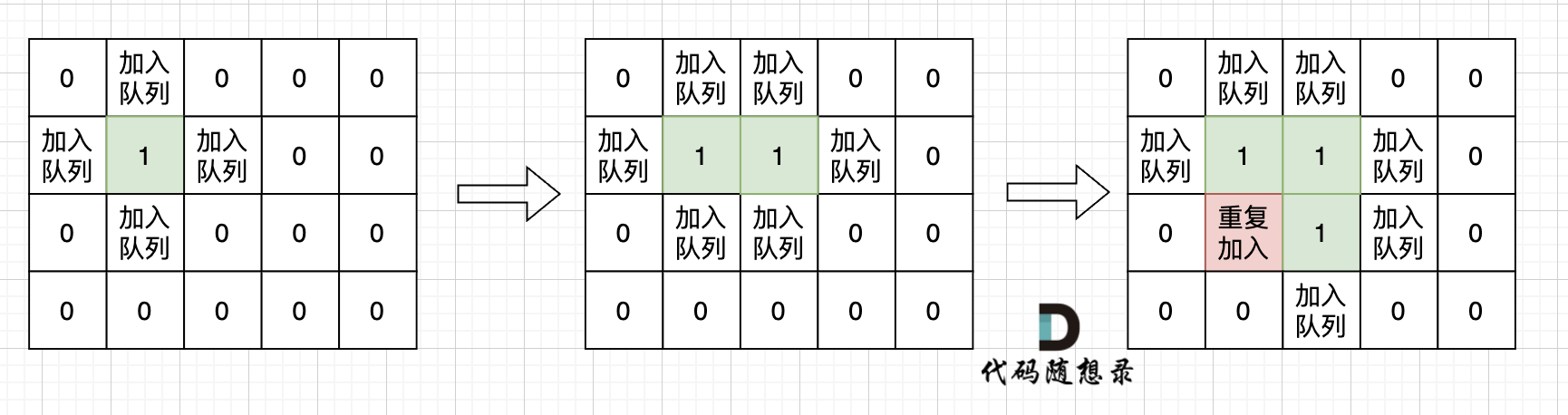
不少同学用广搜做这道题目的时候,超时了。 这里有一个广搜中很重要的细节:
根本原因是只要 加入队列就代表 走过,就需要标记,而不是从队列拿出来的时候再去标记走过。
很多同学可能感觉这有区别吗?
如果从队列拿出节点,再去标记这个节点走过,就会发生下图所示的结果,会导致很多节点重复加入队列。
方法一:广度优先搜索
def dfs(grid, visited, x, y):
dir = [(0, 1), (1, 0), (-1, 0), (0, -1)] # 四个方向
for d in dir:
nextx, nexty = x + d[0], y + d[1]
if 0 <= nextx < len(grid) and 0 <= nexty < len(grid[0]):
if not visited[nextx][nexty] and grid[nextx][nexty] == 1: # 没有访问过的 同时 是陆地的
visited[nextx][nexty] = True
dfs(grid, visited, nextx, nexty)
def main():
n, m = map(int, input().split())
grid = [list(map(int, input().split())) for _ in range(n)]
visited = [[False] * m for _ in range(n)]
result = 0
for i in range(n):
for j in range(m):
if not visited[i][j] and grid[i][j] == 1:
visited[i][j] = True
result += 1 # 遇到没访问过的陆地,+1
dfs(grid, visited, i, j) # 将与其链接的陆地都标记上 True
print(result)
if __name__ == "__main__":
main()100.岛屿的最大面积
- 题目链接:卡码网题目链接(ACM模式)
文章讲解:代码随想录
给定一个由 1(陆地)和 0(水)组成的矩阵,计算岛屿的最大面积。岛屿面积的计算方式为组成岛屿的陆地的总数。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。你可以假设矩阵外均被水包围。
输入描述
第一行包含两个整数 N, M,表示矩阵的行数和列数。后续 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。
输出描述
输出一个整数,表示岛屿的最大面积。如果不存在岛屿,则输出 0。
输入示例
4 5 1 1 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 0 1 1输出示例
4
提示信息
样例输入中,岛屿的最大面积为 4。
数据范围:
- 1 <= M, N <= 50
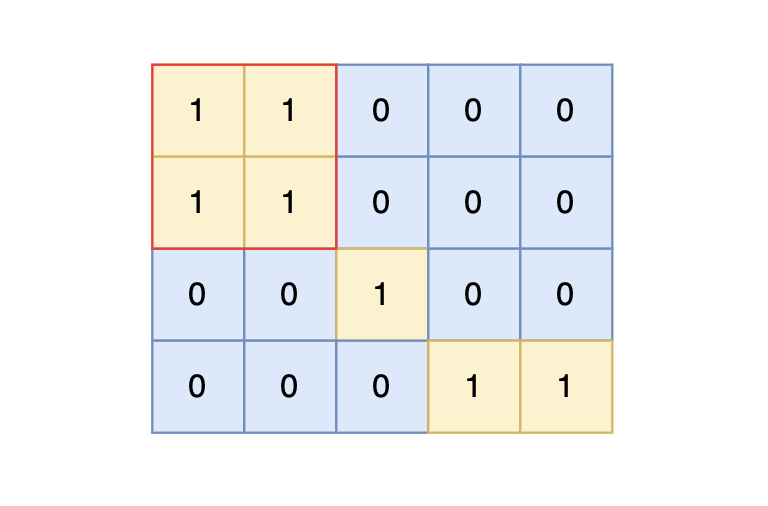
思路
深度优先搜索
很多同学写dfs其实也是凭感觉来的,有的时候dfs函数中写终止条件才能过,有的时候 dfs函数不写终止添加也能过!
这里其实涉及到dfs的两种写法。
写法一,dfs只处理下一个节点,即在主函数遇到岛屿就计数为1,dfs处理接下来的相邻陆地
写法二,dfs处理当前节点,即在主函数遇到岛屿就计数为0,dfs处理接下来的全部陆地
广度优先搜索
关于广度优先搜索,如果大家还不了解的话,看这里:广度优先搜索精讲
方法一:深度优先搜索
# 四个方向
position = [[0, 1], [1, 0], [0, -1], [-1, 0]]
count = 0
def dfs(grid, visited, x, y):
"""
深度优先搜索,对一整块陆地进行标记
"""
global count # 定义全局变量,便于传递count值
for i, j in position:
cur_x = x + i
cur_y = y + j
# 下标越界,跳过
if cur_x < 0 or cur_x >= len(grid) or cur_y < 0 or cur_y >= len(grid[0]):
continue
if not visited[cur_x][cur_y] and grid[cur_x][cur_y] == 1:
visited[cur_x][cur_y] = True
count += 1
dfs(grid, visited, cur_x, cur_y)
n, m = map(int, input().split())
# 邻接矩阵
grid = []
for i in range(n):
grid.append(list(map(int, input().split())))
# 访问表
visited = [[False] * m for _ in range(n)]
result = 0 # 记录最终结果
for i in range(n):
for j in range(m):
if grid[i][j] == 1 and not visited[i][j]:
count = 1
visited[i][j] = True
dfs(grid, visited, i, j)
result = max(count, result)
print(result)方法二:广度优先搜索
from collections import deque
position = [[0, 1], [1, 0], [0, -1], [-1, 0]] # 四个方向
count = 0
def bfs(grid, visited, x, y):
"""
广度优先搜索对陆地进行标记
"""
global count # 声明全局变量
que = deque()
que.append([x, y])
while que:
cur_x, cur_y = que.popleft()
for i, j in position:
next_x = cur_x + i
next_y = cur_y + j
# 下标越界,跳过
if next_x < 0 or next_x >= len(grid) or next_y < 0 or next_y >= len(grid[0]):
continue
if grid[next_x][next_y] == 1 and not visited[next_x][next_y]:
visited[next_x][next_y] = True
count += 1
que.append([next_x, next_y])
n, m = map(int, input().split())
# 邻接矩阵
grid = []
for i in range(n):
grid.append(list(map(int, input().split())))
visited = [[False] * m for _ in range(n)] # 访问表
result = 0 # 记录最终结果
for i in range(n):
for j in range(m):
if grid[i][j] == 1 and not visited[i][j]:
count = 1
visited[i][j] = True
bfs(grid, visited, i, j)
res = max(result, count)
print(result)心得收获
其实本题和岛屿数量这道题思路基本上是一致的,只不过需要计算每个陆地的面积,求最大















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









